はじめに
やりたいこと
- スマホにしゃべるとメールやslackやlineやカレンダーに通知したい
- 基本的な使い方は関連記事を参照してください。
Node-REDのまとめ記事
動作環境
- IBM bluemix Node-RED : v0.20.5
免責事項
- 検証をして確実と思われる情報を載せておりますが、誤っている可能性もゼロではないので、参考程度にご利用ください
- 本来はコードと実行結果のコンソールログも載せるべきなのですが、数と量が多いので、一旦は画面イメージまでとさせてください。
本編
画面

処理の流れ
- 画面を開くとWebSocketを使ってサーバとの通信を確立
- ボタンを押すと音声を認識できる状態になる
- WebSpeechAPIを使って、ブラウザに向かって話した内容を文字列化
- 文字列をサーバに送る
- 文字列をもとに条件分岐などをして、送信先SNSと送るデータを決める
- SNSに送る
- 送った旨のメッセージをWebSocketを使ってブラウザに返す
- WebSpeechAPIを使って喋らせる
フロー
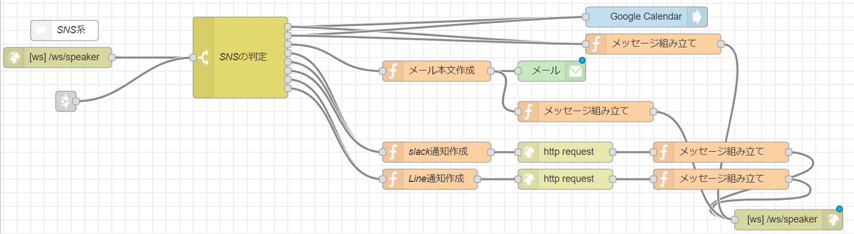
各SNSへのアクセス
実際はググると山程でてきますし、ここに書いてもすぐに古くなるので、各APIを参照ください。
一応いまいま時点でどんなことをしたのかは残しておきます
- slack : IncommingWebHookを使い実現。URLに対してデータを送っています
- Line : DeveloperのMessaging APIを使って実現。WebHookにデータを送っています
- メール:シンプルにメールのノードで実現。
- googleカレンダー:googleカレンダーのノードを使って実現。node-red-node-googleの指示に従い、アカウントとアクセス許可などを設定
補足
- 送る文章は
面倒なので文章全体。↑の例だと遅刻しますって LINE してとすべて送られます。 - カレンダーは今から1時間(デフォルト)でスケジュールが作成されるため、あまり実用的でないです。
- はっきり言って、Node-REDからみると文字列を受け取り、SNSに通知して、文字列を送り返しているだけです!
ブラウザ側の実装
このあたりを参考にさせていただきました
- [ブラウザで音声操作をする。(Speech Recognition API)] (https://qiita.com/PonDad/items/4ca433ad03efbf7499a2)
- Webページでブラウザの音声認識機能を使おう - Web Speech API Speech Recognition
本家の方とほとんど変わらないので、オリジナルの方を見ていただくほうが良いかと思いますが、一応重要な部分のソースです
ブラウザのhtml内のjs
const startBtn = document.querySelector('#start-btn');
const resultDiv = document.querySelector('#speak-text');
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
let recognition = new SpeechRecognition();
recognition.lang = 'ja-JP';
recognition.interimResults = true;
recognition.continuous = false;
let finalTranscript = '';
recognition.onresult = (event) => {
let interimTranscript = '';
for (let i = event.resultIndex; i < event.results.length; i++) {
let transcript = event.results[i][0].transcript;
if (event.results[i].isFinal) {
finalTranscript += transcript;
} else {
interimTranscript = transcript;
}
}
resultDiv.innerHTML = finalTranscript + '<i style="color:#ddd;">' + interimTranscript + '</i>';
}
// 文字列の送信
recognition.onend = (event) => {
recognition.stop();
const speakText = $("#speak-text").text()
sock.send(speakText);
}
// 開始ボタンのクリック
startBtn.onclick = () => {
speechSynthesis.cancel();
$('#status').text('please speak');
$("#speak-text").empty();
$("#response-text").empty();
finalTranscript = '';
recognition.start();
}
//Websocketの確立と各種イベント
var socketaddy = "wss://" + window.location.host + "/ws/speaker";
$(document).ready(function () {
sock = new WebSocket(socketaddy);
sock.onopen = function () {
$('#status').text('connected');
};
sock.onerror = function () {
$('#status').text('error');
};
sock.onclose = function () {
$('#status').text('closed please reload page!!')
}
sock.onmessage = function (evt) {
$('#status').text('response received');
$("#response-text").html(evt.data);
var speakText = $("#response-text").text();
// 発言を作成
const uttr = new SpeechSynthesisUtterance(speakText);
uttr.rate = 1.3;
uttr.lang = "ja-JP";
speechSynthesis.speak(uttr);
};
});
しゃべるデータをいったんhtmlにしてから取り出しているのは、 brタグ などを喋られないようにするためです(笑)
見栄えでは2行にしたいけど、タグを喋られると気持ちが悪いので。。。