この記事は、CPS Lab Advent Calendar 2018の12日目の記事です。
音声合成編 → https://qiita.com/hmmrjn/items/be29c62ba4e4a02d305c
はじめに
先週、研究室のアドベントカレンダー5日目で、Web Speech APIの使い方の記事を書いていたら、記事が長くなってしまって、音声合成だけで切り上げたので、この記事では続きの音声認識について触れていきたいと思います。
Web Speech API とは
先週の記事でも紹介しましたが、一応、もう一度紹介します。
- Webページで、ブラウザの音声認識(マイクの音声を文章に変換)、音声合成(文章を読み上げる)機能を使うためのAPI。
- 2012年にWC3から仕様が策定された。(ちなみに、Siriが登場したのは2011年。)
いいところ
- お金も、登録も、認証キーも一切いらない。
- 軽いJavaScriptの知識があれば誰でも使える。
- HTML/CSS/JSだけの静的ページでも動く。(ブラウザ上で動くので、バックエンドサーバは不要。)
- ブラウザのネイティブAPIなので、JavaScriptライブラリをインポートする必要もなし。
悪いところ
- 未だ、音声認識はChromeしか正式に対応していない...。
Demo
一見は百聞に如かず。
![]() Google の Demo ※ Chrome(Desktop/Android)のみ
Google の Demo ※ Chrome(Desktop/Android)のみ
ブラウザの対応状況
音声認識 (Speech Recognition)

https://caniuse.com/#feat=speech-recognition
2016年あたりから状況はほとんど変わってません...。
正式に対応してるのは、未だ Chrome (Desktop/Android) だけです。
それでも、人口の 64.99% が対応していることになるので、Chrome強し。
ただ、現状だと、iOS端末では使えないのは致命的です。 (iOS版Chromeは中身がSafariなので。)
技術的に難しいことなので、おそらく、OS (Windows/macOS/iOS) 自体が音声認識のAPIを作らない限り、すべてのブラウザが対応するのは難しいのかな?
一応、Firefoxは緑の旗がついてますね。
実は、 about:config の media.webspeech.recognition.enable フラグをオンにすれば使えるらしいですが、なぜか3年前からずっと正式な機能には格上げしていないみたいです...。![]()
ちなみに、Chromeが緑ではなく黄色(部分対応)になっている理由は、
webkit 接頭辞が必要だからみたいですね。(Hello World! 参照)。
正直、ほとんど緑のようなものです。
いつか、このAPIが他のブラウザでも実装されることを信じて、記事を書き進めていきたいと思います...。
一応、Firefox と Operaは In development 中らしいので、少しは前向きに書き進めます。詳細
Hello World!
対応状況でつべこべ言わずに、とにかくコードを触ってみましょう。解説はその後です。
<script>
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
const recognition = new SpeechRecognition();
recognition.onresult = (event) => {
alert(event.results[0][0].transcript);
}
recognition.start();
</script>
実行結果
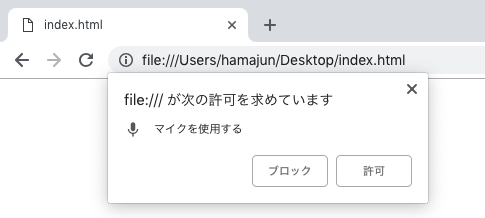
このhtmlファイルをブラウザで開くと、マイクの使用許可を求めるポップアップができてきます。
1年前の記事ではサーバ立てないといけないとか、HTTPSじゃないといけないとか書いてありましたが、私の場合、 index.html ファイルを chrome で開くだけでもいけました。
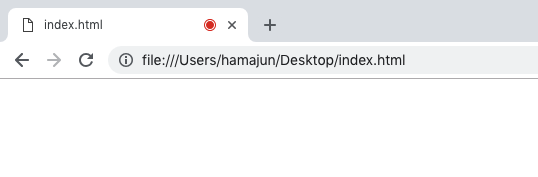
許可すると、タブの右側に録音中という意味の赤い丸が出てきます。
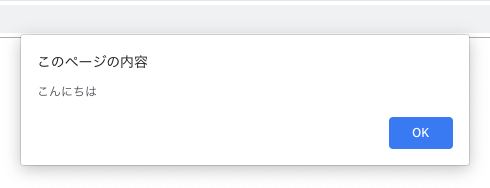
そこで、例えば「こんにちは」と発声すれば、認識された言葉がalertで出てきます。
録音は自動的に終了する。
解説
Chrome と Firefox 両方に対応する
Chromeの場合、webkit 接頭辞が必要なので、Chrome と Firefox 両方に対応するにはこうします。
window.SpeechRecognition = window.webkitSpeechRecognition || window.SpeechRecognition;
window. は省略できます。
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
対応確認
ブラウザが音声認識に対応しているかどうか確認したい場合は以下。
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
if ('SpeechRecognition' in window) {
// ユーザのブラウザは音声合成に対応しています。
} else {
// ユーザのブラウザは音声合成に対応していません。
}
返される結果の中身を覗いてみる
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
const recognition = new SpeechRecognition();
recognition.onresult = (event) => {
console.log(event);
}
recognition.start();
これで、recognition.start()が実行されると、マイクの使用の許可を求めるポップアップが現れるので、許可をして一言話しかけてみましょう。
話し終わったタイミングで、recognition.onresultが着火して、引数の event が渡されますのでその中身を一旦、console.log()してみましょう。
event.results[0][0].transcriptの中にありましたね。
recognition.interimResults 、または、 recognition.maxAlternatives プロパティをいじっていない場合は、認識結果が一つだけ、必ず、 [0][0] の中に入ってます。
よって、認識された文字列だけを取得したい場合は以下となります。
recognition.onresult = (event) => {
alert(event.results[0][0].transcript);
}
recognition.start();
言語を指定する
recognition.lang = 'ja-JP';
BCP 47言語タグの文字列で指定します。
- 日本語: ja-JP
- アメリカ英語: en-US
- イギリス英語: en-GB
- 中国語: zh-CN
- 韓国語: ko-KR
認識している途中にも結果を得る
デフォルトでは、発言が終わったタイミングで結果を取得しますが、
以下のように設定すれば、認識している途中で暫定の認識結果を得ることができます。
recognition.interimResults = true;
interim (インタラム): 【形】 暫定的、仮の
例えば、こうすると、
<script>
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
const recognition = new SpeechRecognition();
recognition.interimResults = true; // これこれ
recognition.onresult = (event) => {
console.log(event.results[0][0].transcript);
console.log(event.results[0].isFinal); // 発言が終了したかどうか。
}
recognition.start();
</script>
こんな結果が得られます。

認識しっぱなしにする
デフォルトでは、発言が終わったタイミングで録音が自動的に終了しますが、
以下のように設定すれば、勝手に終了することなく、続けて認識します。
ただ、1分くらい沈黙が続くと終了します。
recognition.continuous = true;
例えば、こんなコード、
<script>
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
const recognition = new SpeechRecognition();
recognition.continuous = true; // これこれ
recognition.onresult = (event) => {
console.log(event.results);
}
recognition.start();
</script>
「今アドベントカレンダーの記事を書いています。」(沈黙)「あと1時間しかないです。」(沈黙)と言ってみると、
こんな結果が得られます。
沈黙のタイミングで、結果が返ってきて、
最後の結果の中身はこうなりました。
event.results[0][0].transcript = "今アドベントカレンダーの記事を書いています"
event.results[1][0].transcript = "あと1時間しかないです"
いい感じのサンプルを作る
今までのやつを組み合わせて、実用的なサンプルを作ってみる。
<button id="start-btn">start</button>
<button id="stop-btn">stop</button>
<div id="result-div"></div>
<script>
const startBtn = document.querySelector('#start-btn');
const stopBtn = document.querySelector('#stop-btn');
const resultDiv = document.querySelector('#result-div');
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
let recognition = new SpeechRecognition();
recognition.lang = 'ja-JP';
recognition.interimResults = true;
recognition.continuous = true;
let finalTranscript = ''; // 確定した(黒の)認識結果
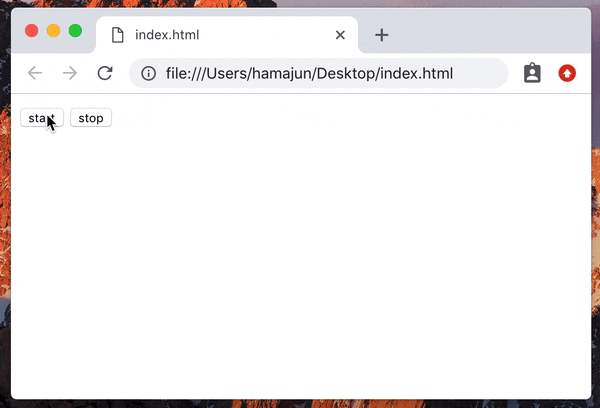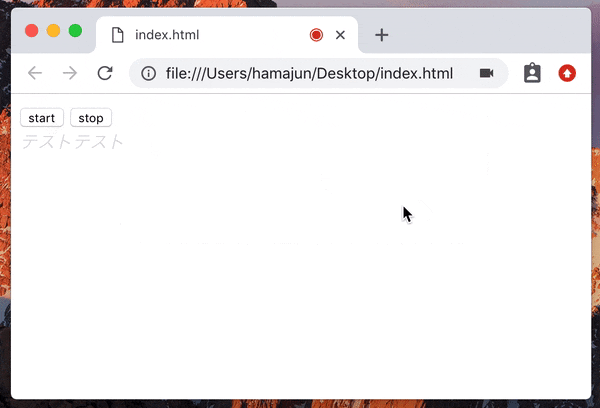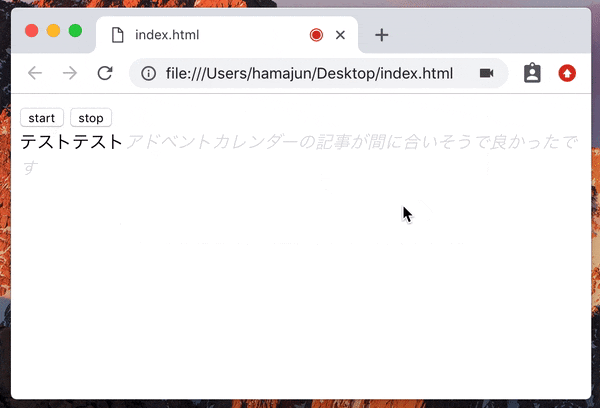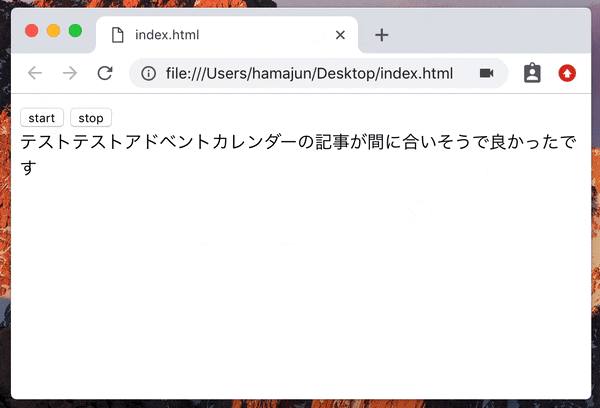
recognition.onresult = (event) => {
let interimTranscript = ''; // 暫定(灰色)の認識結果
for (let i = event.resultIndex; i < event.results.length; i++) {
let transcript = event.results[i][0].transcript;
if (event.results[i].isFinal) {
finalTranscript += transcript;
} else {
interimTranscript = transcript;
}
}
resultDiv.innerHTML = finalTranscript + '<i style="color:#ddd;">' + interimTranscript + '</i>';
}
startBtn.onclick = () => {
recognition.start();
}
stopBtn.onclick = () => {
recognition.stop();
}
</script>
マイクの許可について
-
 HTTPSの場合: 一度だけ聞かれる。
HTTPSの場合: 一度だけ聞かれる。 -
 HTTPの場合: 毎回聞かれる。
HTTPの場合: 毎回聞かれる。
細かいところ
細かいところは、こちらに詳しく書かれていますので、ご確認ください。
MDN Web Docs
https://developer.mozilla.org/en-US/docs/Web/API/SpeechRecognition
W3C Specification
https://w3c.github.io/speech-api/speechapi.html
SpeechRecognition
この記事で触れたものは太字にします。
プロパティ:
- recognition.grammars
- recognition.lang
- recognition.continuous (初期値: false)
- recognition.interimResults (初期値: false)
- recognition.maxAlternatives (初期値: 1)
- recognition.serviceURI
メソッド:
- recognition.abort()
- recognition.start()
- recognition.stop()
イベントハンドラ:
- recognition.onaudiostart
- recognition.onaudioend
- recognition.onend
- recognition.onerror
- recognition.onnomatch
- recognition.onresult
- recognition.onsoundstart
- recognition.onsoundend
- recognition.onspeechstart
- recognition.onspeechend
- recognition.onstart
おわりに
ぎりぎり、間に合ったぁー。
最近色々忙しかったので、ちょっと駆け足になってしまいましたが、間に合ってよかったです。
あとで、ブラッシュアップしたいと思います。
昨日の記事がまだ投稿されてなくて草。