この記事はMLOps Advent Calendar 2021の18日目の記事です。
2016年にもTensorFlowとMLサービスの2016年の布教活動報告を書きましたが、ここ3年くらいはMLOps系の活動をメインにしてきたので、その報告です。COVID後はイベント登壇も減り、ブログ記事の執筆が多くなりました。その裏話的な内容です。
Feature Store のブログ記事
今年5月のGoogle I/OでVertex AIのMLOps系プロダクトがいくつかリリースされたので、その後にフォローアップのブログ記事を出し始めました。まずは6月にPMのAnandと書いた
Kickstart your organization’s ML application development flywheel with the Vertex Feature Store(日本語版)です。
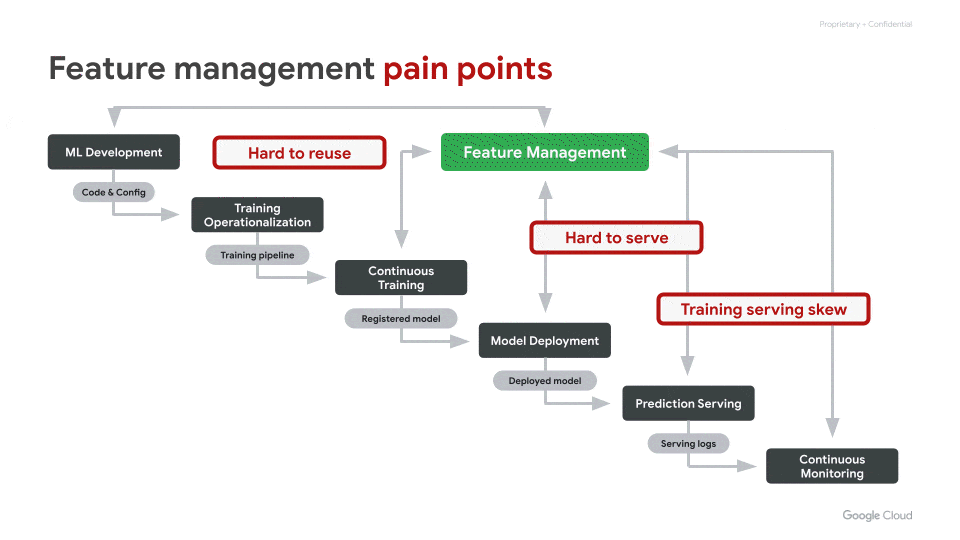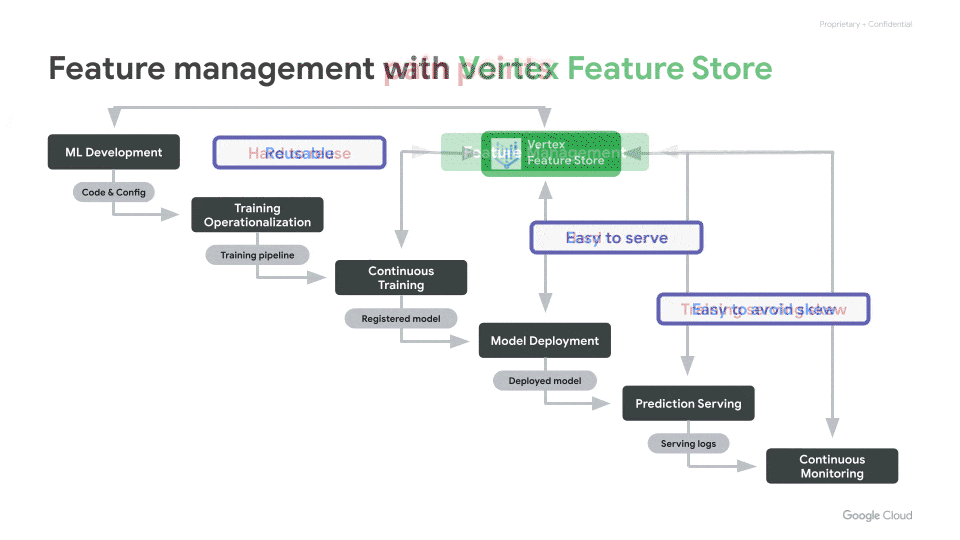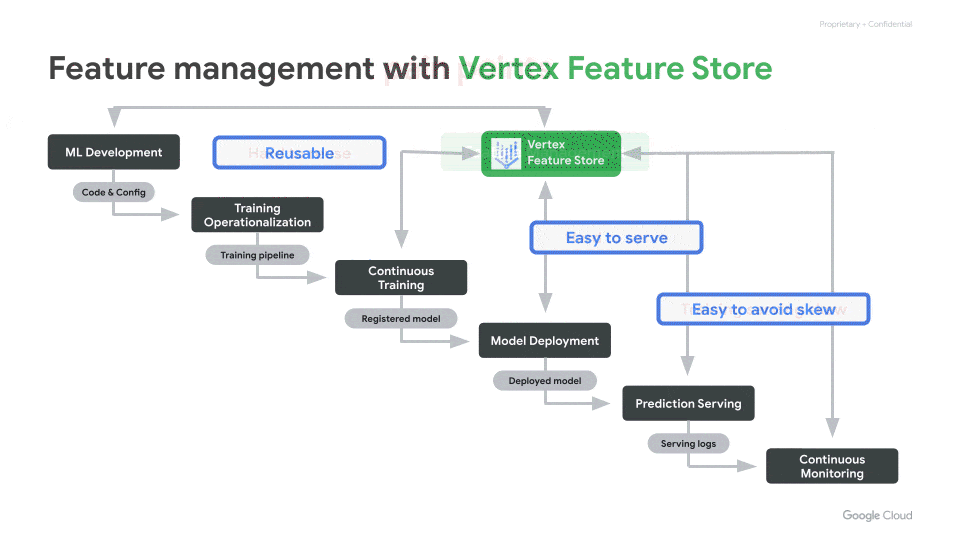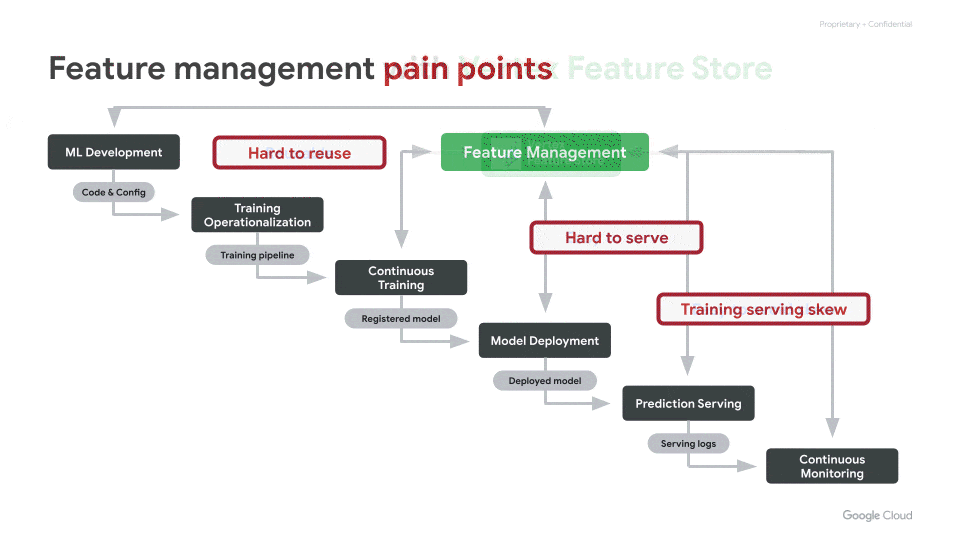
このプロダクトは、企業内で共有可能な特徴量のリポジトリを構築することで、
- 異なるプロジェクトやチーム間で特徴量を再利用したい
- 特徴量をオンライン推論で簡単に使いたい
- Training-serving Skewを減らしたい
といった課題を解決することを目指しています。
詳細はブログ記事を見ていただくとして、個人的には、
- PMのAnandとじっくり議論しながら記事を仕上げた
- After Effectを初めて使った
ってところが思い出深いです。Developer Advocateは何もしないと何も仕事がこないので、インパクトを出すにはプロダクトチームやCE/Sales、マーケ等々のx-funcチームとの連携が重要です。でも、それらの人達は2〜3年で入れ替わることが多く、つねに入れ替わる新しい人たちと信頼関係を築くのが一苦労。その度に社内営業的なムーブも必要です。
Feature StoreのPMのAnandも、最初は私に対する対応も(誰だこいつ...)って感じでしたが、この記事執筆でじっくり議論したことで今ではしっかり信頼関係を結ぶことができました(もっとも、これを3年おきくらいに繰り返さないといけないのですけど…しかも拙い英語&東京からってのがハンデ)。
それと、やはり今の時代、何らかのアイディアを短い時間で、できればTwitterの埋め込み動画等ですばやく伝えるには、After Effectsを勉強せねばなあ〜とずっと思ってたので、この記事から拙いながらもAEでアニメーションを作り始めました。こんな感じ:

このタマタマを思い通りに動かすためにかなり時間がかかりました :) でも、こうして動画を作っておくと、ブログだけでなくそのSNS展開、そしてセッション発表時のスライド等で使い回せるので、重宝するんです。デモ環境もいらない。なにより、こういう素材を外注せずに自分ですぐに作れるのがラクなんです。予算確保したり何週間か待ったり細かい修正入れたりしなくていい。公開直前にちょっと直したい、って時もすぐに直せる。
Model Monitoringのブログ記事
Anandとのコンビで続いて公開したのが、Monitor models for training-serving skew with Vertex AI(日本語版)です。
このプロダクトの機能を文章で書くと「ML推論時の特徴量分布を継続監視し、当初分布とのJS距離が閾値を超えるとアラートを出す」というものですが、そうした説明だけですぐに分かる人たちだけでなく、もっと広いオーディエンスにも価値を伝えたい。そこでAfter Effectsでがっつりアニメーションを作りました。

(クリックするとYouTube動画が再生されます)
前にGoogle AI Comicsってコンテンツの日本語訳を手伝ったのですが、その時の担当者から許可をもらって、マンガを再利用させてもらいました。マンガ内のデータに似た分布のデータをnumpyで再現して、matplotlibで描画、正規分布グラフがぐにょーっと変形するアニメーションを作ってAEでまとめました。上述の文章説明よりもはるかに多くのオーディエンスにリーチできそう...と思うのですがどうでしょう。この動画をSNS展開時にツイートに埋め込んでもらったりしました。
もちろんアニメも含めてすべての内容についてAnand他のステークホルダーからLGTMをもらう必要があるので、AEでアニメを作るまえにSlidesで絵コンテをつくり、レビューしてもらってからAEで作り始める...って流れです。
記事内容についての工夫:この一連のMLOps系プロダクトのブログ記事を書くにあたって、Anandや各位に強く主張したのは、「この技術が(Google Cloudではなく)Googleの既存サービスでどのような価値を生み出して実績の残してきたのかを具体的に示すべき」という点です。ぽっと出のプロダクトの機能だけをマーケティング的に紹介しても面白くないですからね。
そこでこの記事では、冒頭でData Validation for Machine Learning論文にあるGoogle社内で実際に起きたTraining-serving Skewによる障害事例を紹介し、その再発を防ぐためのGoogle社内のデータ検証のプラクティス、そしてPlayチームでの効果を示しています。こうしたベストプラクティスをVertex AIで再現できるのがModel Monitoring、というストーリーラインを構成しました。
Model Monitoringのブログ記事・その2
つづいて、リサーチャーのAnkur、SWEのClaudiuと書いたのがMonitoring feature attributions: How Google saved one of the largest ML services in trouble(日本語版)です。Model Monitoringに追加された特徴量の重要度監視機能をフィーチャした記事です。
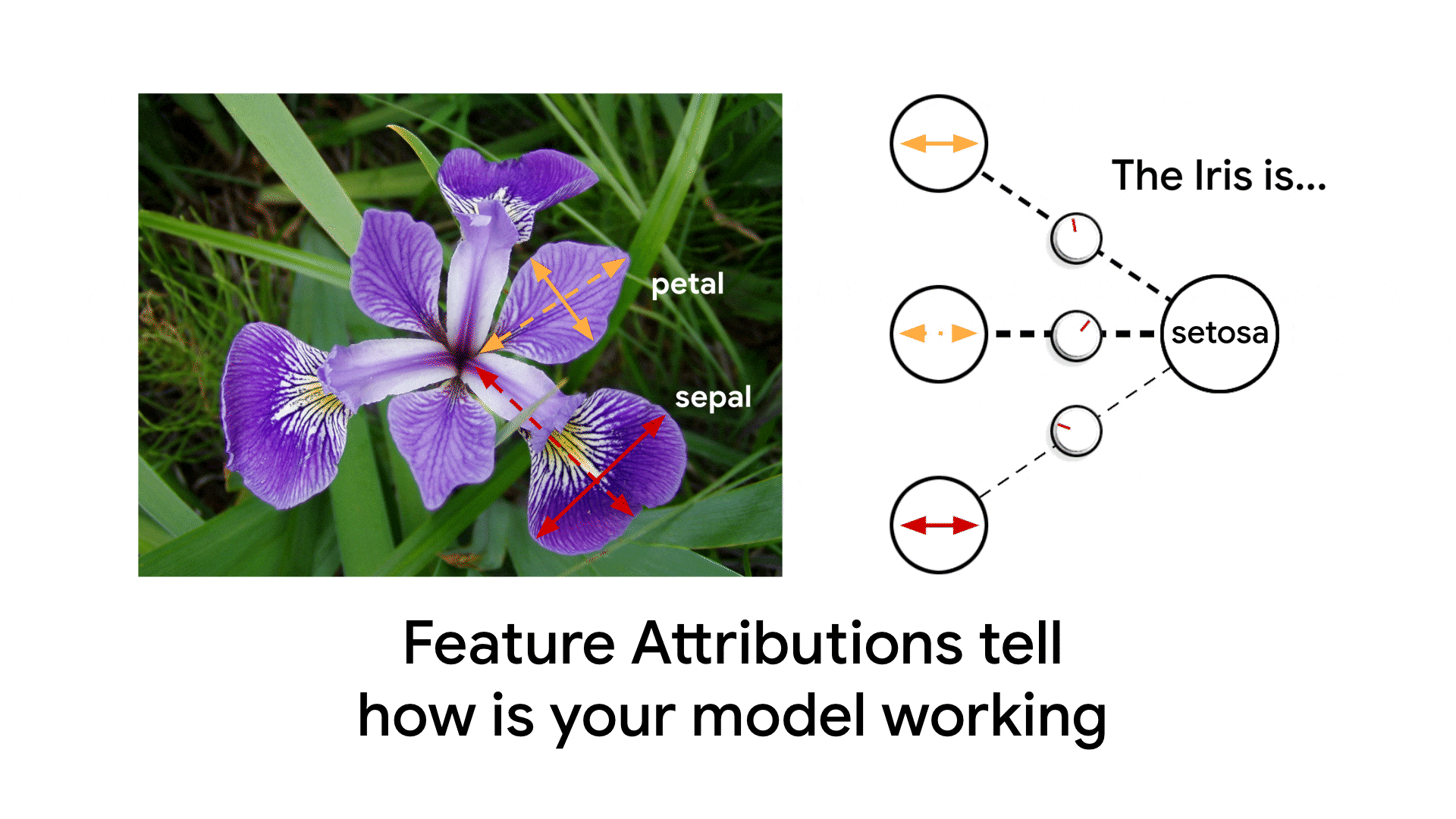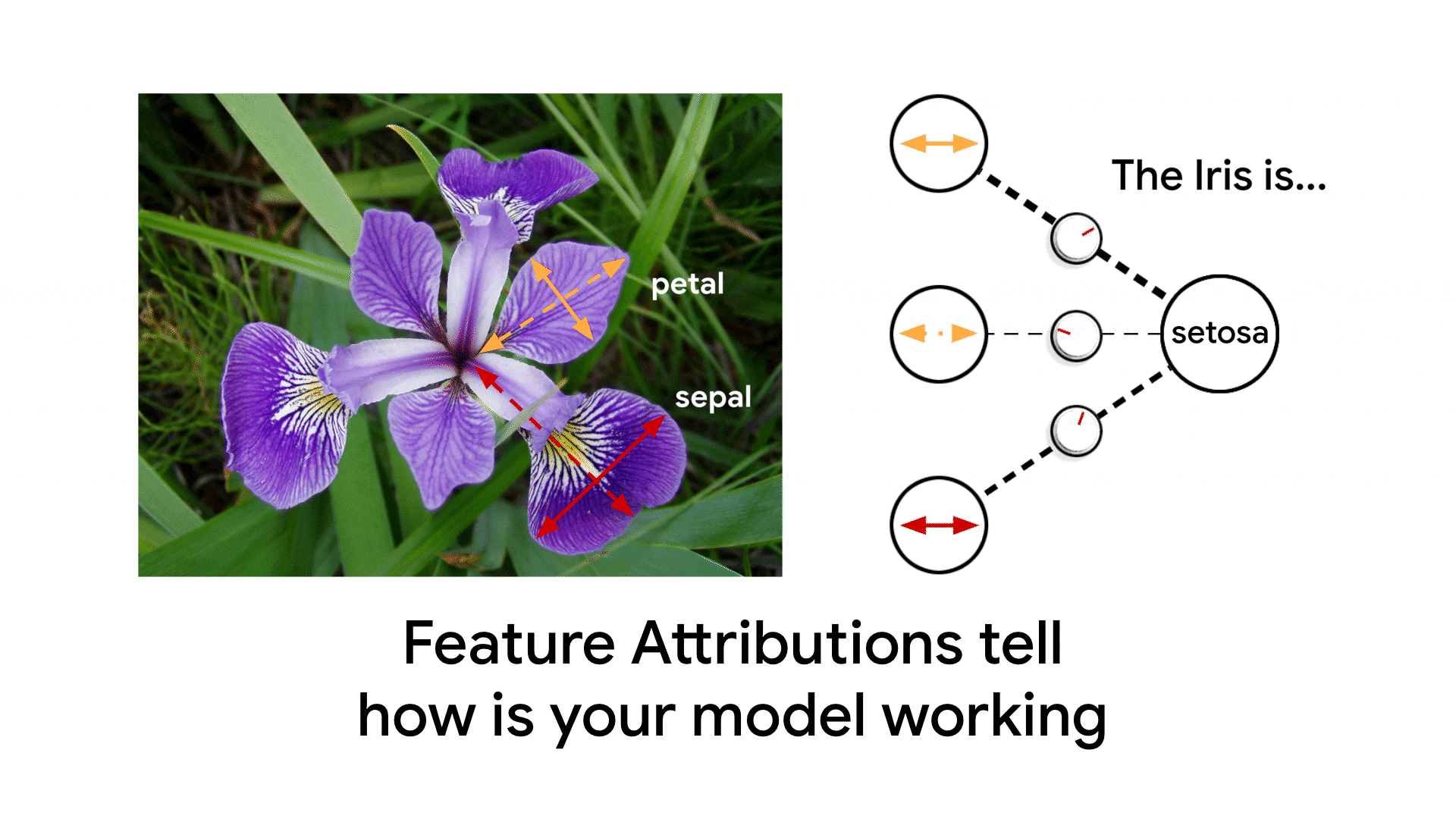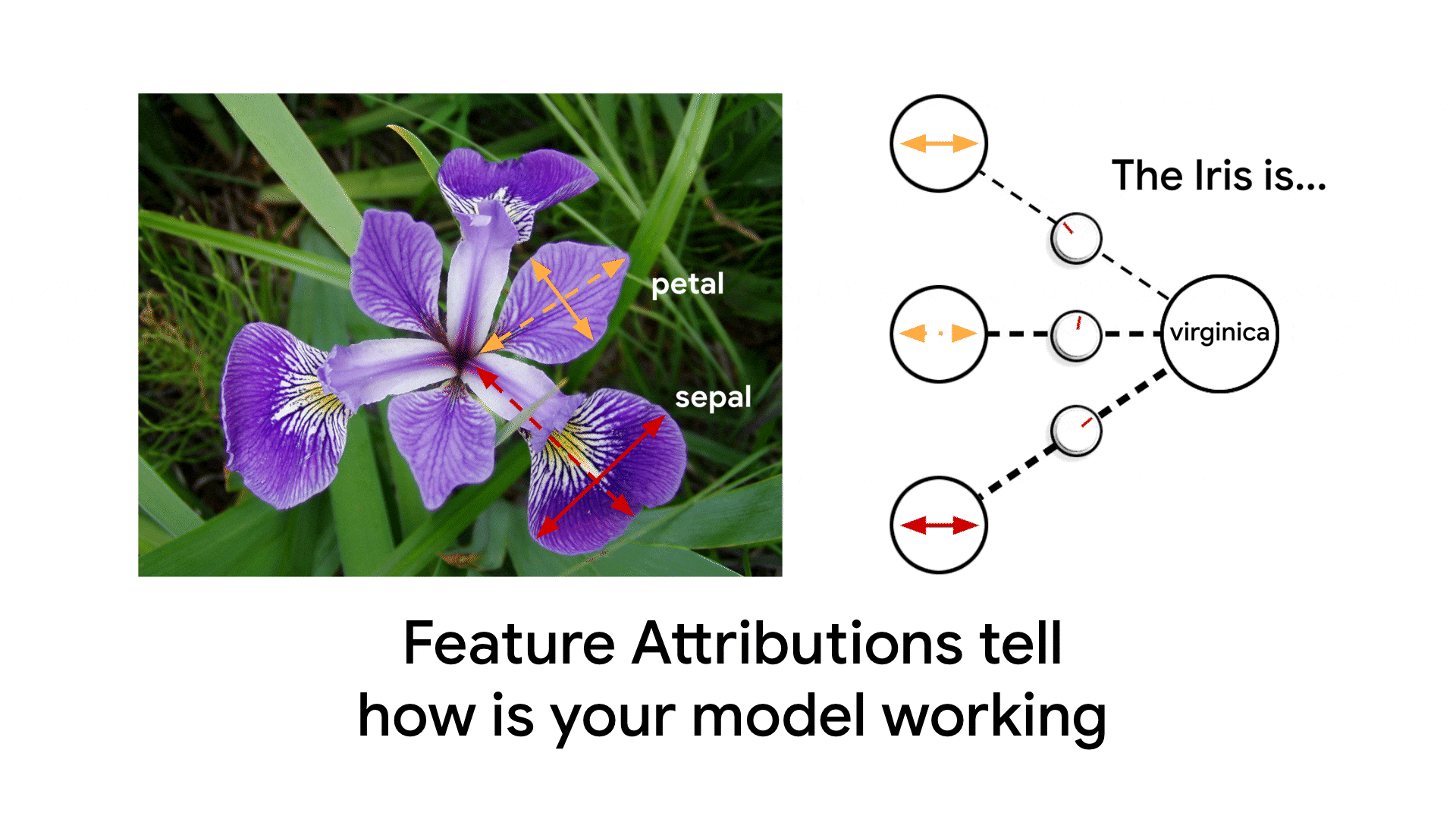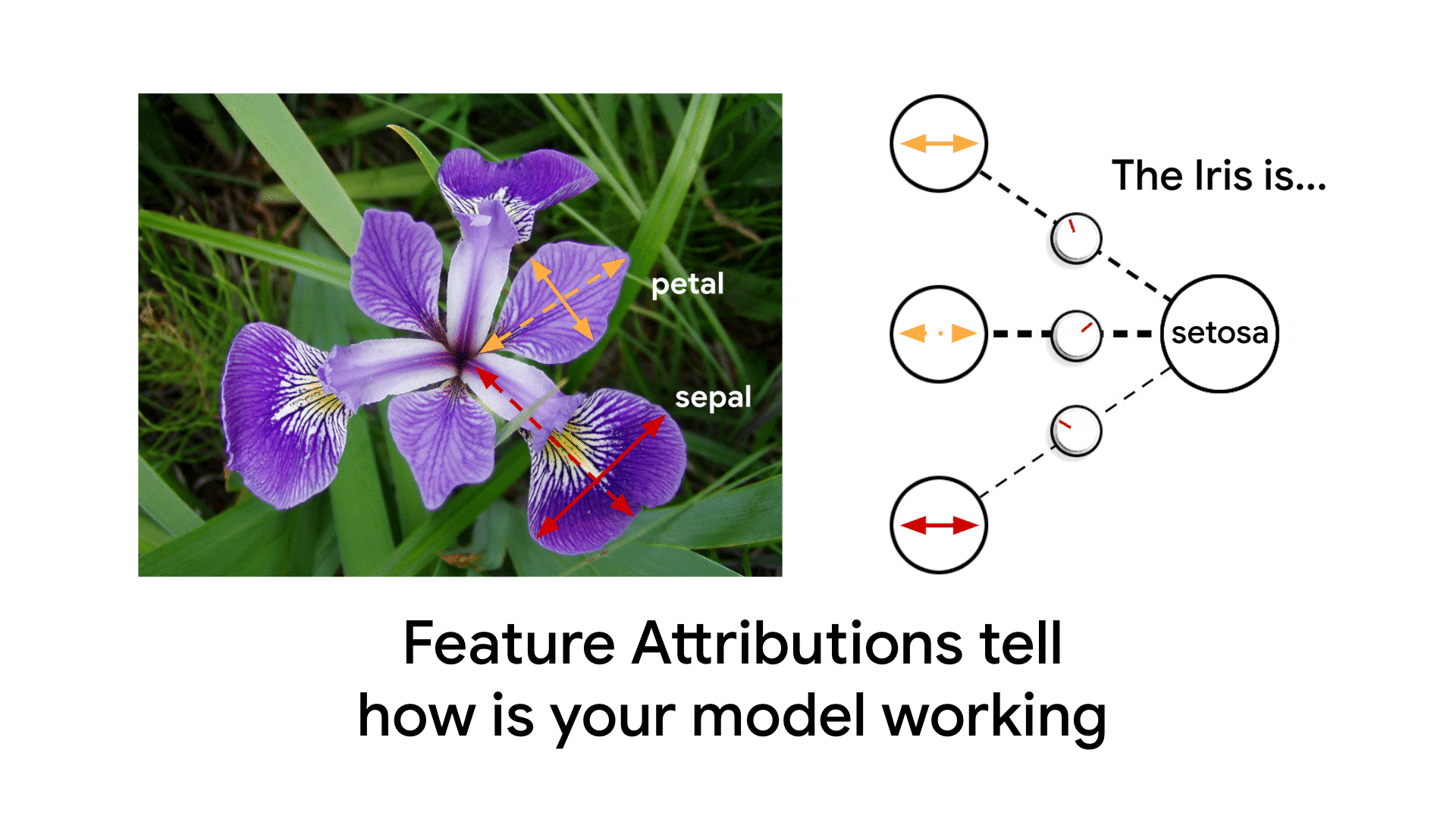
(これはちょっとアニメがうざい気もする...これ作るまでpetal/sepalが何だか知らなかった)
これは元々、Ankurが重要度監視についてのブログのドラフト(主にこの記事の後半の部分)を書いた段階で、プロダクトチームから私に手伝ってほしいと依頼があって始めました。私はここでも「Googleでの実績」をフィーチャしたかったので、PM経由で社内のガチML系SWEであるClaudiuさんに参加を依頼し、冒頭のエピソードを入れることができました。とくにこのグラフ、これ皆さんもお使いのあの巨大サービスのリコメンモデルの監視グラフそのまんま(特徴量のラベルは変えてあるけど)で、これの公開許可が得られたのは嬉しかった。
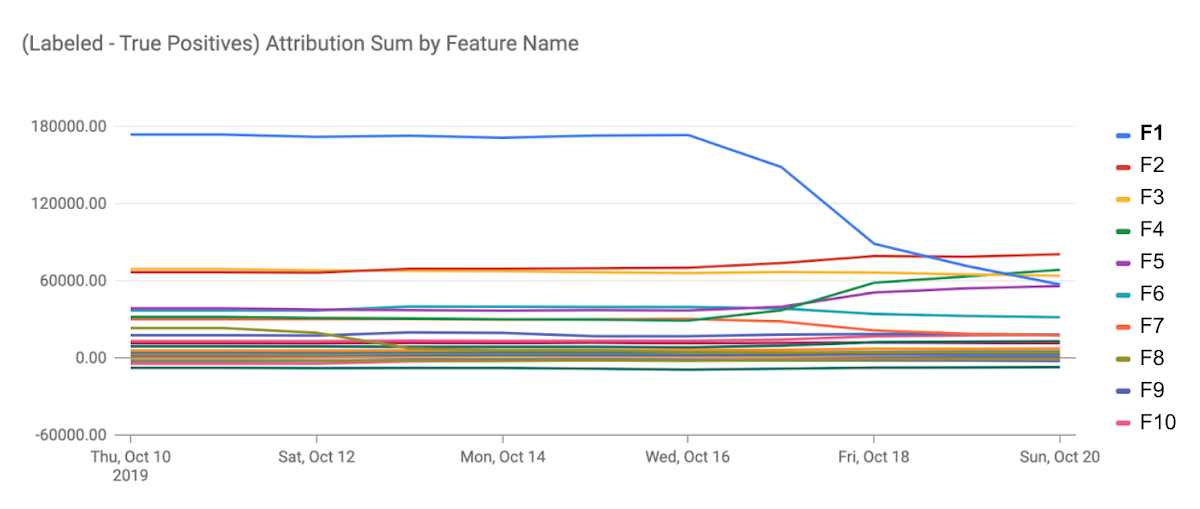
この事例では実際に特徴量監視のおかげでかなりの損失の発生を未然に防げてます。そんなGoogleの経験とノウハウに裏付けされてるならModel Monitoring使ってみたいかも…って思っていただけたなら嬉しいです。
そうしたフックを冒頭に持ってきて、真ん中は特徴量監視とは何かの解説と、実際にVertex AIで使うときの流れを解説。そして後半はAnkurが書いてくれた特徴量監視の骨太の運用ノウハウで締めるストーリーラインです。こういう構成をイメージできて、ステークホルダーと調整して内容的なコンセンサスを得て、いい感じのビジュアルを作ったら、ひと仕事した感あります。
Matching Engineのブログ記事
そして最近公開したのがFind anything blazingly fast with Google's vector search technology(日本語版)です。Vertex AI Matching Engineという近傍検索プロダクトなので、若干MLOpsからは外れる気もしますが、しかし個人的には今いちばん熱いプロダクトです。
この記事は、一にも二にも三にもグルーヴノーツ近永さんチーム作の素晴らしいデモMatchIt Fastありきです。

このデモの由来は実はとても古くて、5年ほど前にQueryIt Smartというデモを近永さんとチームの皆さんに開発いただいたのが始まりです。「BigQueryのUDF使えばNN推論とか近傍検索とかできるんじゃね」というアイディアを思いついて、近永さんにデモ開発を依頼したところ、当時のUDFの制約(最大5MBのコード/モデルしか入らない)にもかかわらず画像や文章ベクトルの近傍検索とMLPによる需要予測推論を見事にUDFで実装していただけました。Cloud Next SFのデモとして展示したりBQプロダクトセッションで紹介されたりしました。
もっともこのベクトル検索はすべてのベクトルとのcos類似度をベタに計算して比較するナイーブ実装なので、100万件に対して20秒ほどかかっていました。そして今年、Googleの虎の子ANNバックエンドを商用化したMatching Engineがリリースされることとなり、またしてもグルーヴノーツさんにお力添えをいただくことになりました。
思ったとおり、Matching Engine、まあ速い。そして、QueryIt Smartの時の下地がとても生きてます。例えばサンプル画像はすべてパブリックドメインのものをWikimediaからCloud Storageにダウンロードしておいたり、カッコいいUIで結果を表示したり。「任意ベクトルの近似近傍検索を大規模高速に実行します」って文章で説明するより、このデモ動画を見ていただいた方がインパクトが何倍も違うじゃないですか。5年前の仕込みがやっと生きた感じです。
それと、ScaNNの説明の部分は中の人であるPhilip Sunと打ち合わせて説明の仕方を工夫しました。本当はもう少しわかりやすいメタファーやビジネス観点からのメリットを示してAnisotropic lossの効用を表現したかったのですが、議論の結果、やはり「内積の最大化」としか言えないという結論に至りました。embeddingの中で起きてることを分かりやすくかつ正確に伝えるのは難しい...
ベクトル検索が熱いのは、画像や文章に限らずなんでも対象にできるところですね。個人的には、データベーステーブルのインデックスとして使うのも面白いかと思ってます。ANNのVQの仕組みって、なんだかOracleのビットマップインデックスを思い出します。
というわけで、来年もいろいろMLOps系の面白コンテンツを生産してまいりますのでご期待ください!
Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。