この記事はMLOps Advent Calendar 2020の17日目の記事です。
もともとはGoogle Cloudからもうすぐ出てくる予定のFeature Storeの紹介でも書こうかと思ったのですが、まだ出てこないな...と思ってたら、Google Cloud ソリューションアーキテクトの中井さん(@enakai00)がいい感じのサーバレスMLOpsソリューションをタイミングよく公開されてたので、紹介させていただくことにしました。
できた。https://t.co/COMDamTMQb
— E. Nakai (@enakai00) December 14, 2020
This example shows how you can use Cloud Run and Cloud Workflows to create a simple ML pipeline. The ML usecase is based on the babyweight model example. https://t.co/S2oHVF9pfy
なぜサーバレスMLOpsか?
サーバレスMLOpsって言葉、中井さんのツイートを見て思いついたのですが、もうどこかで使われてますかね? なぜサーバレスにしたいかという前提として、中井さんも書かれてた「k8s/GKEはそれほど手軽じゃない」問題があります。
kubeflow pipelines とかだと、k8s の基盤を常時持つ必要がありますが、このやり方だと、必要な時だけ Cloud Run のインスタンスが立ち上がって、バックエンドのジョブも dataflow / AI Platform などのサーバーレスを使っているので、何もしてない時は、本当に何もありません。
— E. Nakai (@enakai00) December 14, 2020
そこそこの規模の実運用環境であれば、AI Platform Pipelines(Kubeflow Pipelinesのマネージドサービス)がGoogle Cloudにおける定番のMLOps基盤になります。とはいえ、これ下はGKE(マネージドk8s)で動いてます。つまり、VMを起動しておく必要があり、一定額のコストが発生します。
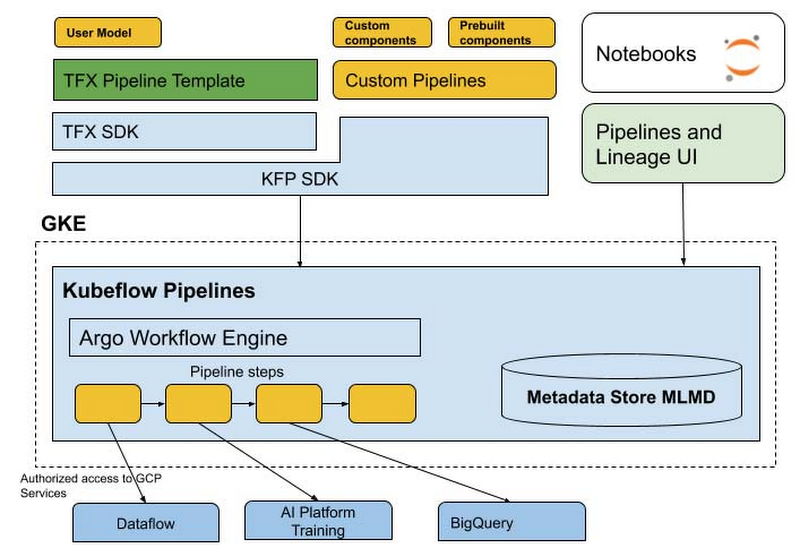
AI Platform Pipelinesの構成
そこまでの規模も予算もないよ、って用途におすすめしたいのがサーバレスMLOpsです。中井さんが提案されたソリューションのように、Google CloudであればCloud Runを使ってすべてをサーバレスで構築すれば、パイプラインを起動してないときはインスタンス代も発生しない(ストレージ代のみ)、というお手軽MLOpsが実現できます。あ、インスタンス止めるの忘れてた! 課金されてた...って残念なことも起きません。

サンプルの概要
中井さんが公開されたサンプルworkflows-ml-pipeline-exampleはこんな構成になっています。
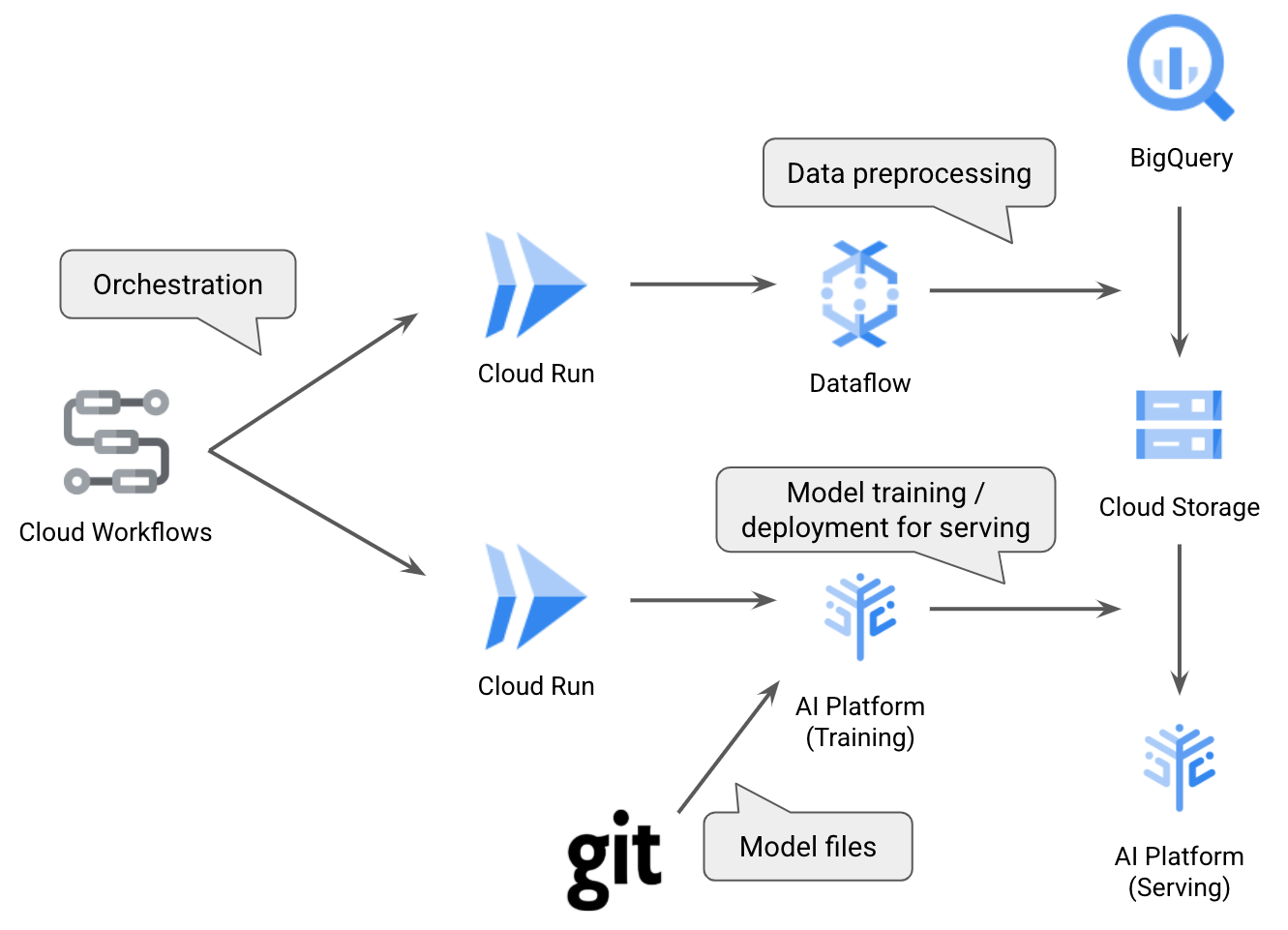
このサンプルの例では、babyweightという赤ちゃんの体重を予測する既存のモデルをパイプライン化しています。大きく分けると、
- 上段:BigQueryからデータを取得、Cloud Dataflowで前処理してCloud Storageに保存
- 下段:AI Platform Trainingでモデル学習、AI Platform Predictionにデプロイ
という2段階のパイプラインになっており、各段階をCloud Runで実行します。またサンプルの後半では、この前処理と学習のオーケストレーションをCloud Workflowsで自動化する例も出てきます。
Cloud Runを動かしてみた
GCPプロジェクトを用意して、READMEに記載されているサンプルコードをコピペしていくだけですんなり動きました。PROJECT_IDに自分のプロジェクトIDをセットし、あとは他の環境変数の設定やGCSバケットの作成、そして関連するAPIを有効に設定して、サンプルコードをcloneします。
Cloud Dataflowで前処理
で、まずは前処理を実行するCloud Runのコンテナイメージをビルドします。
gcloud builds submit --tag gcr.io/$PROJECT_ID/preprocess-service
このコンテナイメージには、サンプルに用意された以下のような前処理のコードが組み込まれます。
def preprocess(limit, output_dir, job_name, region):
options = {
'region': region,
'staging_location': os.path.join(output_dir, 'tmp', 'staging'),
'temp_location': os.path.join(output_dir, 'tmp'),
'job_name': job_name,
'project': PROJECT_ID,
'max_num_workers': 3, # CHANGE THIS IF YOU HAVE MORE QUOTA
'setup_file': './setup.py'
}
opts = beam.pipeline.PipelineOptions(flags=[], **options)
RUNNER = 'DataflowRunner'
p = beam.Pipeline(RUNNER, options=opts)
query = """
SELECT
weight_pounds,
is_male,
mother_age,
plurality,
gestation_weeks,
FARM_FINGERPRINT(CONCAT(CAST(YEAR AS STRING), CAST(month AS STRING))) AS hashmonth
FROM
publicdata.samples.natality
WHERE year > 2000
AND weight_pounds > 0
AND mother_age > 0
AND plurality > 0
AND gestation_weeks > 0
AND month > 0
"""
if limit:
query = query + ' LIMIT {}'.format(limit)
for step in ['train', 'eval']:
if step == 'train':
selquery = 'SELECT * FROM ({}) WHERE ABS(MOD(hashmonth, 4)) < 3'.format(query)
else:
selquery = 'SELECT * FROM ({}) WHERE ABS(MOD(hashmonth, 4)) = 3'.format(query)
(p
| '{}_read'.format(step) >> beam.io.Read(beam.io.BigQuerySource(query=selquery, use_standard_sql=True))
| '{}_csv'.format(step) >> beam.FlatMap(to_csv)
| '{}_out'.format(step) >> beam.io.Write(beam.io.WriteToText(os.path.join(output_dir, '{}.csv'.format(step))))
)
return p.run()
この前処理では、BigQueryでクエリを実行してデータを読み込み、欠損値(超音波診断結果がない場合)の対応や文字列変換、trainとevalへの分割等を行っています。
Cloud Runは、この前処理ジョブの起動をRESTで受け付けるエンドポイントとして動きます。そのために、このサンプルでは以下のようなコードを用いています。
@app.route('/api/v1/preprocess', methods=['POST'])
def preprocess():
<...snip...>
result = pipe.preprocess(limit, output_dir, job_name, region)
resp = {'jobName': job_name,
'jobId': result.job_id(),
'outputDir': output_dir}
return resp, 200
Cloud Runでは、こんなふうにアノテーションを使ってエンドポイントURIと関数をマッピングできます。この例では、上述のDataflowコードpipe.preprocessを呼び出しているのが分かります。
このコンテナイメージのビルドが終わったら、Cloud Runにデプロイします。
gcloud run deploy preprocess-service \
--image gcr.io/$PROJECT_ID/preprocess-service \
--platform=managed --region=us-central1 \
--no-allow-unauthenticated \
--memory 512Mi \
--set-env-vars "PROJECT_ID=$PROJECT_ID"
サーバレスなので、この段階ではインスタンスは生成されません。
Kerasで学習
同様にして、学習用のコンテナイメージもビルドします。これには以下のようなKerasのモデルが組み込まれます。
def create_keras_model(learning_rate=0.001):
wide, deep, inputs = get_wide_deep()
feature_layer_wide = layers.DenseFeatures(wide, name='wide_features')
feature_layer_deep = layers.DenseFeatures(deep, name='deep_features')
wide_model = feature_layer_wide(inputs)
deep_model = layers.Dense(64, activation='relu', name='DNN_layer1')(feature_layer_deep(inputs))
deep_model = layers.Dense(32, activation='relu', name='DNN_layer2')(deep_model)
wide_deep_model = layers.Dense(1, name='weight')(layers.concatenate([wide_model, deep_model]))
model = models.Model(inputs=inputs, outputs=wide_deep_model)
# Compile Keras model
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=learning_rate))
return model
このモデルでは、母親の年齢や妊娠週といった連続値は3層のMLPに入れ、性別や胎児数といったカテゴリ値は1層のNNに入れるという設計になっています。
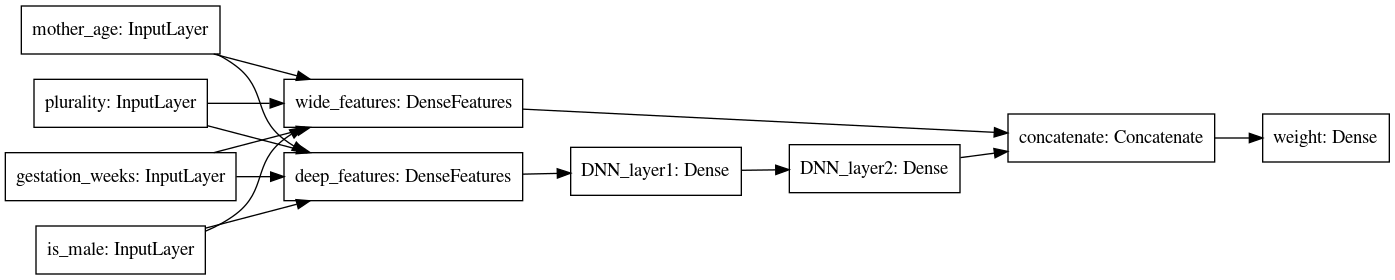
このモデルに対して先程の前処理でCloud Storageに保存した学習データを使い学習を行いたいわけですが、そのためのCloud Runのエンドポイント定義は以下のようになります。
@app.route('/api/v1/train', methods=['POST'])
def train():
json_data = request.get_json()
scale_tier = 'BASIC_GPU'
region = 'us-central1'
runtime_version = '2.2'
python_version = '3.7'
data_dir = None
job_dir = None
num_train_examples = '60000000'
num_eval_examples = '50000'
num_evals = '100'
learning_rate = '0.0001'
<...snip...>
training_inputs = {
'scaleTier': scale_tier,
'packageUris': [package],
'pythonModule': 'trainer.task',
'region': region,
'jobDir': job_dir,
'runtimeVersion': runtime_version,
'pythonVersion': python_version,
'args': [
'--data-dir', data_dir,
'--num-train-examples', num_train_examples,
'--num-eval-examples', num_eval_examples,
'--num-evals', num_evals,
'--learning-rate', learning_rate
]
}
job_spec = {'jobId': job_id, 'trainingInput': training_inputs}
credentials = GoogleCredentials.get_application_default()
api = discovery.build(
'ml', 'v1', credentials=credentials, cache_discovery=False)
api_request = api.projects().jobs().create(
body=job_spec, parent='projects/{}'.format(PROJECT_ID))
resp = None
try:
resp = api_request.execute()
except googleapiclient.errors.HttpError as err:
resp = {'message': err._get_reason()}
return resp, 500
return resp, 200
ここでは、Google Cloudが提供するマネージドのML学習環境であるAI Platform Trainingを呼び出しています。学習に使う計算リソースやリージョン、学習率等のパラメータを渡して、学習ジョブを開始してるのがなんとなく分かるかと思います。
この学習用のコードも、前処理コードと同様にコンテナイメージにビルドし、Cloud Runにデプロイします。Cloud Runのコンソールを見ると、それぞれのCloud Runエンドポイントがデプロイされていることが確認できます。
テスト
この状態で、前処理と学習のそれぞれのCloud Runエンドポイントを叩いてテストできます。まずは前処理の方。
curl -X POST -H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: application/json" \
-d "{\"limit\":\"1000\", \"outputDir\":\"$BUCKET/preproc\"}" \
-s $PREPROCESS_SERVICE_URL/api/v1/preprocess | jq .
このジョブが完了すると、Cloud Storageのバケットには前処理済みの学習データが保存されます。
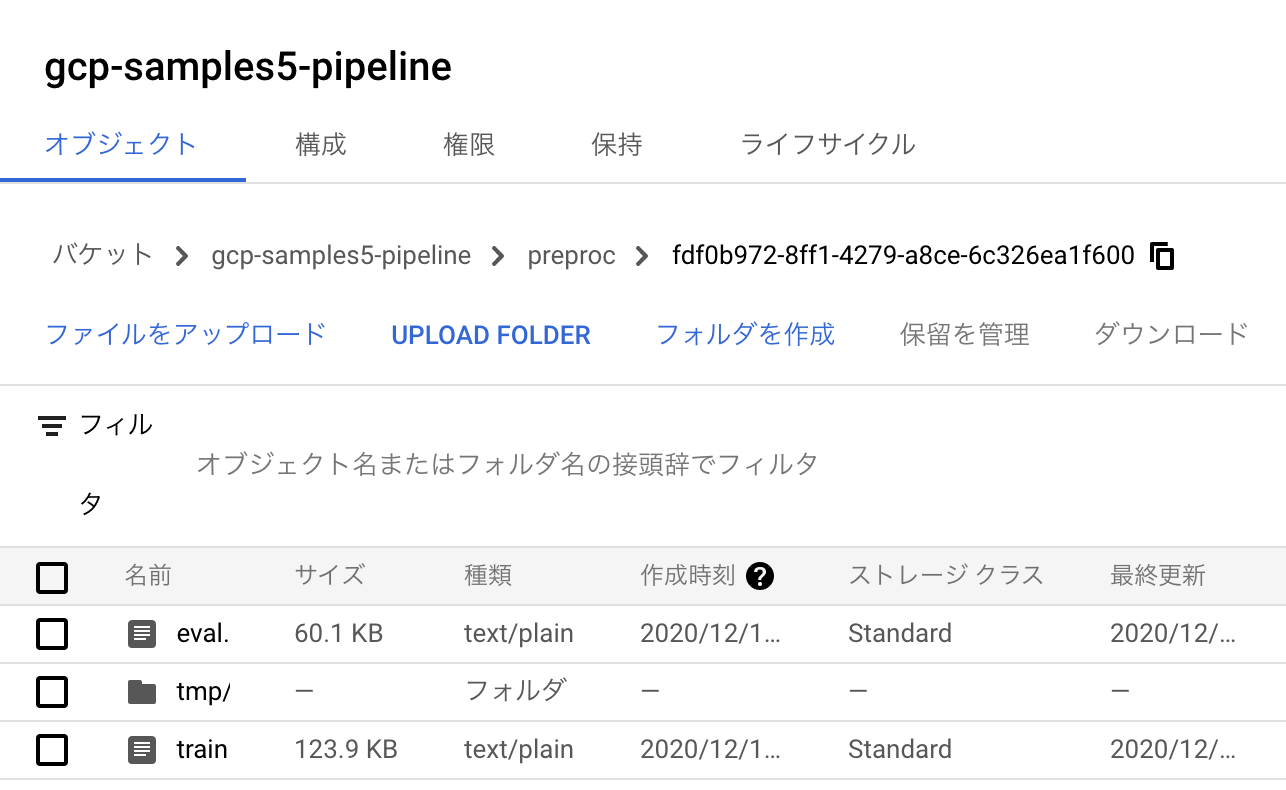
つづいて、同様にして学習のエンドポイントも叩きます。学習ジョブが完了すると、AI Platformのモデルコンソールでは作成されたモデルの詳細を確認できます。
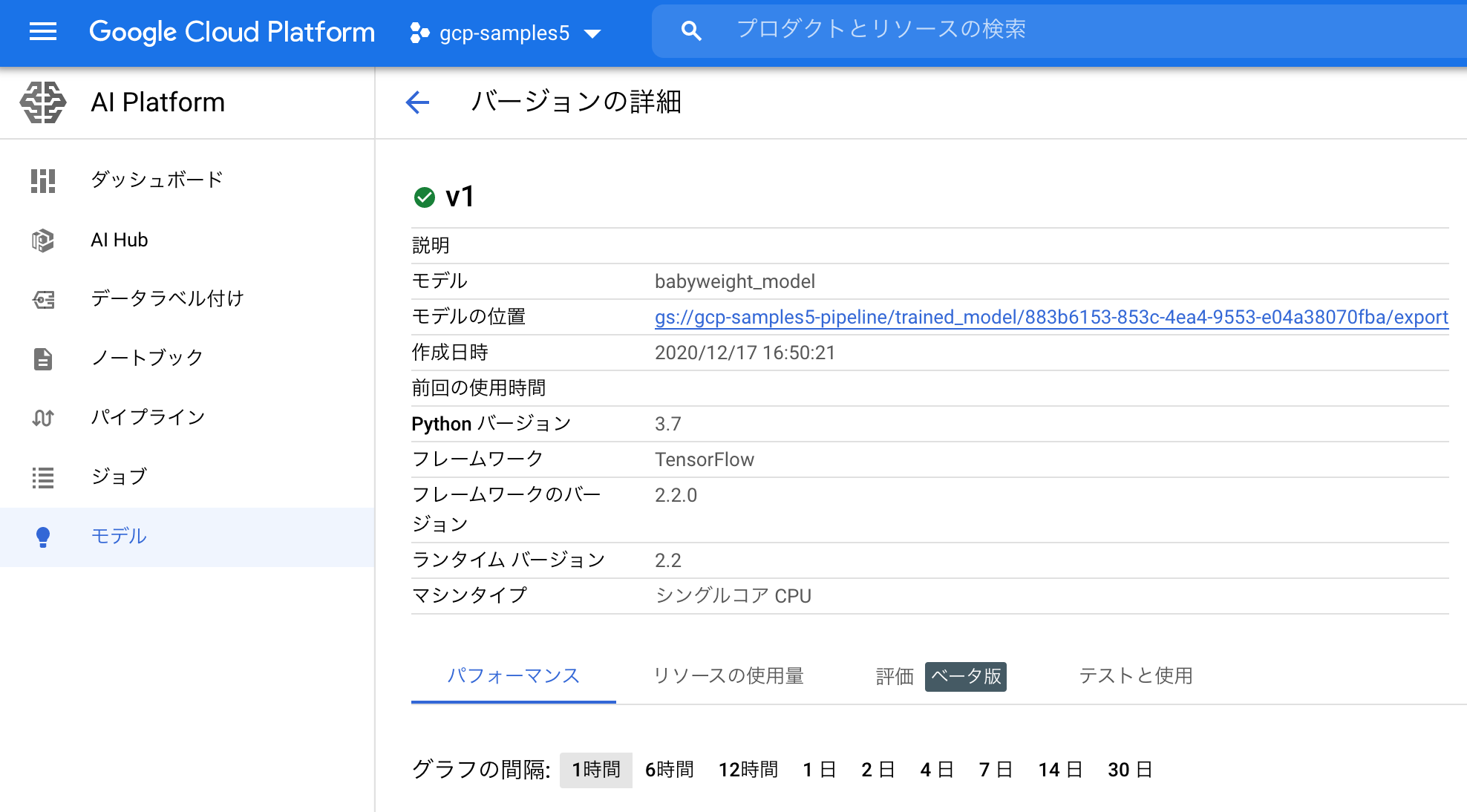
Cloud Workflowsでサーバレス オーケストレーション
さて、ここまではCloud Runを使ってVMを立てずに前処理や学習を起動する方法について見てきました。中井さんのサンプルコードでは、これらを組み合わせるパイプライン構築もサーバレスに実現されています。
このオーケストレーションには、サーバレス ワークフローツールであるCloud Workflows(ベータ版)を使用します。

Google CloudではCloud Composerというワークフローツールがすでに提供されていますが、ComposerはGKEの上にApache Airflowを載せる構成。一方、Workflowsはサーバレス実装となっており、Cloud Runと同様のお手軽感でオーケストレーションを実装できる新サービスです。このWorkflowsについてはYuttyさんによる日本語解説がありますので、合わせてご覧ください。
今回のサンプルコードでは、以下のようなYAMLファイルでワークフローが定義されています。
main:
params: [args]
steps:
- assignLimit:
steps:
- assignDefault:
assign:
- limit: null
- assignArgVal:
switch:
- condition: ${"limit" in args}
assign:
- limit: ${args.limit}
- preprocessData:
call: http.post
args:
url: PREPROCESS-SERVICE-URL/api/v1/preprocess
body:
"limit": ${limit}
"outputDir": ${args.bucket + "/preproc"}
auth:
type: OIDC
result: preprocess
- sleepPreprocess:
call: sys.sleep
args:
seconds: 60
- getPreprocessStatus:
call: http.get
args:
url: ${"PREPROCESS-SERVICE-URL/api/v1/job/" + preprocess.body.jobId}
auth:
type: OIDC
result: preprocessStatus
- waitPreprocess:
switch:
- condition: ${preprocessStatus.body.currentState == "JOB_STATE_DONE"}
next: trainModel
- condition: ${preprocessStatus.body.currentState == "JOB_STATE_FAILED"}
return: ${preprocessStatus.body}
next: sleepPreprocess
- trainModel:
call: http.post
args:
url: TRAIN-SERVICE-URL/api/v1/train
body:
"jobDir": ${args.bucket + "/trained_model"}
"dataDir": ${preprocess.body.outputDir}
"numTrainExamples": ${args.numTrainExamples}
"numEvalExamples": ${args.numEvalExamples}
"numEvals": ${args.numEvals}
auth:
type: OIDC
result: train
- sleepTrain:
call: sys.sleep
args:
seconds: 60
- getTrainStatus:
call: http.get
args:
url: ${"TRAIN-SERVICE-URL/api/v1/job/" + train.body.jobId}
auth:
type: OIDC
result: trainStatus
- waitTrain:
switch:
- condition: ${trainStatus.body.state == "SUCCEEDED"}
next: deployModel
- condition: ${trainStatus.body.state == "FAILED"}
return: ${trainStatus.body}
next: sleepTrain
- deployModel:
call: http.post
args:
url: TRAIN-SERVICE-URL/api/v1/deploy
body:
"modelName": ${args.modelName}
"versionName": ${args.versionName}
"deploymentUri": ${train.body.trainingInput.jobDir + "/export"}
auth:
type: OIDC
result: deploy
- finish:
return: ${deploy.body}
上から眺めていけば、前処理→学習→デプロイという流れになっており、それぞれでCloud Runのエンドポイントを呼び出してるのが分かるかと思います。このワークフローも、コンソール上で詳細や実行結果を確認できます。
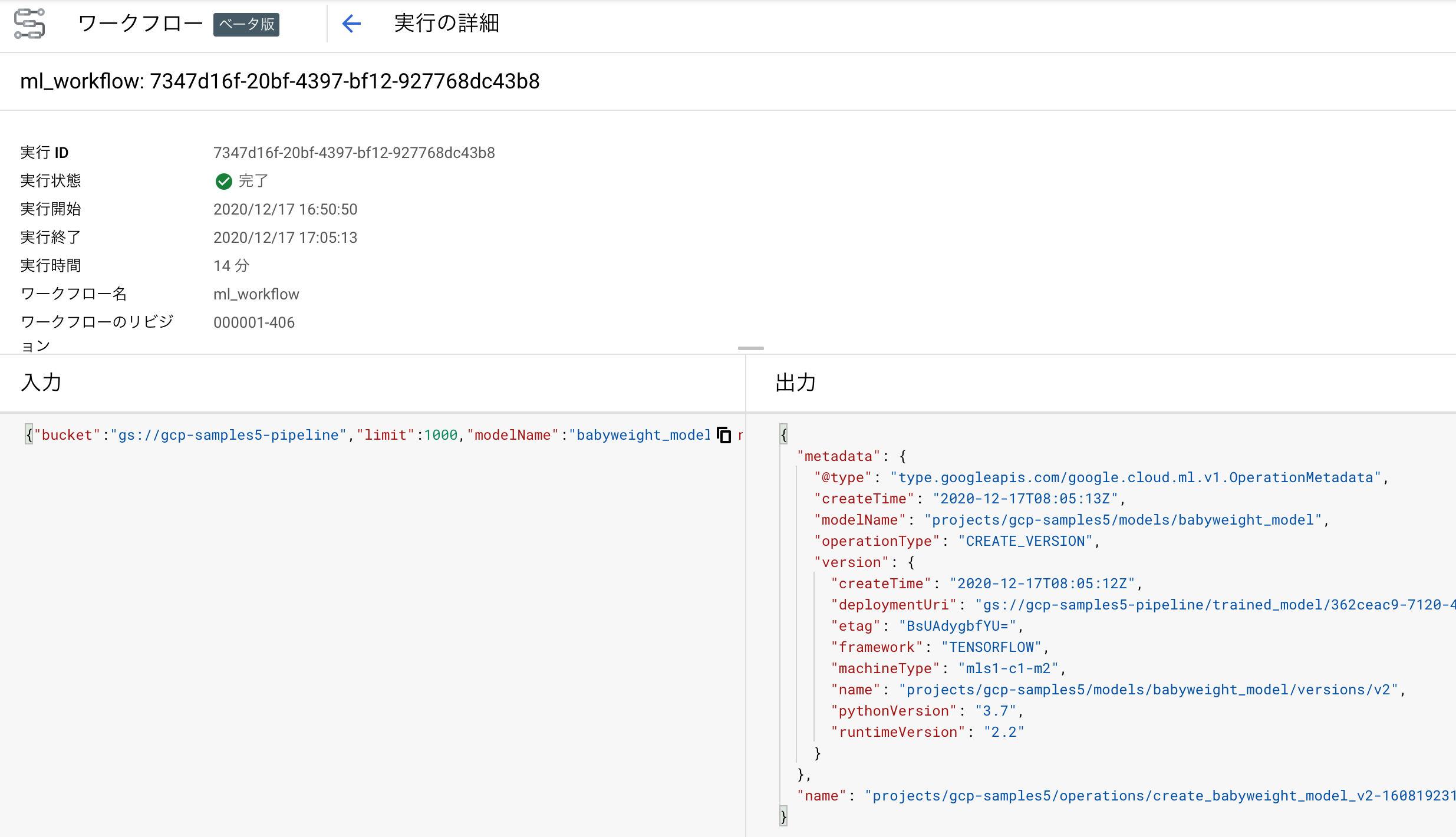
AI Platform Pipelines(Kubeflow Pipelines)のように、かっこいいUIでワークフロー表示したりメタデータや実験結果を管理したり...といった機能はありませんが、とりあえず前処理して学習してデプロイ、という流れの自動化にさくっと使えそうです。
まとめ
以上、中井さんが公開されたサンプルコードを見ながら、Google CloudでつくるサーバレスMLOps環境について解説しました。Google Cloudの魅力はなんといってもgVisorに基づくさまざまなサーバレス環境にあるので、今後はこうしたサーバレスなML開発&運用環境がどんどん増えてくるものと期待しています。
Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。