KCCS APIの過去気象予報と発電実績を元に、太陽光発電電力量を予測する記事を、以前投稿いたしました。
[・過去気象予報を使って太陽光発電電力量を予測する]
(https://qiita.com/kccs_api1/items/360d6b135030f46eb5b1 "過去気象予報を使って太陽光発電電力量を予測する")
JupterNotebookでpytonを使い実装していましたが、弊社ではGoogle Cloudパートナー企業でGoogle Cloudを使っておりますので、せっかくなので、全てGoogle Cloudのサーバレスサービスで実装したいと思います。
[・KCCSのGoogle Cloud ソリューション]
(https://www.kccs.co.jp/ict/service/gcp/ "Google Cloud ソリューション")
以下のサービスと役割でデータ分析の基盤とします。
| サービス | 役割 |
|---|---|
| CloudStorage | Inputデータの格納先 (過去気象予報、発電実績) |
| Dataprep | BigQueryへデータをクレンジングして格納する。 |
| BigQuery | モデルを使い発電予測を行う。 |
| DataPortal(DataStudio) | 予測結果を可視化する。 |
機械学習の基盤にBigQuery MLを使う意図としては、SQLで大きなデータを扱えるメリットを活かしたいと考えております。
[・BigQuery ML とは ]
(https://cloud.google.com/bigquery-ml/docs/introduction "BigQuery ML とは ")
BigQuery ML では、既存の SQL ツールやスキルで機械学習を使用できるため、データ アナリストも機械学習を簡単に利用できます。アナリストは、BigQuery ML を使用して BigQuery に ML モデルを構築し、評価できます。スプレッドシートなどのアプリケーションに少量のデータをエクスポートする必要はありません。また、データ サイエンス チームの限られたリソースを待つ必要もありません。
利用するGoogle Cloudサービスが多いため、記事を以下の2回に分けたいと思います。
第1回 Dataprepを活用したCloud StorageからBigQueryへデータをクレンジングして格納する
第2回 BigQuery MLで太陽光発電量を予測して、DataPotalに表示する
#DataprepでCloud Storage→BigQueryへデータをクレンジングして格納する。
今回は、Dataprepを活用してBigQueryに対してCloudStorageのデータの格納をします。
Dataprepはサーバレスな環境(※)で、分析と機械学習に使用するデータを視覚的に探索、クリーニング、準備できるインテリジェントなクラウド データサービスになります。
※バックエンドDataFlowが動作します。
[・Dataprep by Trifacta]
(https://cloud.google.com/dataprep?hl=ja "Dataprepとは")
若干のETLツールの知識が必要になりますが、ノンコーディングでCSVデータをクレンジングしてデータ取り込みができますので、便利で扱いやすいサービスになります。
気象予報と発電実績をインプットに発電予測を行うため、以下がインプットファイルになります。
過去の気象予報ファイル(WEATHER_FORECAST_RESULT.csv )
過去の発電実績ファイル(PV_FORECAST.csv )
・過去の気象予報ファイルは、KCCS APIから取得します。
緯度・経度を指定してダウンロードします。
[KCCS API 過去気象予報データダウンロード機能]
(https://www.energy-cloud.jp/specification/#past-weather-forecast "KCCS API 過去気象予報データダウンロード機能")
・過去の発電実績ファイルは、弊社社員の住宅に設置された太陽光発電量を利用します。
インプットファイルをCloud Storageにアップロードします。

これをDataprepでロードします。
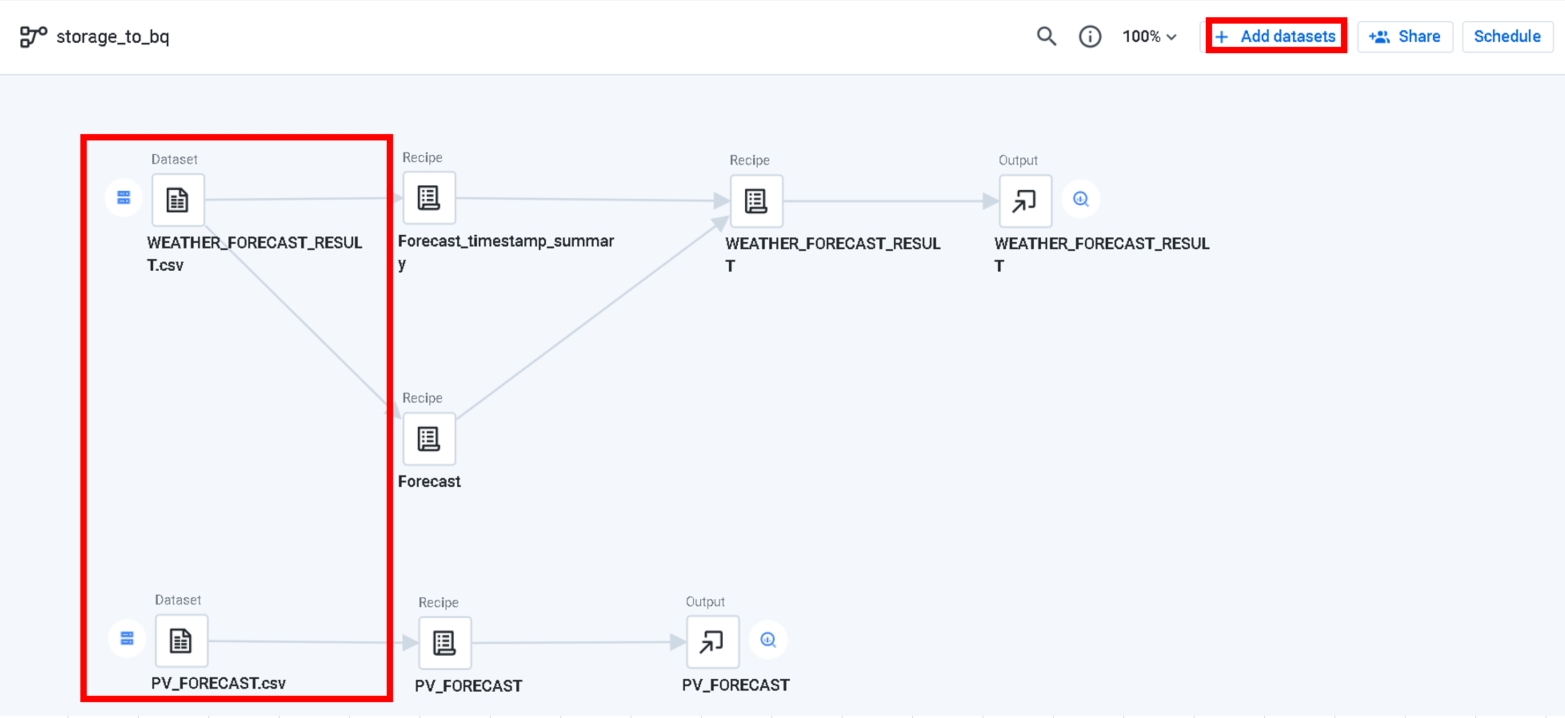
##過去の気象予報ファイル(WEATHER_FORECAST_RESULT.csv )取り込み
過去気象予報(WEATHER_FORECAST_RESULT.csv)のデータをクレンジングします。
CSVのカラムは
場所名、緯度、経度、予報演算実施日時、日時、風速(m/s)、風向(360度)、気温(K)、気温(℃)、相対湿度(%)、降雨量(mm/h)、全雲量(%)、上層雲量(%)、中層雲量(%)、下層雲量(%)、日射量(W/m^2)、南中高度、南中角度
となります。
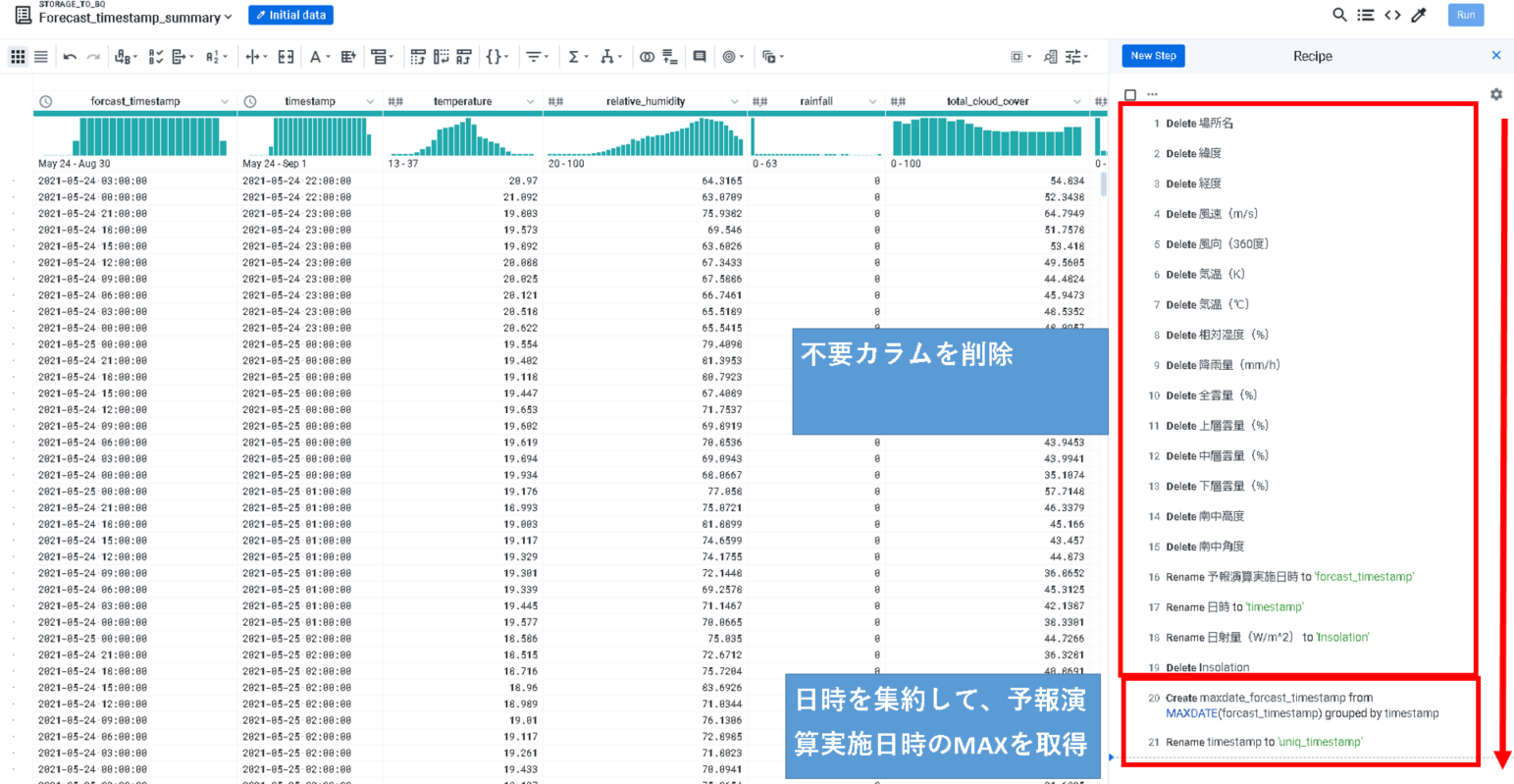
このデータのクレンジング内容は
①場所名、緯度、経度、風速(m/s)、風向(360度)、気温(K)はKCCS APIからダウンロードする時に指定済みのため不要。
→カラムを削除。
②予報演算実施日時は予報日時毎のデータが含まれているが、最新の予報演算日時のデータに絞る必要がある。
→集計処理用のデータセットと、結合用のデータセットで分けて、最後に結合する。

③カラム名に和名は使えないので、英名にリネームする必要がある。
④仕様上、降雨量に空の列があるので0に変換する。
⑤CSV読み込み時にIntで読みこんでしまうカラムをFloat型に変換する。
→BigQueryにてFloat型で処理するため。
という仕様にしたいと思います。
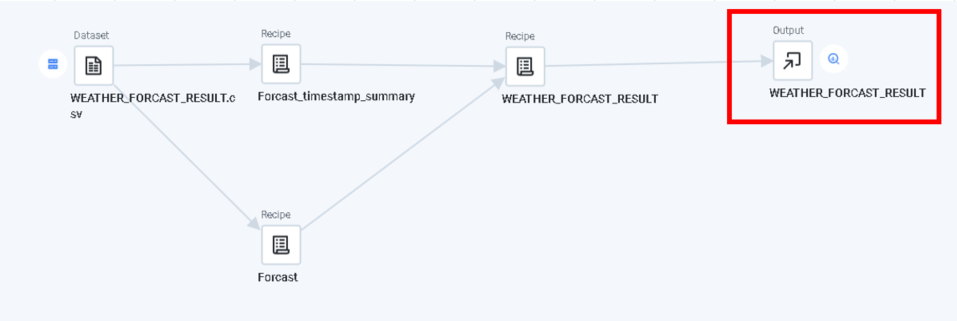
そのためRecipeを分けて、

上のサマリ用のRecipeは、
・不要カラムを削除
・日時を集約(Group by)して、予報演算実施日時のMAXを取得する。
しています。
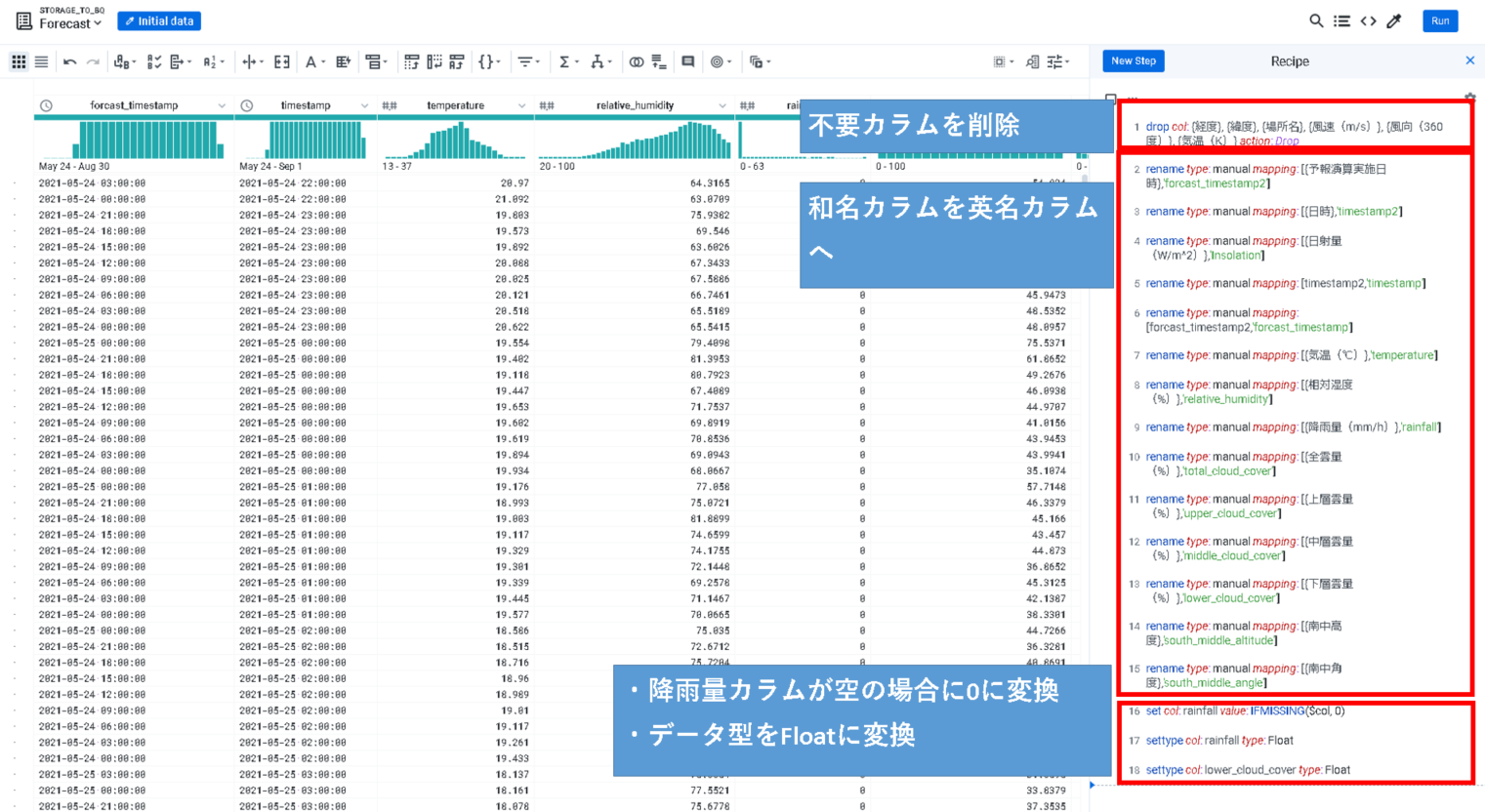
下の結合用のRecipeは、
・不要カラムを削除
・和名カラムを英名カラムへ変換
・降雨量カラムが空の場合に、0に変換
・Intで取り扱われる型をFloatに変換
しています。
日時と、予報演算日時は後で結合するキーになるので、残して置く必要があります。
この2つのRecipeを次のRecipeで結合します。
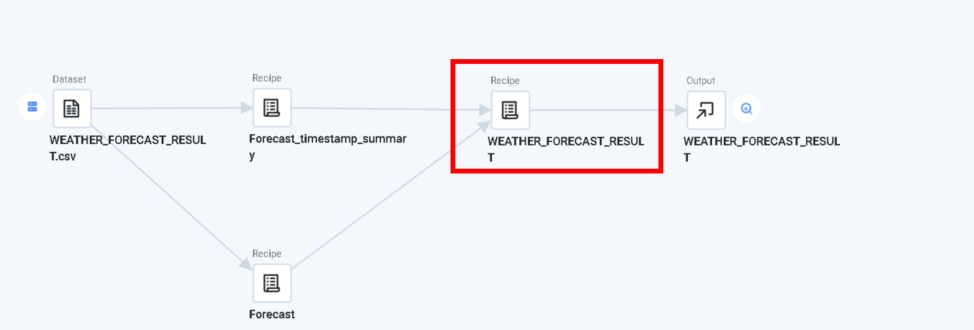
Recipe上では、
それぞれの対応するカラムをInner Joinします。
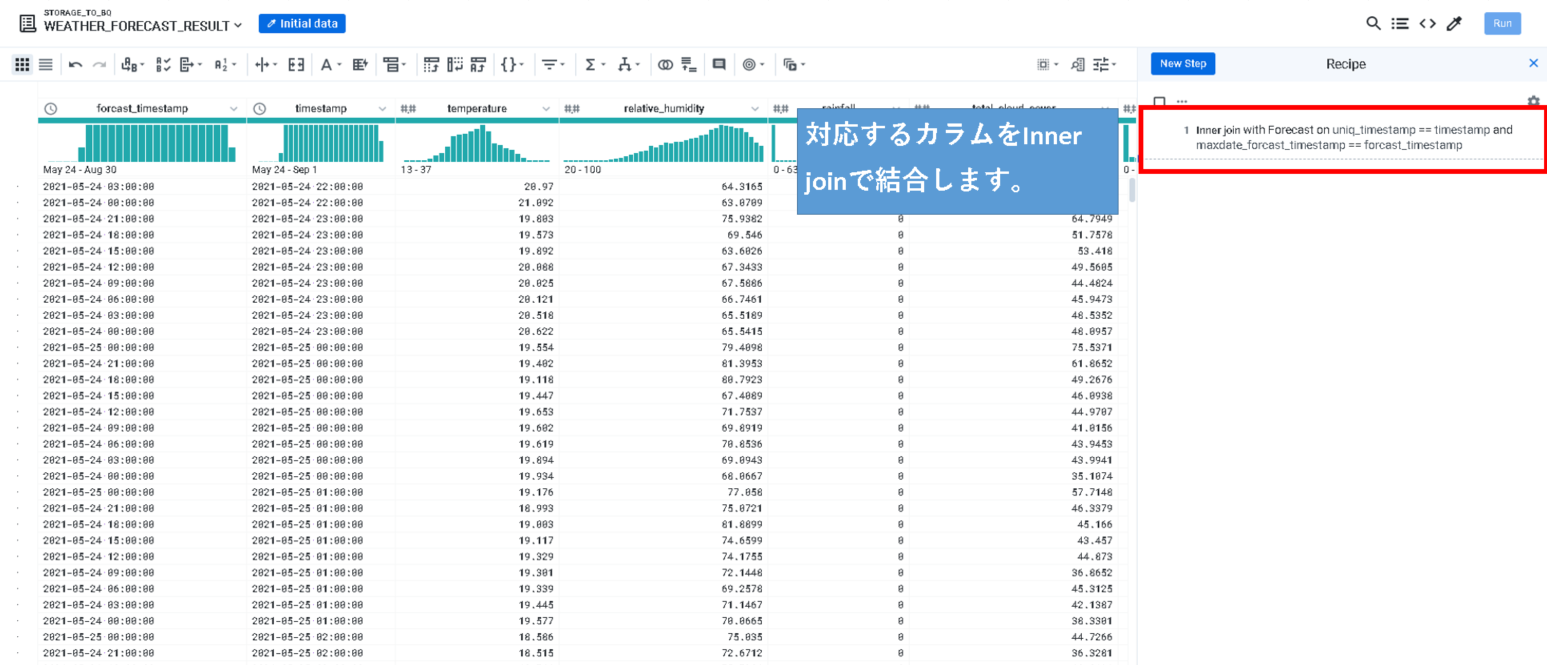
これをBigQueryにOutputすれば、テーブルが作成されます。
※事前にデータセットを作成しておく必要があります。
また、バックエンドでDataFlowが動作するため、CloudStorageやBigQueryのリージョンを一致させる必要があります。
##過去の発電実績ファイル(PV_FORECAST.csv )
・PV_FORECAST.csv
のデータは、発電電力量、計測日時のフォーマットになっています。
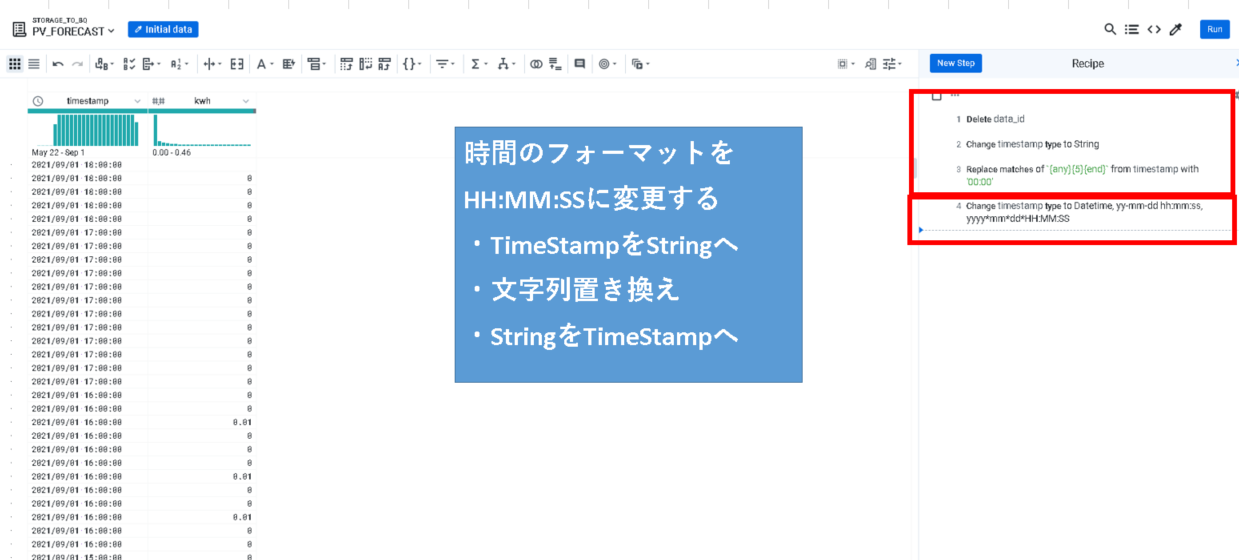
BigQuery上で気象予報データとの結合を想定し、時刻単位をあわせなければなりません。
つまり「YYYY/MM/DD HH:00:00」に変更する必要があるので、
・TimeStampをStringへ
・文字列置き換え「YYYY/MM/DD HH:00:00」
・StringをTimeStampへ変換
※型変換するときにタイムゾーンに注意
しています。
後は、BigQueryに格納すれば大丈夫です。
実際に、上記のRecipeでDataprepを実行すると、無事にテーブルができました!

次回は、このデータを元にBigQeuery MLで太陽光発電電力量を予測したいと思います。