はじめに
こんにちは、京セラコミュニケーションシステム 西田(@kccs_hiromi-nishida)です。
前回の記事でCloud Functionsの第1世代を使ってExcelをCSVに変換する処理を作成しました。
今回は、この第1世代で作成した処理を第2世代で作り直してみたいと思います。
第1世代のCloud Functionsを第2世代もリリースされたことだし使ってみたいな・・と思っている方や、第2世代ってまだ使ったことないな・・という方!
第1世代と第2世代の比較などもあわせて紹介しますので、ぜひ記事をご覧いただき作成にチャレンジしてみてください。
本記事は2023年5月ごろに作成しております。よって、引用している文章などはこの時点での最新となります。ご了承ください。
この記事の対象者
- Cloud Functions第2世代を使ってみたい方
- Cloud Functions第1世代と第2世代の作成方法の違いに興味がある方
第1世代と第2世代の違い
公式ドキュメントの比較表を確認してみましょう。
簡単にまとめると・・
- リクエストのタイムアウト時間がHTTPトリガーの場合、最大60分に延長
- CPU/メモリが第1世代の2倍に増加
- 同時実行数が最大1000件まで増加
- トラフィック分割のサポート
- EventarcのサポートやCloudEventsのサポートランタイム拡大により対応イベントソースが充実
とくにタイムアウト時間がHTTPトリガーの場合、60分に延長されたのは大きなポイントかなと思います。
実行時間が伸びたことにより、Cloud Functionsを使う場面が増えるのではないでしょうか。
(Pub/Sub経由のちょっと長めのバッチ処理もCloud Functions上でできそうですよね)
また、トラフィック分割のサポートにより、ABテストやカナリアリリースができるようになったのも、構築・運用される立場の方からみた場合、ポイントの1つかなと思います。
料金に関して
第1世代と第2世代の課金方法ですが、第2世代はCloud Runの料金が適用されるなど少し違いがあるので取り上げたいと思います。
第1世代の料金
第1世代の料金は、公式ドキュメントにも記載があるように以下の要素で料金が決まります。
※下記以外にもイメージの保存料金がかかりますが、わずかな金額なのでここでは割愛します
- 呼び出し回数
- 関数を実行した回数に応じた課金
- コンピューティング時間
- 関数の呼び出しから完了までにかかった時間に応じた課金
- データ通信
- 関数から外に転送されるデータのサイズによる課金
簡単にですが表にまとめてみました。
※コンピューティング時間は一般的なコストを記載しています
| 課金方法 | 料金 | 無料枠 |
|---|---|---|
| 呼び出し回数 | $0.4/100万回 | 最初の200万回 |
| コンピューティング時間 ※Tier1の場合 |
$0.0000025/GB秒 | 400,000 GB 秒 |
| $0.0000100/GHz秒 | 200,000 GHz 秒 | |
| データ通信 | $0.12/GB(送信・下り) | 5GBのデータ送信 |
料金に関しては、Google Cloud Pricing Calculatorで試算することができます。
このページから、CLOUD FUNCTIONSのアイコンを選択し、入力していくだけで試算が可能です。試しに以下条件で試算してみました。
- Location: Tokyo(asia-northeast1)
- Type: Memory 256MB CPU 400MHz
- Execution time per function(関数の実行時間): 3000ms
- Invocations per month(関数の呼び出し回数/月): 300万回
この条件だと、$39.03となりました。

Google Cloud Pricing Calculator
第2世代の料金
第2世代はプラットフォームにCloud Runを使用しているので、Cloud Runの料金が適用されます。
ですので、Cloud Runの課金方法を確認する必要があります。
※CPU、メモリコンピューティング時間はTier1の場合の料金
| 課金方法 | 料金 | 無料枠 |
|---|---|---|
| CPUコンピューティング時間 | $0.00002400/vCPU秒 | 180,000/vCPU秒 |
| メモリコンピューティング時間 | $0.00000250/GiB 秒 | 360,000/GiB秒 |
| リクエスト回数 | $0.40/100万リクエスト | 200万リクエスト |
同じようにGoogle Cloud Pricing Calculatorで試算してみましょう。
- Location: Tokyo(asia-northeast1)
- Cpu:1
- Memory:256MB
- Execution time per request(実行時間): 3000ms
- Requests per Month (呼び出し回数/月): 300万回
この条件だと、$6.88となりました。

Google Cloud Pricing Calculator
余談
Cloud Functions第2世代はプラットフォームがCloud Runなので、第1世代にくらべると性能は上がっていると言えます。
となると、Cloud RunとCloud Functionsどっち使えばいいの?となりませんか?
そんな方向け(?)に公式ブログに記事があったので紹介しておきます。
さっそく作ってみよう
前回の記事と同様に、Cloud Storageへのファイルアップロードをトリガーに実行されるCloud Functionsを第2世代で作り直してみます。
使用画像について
特別な記載のない限り、画像はGoogle Cloud - Cloud Functions画面をキャプチャしたものとなります
Cloud Functionsから[ファンクションを作成]を選択します。

Eventarcトリガーの作成
Cloud Functions第2世代では、Eventarcトリガーを使用することでサポートされているイベントタイプで関数をトリガーすることができます。
画像のように基本情報を設定してみてください。
入力し終わったら、[EVENTARCトリガーを追加]を選択します。

以下のように設定をし、[トリガーを保存]を選択してください。
- トリガーのタイプ:Googleのソース
- イベントプロバイダ:Cloud Storage
- イベント:google.cloud.storage.object.v1.finalized
- バケット:Excelファイルをアップロードするバケットを選択

※画像の赤枠のようにロール付与の警告が表示されている場合は、[付与]ボタンを選択することでロールを付与することができます。表示されている場合は付与してください。
Eventarcトリガーが追加されました。
[次へ]を選択し、コードの作成を行いましょう。

コードの作成
前回記事のコードをそのまま使います。(一部分修正する箇所はありますが)
ランタイム(Python 3.11)を選択し、必要なライブラリを定義します。
requirements.txtを選択し、以下を貼りつけてください。
openpyxl==3.*
google-cloud-storage

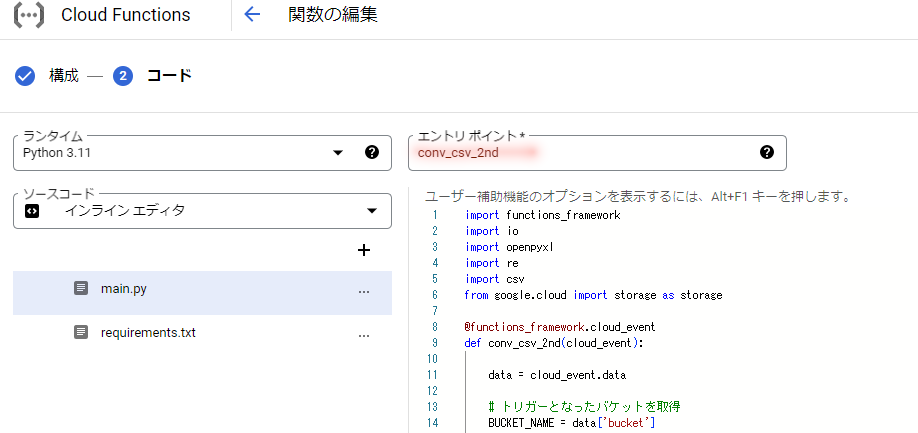
次に処理をmain.pyに記述します。
以下のコードを貼り付け、エントリポイントを[conv_csv_2nd]に変更し、デプロイを選択してください。
※長いので折りたたんでいます。クリックすると展開します。
プログラムコード
import functions_framework
import io
import openpyxl
import re
import csv
from google.cloud import storage as storage
@functions_framework.cloud_event
def conv_csv_2nd(cloud_event):
data = cloud_event.data
# トリガーとなったバケットを取得
BUCKET_NAME = data['bucket']
# CSVファイルを出力するバケット
TARGET_BUCKET_NAME = "csv_output"
# 対象のシート名
TARGET_SHEET_NAME = "データ連携"
OUT_NAME = 'merge.csv'
client = storage.Client()
# バケットの取得
bucket = client.get_bucket(BUCKET_NAME)
# バケット内のオブジェクト一覧を取得
blobs = client.list_blobs(BUCKET_NAME)
# 取得対象行(ヘッダーは不要なので2行目から)
start_row = 2
pattern = r".*\.(xlsx|xls)$"
si = io.StringIO()
writer = csv.writer(si, quoting=csv.QUOTE_ALL)
for blob in blobs:
# .xlsx,.xlsファイルだけを処理対象とする
if re.match(pattern, blob.name, re.IGNORECASE):
buffer = io.BytesIO()
blob.download_to_file(buffer)
wb = openpyxl.load_workbook(buffer)
if TARGET_SHEET_NAME in wb.sheetnames:
targetSheet = wb[TARGET_SHEET_NAME]
# 対象シートの最大行数・最大列数を取得
max_column = targetSheet.max_column
max_row = targetSheet.max_row
# 開始行~最大行までループしながら1~最大列数分の値を取得して書き込み
for r in range(start_row, max_row+1):
row_data = []
for c in range(1, max_column+1):
row_data.append(targetSheet.cell(row=r, column=c).value)
writer.writerow(row_data)
wb.close()
# CSVアップロード対象のバケットにCSVファイルをアップロード
bucket = client.get_bucket(TARGET_BUCKET_NAME)
blob = bucket.blob(OUT_NAME)
blob.upload_from_string(data=si.getvalue(), content_type='text/csv')
client.close()
si.close()
return "OK"
デプロイが成功すると、緑色のチェックマークがつきます。

ソースコードの違い
第1世代と第2世代で、作成したコードにどのような違いがあるか紹介しておきます。
- import文の追加
以下の1文が追加となります。
CloudEvent 関数を使うときに必須のライブラリなので、おまじないのように入れておきます。
import functions_framework
- 関数の引数の変更
第2世代は引数がcloud_eventになります。
+ def conv_csv_2nd(cloud_event):
- def conv_csv(event, context):
- eventからのデータ取得方法
たとえば、eventからバケット名を取得する場合は以下のような記述になります。
※関数の引数であるcloud_event / eventから取得
# 第2世代
+ data = cloud_event.data
+ BUCKET_NAME = data['bucket']
# 第1世代
- BUCKET_NAME = event['bucket']
動作確認
動作確認は、以下の記事と手順が同じなので、ここでは割愛します。
以下の記事を見てください。
実行時にエラーが出た場合
おそらく、ログにこのエラーが出ていると思います。

このエラーは認証のエラーの為、サービスアカウントに必要な権限が付与されているかを確認し、付与されていなければ付与してください。
1. サービスアカウントを確認する
作成したCloud Functionsを開き、[詳細]を選択すると、使用しているサービスアカウントが表示されていますので、このサービスアカウントに対して権限を付与します。

2. 権限の付与
[IAMと管理]→[IAM]を選択します。

1で確認したサービスアカウントを探します。
認証エラーが出る場合は、この4つの権限が付与されているか確認してください。
付与されていないと思うので、足りない権限を付与します。右側の鉛筆のようなアイコンを選択してください。

画像のようにロールを追加し、保存を選択すれば完了です。

最後に
今回は第1世代と第2世代の違いや料金、具体的な関数の作成方法をご紹介しました。
まだまだ第1世代の関数が多いのが現状かなと思いますが、メリットも多いので第2世代を積極的に使っていきたいですね!(いつか第1世代がサポート終了になるかもしれないですし)