はじめに
2020年度SQiP研究会(ソフトウェア品質管理研究会)で発表された「自然言語処理を利用した類似障害情報の抽出と活用方法の提案」の内容を写経してみました。
論文の付録として、ソースコードが掲載されているのは非常にありがたかったです。
論文のおかけで、Pythonで自然言語をベクトル表現に変換するプログラムを、写経で作れました。
論文の提案通りに作業を実施してみた結果、文書をベクトル表現したデータがEmbedding Projectorで表示され、文書の中から類似度の高い文が特定できました。
同じようなことを異なる表現で繰り返している箇所がわかるので、文書を推敲するために活用できる可能性があります。
参考論文
「ソフトウェア品質管理の研究-第36年度ソフトウェア品質管理研究会分科会報告書」,一般財団法人日本科学技術連盟,2021
上田良太,栗原崇至,杉本智,栗田太郎,徳本晋,石川冬樹,「自然言語処理を利用した類似障害情報の抽出と活用方法の提案」,第36年度ソフトウェア品質管理研究会,2021
https://www.juse.or.jp/sqip/workshop/report/attachs/2020/5_sku_ronbun.pdf
※SQiP研究会の成果報告会の資料の一覧
http://juse.or.jp/sqip/workshop/report/2020.html
使用する技術
- Python
- GiNZA
- Embedding Projector
https://projector.tensorflow.org/
※Embedding Projectorの参考記事
「Embedding projectorで類書の距離を可視化してみた」,2020
https://www.techceed-inc.com/engineer_blog/5729/
準備
参考サイト
準備手順
「Python入門」のサイトで示されている通りに以下を実施。
- 「Pythonインストールと環境設定」を実施。
- 「Pythonプログラムの基本事項」を写経。
既にPythonやAnacondaがインストールされているPCで以降の作業を実施しようとしたときに、うまくいかないことがあった。
pipでライブラリのインストールに失敗した。
※Windowsでpythonを利用しようとしたが上手くいかないときに、参考になるかもしれない記事
https://qiita.com/kaizen_nagoya/items/7bfd7ecdc4e8edcbd679
写経
論文の付録に掲載されているソースコードをもとに、以下のように写経(コピー&ペースト)でコーディングし、test.pyを作成。
# --------------------------------------------------------
# 【目的】
# GiNZA使って、複数のCSVテキスト文章から、
# 文章の長短、単語に依存しない文章ベクトルを生成し
# Embedding Projectorを使用して類似を表示させる。
# 【使用】
# トークナイザー(形態素解析)はGiNZA Model(V4.0.0)を使用。
# 【表示】
# Embedding Projector(http://projector.tensorflow.org/)
# 出力ファイル「basedoc_text.tsv」と
# GiNZAでの文章ベクトル「basedoc_vector_ginza.tsv」を使用し、
# PCA(T-SNEやUMAPなども選択する事も可)による次元圧縮を行い、
# COS類似度などを選択し3次元可視化する。
# --------------------------------------------------------
# ========================================================
import pandas as pd
import re
import torch
import ginza
import spacy
nlp = spacy.load('ja_ginza')
# =========================================================
# GiNZAによる形態素解析および文章ベクトル算出サブ処理
#
# 【解説】
# GiNZAによるトークナイズ(形態素解析)と併せて
# 同時に文章の長さに依存しないベクトルを生成する。
# GiNZAの次元数はデフォルトで300次元(V4.0.0)。
# <引数>
# text: 文章テキスト
# <戻り値>
# GiNZAによる300次元(V4.0.0)の文章ベクトル
# =========================================================
def compute_vector(text):
doc1 = nlp(text)
tokens = []
print("変換中===> ",doc1)
for sent in doc1.sents:
for token in sent:
tokens.append(token.orth_)
return doc1.vector # 文章の長さ(単語数(Token数)分)に依存しない 1x300次元のベクトルを生成
# =========================================================
# GiNZA文章ベクトル算出メイン処理
#
# 【解説】
# 複数のテキスト文章からGiNZAで文章の長さに依存しない文章ベクトルを出力します。
# COS類似度など、以降の類似計算に単語数に依存しない方法での計算に使用可能。
# <入力ファイル>
# basedoc.csv:
# 変換したい複数の原文をCSV形式で登録したもの
# <出力ファイル>
# basedoc_text.tsv:
# 以下のベクトルファイルに対応した原文ファイル
# basedoc_vector_ginza.tsv:
# GiNZAによる文章ベクトルデータ。1文章=300ベクトルデータで出力
# =========================================================
# 入力ファイル・出力ファイルの作業フォルダ(適切なフォルダパスを指定のこと)
work_folder = r'C:\Users\UserName\Documents\Python' + '\\'
basedocs_df = pd.read_csv(work_folder + 'basedoc.csv', encoding = "shift-jis")
basedocs_df["text"] = basedocs_df["text"].astype(str) # 文字列にしておく
vectors_ginza = []
basedocs = []
for basedoc in basedocs_df["text"]:
basedoc = re.sub('\n', " ", basedoc) # 改行文字の削除
strip_basedoc = re.sub(r'[︰-@]', "", basedoc) # 全角記号の削除
try:
if len(strip_basedoc) > 3: # 文字数が少なすぎると適切なベクトルが得られない可能性があるため
vector = compute_vector(strip_basedoc)
vectors_ginza.append(vector)
basedocs.append(basedoc)
except Exception as e:
continue
# TSVファイル出力
pd.DataFrame(basedocs).to_csv(work_folder + 'basedoc_text.tsv', sep='\t', index=False, header=None)
pd.DataFrame(vectors_ginza).to_csv(work_folder + 'basedoc_vector_ginza.tsv', sep='\t', index=False, header=None)
以下の2点だけ、論文のサンプルコードから変えました。
-
work_folderの位置 -
read_csvの使い方
変更前
basedocs_df = pd.read_csv(work_folder + 'basedoc.csv')
変更後
basedocs_df = pd.read_csv(work_folder + 'basedoc.csv', encoding = "shift-jis")
入力ファイル作成
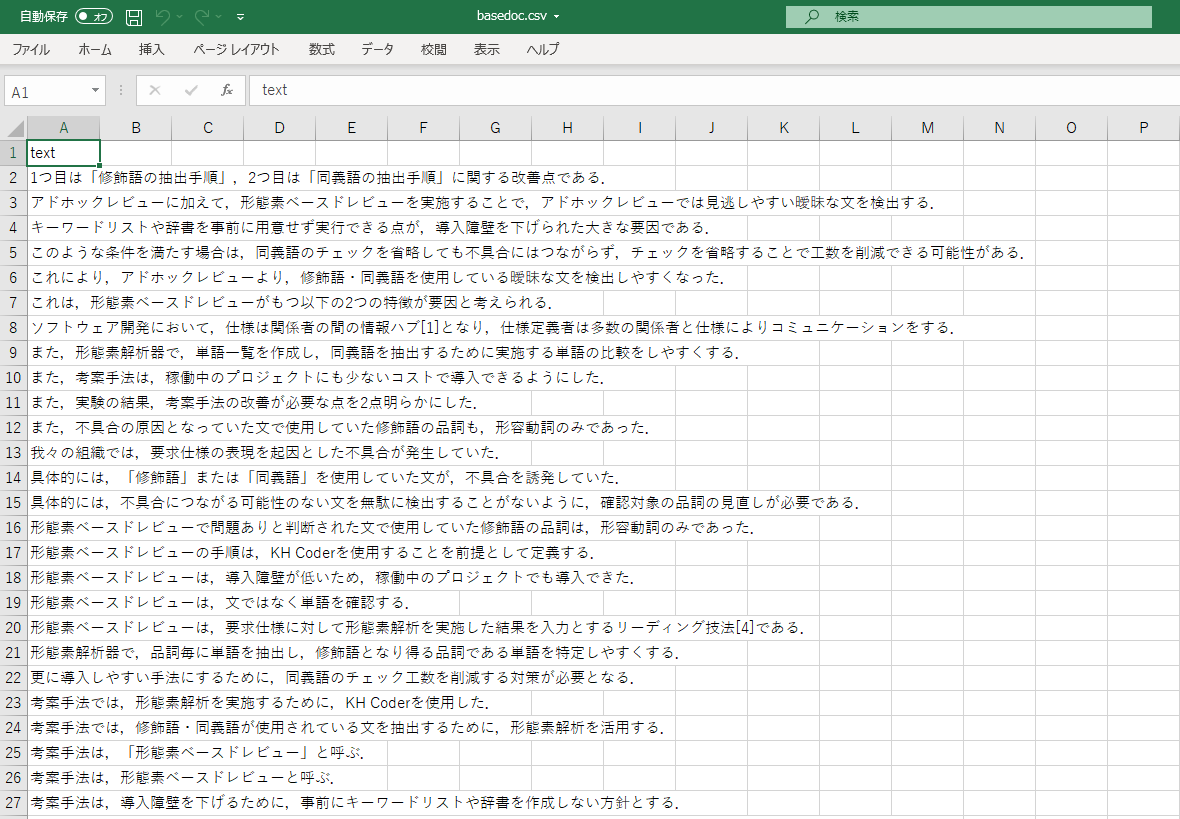
Execlで、basedoc.csvという名前の入力ファイルを作成する。
- 1行目は、
textという固定文言。 - 2行目以降は、ベクトル表現したい文
作成した入力ファイルは、work_folderに格納する。
入力ファイルのイメージ
実行(ベクトルデータ生成)
Anaconda Promptを起動させ、以下を実行する。
1. ライブラリのインストール
>pip install pandas
>pip install torch
>pip install ginza
>pip install spacy
2. Pythonを対話モードで起動し、利用するライブラリが無事インストールできているか確認
>>> import pandas as pd
>>> import re
>>> import torch
>>> import ginza
>>> import spacy
確認後は、Ctrl+Zで対話モードを終了する。
3. プログラムの実行
cdコマンドで、test.pyのあるフォルダに移動する。
test.pyを実行する。
>python test.py
basedoc_text.tsvとbasedoc_vector_ginza.tsvがbasedoc.csvを格納していたフォルダに生成されていたら成功。
これで、文書をベクトル表現したデータが生成できる。
Embedding projectorの入力となるベクトルファイル(basedoc_vector_ginza.tsv)およびテキストファイル(basedoc_text.tsv)が生成できる。
実行(Embedding projectorで文の類似度を可視化)
論文の付録に掲載されているEmbedding projector使用手順を参考に操作。
1. Embedding projectorの起動
以下サイトでEmbedding projectorを起動する。
https://projector.tensorflow.org/
2. ベクトルファイル(basedoc_vector_ginza.tsv)およびテキストファイル(basedoc_text.tsv)を読み込む
Loadボタンをクリックする。
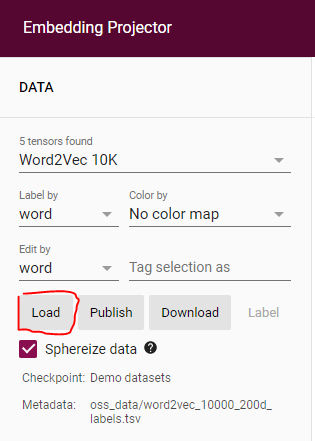
表示しされたダイアログで、生成したベクトルファイル(basedoc_vector_ginza.tsv)およびテキストファイル(basedoc_text.tsv)を選択する。
以下の図の、上にベクトルファイルを設定し、下にテキストファイルを設定する。
ファイルを指定したら、適当なところをクリック。
以下の図のような3次元表現の図が表示される。
適当な丸を選択すると、以下のような表示がされる。

分析
論文では、以下の考察が述べられている。
実験結果から,類似度(cosine 距離)が 0.3 以下は類似障害として一致する確率が高い(約 73%(19/24))ことが分かるため,類似度の閾値として活用できるのではないかと考える.
実際に、今回の実験データでも、cosine 距離が0.3以下の文は、類似度が高いと判断してよさそうである。

以下の2つの文のcosine 距離は、0.187であった。
- 実際に我々の組織では,「修飾語」または「同義語」を使用している文が不具合を誘発していた.
- 具体的には,「修飾語」または「同義語」を使用していた文が,不具合を誘発していた.
類似度が高い文を特定できるため、同じことを別の表現で繰り返している箇所について、見直しをかけることが可能となる。
今回の論文で提案されている技術は、文書を推敲するためにも活用できる可能性がある。
おわりに
貴重な論文を執筆していただいた 2020年度SQiP研究会研究コース5の上田良太様、栗原崇至様、杉本智様に感謝の意を表します。
ありがとうございました。