kNN(k-nearest neighbor algorithm、k近傍法)の考え方
- 参考にしたもの:機械学習のエッセンスの第05章「機械学習アルゴリズム」
k近傍法とは
- 機械学習における、教師あり学習の手法
- 予測も分類もイケる
- 教師データを取り込んでおいて、予測(分類)したいモノの近くにある教師データをもとに予測(分類)する
考え方
- 教師データを取り込む(説明変数、目的変数の両方)
- 予測したいデータの説明変数を取り込む
- 予測したいデータの近くにある教師データから、目的変数を予測する
- 近く何個分の教師データを参考にするかは、手動で決める
- 近いデータと遠いデータで重みづけするかも、手動で決める
(「距離の種類」「近い点の探し方」とかもあるけど、一旦省略)
特徴
- 複雑な境界のデータにも適用可能
- 「データ数が小さい」「次元が小さい」場合に向いてる
- データ数が大きいと
- 距離が近いものを探すのに時間がかかる
- 学習データ保持に容量が必要になる
- 次元が高いと
- 未知データの近くに学習データが見つかりにくい
- データ数が大きいと
例
- とりあえず、超簡単に↓で考えてみる
- 説明変数は、それぞれの点の座標
- 目的変数は、**青=1、赤=-1**にしてある
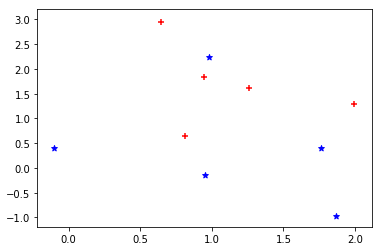
- ここに↓の緑の点が新しくできたとして、目的変数がどのくらいなのか予測する
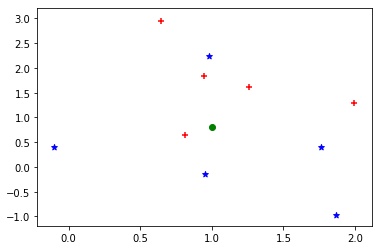
| 何個分を使うか | 重みづけ | 予測値 | コメント |
|---|---|---|---|
| 1 | - | -1 | 一番近くの赤(-1) |
| 3 | 平等 | -0.33 | 赤(-1)が2つ、青(1)が1つの平均 |
| 3 | 距離に反比例 | -0.64 | 青よりも近い赤が重視されてる |
| 5 | 平等 | -0.2 | 赤(-1)が3つ、青(1)が2つの平均 |
| 5 | 距離に反比例 | -0.48 | 青よりも近い赤を重視 |
参考にしたもの
図作ったときのコード置き場
- scikit-learnに放り込んだだけ: https://github.com/kzy611/qiita/blob/master/kNN_sample.ipynb