はじめに
こんにちは、京セラコミュニケーションシステム 西田(@kccs_hiromi-nishida)です。
今回は前編に続いて、後編の記事となります!
たとえば基幹システム等の既存システムから何かデータを取得・連携して分析したいと思っても、費用対効果もわからないうちから正式にデータ連携出力を依頼するのはハードルが少し高いな・・と思ったことはありませんか?
そんな時、まずはスクレイピングで気軽に試してみるのもよいかもしれません。
前編、後編を合わせて読んでいただくことで、スクレイピングからデータ連携・分析までの一連の流れを確認できますので、ぜひ両編とも目を通して頂ければと思います。
そして、この記事が業務改善の一助になれれば幸いです!
本記事は2022年12月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
この記事の対象者
- WEBサイトからのデータ収集を自動化してみたいと思っている方
- Pythonを使ったスクレイピングに興味のある方
- CSVデータをBigQueryに連携し、分析してみたい方
今回の記事の範囲
前回の記事ではSelenium+Pythonを使ってWEBサイトからデータを自動収集してCSVファイル出力するところをご紹介しました。
今回の記事範囲は出力したCSVファイルをCloud Storage APIを使ってCloud Storageにアップロードし、BigQueryから外部テーブルでCloud Storage上のCSVファイルを参照、そのデータをコネクテッドシートで分析するところ(下図のオレンジ枠の範囲)となります!

前提
前編記事からの続きとなる記事ですので、前編記事の前提もそのまま引き継いでいます。
また、Cloud Storage、BigQueryを利用しますので、Google Cloudの利用開始がまだの方は以下サイトより利用登録を行うことができますので、利用を開始しておいてください。
[参照]公式サイト・ドキュメント
無料トライアルと無料枠
上記サイトの「無料で開始」ボタンから登録が可能
Google Cloud の無料プログラム
Google Cloudの無料プログラムの詳細を確認できます
Cloud Storage APIを使えるようにする
PythonからCloud Storageの操作を行うために、今回はCloud Storage APIを使います。
順を追って利用方法を説明します。
サービスアカウントの作成
使用画像について
特別な記載のない限り、画像はGoogle Cloud - IAMと管理画面をキャプチャしたものとなります
サービスアカウント1とはプログラムからGoogle APIへアクセスするために使用される特殊なGoogleアカウントです。
今回、PythonプログラムからCloud Storage APIを使用するため、まずサービスアカウントの作成が必要となります。
Google Cloudにアクセスしてハンバーガーメニューを開き、IAMと管理 ⇒ サービスアカウントを選択します。
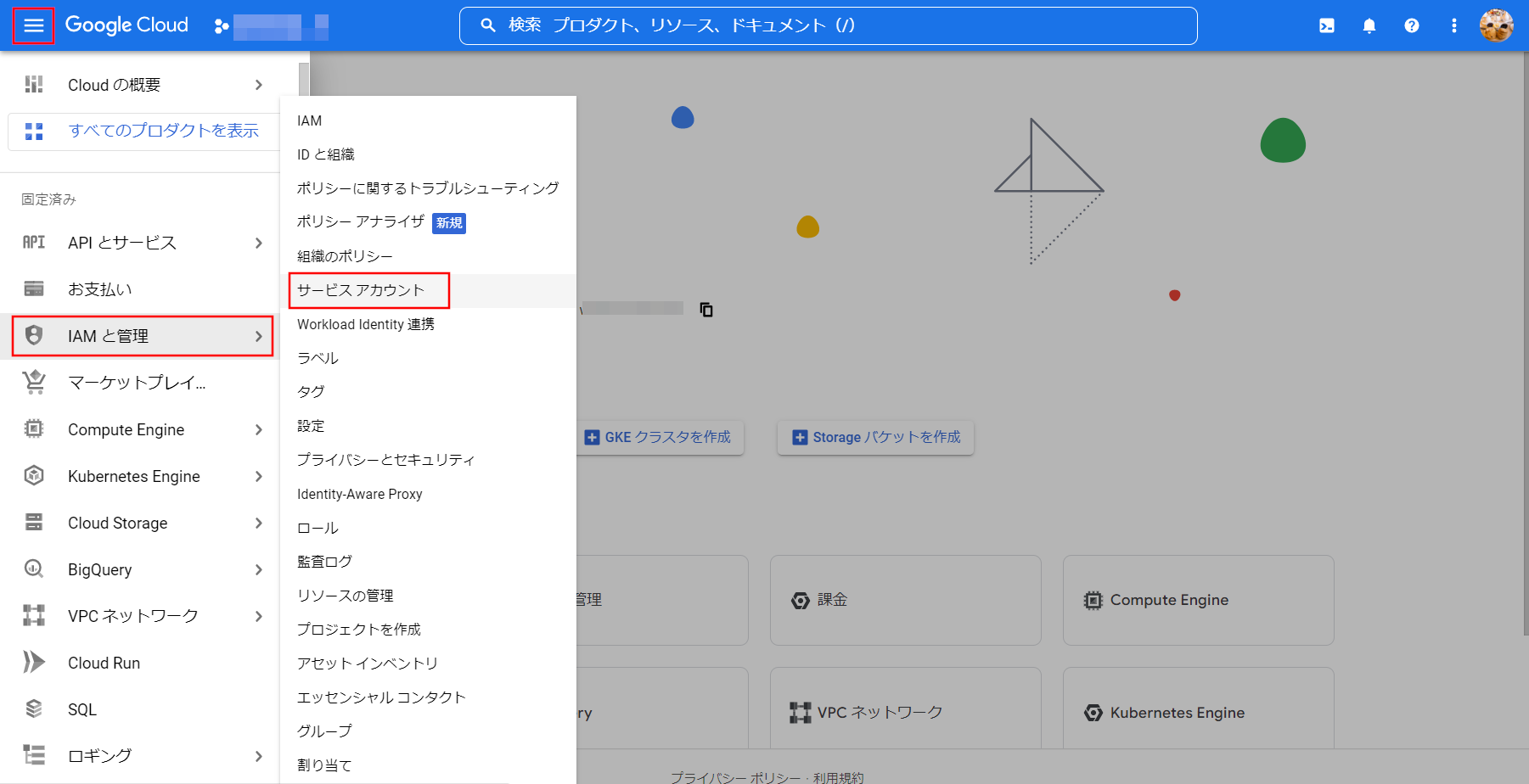
画面上部の[サービスアカウントを作成]を選択してください。
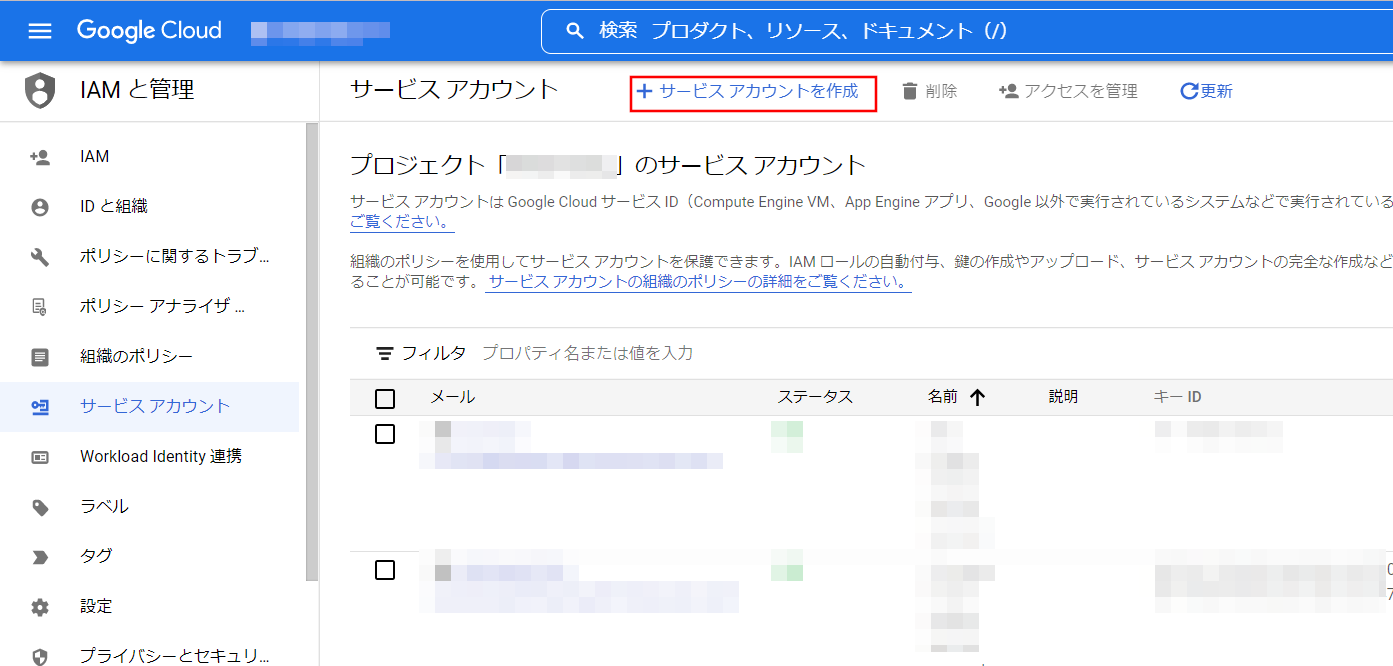
サービスアカウント名とサービスアカウントの説明を入力し、[作成して続行]を選択してください。

[ロールを追加]を選択し、Cloud Storage ⇒ ストレージ管理者を選択し、[完了]を選択してください。これでサービスアカウントの作成は完了です。


サービスアカウントキーの作成
次に作成したサービスアカウントのキーを作成します。
※このキーを使って認証を行います。
先ほど作成したサービスアカウントを選択します。

[キー]を選択し、[鍵を追加]⇒[新しい鍵を作成]を選択してください。

[JSON]を選択し、[作成]を選択すると、キーが自動的にダウンロードされます。

このキーをわかりやすい場所に移動させておきましょう。

※私の場合は、sample.py(前編で作成したプログラム)と同じ階層に配置し、わかりやすい名前にリネームしました(storage_key.json)
Google Cloud Storage用のライブラリをインストール
Python用のGoogle Cloud Storageのライブラリをインストールします。
コマンドプロンプト(Macの方はターミナル)を起動して以下を入力するだけでインストールが完了します。
pip install google-cloud-storage
Cloud Storageにバケットを作成
使用画像について
特別な記載のない限り、画像はGoogle Cloud - Cloud Storage画面をキャプチャしたものとなります
早速プログラミング!といきたいところですが、その前にCSVファイルをアップロードするバケットをCloud Storageに作成しておく必要があるので、作成しておきます。
Google Cloudにアクセスしてハンバーガーメニューを開き、Cloud Storage ⇒ バケットを選択します。
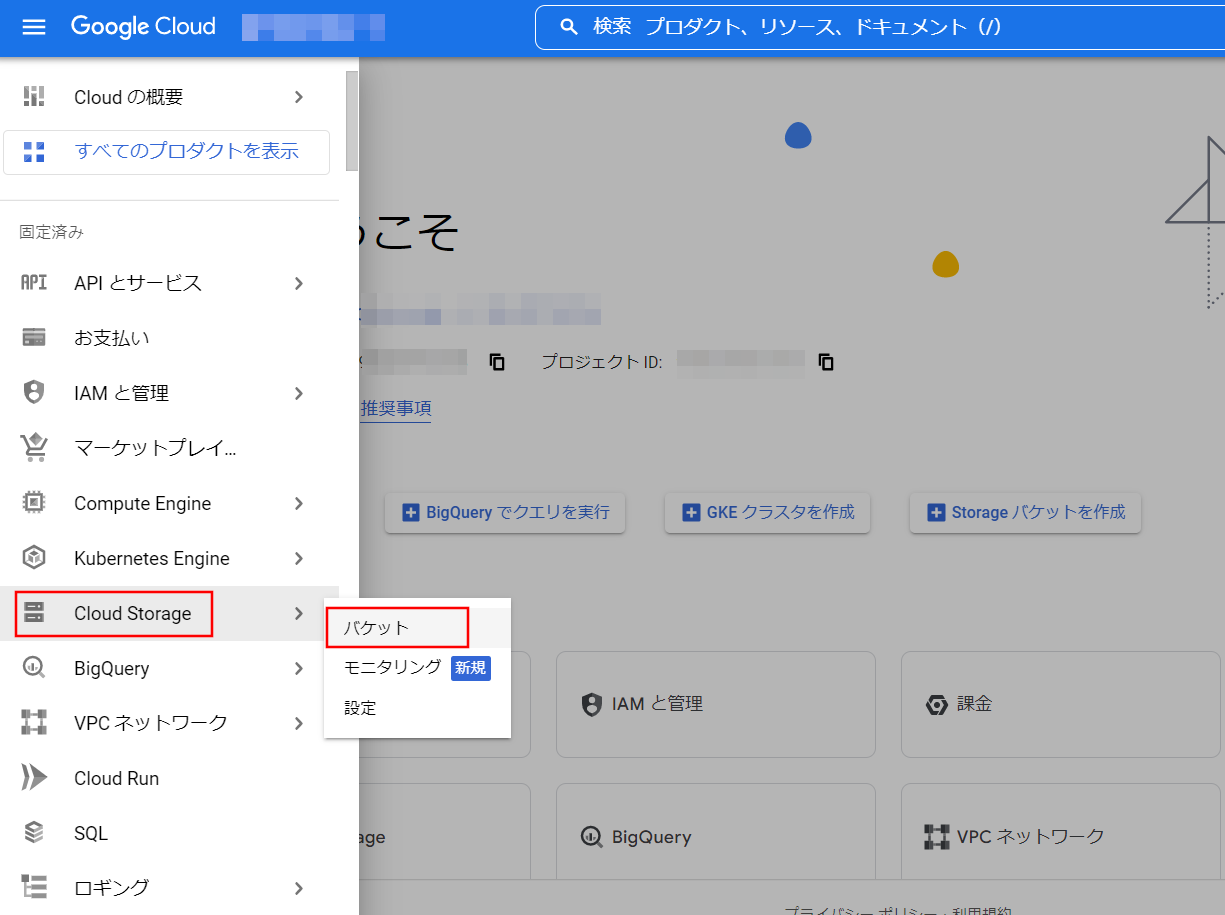
画面上部の[作成]を選択してください。

バケットの名前を入力し、[続行]を選択してください。

ロケーションタイプは今回Regionとし、asia-northeast1を選択しました。
[続行]を選択してください。

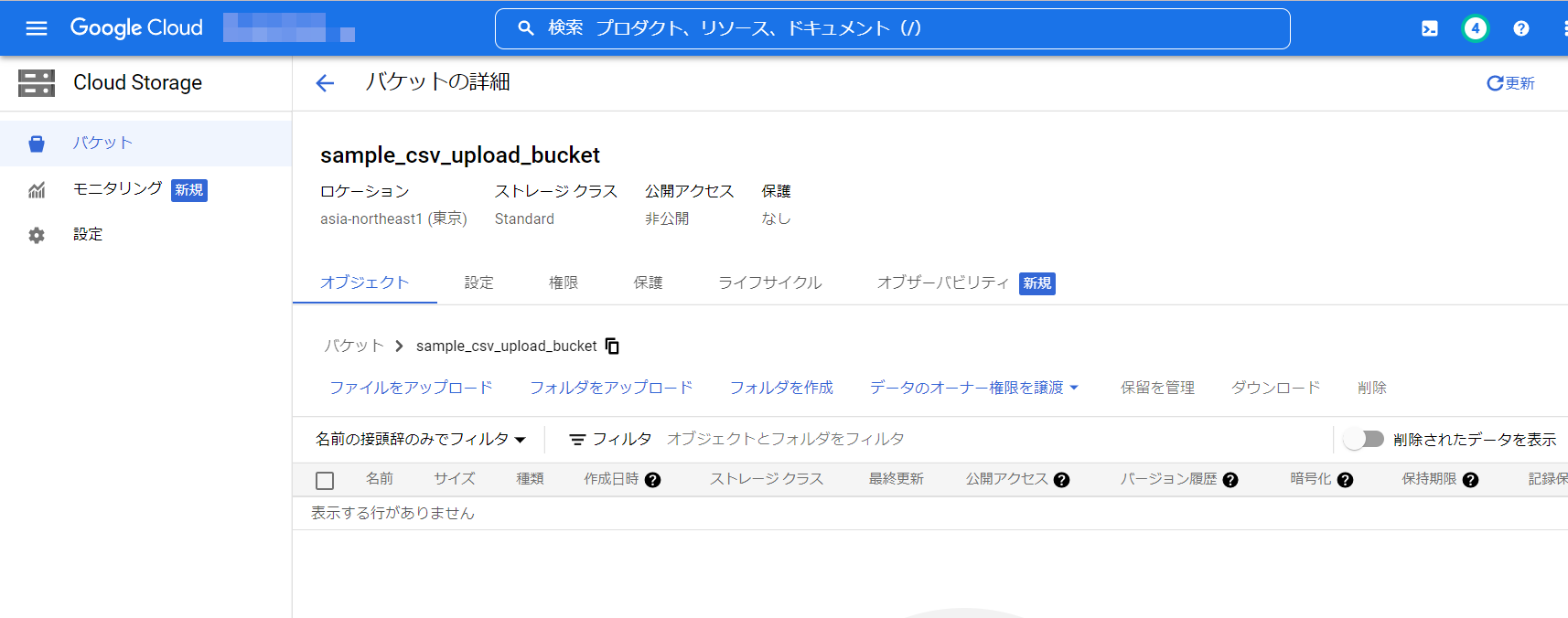
後の項目はとくに変更の必要はないので、[続行]を選択していき、最後[作成]を選択してください。バケットが作成されました。
PythonからCloud Storageにファイルをアップロード
では、前編-CSVファイルを出力するからの続きに、順を追って記述していきましょう!
まずは、必要なモジュールをインポートします。
# 冒頭部分に追記してください
from google.cloud import storage
次にサービスアカウントキーを使って認証を行い、バケットを取得します。
# 保管したサービスアカウントキーを指定します
client = storage.Client.from_service_account_json("storage_key.json")
# 作成したCSVファイルアップロード先バケット名を指定します
bucket = client.get_bucket("sample_csv_upload_bucket")
バケットを取得できたら、そのバケットにCSVファイルをアップロードします。
blob = bucket.blob(file_name)
blob.upload_from_filename(output_path)
ここまで記述できたら、sample.pyを実行してみてください。
指定したバケットにCSVファイルがアップロードされているはずです。

Cloud Storage上のCSVファイルをBigQueryのテーブルに読み込んでみよう
使用画像について
特別な記載のない限り、画像はGoogle Cloud - BigQuery画面をキャプチャしたものとなります
まず、BigQureyにデータセットを作成し、作成したデータセット内にテーブルを作成します。
データセットを作成する
Google Cloudにアクセスしてハンバーガーメニューを開き、BigQuery ⇒ SQLワークスペースを選択します。

データセットを作成するプロジェクトを選択 ⇒ データセットを作成を選択します。
これでデータセットの作成は完了です。

データセットIDを入力し、データのロケーションにはasia-northeast1を選択し、[データセットを作成]を選択してください。
※作成したCloud Storageのバケットのロケーションと合わせておいてください

作成したデータセットにテーブルを作成する
作成したデータセットを選択 ⇒ テーブルを作成を選択します。

テーブルの作成元にはGoogle Cloud Storageを選択してください。
選択すると、バケットからファイルを選択するための参照ボタンが表示されるので、[参照]ボタンを選択します。

バケットを選択 ⇒ CSVファイルを選択して、画面下部の選択ボタンを押下してください。


テーブル名を入力し、テーブルタイプは[外部テーブル]を選択してください。

スキーマは、[テキストとして編集]をONにすると、入力できる状態になるので、

以下のスキーマ定義を貼り付けてください。
※長いので折りたたんでいます。クリックすると展開します。
スキーマ定義
[
{
"mode": "NULLABLE",
"name": "year",
"type": "STRING",
"description": "年"
},
{
"mode": "NULLABLE",
"name": "atm_p_local_ave",
"type": "STRING",
"description": "気圧_現地_平均"
},
{
"mode": "NULLABLE",
"name": "atm_p_sea_surf_ave",
"type": "STRING",
"description": "気圧_海面_平均"
},
{
"mode": "NULLABLE",
"name": "precipitation_total",
"type": "STRING",
"description": "降水量_合計"
},
{
"mode": "NULLABLE",
"name": "precipitation_max_day",
"type": "STRING",
"description": "降水量_最大_日"
},
{
"mode": "NULLABLE",
"name": "precipitation_max_hour",
"type": "STRING",
"description": "降水量_最大_1時間"
},
{
"mode": "NULLABLE",
"name": "precipitation_max_min",
"type": "STRING",
"description": "降水量_最大_10分間"
},
{
"mode": "NULLABLE",
"name": "temp_ave_daily_avg",
"type": "STRING",
"description": "気温_平均_日平均"
},
{
"mode": "NULLABLE",
"name": "temp_ave_daily_high",
"type": "STRING",
"description": "気温_平均_日最高"
},
{
"mode": "NULLABLE",
"name": "temp_ave_daily_min",
"type": "STRING",
"description": "気温_平均_日最低"
},
{
"mode": "NULLABLE",
"name": "temp_highest",
"type": "STRING",
"description": "気温_最高"
},
{
"mode": "NULLABLE",
"name": "temp_lowest",
"type": "STRING",
"description": "気温_最低"
},
{
"mode": "NULLABLE",
"name": "hum_avg",
"type": "STRING",
"description": "湿度_平均"
},
{
"mode": "NULLABLE",
"name": "hum_min",
"type": "STRING",
"description": "湿度_最小"
},
{
"mode": "NULLABLE",
"name": "wind_dir_speed_avg_wind_speed",
"type": "STRING",
"description": "風向・風速_平均風速"
},
{
"mode": "NULLABLE",
"name": "wind_dir_speed_max_wind_speed",
"type": "STRING",
"description": "風向・風速_最大風速_風速"
},
{
"mode": "NULLABLE",
"name": "wind_dir_speed_max_wind_dir",
"type": "STRING",
"description": "風向・風速_最大風速_風向"
},
{
"mode": "NULLABLE",
"name": "wind_dir_speed_max_inst_wind_speed",
"type": "STRING",
"description": "風向・風速_最大瞬間風速_風速"
},
{
"mode": "NULLABLE",
"name": "wind_dir_speed_max_inst_wind_dir",
"type": "STRING",
"description": "風向・風速_最大瞬間風速_風向"
},
{
"mode": "NULLABLE",
"name": "sunlight_hours",
"type": "STRING",
"description": "日照時間"
},
{
"mode": "NULLABLE",
"name": "solar_radiation_day_avg",
"type": "STRING",
"description": "全天日射量平均"
},
{
"mode": "NULLABLE",
"name": "snow_snowfall_total",
"type": "STRING",
"description": "雪_降雪_合計"
},
{
"mode": "NULLABLE",
"name": "snow_snowfall_max_day_total",
"type": "STRING",
"description": "雪_降雪_日合計の最大"
},
{
"mode": "NULLABLE",
"name": "snow_deepest_snow",
"type": "STRING",
"description": "最深積雪"
},
{
"mode": "NULLABLE",
"name": "cloud_cover_avg",
"type": "STRING",
"description": "雲量平均"
},
{
"mode": "NULLABLE",
"name": "atm_phenomenon_num_of_snow_days",
"type": "STRING",
"description": "大気現象_雪日数"
},
{
"mode": "NULLABLE",
"name": "atm_phenomenon_fog_days",
"type": "STRING",
"description": "大気現象_霧日数"
},
{
"mode": "NULLABLE",
"name": "atm_phenomenon_thunder_days",
"type": "STRING",
"description": "大気現象_雷日数"
}
]
詳細オプションを開き、スキップするヘッダー行に[1]を入力し、[テーブルを作成]ボタンを選択してください。
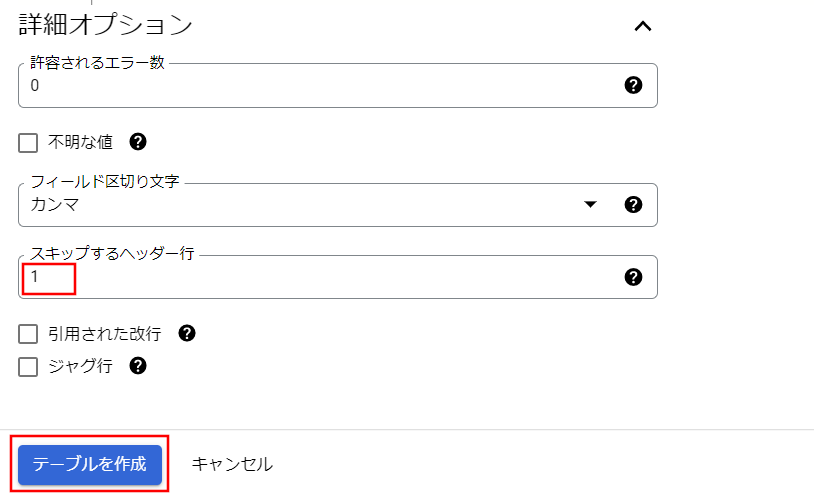
テーブル作成が完了しました。

データを加工してViewを作る
今回の気象データの中には、よーく見ると数値だけではなく記号2も含まれています。
その為、今回テーブルのスキーマ定義で項目の方はすべて文字列型(STRING)にしました。
ですが、データを使って分析する際に、数値型でないとグラフなどを作成するのが難しくなります。
そこで文字列型を数値型(NUMERIC)に変換したViewを作成し、分析時はこのViewをインプットにしたいと思います。
作成したテーブルを選択し、クエリ ⇒ 新しいタブを選択してください。

画面が開いたら、以下のSQL文を貼り付けて、保存 ⇒ ビューを保存を選択してください。

※長いので折りたたんでいます。クリックすると展開します。
※SQL中の「★プロジェクト名★」は使用しているプロジェクト名に置き換えてください。
View作成用SQL
SELECT
SAFE_CAST(`year` AS NUMERIC) AS `year`,
SAFE_CAST(`atm_p_local_ave` AS NUMERIC) AS `atm_p_local_ave`,
SAFE_CAST(`atm_p_sea_surf_ave` AS NUMERIC) AS `atm_p_sea_surf_ave`,
SAFE_CAST(`precipitation_total` AS NUMERIC) AS `precipitation_total`,
SAFE_CAST(`precipitation_max_day` AS NUMERIC) AS `precipitation_max_day`,
SAFE_CAST(`precipitation_max_hour` AS NUMERIC) AS `precipitation_max_hour`,
SAFE_CAST(`precipitation_max_min` AS NUMERIC) AS `precipitation_max_min`,
SAFE_CAST(`temp_ave_daily_avg` AS NUMERIC) AS `temp_ave_daily_avg`,
SAFE_CAST(`temp_ave_daily_high` AS NUMERIC) AS `temp_ave_daily_high`,
SAFE_CAST(`temp_ave_daily_min` AS NUMERIC) AS `temp_ave_daily_min`,
SAFE_CAST(`temp_highest` AS NUMERIC) AS `temp_highest`,
SAFE_CAST(`temp_lowest` AS NUMERIC) AS `temp_lowest`,
SAFE_CAST(`hum_avg` AS NUMERIC) AS `hum_avg`,
SAFE_CAST(`hum_min` AS NUMERIC) AS `hum_min`,
SAFE_CAST(`wind_dir_speed_avg_wind_speed` AS NUMERIC) AS `wind_dir_speed_avg_wind_speed`,
SAFE_CAST(`wind_dir_speed_max_wind_speed` AS NUMERIC) AS `wind_dir_speed_max_wind_speed`,
SAFE_CAST(`wind_dir_speed_max_wind_dir` AS NUMERIC) AS `wind_dir_speed_max_wind_dir`,
SAFE_CAST(`wind_dir_speed_max_inst_wind_speed` AS NUMERIC) AS `wind_dir_speed_max_inst_wind_speed`,
SAFE_CAST(`wind_dir_speed_max_inst_wind_dir` AS NUMERIC) AS `wind_dir_speed_max_inst_wind_dir`,
SAFE_CAST(`sunlight_hours` AS NUMERIC) AS `sunlight_hours`,
SAFE_CAST(`solar_radiation_day_avg` AS NUMERIC) AS `solar_radiation_day_avg`,
SAFE_CAST(`snow_snowfall_total` AS NUMERIC) AS `snow_snowfall_total`,
SAFE_CAST(`snow_snowfall_max_day_total` AS NUMERIC) AS `snow_snowfall_max_day_total`,
SAFE_CAST(`snow_deepest_snow` AS NUMERIC) AS `snow_deepest_snow`,
SAFE_CAST(`cloud_cover_avg` AS NUMERIC) AS `cloud_cover_avg`,
SAFE_CAST(`atm_phenomenon_num_of_snow_days` AS NUMERIC) AS `atm_phenomenon_num_of_snow_days`,
SAFE_CAST(`atm_phenomenon_fog_days` AS NUMERIC) AS `atm_phenomenon_fog_days`,
SAFE_CAST(`atm_phenomenon_thunder_days` AS NUMERIC) AS `atm_phenomenon_thunder_days`
FROM
`★プロジェクト名★.weather_dataset.tokyo_data`
データセットを選択し、テーブル名を入力して保存を選択してください。
これでViewの作成は完了です。

コネクテッドシートでデータを見てみよう
BigQueryにデータを取り込むことができたので、さっそくコネクテッドシートでデータを見てみましょう。
コネクテッドシートに関しては以前記事投稿していますので、合わせてみて頂ければ嬉しいです!
使用画像について
特別な記載のない限り、画像はGoogleスプレッドシート画面をキャプチャしたものとなります
BigQueryに接続して、スプレッドシート上にデータを表示する
スプレッドシートを新規作成し、データ → データコネクタ → BigQueryに接続を選択します。

プロジェクトを選択します。
データセットを選択し、tokyo_data_viewを選択し接続ボタンを押下してください。


スプレッドシート上でデータを見ることができるようになりました!

グラフを作ってみる
では、試しにグラフを作ってみましょう。シートの[グラフ]を選択してください。

新しいシートを選択し、作成ボタンを押下します。

今回は、年別の最高気温と最低気温の推移がわかるグラフを作ってみようと思います。
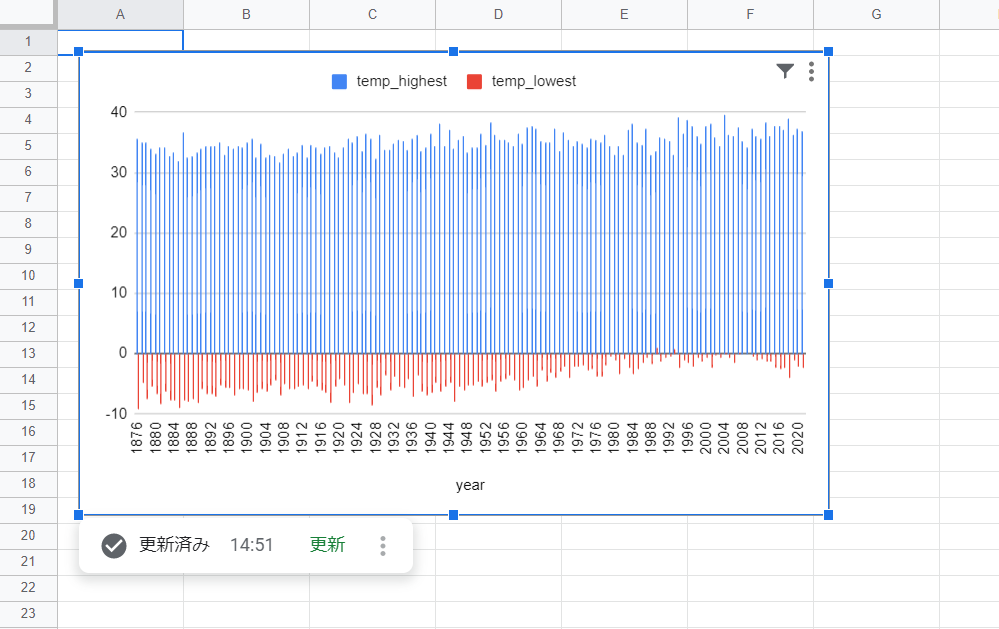
グラフエディタで、画像のように設定を行います。
● グラフの種類:縦棒グラフ
● X軸:year
● 系列:temp_highestとtemp_lowest
● フィルタ:temp_highestとtemp_lowestそれぞれ空白ではない値


ここまで設定したら、適用ボタンを押下してください。
グラフが表示されました!
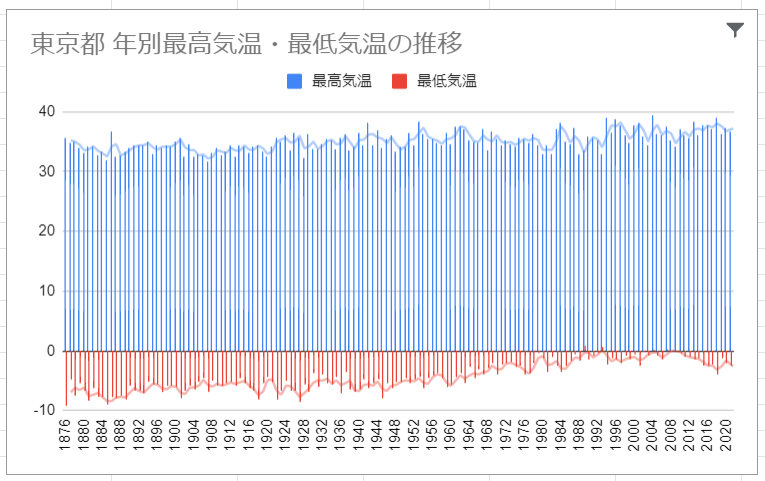
あとは、グラフのタイトルや凡例を変更して、こんな感じにしてみました。
こうみると、最高気温・最低気温が徐々に上昇していることがわかります。
とくに最低気温!昔の東京ってすごく寒かったんですね!
グラフ以外にもピボットテーブルを作成したり、データの抽出もできるのでコネクテッドシートを使って色々な分析をしてみてください!
まとめ
- SeleniumはWEBブラウザの自動化(スクレイピング)を行える便利なツール!
- スクレイピングには注意点があるのでよく確認すること(前編記事:スクレイピングの注意点)
- Cloud Storage APIを使えば、プログラムからCloud Storageの操作が可能
- BigQueryにデータがあれば、色んなツールで分析ができる!(手軽に始めるならコネクテッドシート)
おまけ
今回作成したsample.pyですが、記事上では説明の為、ソースコードを細切れで掲載しました。
ここにソースコードをまとめて掲載しておきます。
※長いので折りたたんでいます。クリックすると展開します。
完成版プログラムコード
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from google.cloud import storage
import pandas as pd
# 使用しているChromeブラウザのバージョンにあったDriverがインストールされます
# バージョンに相違がない場合はインストールされません
chrome_service = Service(ChromeDriverManager().install())
# Driverのオプションを指定できます
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
options.use_chromium = True
options.add_argument("--headless") # 最初はコメントアウトしておいてもOKです
driver = webdriver.Chrome(service=chrome_service, options=options)
# 要素がロードされるまでの待ち時間を10秒に設定します
driver.implicitly_wait(10)
# 取得したいWEBサイトのURLを指定します(今回は気象庁-過去の気象データ検索画面のURL)
driver.get("https://www.data.jma.go.jp/obd/stats/etrn/")
# 都府県・地方選択画面を表示
area_link = driver.find_element(
By.XPATH, '//*[@id="main"]/table[4]/tbody/tr/td[1]/div/table/tbody/tr[2]/td/a')
driver.execute_script('arguments[0].click();', area_link)
# 地図の中から東京都を選択
select_area_link = driver.find_element(
By.XPATH, '//*[@id="main"]/map/area[25]')
driver.execute_script('arguments[0].click();', select_area_link)
# 東京都のエリアから東京を選択
select_tokyo = driver.find_element(
By.XPATH, '//*[@id="ncontents2"]/map/area[9]')
driver.execute_script('arguments[0].click();', select_tokyo)
# 年ごとの値を選択
select_year = driver.find_element(
By.XPATH, '//*[@id="main"]/table[4]/tbody/tr/td[3]/div/table/tbody/tr[1]/td[1]/table/tbody/tr[1]/td[2]/a')
driver.execute_script('arguments[0].click();', select_year)
# 表全体を取得
table = driver.find_element(By.XPATH, '//*[@id="tablefix1"]')
html = table.get_attribute('outerHTML')
df_temp_data = pd.read_html(html)
# CSVヘッダーの定義
header_columns = ["年", "気圧_現地_平均", "気圧_海面_平均", "降水量_合計", "降水量_最大_日", "降水量_最大_1時間",
"降水量_最大_10分間", "気温_平均_日平均", "気温_平均_日最高", "気温_平均_日最低", "気温_最高",
"気温_最低", "湿度_平均", "湿度_最小", "風向・風速_平均風速", "風向・風速_最大風速_風速",
"風向・風速_最大風速_風向", "風向・風速_最大瞬間風速_風速", "風向・風速_最大瞬間風速_風向",
"日照時間", "全天日射量平均", "雪_降雪_合計", "雪_降雪_日合計の最大", "最深積雪",
"雲量平均", "大気現象_雪日数", "大気現象_霧日数", "大気現象_雷日数"]
output_data = []
# 行を1行ずつ取得
for i, data in df_temp_data[0].iterrows():
record = []
# 行から項目数分のデータだけ取得して保持
for j in range(0, len(header_columns)):
record.append(data[j])
output_data.append(record)
# CSV出力用のDataFrameを定義
output_df = pd.DataFrame(data=output_data, columns=header_columns)
file_name = "tokyo_weather_data.csv"
# output_pathはどこでも構いませんが、今回はsample.pyと同じ階層に
# outputフォルダを作成しておき、そのフォルダに出力するようにしました
output_path = "./output/" + file_name
output_df.to_csv(output_path, index=False, encoding="shift-jis")
# Chrome Driverのclose処理
driver.close()
# Cloud Storageにファイルをアップロードする
client = storage.Client.from_service_account_json(
'storage_key.json')
bucket = client.get_bucket("sample_csv_upload_bucket")
# CSVファイルをアップロード
blob = bucket.blob(file_name)
blob.upload_from_filename(output_path)
-
サービス アカウントについて ――公式ドキュメント ↩