はじめに
こんにちは、京セラコミュニケーションシステム デジタルプラットフォーム部の吉永です。
私たちの部門ではDatabricksを活用したデータ分析基盤の構築や技術検証を行なっています。
Databricksで50GBのデータを作成する処理が、パーティショニングの設定を見直しただけで約1/40(51分 → 77秒)に短縮されました!!
「Databricksを使っているのに処理が遅い・・・」
そう感じた時、コンピューティングリソースを増強する前にまず確認すべきなのがパーティショニングです。
本記事では、Sparkの分散処理能力が機能していない「悪い実装」と、それを最適化した「良い実装」を比較し、なぜこれほどの差が生まれたのかを検証結果とともに解説します。
| 検証項目 | パーティショニングなし | パーティショニング最適化 | 結果 |
|---|---|---|---|
| 処理時間 | 51分 (3060秒) | 77秒 | 約1/40に! |
| 稼働ワーカー | 1台 | 複数台 (並列稼働) | 分散処理に! |
元々は100GB規模の検証を行う予定でしたが、その準備段階(データ作成)で躓いたことが、この劇的な改善策を見つけるきっかけとなりました。
本記事が、同じように処理速度の壁に当たっている方の助けになれば幸いです。
対象読者
- Databricksで大量データを扱うが、期待したほど処理が速くない方
- Sparkのパーティショニングの重要性や効果を具体的に知りたい方
パーティショニングについて
パーティショニングと聞くと、テーブルのデータを物理的に分けるためのパーティショニングをイメージされる方もいらっしゃるかもしれません。
ここで利用するパーティショニングは、テーブルに対するパーティショニングではなく、Sparkのようなデータフレームのパーティショニングを指しています。
データフレームのパーティショニングとは
分散コンピューティングフレームワーク(例:Apache Spark)が、データの並列処理を可能にし、処理速度を向上させるために、内部でデータを分割・分散して保持する仕組みです。
具体的には、処理対象のデータセットを複数のブロック(パーティション)に分割し、これらをクラスター内の異なるノードに分散配置して同時にタスクを実行できるようにする仕組みです。
参考
検証
目的
ランダムなデータを生成し、それらを格納する約50GBのテーブルを作成する処理で、パーティショニングの有無による速度差を比較します。
内容
以下の4つのパターンで検証を実施しました。
| パーティショニング有無 | パーティション数 |
|---|---|
| 無し | 1 |
| 有り | 50 |
| 200 | |
| 500 |
前提条件
パーティショニングの有無以外の条件の差分を無くすため、データ生成ロジックと使用するコンピューティングリソースの設定を揃えることにしました。
データ生成ロジック
データ生成の中身(カラム構成)とコンピューティングリソースは統一しています。
ベンチマークとして以下の3種類のカラムを持つデータフレームを生成します。
- 文字列カラム: ランダムな文字列(暗号化・置換処理含む)
- 日付カラム: ランダムな日付
- 数値カラム: ランダムな整数
コンピューティングリソース
具体的には以下の設定の汎用コンピュートを用いました。

パターン1:パーティショニング無し
まずは、パーティション数を意識せず(デフォルト値のまま)、データフレームを生成・テーブルに格納する検証を実施しました。
パーティショニングを行わない場合、巨大なデータを一度に処理しようとするとドライバーのメモリ不足に陥るリスクがあります。そのため、やむを得ずループ処理を用いて少しずつデータを書き込む実装を行いました。
実装は以下の通りです。
# パーティショニング無しの実装
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, DateType, IntegerType
from pyspark.sql.functions import regexp_replace, base64, sha2, concat, col, rand, date_add, lit
from datetime import datetime, timedelta
import random
start_time = time.time()
# 設定
target_table = "yoshinaga_catalog.apache_spark_test.test_table_50gb_not_partition"
target_size_gb = 50
estimated_row_size_bytes = 800 # 一行あたり800バイトと仮定
target_num_rows = int((target_size_gb * 1024**3) / estimated_row_size_bytes)
# 共通:データ生成ロジックの定義
def generate_optimized_data():
# numPartitionsを指定せずにrangeを生成
df = spark.range(0, target_num_rows)
df_optimized = df.select(
regexp_replace(
base64(sha2(concat(col("id"), rand()), 256)),
"[^a-zA-Z]", "a"
).substr(1, 200).alias("StringColumn1"),
regexp_replace(
base64(sha2(concat(col("id"), rand() * 2), 256)),
"[^a-zA-Z]", "b"
).substr(1, 200).alias("StringColumn2"),
regexp_replace(
base64(sha2(concat(col("id"), rand() * 3), 256)),
"[^a-zA-Z]", "c"
).substr(1, 200).alias("StringColumn3"),
# ランダム日付の生成
date_add(lit("1900-01-01"), (rand() * 44927).cast("int")).alias("DateColumn1"),
date_add(lit("1900-01-01"), (rand() * 44927).cast("int")).alias("DateColumn2"),
date_add(lit("1900-01-01"), (rand() * 44927).cast("int")).alias("DateColumn3"),
# 整数の生成
(rand() * 10000).cast("int").alias("IntColumn1"),
(rand() * 10000).cast("int").alias("IntColumn2"),
(rand() * 10000).cast("int").alias("IntColumn3")
)
return df_optimized
# バッチ単位でDataFrame生成&保存(大きいデータを一括ではメモリに乗らないため)
batch_size = 1000000
num_batches = (target_num_rows + batch_size - 1) // batch_size
# データ生成関数を実行し、テーブルに書き込む
for batch in range(num_batches):
df = generate_optimized_data()
write_mode = "overwrite" if batch == 0 else "append"
df.write.mode(write_mode).saveAsTable(target_table)
end_time = time.time()
execution_time = end_time - start_time
print(f"実行時間: {execution_time:.2f} 秒")
print("パーティショニング無しの処理で実行完了!")
この実装では以下の部分でパーティション数を指定していません。
# numPartitionsを指定せずにrangeを生成
df = spark.range(0, target_num_rows)
結果
処理時間は51分(=3060秒)でした。
考察
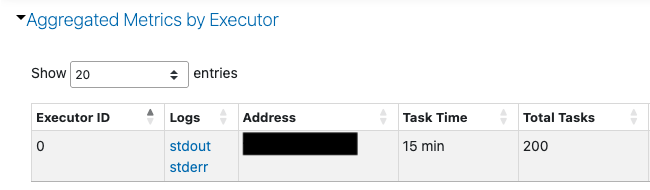
汎用コンピュートのログを確認すると、最大でもワーカーが1個しか稼働しておらず、ドライバーノードにも負荷がかかり、Sparkの分散処理が十分に活かされていませんでした。
パターン2:パーティショニング有り
次に、パターン1の問題解決とSparkの性能最大化のため、パーティション数を50、200、500と変えて、最適な設定値を探る検証を実施しました。
パーティショニングを適切に行うことで、Sparkがデータを分割して並列処理できるようになります。これにより、パターン1のような「小分けのループ処理」が不要になり、一括でドーンと書き込むシンプルな実装になります。
実装は以下の通りです。
# パーティショニング有りの実装
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import time
start_time = time.time()
# 設定
target_table = "yoshinaga_catalog.apache_spark_test.test_table_50gb_partition"
target_size_gb = 50
estimated_row_size_bytes = 800
target_num_rows = int((target_size_gb * 1024**3) / estimated_row_size_bytes)
# 共通:データ生成ロジックの定義
def generate_optimized_data():
# 以下がパターン1との違い
# numPartitionsでパーティションの数を設定
# この実装ではパーティション数200と設定
df = spark.range(0, target_num_rows, numPartitions=200)
df_optimized = df.select(
regexp_replace(
base64(sha2(concat(col("id"), rand()), 256)),
"[^a-zA-Z]", "a"
).substr(1, 200).alias("StringColumn1"),
regexp_replace(
base64(sha2(concat(col("id"), rand() * 2), 256)),
"[^a-zA-Z]", "b"
).substr(1, 200).alias("StringColumn2"),
regexp_replace(
base64(sha2(concat(col("id"), rand() * 3), 256)),
"[^a-zA-Z]", "c"
).substr(1, 200).alias("StringColumn3"),
# ランダム日付の生成
date_add(lit("1900-01-01"), (rand() * 44927).cast("int")).alias("DateColumn1"),
date_add(lit("1900-01-01"), (rand() * 44927).cast("int")).alias("DateColumn2"),
date_add(lit("1900-01-01"), (rand() * 44927).cast("int")).alias("DateColumn3"),
# 整数の生成
(rand() * 10000).cast("int").alias("IntColumn1"),
(rand() * 10000).cast("int").alias("IntColumn2"),
(rand() * 10000).cast("int").alias("IntColumn3")
)
return df_optimized
# データ生成関数を実行
df_final = generate_optimized_data()
# テーブルに書き込む
df_final.write \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.option("maxRecordsPerFile", 1000000) \
.saveAsTable(target_table)
end_time = time.time()
execution_time = end_time - start_time
print(f"実行時間: {execution_time:.2f} 秒")
print("パーティショニング有りの処理で実行完了!")
この実装では、spark.range に「numPartitions=200」という引数を追加することで、パーティション数を明示的に指定しています。
この実装を追加することで、Sparkはデータを200個のブロックに分割し、複数のワーカーに仕事を配るようになります。
# numPartitionsでパーティションの数を設定
df = spark.range(0, target_num_rows, numPartitions=200)
結果
処理時間と最大稼働ワーカー数は以下の通りとなりました。
| パーティション数 | 処理時間(秒) | 最大稼働ワーカー数 |
|---|---|---|
| 50 | 90.69 | 8 |
| 200 | 76.7 | 7 |
| 500 | 88.86 | 5 |
考察
パーティション数を明示的に指定することで、Sparkの分散処理が適切に機能し、複数のワーカーが並行稼働しました。
パーティション数を200に設定した場合、最も処理時間が短くなりました。
結果の比較と考察
結果の比較
検証の結果をまとめました。
| パーティショニング | パーティション数 | 最大稼働ワーカー数 | 処理時間 | 備考 |
|---|---|---|---|---|
| 無し | 1 | 1 | 3060秒 (=51分) | 1ワーカーしか稼働しなかったため、分散処理できていないと推測 |
| 有り | 50 | 8 | 90.69秒 | |
| 200 | 7 | 76.7秒 | 最速 | |
| 500 | 5 | 88.86秒 |
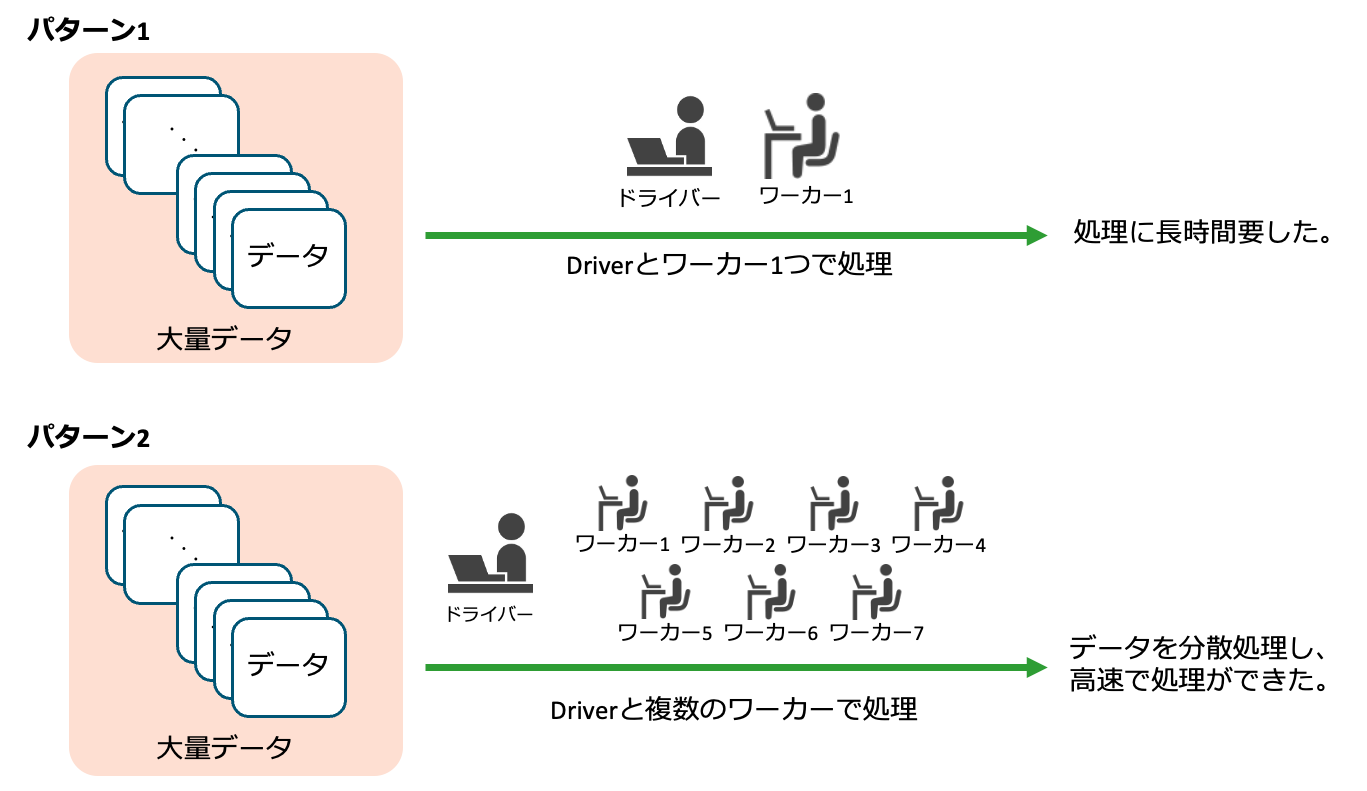
考察1 : パーティショニングによる分散処理の有効活用
パーティショニング無しの場合、実稼働ワーカー数が最大1だったのに対し 、パーティショニング有りの場合は最大8ワーカーが稼働しました。
パーティショニングを適切に行うことで、Sparkクラスター全体に処理が分散され、高速化が実現できたと考えられます。
考察2 : 適切なパーティション数の重要性
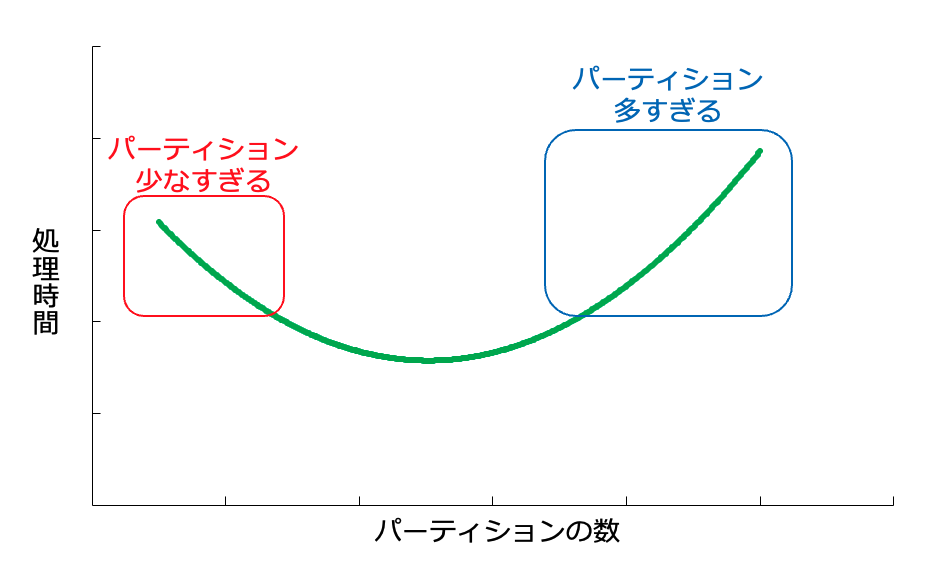
今回の検証では、パーティション数 200 の時が最速となりました。また、パーティション数が少なすぎる、あるいは多すぎる場合は、タスクの非効率やオーバーヘッドが生じるためか、処理が遅くなるという結果でした。
このことから、データサイズやクラスターリソースに応じた「適切なパーティション数」を見つけることが重要であると分かります。
考察3 : ベストプラクティスと今回の結果の整合性
今回の検証結果は、一般的に推奨されるSparkのパーティション数設定のベストプラクティスと非常に高い整合性を示しています。
パーティショニングのベストプラクティス
各パーティションのサイズは、一般的に128〜256MBの範囲が推奨されています。
小さすぎるとファイル管理のオーバーヘッドが増大し、大きすぎるとワーカーごとのメモリ消費が集中します。
参考
今回の結果の評価
今回の検証結果を、Sparkパーティショニングのベストプラクティスに基づいて評価しました。
| パーティション数 | 処理時間(秒) | 各パーティションのサイズ | 評価 |
|---|---|---|---|
| 50 | 90.69 | 50GB / 50 = 1GB | 推奨範囲より大きい。パーティションのサイズが大きすぎたため、タスク数が少なく、並列度の低下やメモリ負荷が生じた可能性がある。 |
| 200 | 76.7 | 50GB / 200 ≒ 256MB | 推奨範囲内。 |
| 500 | 88.86 | 50GB / 500 ≒ 102.4MB | 推奨範囲より小さい。パーティションのサイズが小さすぎたため、タスクのスケジューリングやオーバーヘッドが増大し、かえって処理が遅延した可能性が高い。 |
この結果は、データ生成・書き込みフェーズにおいて、パーティションごとのサイズを最適な範囲(128MB〜256MB)に保つことが、処理速度を決定する上で重要であることを示しています。
まとめ
処理内容が同じであっても、Databricksで大量データを高速処理するには、Sparkの分散処理能力を引き出す適切なパーティショニングの実装が重要です。
もしDatabricksでの処理が遅いと感じたら、コンピューティングリソースのスケールアップやスケールアウトを検討する前に、「パーティショニングを実装しているか」・「各パーティションのデータサイズが適切か」を見直してみるのが良いと思います。