Google Cloud Platform (GCP)の英語ブログに、Google Compute Engine (GCE)のライブマイグレーション機能について解説記事がポストされた。個人的にもいくつかの大規模な案件でこの機能の能力に触れて、GoogleまじGoogleだなと思わされたし、GCPチームで実際に作った人たちと会うととても誇らしげに説明してくれる。熱いのだ。そこで、上記ブログ記事+個人の経験をもとに簡単にまとめてみたい。
なお、以下の内容は個人の感想です!
Heartbleedバグの時もVM再起動なし
GCEでは2013年12月より、ライブマイグレーションを利用したTransparent Maintenance(自動メンテナンス)という運用を開始している。これはつまり、VMを動かしたまま同一ゾーン内の別のサーバーへ移動することで、ハードウェアやホストOSのメンテナンスを勝手にやってくれるもの。メンテナンスのために「VMが止まるから再起動してね」といったメールが届くような事態を極力減らす仕組みだ。
実際、昨年4月のHeartbleedバグの際にも、他社クラウドのようにホストOSへのパッチ適用のために全VMを再起動するような騒ぎはGCEではまったく起きていない。もちろん「GCEではハード障害も含めて再起動は一切起きない」というわけではなく、VM再起動はゼロではないのだが、しかしハード更改やパッチ適用のような計画メンテのためにVMを止める機会はぐんと減っている。
Googleのデータセンターは、ばしばしメンテされる
Googleにとって、GCEを正式サービスとして公開できるかどうかは、このライブマイグレーション機能の実現にかかっていたとも言える。なぜならGoogleのデータセンターは常時ばしばしハードやホストOSのメンテが走っているからだ。例えば、
- サーバ、ネットワーク、電源設備等の更新
- ホストOSイメージ、BIOS、ホストのシステム構成等の変更
- 緊急のセキュリティパッチ適用
などの作業。Googleの様々なサービスは、これらの頻繁なメンテに耐えうるフェイルオーバー/冗長化設計がなされている。GCEにおいても、ライブマイグレーションが実装されたことで、他のGoogleサービスと同様につねに最新のインフラの上でVMを運用可能となった。Google最新のSDNインフラであるAndromedaのおかげでGCEインスタンス間で3Gbps通信できるよ! みたいなメリットも自動的に享受できる。
障害の事前検知時もマイグレーション
ライブマイグレーションは計画メンテナンスだけではなく、ハード障害やソフトの不具合を事前検知した際にも起動される。具体的には、
- ネットワークカードの調子がよくなくてエラー率が上がった
- バッテリや電源が加熱してサーバー温度が上昇した
- ホストOSの不具合が見つかった
- メモリ消費が異常に増えた
といった障害の兆候を検出して、実際にダウンするまえに予防的にVMを他のサーバーにマイグレーションする。マイグレーション後にはGCEのシステムログにそのタイムスタンプが記録される。ただし、ユーザー側から明示的にマイグレーションを起動することはできない。
動いてるVMを0.5sほどで移動、パケロスなし
ここまでの説明を読んで、以下のような疑問を持った人も多いはず:
- 他社VMのライブマイグレーションのように数秒くらい止まるの?
- 動いてるVMを別のサーバーに移動すると、サービスが止まったりネットワークが切れたりするのでは?
これは私にとっても大きな疑問で、正直、出てきたばかりのころは半信半疑だった。「怖いからライブマイグレーションをオフにしたい」という意見もごもっともである(GCEではライブマイグレーションを無効に設定できる)。
結論から言うと、これは個人の感想ではあるけど、ライブマイグレーションでVMが止まる時間はたいていの場合は0.5sくらい。かつ、もっとも重要な点は、ネットワークのパケットロスやTCP接続切れが起きないことだ(←これはほんとにすごい)。要するに、ほとんどたいていの用途でエンドユーザーもサーバー管理者も気づくことなくライブマイグレーションされる。
本当か? と思われるかもしれないが、実際にGCEで稼働する膨大な数のVMに対してすでに多数のマイグレーションが実施され、滞りなく運用されている。Rightscaleが実施した大規模な負荷テストでも、
ログファイルやDB内容をさらって見ても、なんにも異常は見当たらない。
もしGoogleがマイグレーションしたと教えてくれなければ気付かなかったはず。
との評価。

From Google Compute Engine Live Migration Passes the Test
実際に私が関わった国内事例でも、GCE上で稼働するDBクラスタに対して国内有数規模の実トラフィックをかけつつマイグレーションする負荷テストを実施し、DBエラーや接続切れ等は一切発生しなかった。観測されたのはごくわずかなレプリケーション遅延のみ。なにこの謎テクノロジー...と思った。
マイグレーションのメカニズム
では、このマイグレーションはどのような仕組みで実現されてるのだろうか。
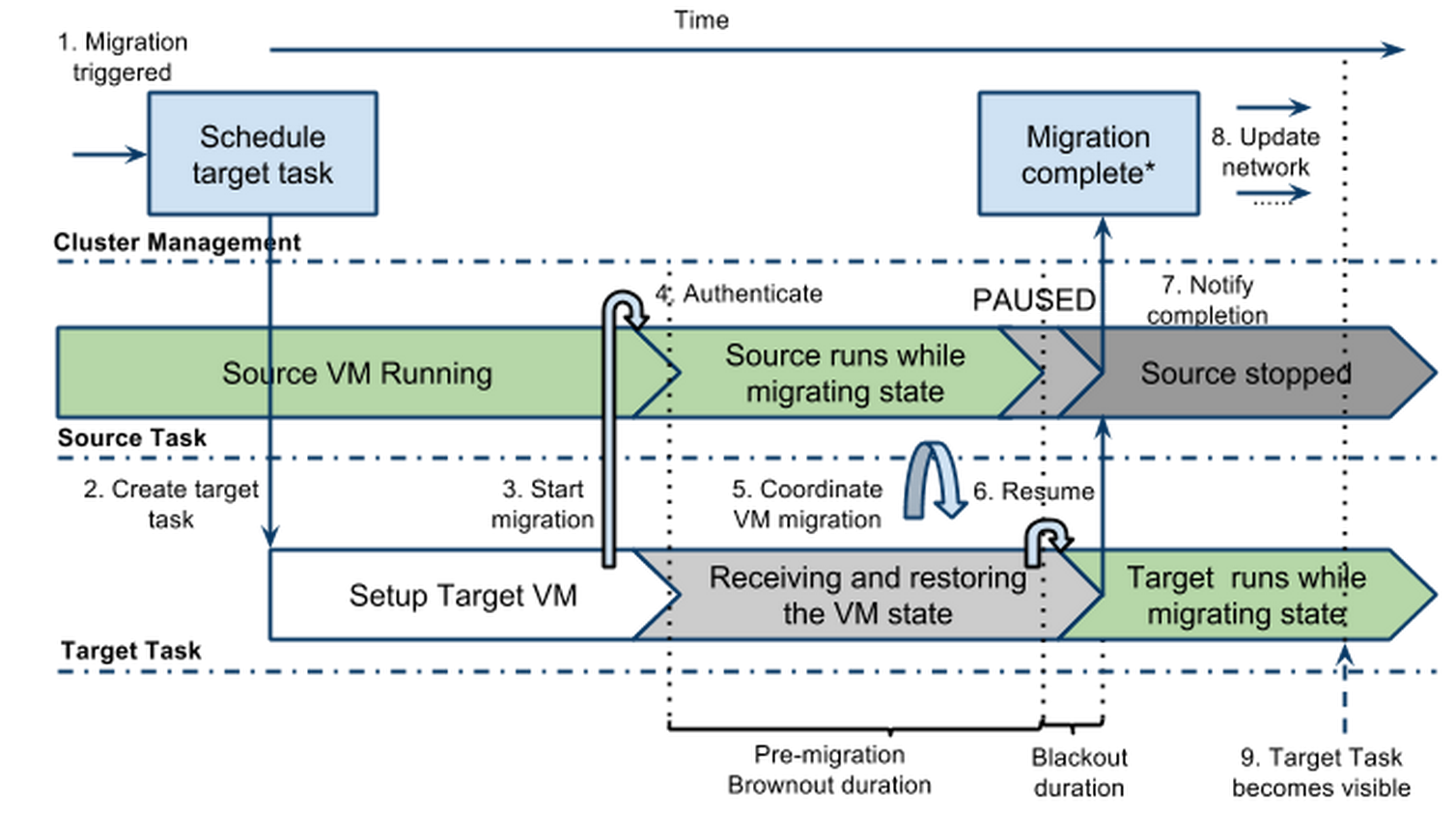
マイグレーション開始の60秒前になると、VM上のゲストOSに対してマイグレーションの開始が事前通知される。つづいて移行先の新しいVMが用意され、以下の3段階のマイグレーションが開始される。
- ブラウンアウト期間:移行元VMを稼働させた状態で、メモリ上のデータ等のVM内容を移行先VMにコピーする
- ブラックアウト期間:移行元VMのすべての動作を一瞬だけ停止し、ブラウンアウト期間中に更新された変化分を移行先VMにコピーする
- マイグレーション後のブラウンアウト期間:移行元VMは移行後も残り、ブラックアウト期間中に受け取ったネットワークパケットを移行先VMに転送する
先に述べたとおり、ここで言うブラックアウト期間は、私の経験上はたいていの場合0.5sくらいで終了する。その間に届いたネットワークパケットはすべて移行先VMに届くので、TCP接続も問題なく維持される仕組みだ。
GCEはいろいろこわいよ
このGCEのライブマイグレーションは、他社クラウドサービスのユーザーにとってはかなり魅力的な機能のひとつで、説明するたびに驚かれる。これによってGCEが停止する可能性がゼロになるわけではないけれど、ユーザーがクラウドのおかげででラクできる点がひとつ増えたとは言えるだろう。
1Mリクエスト/秒を難なくさばけるGCEのロードバランサーをはじめ、今回のライブマイグレーションなど、そろそろ「Googleらしいクラウド」としての特色が出てきたGCE。年内にはもうひとつ、これもGoogleこわいよーと思ったサービスが出てくるらしいので、ご期待いただきたい。
Disclaimer この記事は個人的なものです。ここで述べられていることは私の個人的な意見に基づくものであり、私の雇用者には関係はありません。