今月はじめ、インテルがFPGA大手のアルテラを総額2兆円で買収することを発表した。インテルはちょっと前まではCPU+FPGAなんてコードが分断するしダメダメソリューションだなんて言ってたくせに、なんて鮮やかな手のひらの返しよう。まあでも、すばらしい展開だし非ノイマン計算をソフト屋が使いこなす時代が幕開けしそうなので、あっぱれインテルである。非ノイマンなにそれ? という人はコネクションマシン本と青いリコンフ本を読んでおこう。
この発表でインテルが説明に用いたスライドで、とくに目を引いたのが以下の一文。
Up to 1/3 of Cloud Service Provider Nodes to Use FPGAs by 2020
(2020年までに、クラウドサービスプロバイダのサーバの1/3がFPGAを利用する)
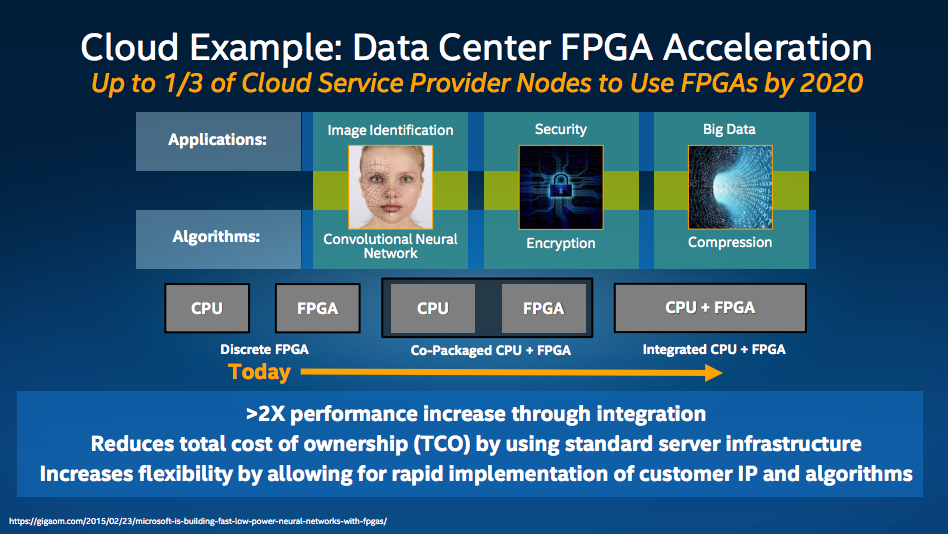
つまりあと5年もすると、クラウドを使うエンジニアは直接的/間接的にFPGAを使わざるを得なくなる……とインテルは考えてる。
じゃあ、データセンターでFPGAっていったいどういう用途にどう使うの? って点が気になるが、6/13にアメリカのポートランドで開催された計算機アーキテクチャの国際会議ISCA 2015においてインテルのPK Guptaがその疑問に答えてくれる発表を行った。その名も、
Xeon+FPGA Platform for the Data Center

この発表のスライドが公開されたので、以下その要点をかいつまんでみたい。さらに、現地参加したprof_hrkさんとshtaxxxさんによる一連のつぶやきもまとめたので、あわせて参考にしてほしい。
なぜFPGAアクセラレータか
では、なぜデータセンターのアクセラレータとしてFPGAを使いたいのか?

- パフォーマンスの強化:CPUコアだけじゃ足りない部分はアクセラレータで補う。PCIeやQPIでアクセラレータをつなぎ、CPUの1スレッドあたりにできることを増やす
- ヘテロ計算への移行:ムーアの法則は続いてるけど、アーキテクチャやソフトウェアには劇的な進化が求められる。従来のCPU単独の並列性だけでなく、CPU以外の技術も組み合わせたヘテロ計算を導入、シリコンの能力を引き出してアプリケーション特化したハードウェアを実現
MSははっきりと「ムーアの法則は終わった」って言ってるけど、さすがにインテルはそうは言えない様子。要するに、CPUコアやスレッドを増やすだけではあまり先が見えないので、GPUやFPGAと組み合わせてスレッドあたりの性能を高めよう、という意味だ。
XeonとFPGAを25.6GbpsでQPI接続
FPGAをCPUのアクセラレータとして使う場合、CPUとFPGA間の接続がしょぼいとボトルネックになりがちだが、そこはインテル、がつんとQPIで提案している。
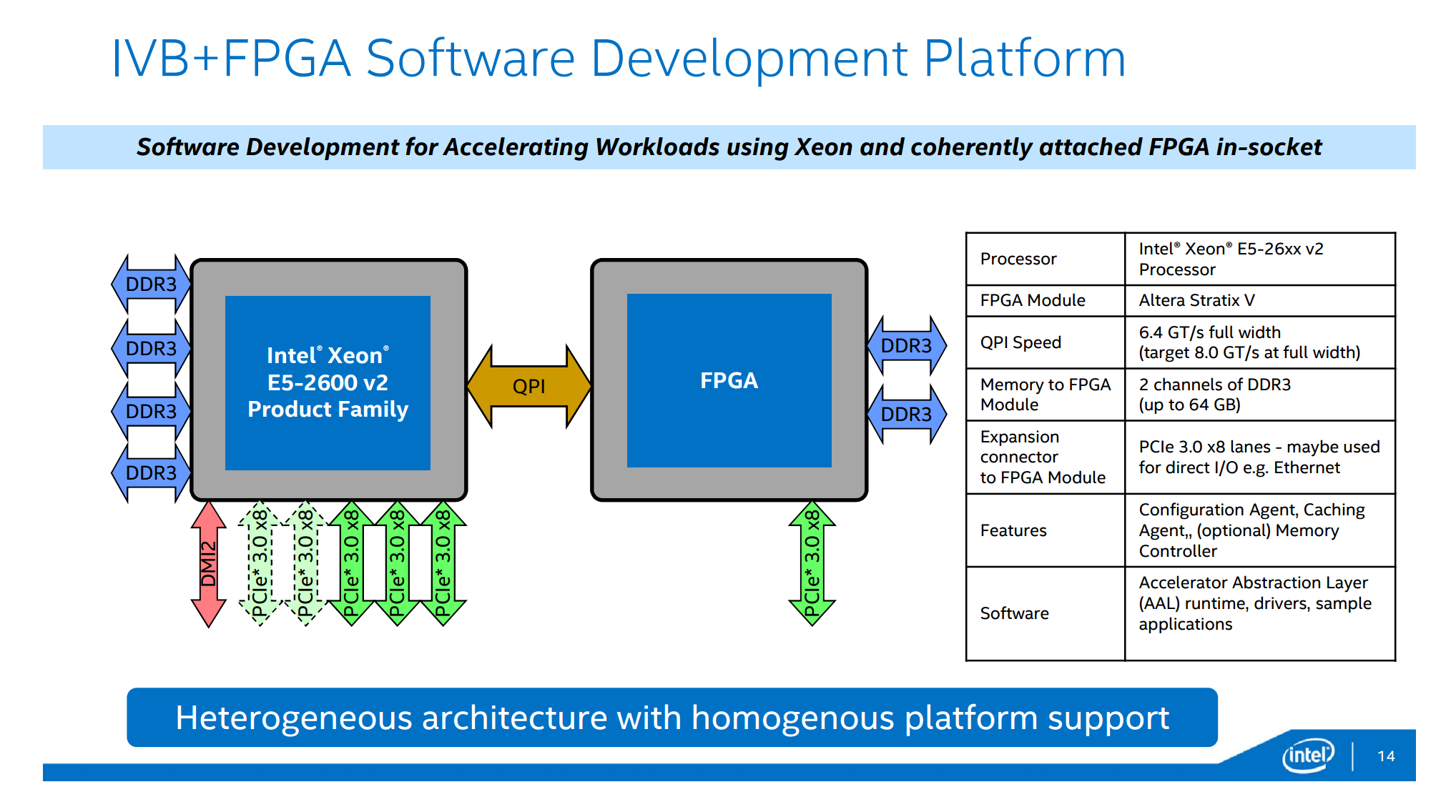
6.4 GT/s full widthということは双方向で25.6Gbpsの帯域が得られる計算。ちなみにIBMもPOWER8のCAPIではこれに近い帯域で外部FPGA/ASICとの接続を提供してる。また上図をみるとFPGAからDDR3メモリとPCIeへの直接パスがあるので、MSのBing事例のようにFPGA同士をつないでトーラスを組んだり外部とRDMAしたりといった応用もできそうだ。
CPUとFPGAの連携API
帯域は十分だとして、CPU上のソフトとFPGAとの連携はどうなるか? を解説したのが以下の図。
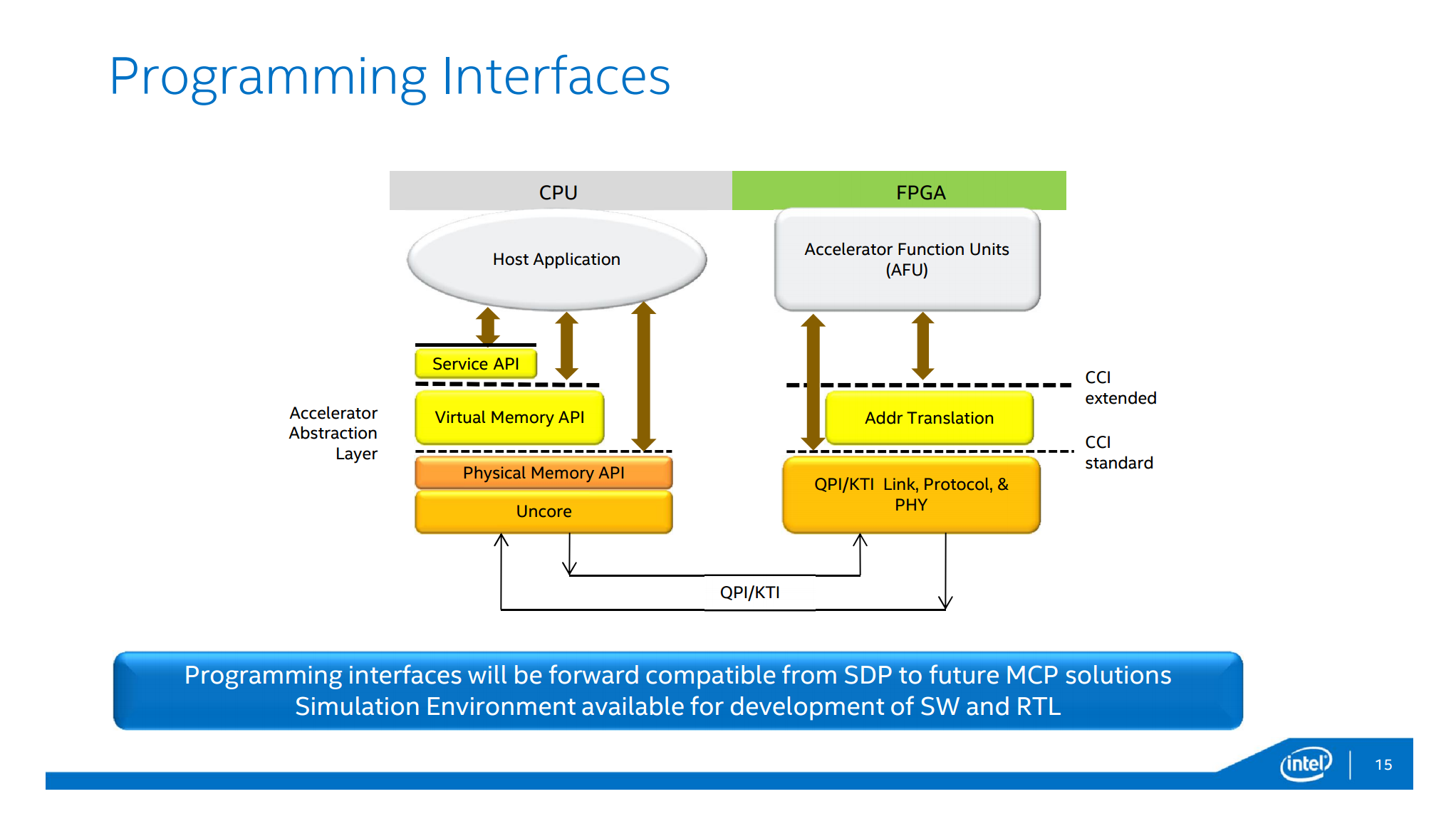
CPU上のアプリケーションから見ると、FPGAとの通信は特定のメモリアドレスへのアクセスで行う。そのアドレスに、あれやって、これやって、とデータやコマンドを送ると、FPGA側でそれに応じた処理を始める流れになる。ただ、すべてのデータをCPUとFPGA間でバケツリレーしてるとそこがボトルネックになったりするので、例えばCPUから「PCIe経由で外部のネットワークやストレージからどばっとデータが流れてくるので、暗号化や正規表現マッチを直接やっといて」みたいな指示を出す……って使い方が出てくるはず。複雑な制御はCPUで、単純なストリーム処理はFPGAで、という役割分担だ。
OpenCLで高位合成
では、FPGA上で動作するアクセラレータ自体はどのように開発するのか。従来のFPGA開発では、Verilog HDLやVHDLといったハードウェア記述言語(HDL)を用いてデジタル回路設計を行うのが主流。つまりはハードエンジニアの独壇場であった。俺もがんばって小さいMIPSをHDLで書いてみたけど、こりゃ仕事でやるのはムリと思い知った。MSのBing事例やドワンゴさんのようにおカネのあるプロジェクトではハードエンジニアを雇うのがベストだろう。
一方で、よりお手軽なFPGA開発手法としてこれから熱いのが高位合成。つまり、CやJava等のプログラミング言語でハードウェアのふるまいを記述して、そこからHDLを自動生成するという手法だ。国内ではみよしさんが開発したSynthesijerがちまたで盛り上がりつつある一方で、GPUとも共用できるOpenCLをFPGAの高位合成に用いる手法も使われ始めている。
インテルが提唱するのは、OpenCLをFPGAに用いる方法だ。

この方法では、OpenCLの枠から出て自由自在にアプリ固有の非ノイマン計算機を組む、って訳にはいかなくなるけど、GPUと同じ手軽さでFPGAを使えるようになる。どちらが速いか比べて速い方を選ぶ、ってこともできそうだ。
なければ買ってくればいいさ
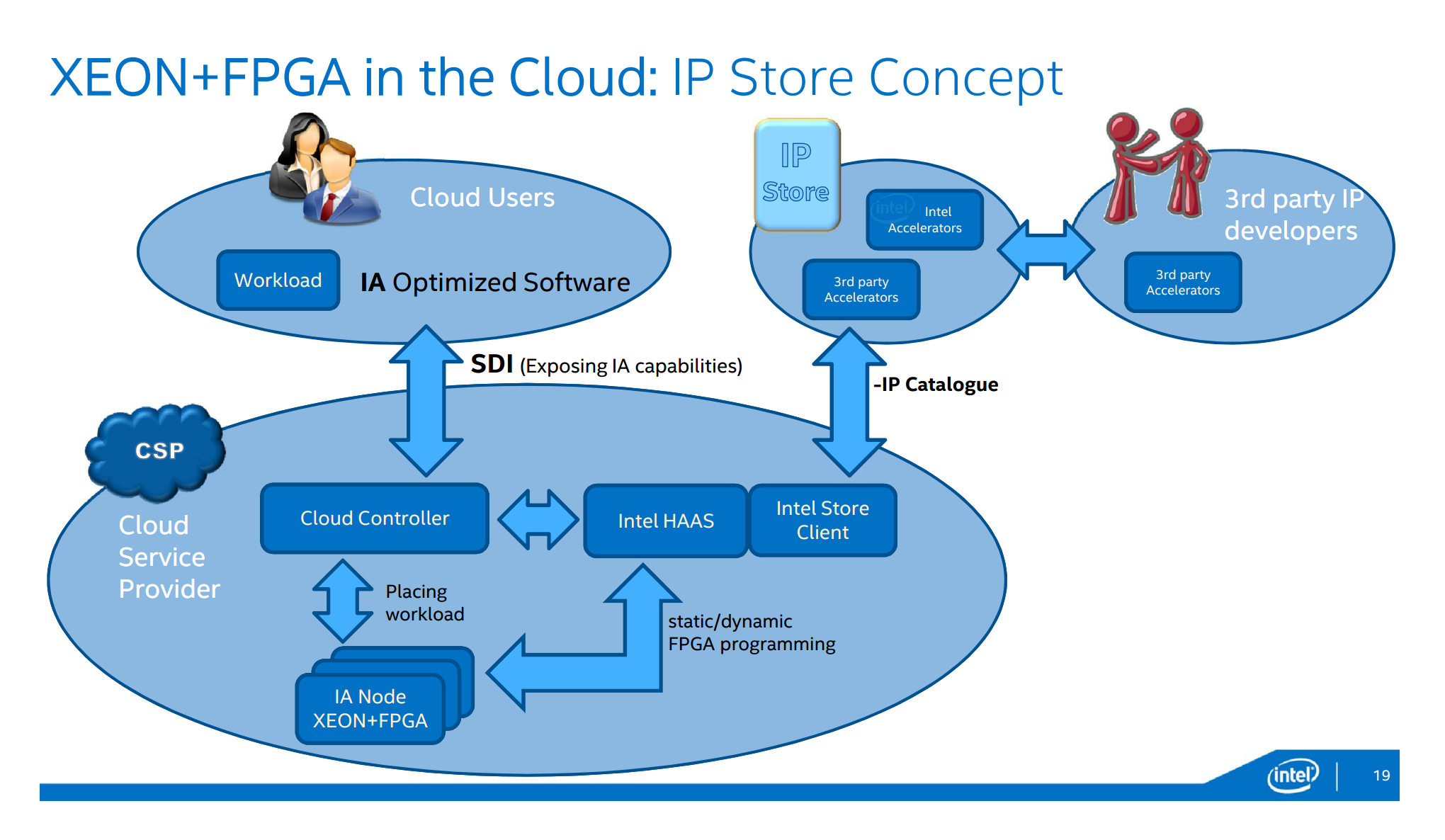
さらに、インテルは「IPストア」というコンセプトも検討している。ここで言うIPとはIntellectual Property、つまりハードウェア回路のライブラリのこと。例えば、市場ではネットワーク通信、ディスクI/O、数値演算、暗号化、TCP/IPスタックなど、さまざまな商用IPが販売されている。それらを購入してFPGAに載せ、CPU側から簡単に呼び出して使う……といった将来像が描かれている。
まずはディープラーニングに
Xeon+FPGAの用途だが、まずはやはりMSでも実用化されているディープラーニングのアクセラレータとして。
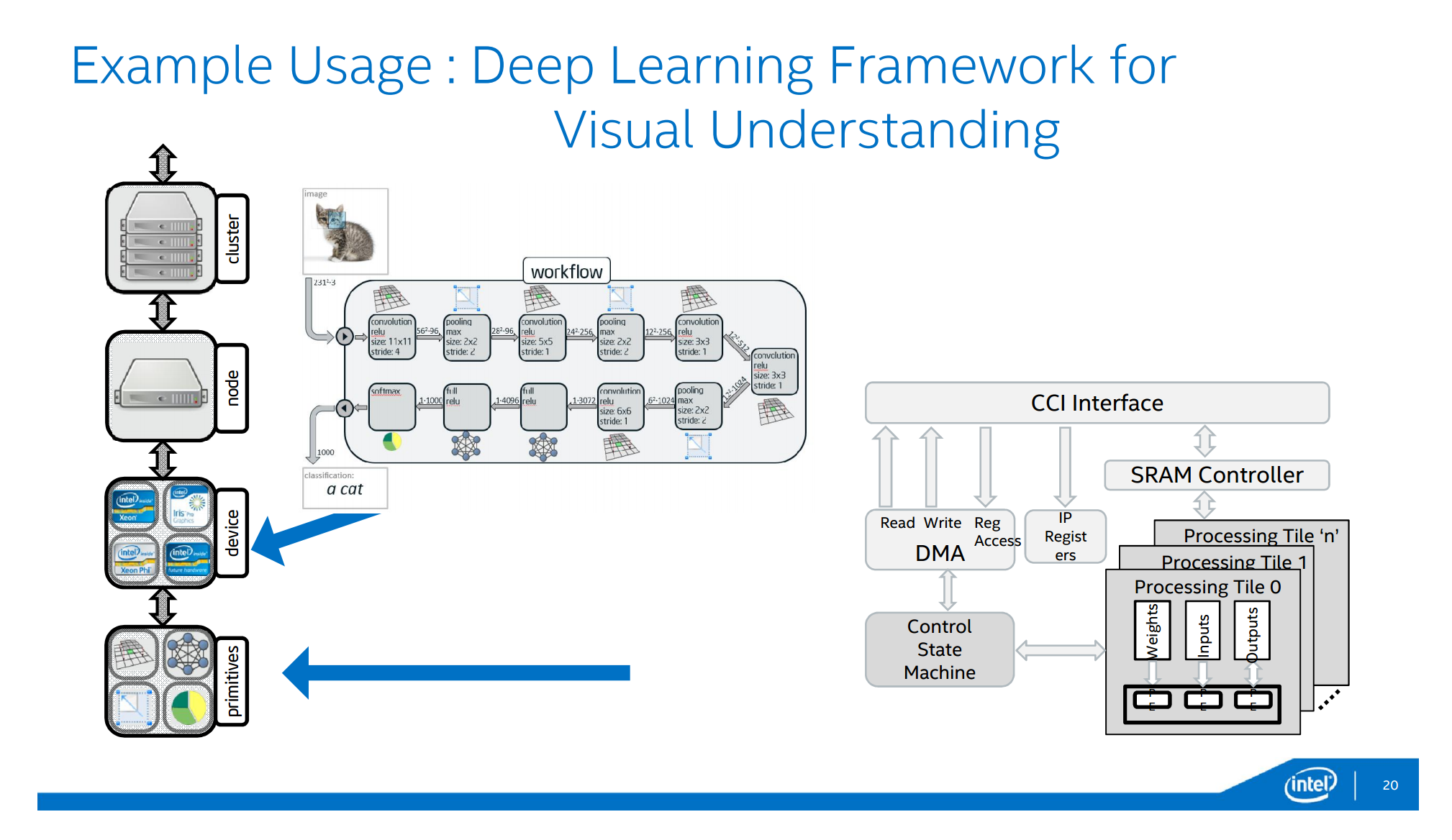
つづいて、Open vSwitchベースのネットワークスイッチのオフロード。
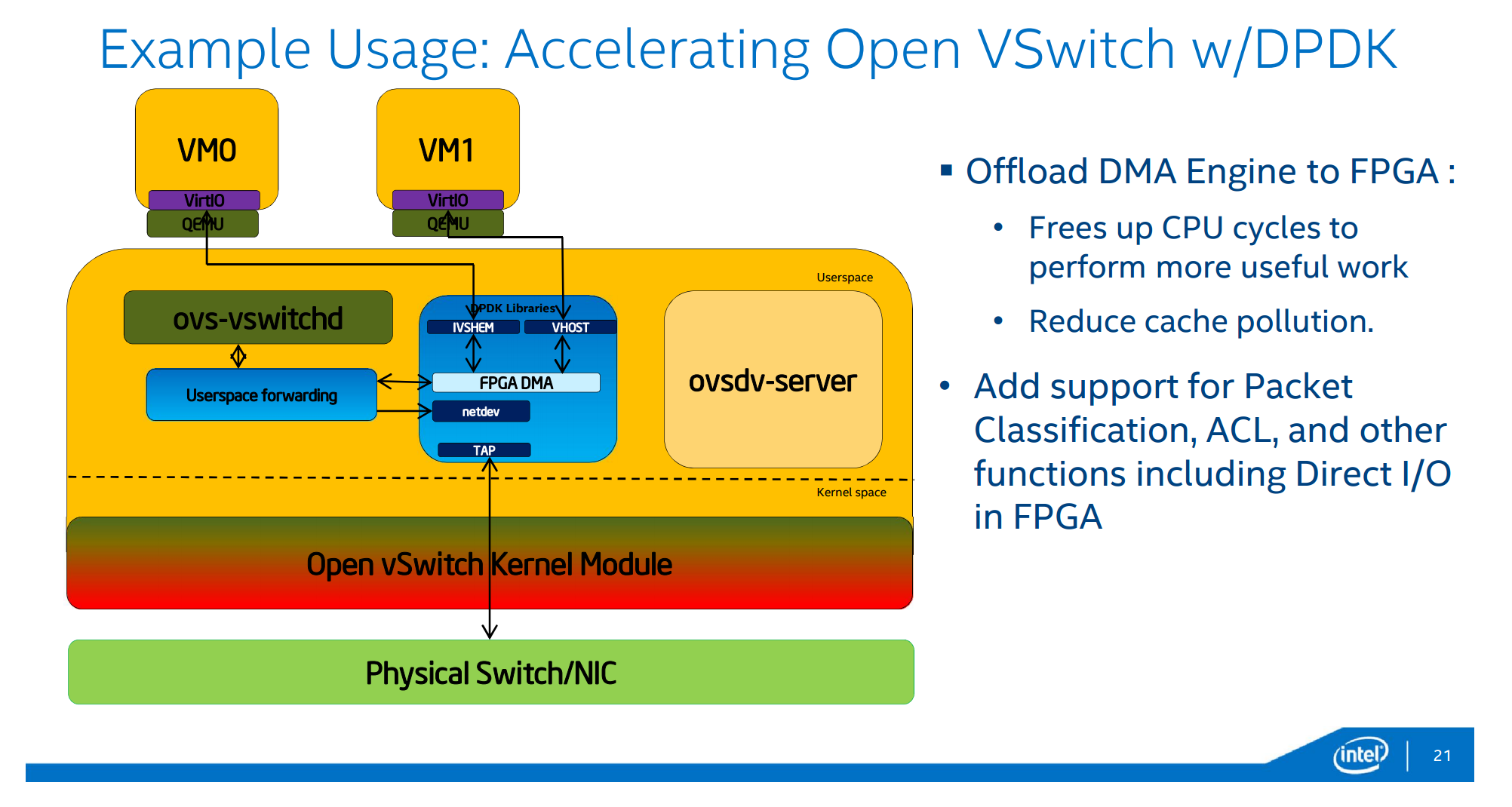
そして定番、金融機関のHFT。
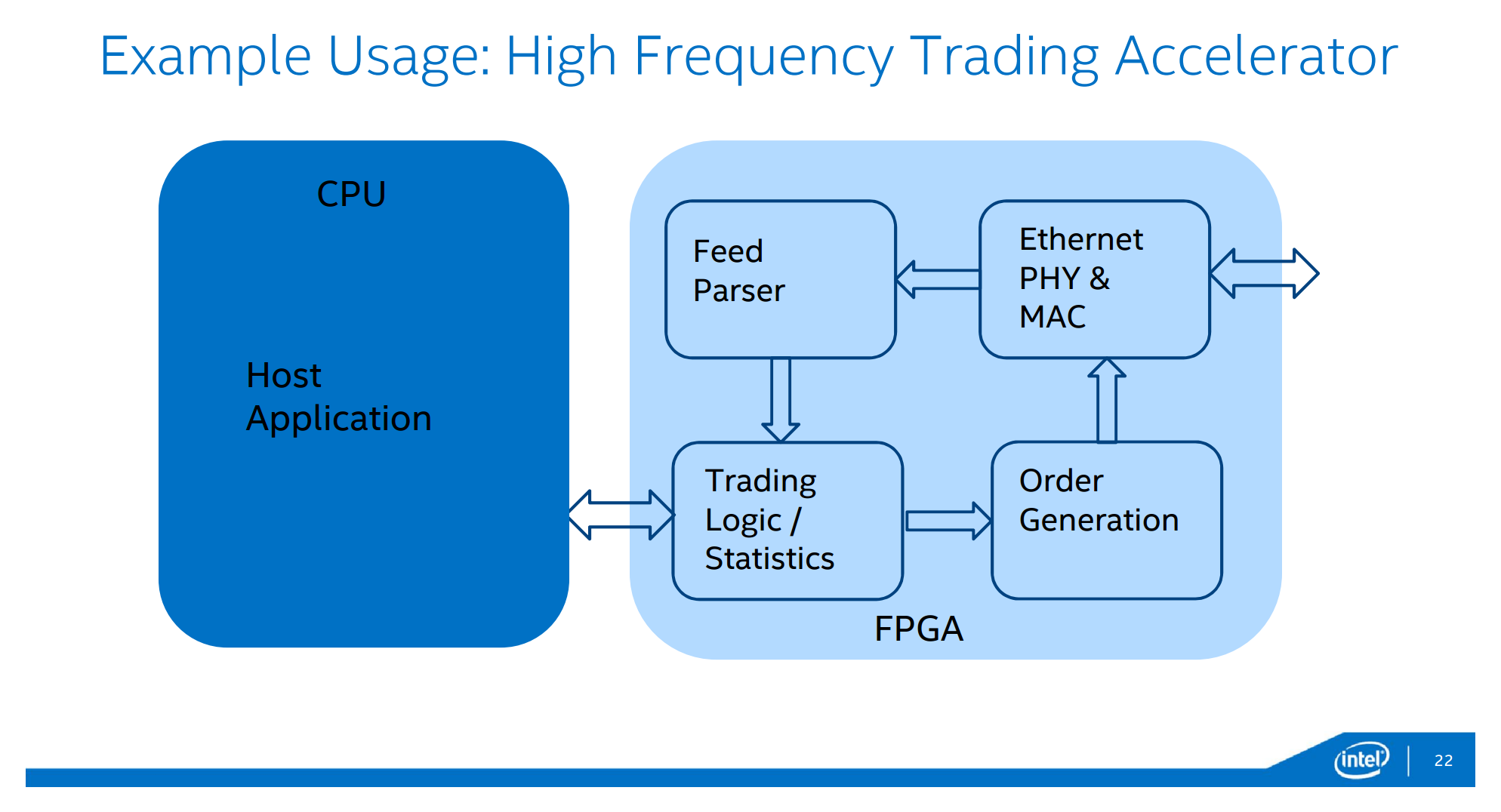
といったところが応用として示されてる。
Xeon+FPGA、早く来てほしい
Xeon+FPGAの出荷は2016年とのことで、とりあえずOpenCLでディープラーニングを実装する練習でも始めておこうかと思う今日このごろです。
ちなみに、次回のFPGAエクストリームコンピューティングは8/2にドワンゴさんで開催予定。来月頭には告知する予定なので、しばしお待ちを……。