はじめに
こんにちは、京セラコミュニケーションシステム 西田(@kccs_hiromi-nishida)です。
BigQueryに蓄積しているデータを分析したいなと思っても、目的のデータを取得するSQLの記述が難しくて断念したり、使い慣れてるMicrosoft Excelを使って簡単に分析できればいいのにと思ったことはありませんか?
この記事ではコネクテッドシートという、BigQuery上のデータをExcelライクなGoogle スプレッドシートで利用できる機能の紹介と、その使い方を説明したいと思います。
※ちなみに、Microsoft Excel 用のBigQueryコネクタも用意されていますので興味のある方はサイトをご確認ください。(Microsoft Excel用のBigQueryコネクタ)
本記事は2022年9月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
Google SpreadsheetsはGoogle Sheetsに名称変更されましたが、日本語訳は変わらずGoogle スプレッドシートのままですので、本記事ではGoogle スプレッドシート(以降スプレッドシート)と表現させて頂きます。1
この記事の対象者
- BigQueryに蓄積しているデータを分析したいけれど、複雑なSQLの記述は苦手な方
- 使い慣れたツールでデータ分析できたらいいのに・・と思っている方
1. コネクテッドシートとは
コネクテッドシートとは、スプレッドシートからBigQuery上のデータに接続し、簡単にデータを抽出・分析することができる機能です。
スプレッドシート上にBigQueryのデータが展開されるため、使い慣れたスプレッドシートの機能(ソートやフィルター、グラフ、ピボットテーブルなど)を使用できます。
[参照]公式ドキュメント
コネクテッド シートの使用
Use BigQuery data in Google Sheets
1-1. 利用するには
従来はGoogle WorkspaceのEnterpriseエディションが必要でしたが、2022年5月のアップデートにより、個人用Googleアカウントを含む全エディションで利用が可能になりました!2
アカウントに加え、Google Cloudの利用を開始する必要があります。
利用開始がまだの方は、以下サイトより利用登録を行うことができます。
[参照]公式サイト・ドキュメント
無料トライアルと無料枠
上記サイトの「無料で開始」ボタンから登録が可能
Google Cloud の無料プログラム
Google Cloudの無料プログラムの詳細を確認できます
1-2. 料金について
コネクテッドシートそのものの利用料金は無料ですが、別途BigQueryのストレージ料金・分析料金が発生します。
BigQueryの料金に関しては以前記事投稿していますので、ぜひご参照ください ![]()
[参照]Qiita記事
BigQueryの料金体系をサクッと解説
2. 使ってみようコネクテッドシート
では、早速コネクテッドシートを使ってみましょう!
使用画像について
特別な記載のない限り、画像はすべてGoogle スプレッドシートの画面をキャプチャしたものとなります
2-1. BigQueryに接続する
スプレッドシートを新規作成し、データ → データコネクタ → BigQueryに接続を選択します。
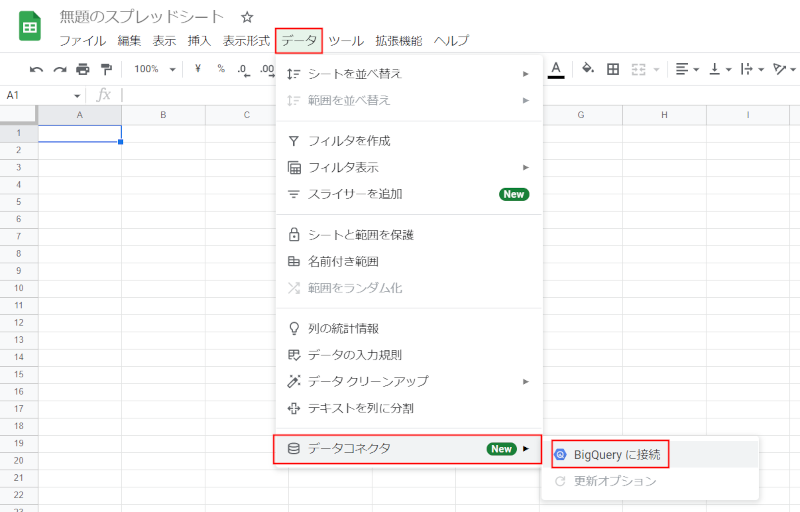
[接続]を選択してください。

次にプロジェクトを選択します。

今回は公開データセットを選択します。
公開データセットにはさまざまなデータセットがありますが、今回はNOAA(アメリカ海洋大気庁)の気象情報データセットを選択してみましょう。[ghcn_d]を選択してください。
※[データセットを検索]の欄に[ghcn_d]と入力すればすぐに表示されます。


2021年のデータである[ghcnd_2021]を選択し、[接続]を選択してください。

接続しています → データを接続しました の表示になれば完了です。


このようにスプレッドシート上にデータが展開され、グラフやピボットテーブルの作成を行うためのボタンも用意されています。
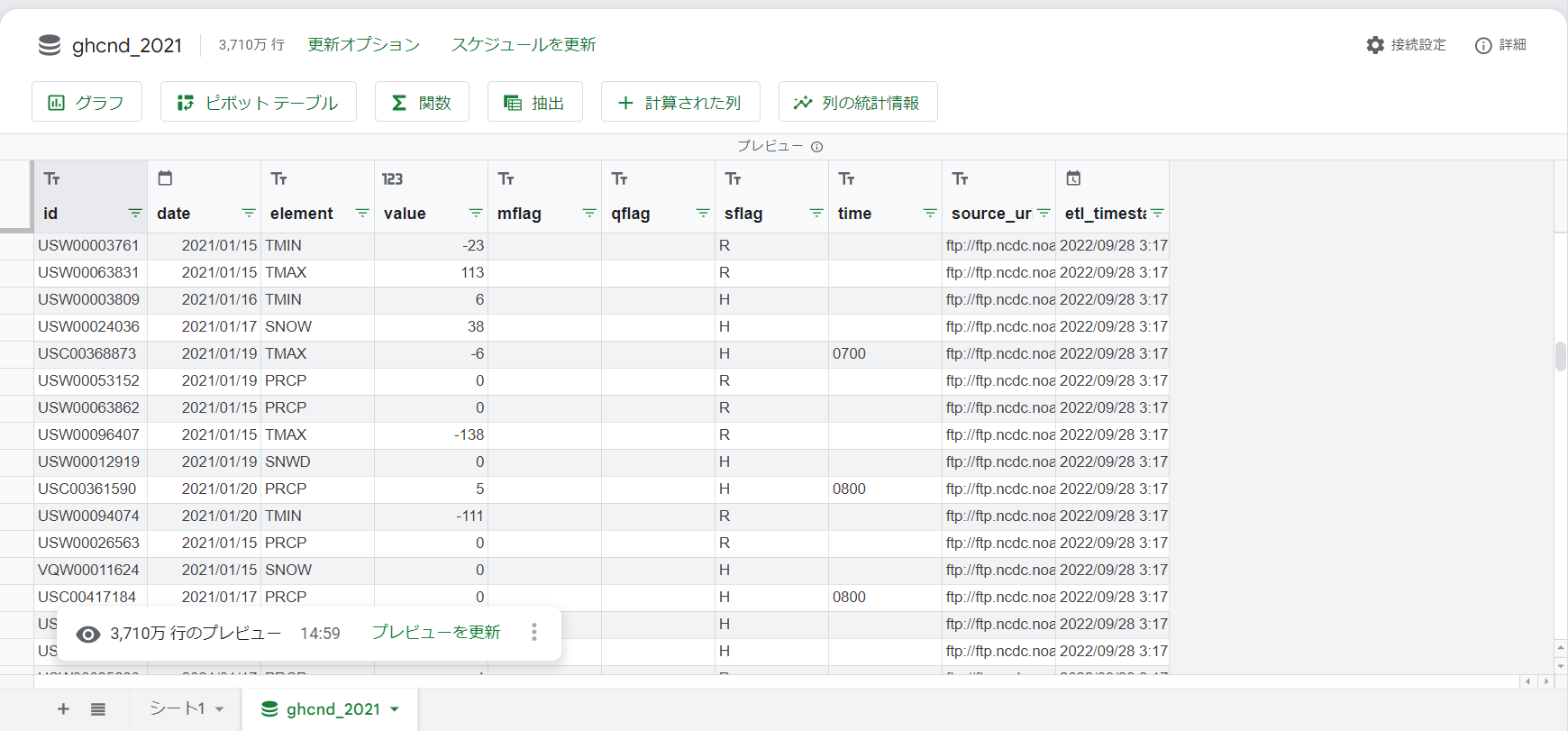
2-2. 接続したデータセットからデータを抽出する
2-1で接続したデータは、世界180か国 80,000 か所の観測所から送られてきた気象データ3なので、今回はその中から東京の気象データのみを抽出してみたいと思います。
画面上部の[抽出]ボタンを選択してください。

今回は挿入先を[新しいシート]にして、[作成]ボタンを選択してください。

このようなシートが表示されます。
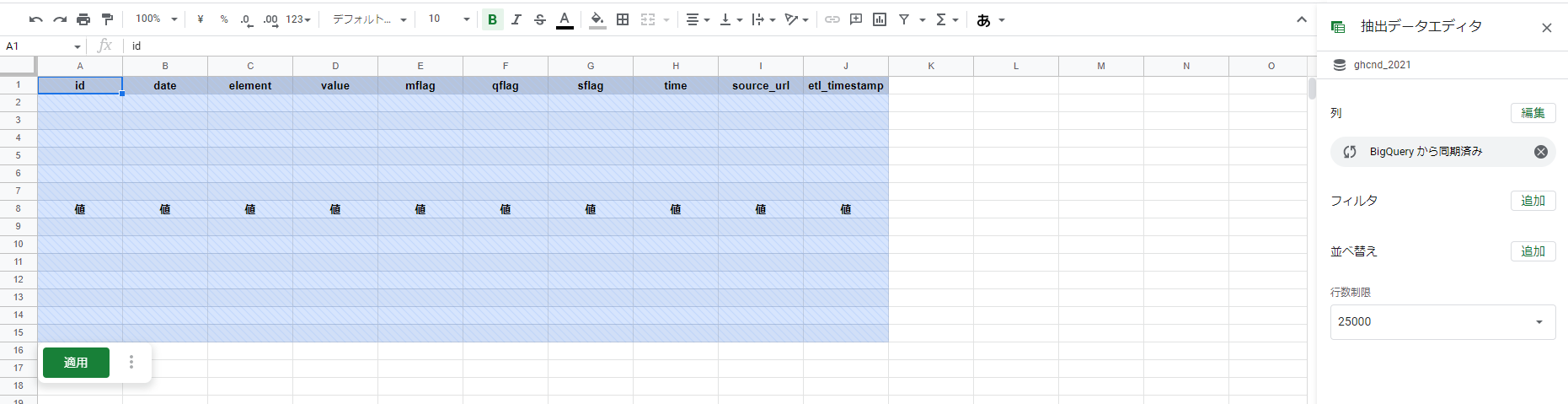
次に抽出する列を指定しましょう。
初期状態だと、[BigQueryから同期済み]となっていて、接続したテーブルの項目を全て取得するようになっていますが、今回全項目は不要なので必要な項目だけに絞りたいと思います。(分析料金の節約にもなります)
抽出データエディタエリアの、列項目横にある[編集]ボタンを選択し、[列を個別に選択する]を選択してください。
列を選択できるようになるので、[id][date][element][value]を選択し、[適用]を選択してください。

次にフィルタを指定し、抽出するデータの条件を指定します。
フィルタ項目横にある[追加]ボタンを選択し、[id]を選択してください。

[すべてのアイテムを表示]を選択し、[条件でフィルタ]項目の[なし]と表示されている箇所を選択してください。


プルダウンが表示されるので、[次と等しい]を選択し、値欄に[JA000047662](JA000047662は東京を示す観測地点のid値)と入力し、[OK]を選択します。

最後に日付項目で並べ替えを設定します。
並べ替え項目横にある[追加]ボタンを選択し、[date]を選択してください。
初期表示は昇順ですが、項目を選択するたびに昇順/降順が切り替わります。

東京の2021年気象データを全て抽出することができました。

ちなみに、element列は気象データの種類4を表しており、代表的な項目は以下の5項目です。
| 種類 | 内容 |
|---|---|
| PRCP | 降水量(1/10ミリ) |
| SNOW | 降雪量(mm) |
| SNWD | 積雪の深さ(mm) |
| TMAX | 最高気温(1/10度) |
| TMIN | 最低気温(1/10度) |
降水量、最高気温、最低気温は10で除算する必要があるので、例えば以下のようにE列に関数を定義しておくと、見やすいデータになると思います。
※elementの値が[PRCP][TAMX][TMIN][TAVG]の場合、valueの値を10で除算
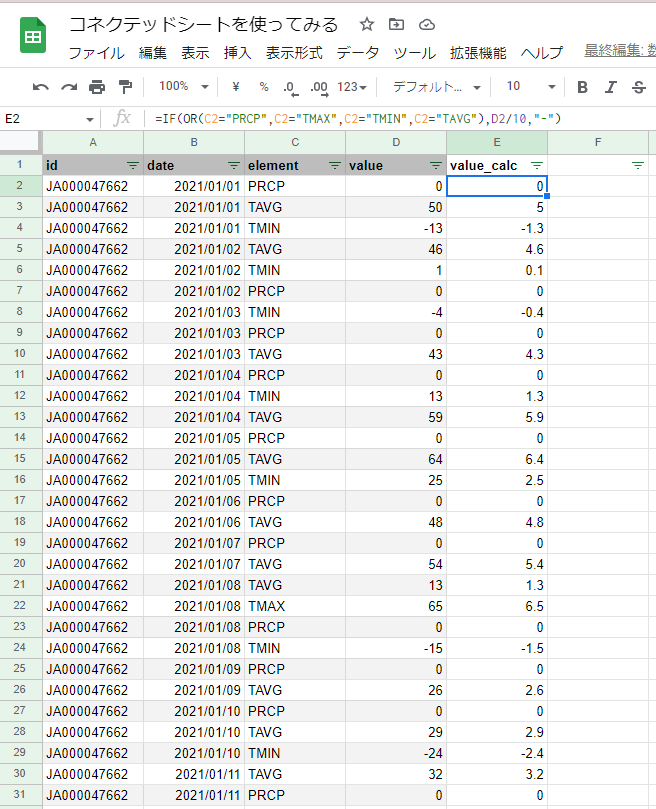
なお、東京都以外の地域のデータを取得したい場合は、フィルタの[id]項目に入力した観測地点のid値5を変更すれば確認することができます。
※ちなみに・・データを見たところ最高気温はほとんど入っておらず、平均気温(TAVG)が多く入っています。最低気温も抜けがあるので、最高気温・最低気温は分析にはあまり向かないデータかもしれません
2-3. カスタムクエリを使ってデータを抽出する
2-2ではクエリを作成することなく、スプレッドシート上からBigQueryのデータを抽出しましたが、コネクテッドシートには直接クエリを作成してデータを取得する機能もあります。
クエリ作成の知識は必要ですが、複数のテーブルを結合する等、複雑な分析を行う場合はカスタムクエリを使用します。
また、パラメータという便利な機能もあるので、あわせて紹介します。
事前準備
今回はカスタムクエリで分割テーブルを使用するので、今まで使用していた公開データ[ghcnd_2021]から分割テーブルをあらかじめ作成しておきます。
※sample_datasetというデータセット内にweatherdata_by_monthという分割テーブルを時間単位列パーティション(月単位)で作成。日本のデータに絞っています。
CREATE OR REPLACE TABLE
sample_dataset.weatherdata_by_month
PARTITION BY
DATE_TRUNC(date, MONTH) AS
SELECT
id,
date,
element,
value,
qflag
FROM
`bigquery-public-data.ghcn_d.ghcnd_2021`
WHERE
id like 'JA%'
①カスタムクエリを作成してデータ取得
データ → データコネクタ → BigQueryに接続を選択します。
次にプロジェクトを選択します。

画面下部の[カスタムクエリを作成]を選択します。

BigQuery クエリエディタが表示されるので、入力エリア内にクエリを入力します。
今回は、2021年1月~6月の大阪府における最高気温・最低気温・平均気温・降水量を取得してみましょう。
このサンプルでは、公開データセットの[ghcnd_stations]をjoinしています。
ghcnd_stationsには気象観測地点のデータが含まれており、今回は気象観測地点の名称を取得するためにjoinしました。
SELECT
id,
name,
date,
MAX(tmin) AS tmin,
MAX(tmax) AS tmax,
MAX(tavg) AS tavg,
MAX(prcp) AS prcp
FROM (
SELECT
wd.id,
s.name,
wd.date,
IF( wd.element = 'TMIN', wd.value / 10, NULL ) AS tmin,
IF( wd.element = 'TMAX', wd.value / 10, NULL ) AS tmax,
IF( wd.element = 'TAVG', wd.value / 10, NULL ) AS tavg,
IF( wd.element = 'PRCP', wd.value / 10, NULL ) AS prcp
FROM
`sample_dataset.weatherdata_by_month` AS wd
JOIN
`bigquery-public-data.ghcn_d.ghcnd_stations` AS s
ON
wd.id = s.id
WHERE
wd.date BETWEEN "2021-01-01" AND "2021-06-30"
AND s.name LIKE "%OSAKA%")
GROUP BY
id,name,date
ORDER BY
date
クエリエディタにクエリを入力し、[接続]を選択してください。

しばらくすると接続が完了し、取得結果が表示されます。

②パラメータを使ってみよう
①ではカスタムクエリを作成しデータを取得しましたが、次に地域は京都、期間は2021年6月~2021年12月のデータを取得したい、と思った場合どうすればいいでしょうか。
条件を変更するためだけに、毎回クエリを定義しなおすのは面倒ですよね。
そんな時便利なのが、パラメータという機能です。
パラメータを使用することで、クエリ内にスプレッドシートの特定のセル値を埋め込むことができます。
さっそく設定シートを作成し、パラメータを設定してみましょう。
②-1 設定シートの作成
スプレッドシートに以下のような値を持つ設定シートを作成します。
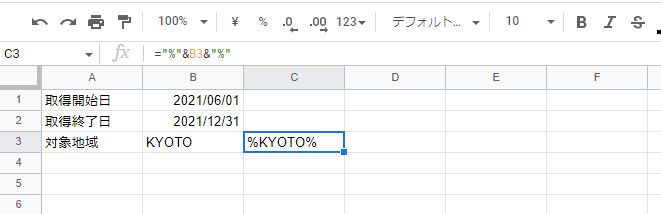
対象地域はあいまい検索にするため、B3セルに入力した文字を%で囲んだ文字にしてC3セルに表示するようにしています。(画像内の式を参照してください)
次にセルの型を設定します。
セルの設定値をクエリのパラメータとして使用するため、パラメータを設定するカラムとセルの型を合わせておく必要があります。
取得開始日を入力するセル(B1)を選択し、表示形式 → 数字 → 日付を選択してください。取得終了日を入力するセル(B2)も同じ手順で設定してください。

対象地域のセル(C3)は書式なしテキストに設定します。

これで設定シートの準備は完了です!
②-2 カスタムクエリにパラメータを定義
では、先ほど①カスタムクエリを作成してデータ取得、で作成したカスタムクエリを編集しパラメータを設定してみましょう。①で取得した結果が表示されているシートの右上にある[接続設定]を選択してください。

クエリエディタが開き、①で定義したクエリが表示されています。
今回は取得開始日、取得終了日、対象地域の3つをパラメータとして追加します。
パラメータの[追加]を選択してください。

まず、取得開始日を追加します。名前欄には[DATE_FROM]と入力し、下記画像の赤枠で囲んだアイコンを選択してください。

データ範囲の選択が行えるようになるので、参照するセルを選択します。
②-1で作成した設定シートを表示し、B1セル(取得開始日の入力を行うセル)を選択し、[OK]を選択してください。
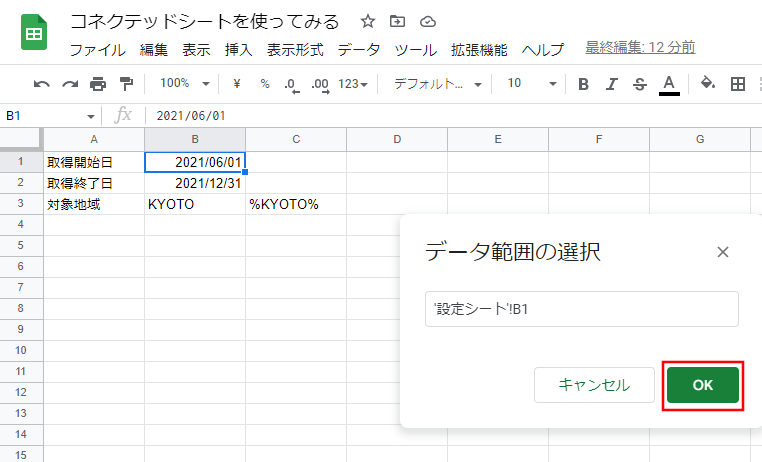
クエリエディタに戻ってくるので、[追加]を選択してください。

同じ手順で、取得終了日と対象地域を追加してください。


このように追加したパラメータが表示されていればOKです。
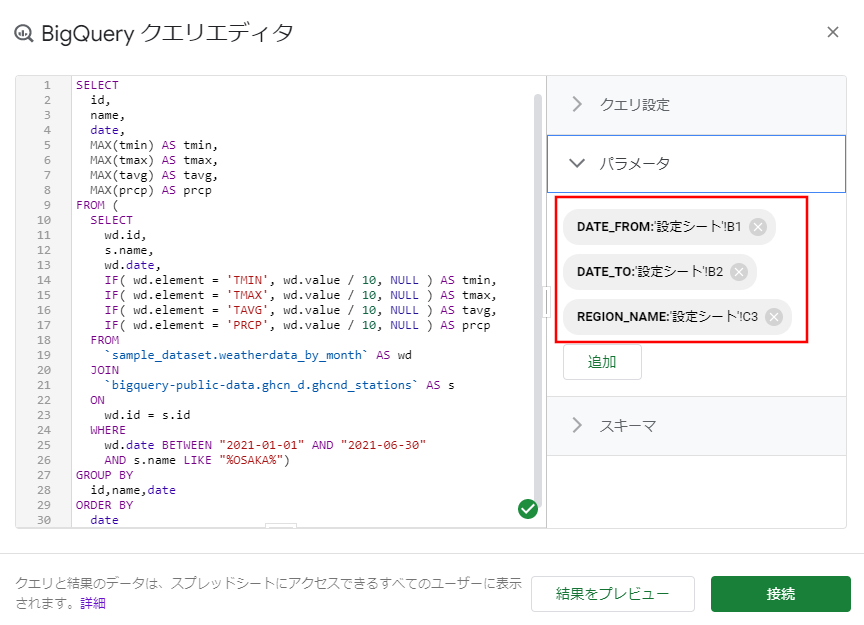
次にクエリのWHERE句を以下のように修正します。
WHERE
- wd.date BETWEEN "2021-01-01" AND "2021-06-30"
+ wd.date BETWEEN @DATE_FROM AND @DATE_TO
- AND s.name LIKE "%OSAKA%")
+ AND s.name LIKE @REGION_NAME)
クエリを修正したら、[接続]を選択してください。

設定シートで指定した値で対象データが取得されています。


設定シートの設定値を変更して、データを再取得してみましょう。

設定シートの設定値を変更後、接続シートに戻り、[プレビューを更新]を選択すると、設定シートの設定値でデータが再取得されていることがわかります。
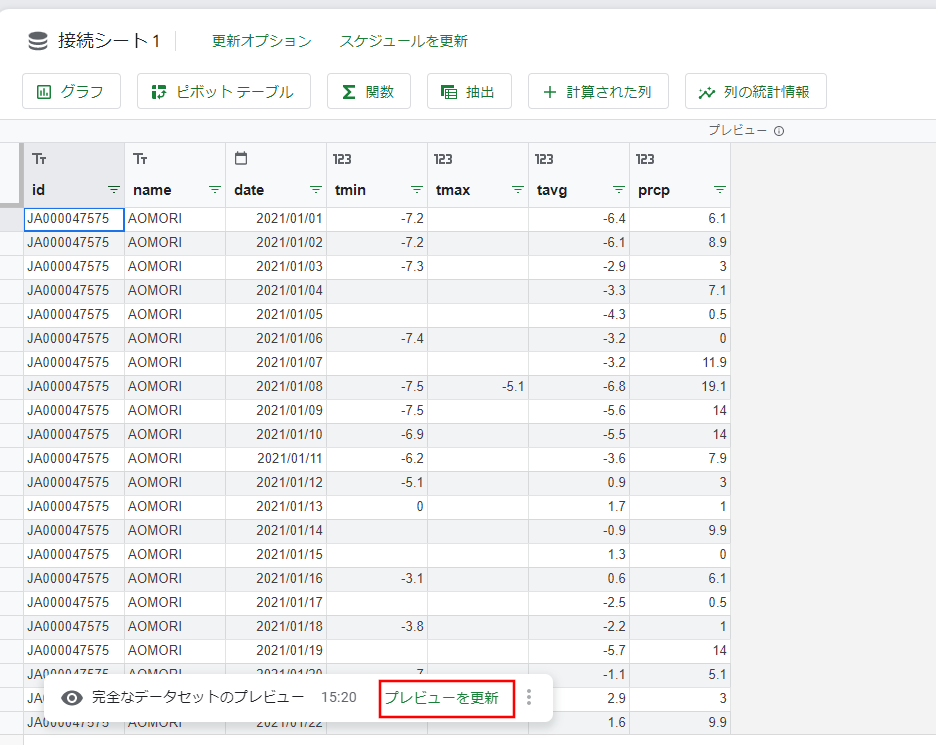
パラメータを使用すると、セルの値を修正するだけで目的のデータを簡単に取得でき便利です。
2-4. 抽出したデータからグラフやピボットテーブルを作成する
抽出したデータを使い、グラフやピボットテーブルを作成できます。
グラフの作成やピボットテーブルの細かな作成方法は省略しますが、以下のようなグラフやピボットテーブルを簡単に作成できます。
2-2で抽出したデータからピボットテーブルを作成し、2021年 東京都の雨温図を作成してみました。(平均気温・降水量それぞれのピボットテーブルを作成し、集計したデータを使ってグラフ作成)

※2021年1月はデータが欠落している日があるので、気象庁発表データ6とは大きな差があります
まとめ
- コネクテッドシートは使い慣れたスプレッドシート上からBigQueryのデータに接続できる機能
- クエリを作成しなくてもスプレッドシート上でデータの抽出が可能
- 複雑な分析やパラメータを使用したい場合は、カスタムクエリを作成してデータを抽出
- 抽出したデータからグラフやピボットテーブルの作成が可能
- BigQueryの分析料金には注意
(おまけ)作成したピボットテーブルとグラフの内訳
2-4では2-2で抽出したデータをもとに、ピボットテーブルを作成しグラフ化しました。
簡単ですが、設定内容を記載しておきます。
平均気温ピボットテーブルは2-2で抽出したデータ(2-2章の最後でvalue_calcという列を追加しています)を使って、以下の画像のように設定することで月単位の平均気温が集計できます。
- 行にdate項目を設定(日付グループで年月単位に)
- 列にelement項目を設定
- 値にvalue_calc項目を設定(平均気温なので集計はAVERAGE)
- フィルタにelement項目を設定(TAVGだけを対象に)


月別降水量ピボットテーブルは以下の画像のように設定し、集計しました。
- 行にdate項目を設定(日付グループで年月単位に)
- 列にelement項目を設定
- 値にvalue_calc項目を設定(降水量の合計を取得したいので集計はSUM)
- フィルタにelement項目を設定(PRCPだけを対象に)


グラフは複合グラフを使用しました。

-
Use Connected Sheets with VPC-SC protected data, improved Cloud Audit Logs for Connected Sheets events のAvailabilityを参照 ↩
-
GHCN の日次気象データを BigQuery で分析する の冒頭部分にデータセットの説明が記載 ↩
-
README FILE FOR DAILY GLOBAL HISTORICAL CLIMATOLOGY NETWORK (GHCN-DAILY) のIII. FORMAT OF DATA FILESにELEMENTの種類が全て記載 ↩
-
GHCND Stations - NOAA の一番左の列が観測拠点のid。日本の観測拠点のidは[JA]から始まる ↩
-
気象庁 -過去の気象データ検索 で2021年東京都の月単位のデータが確認できる ↩