DataGemma がリリースされました。外部情報を使ってハルシネーションを抑止する手法として RAG が有名ですが、Datagemma では RAG だけではなく RIG という手法も提案・利用していました。
RIG というのがよくわからなかったので論文を読みました。そしてそのときの翻訳を残します。
RIG が一体なんなのかはそのうち…
注) RIG の Retrieval Interleaved Generation は勝手に検索交互生成としました。
以下原文を LLM の助けを借りながら翻訳したもの
要旨
大規模言語モデル(LLM)は、数値や統計データ、あるいは時事的な事実に関連するクエリに応答する際、事実に反する情報を生成しがちです。本論文では、国際連合(UN)、疾病管理予防センター(CDC)、世界各国の国勢調査局など信頼できる機関からの公的統計を集めた大規模なオープンソースリポジトリである Data Commons と統合することで、LLMの精度を向上させるアプローチを提示します。我々は主に 2 つの方法を探究します:LLM が Data Commons からデータを取得するための自然言語クエリを生成するよう訓練される検索交互生成(RIG)と、Data Commons から関連するデータテーブルを取得して LLM のプロンプトを拡張する検索拡張生成(RAG)です。これらの方法を多様なクエリセットで評価し、LLM の出力の事実的正確性を向上させる効果を実証します。我々の研究は、検証可能な統計データに基づき、複雑な事実推論が可能な、より信頼性の高い信頼できるLLMを構築するための初期段階を表しています。
はじめに
生成型大規模言語モデル(LLM)がクエリに対して事実に反する記述を生成したり(幻覚)、主張に対する正確な引用を提供できないことがあることは、多くの文献で報告されています。研究者たちは、これらの現象の原因として、LLM 生成の本質的に確率的な性質や、訓練データにおける事実の十分なカバレッジの欠如などを特定しています。
本論文では、LLMをデータに接続する一般的なアーキテクチャを提示し、解決すべき3つの問題を概説します。
まず、いつ LLM は(パラメータに格納された知識に頼るのではなく)外部ソースに情報を求めるべきかを学習する必要があります。外部ソースに何をいつ尋ねるべきかという知識は、LLM のパラメータにエンコードされる必要があります。我々は、これを達成するための複数のメカニズムを探ります。
(翻訳外メモ: 外部データを使う When, What を知る)
次に、要求された情報に対してどの外部ソースに問い合わせるべきかを決定する必要があります。利用可能なソースの集合が大規模で動的である可能性があるため、この知識はLLMの外部にあることが望ましいです。本論文では、多数のデータソースを含む単一の外部情報源を利用します。
(翻訳外メモ: 外部データの Which を知る、という話だが、今回は結局単一リソースなので which は関係ない)
最後に、必要な外部データを理解した後、LLM はそのデータを取得するための 1 つ以上のクエリを生成する必要があります。異なるソースは異なる種類のデータを生成するため、LLM が様々なソースの API に関する特定の知識を持つ必要がなく、代わりに単一の API に依存できれば有益です。言い換えれば、外部データとサービスのための単一の「ユニバーサル」 API が必要です。我々は、1993 年に Robert McCool によって設計された URL パラメータエンコーディングインターフェースからインスピレーションを得ています。これは非常にシンプルですが、時間の試練に耐え、ウェブ上で最も普遍的な API に近いものです。その精神に基づき、我々はクエリを表現するメカニズムとして自然言語自体を使用します。返される回答は、非テキスト形式の回答を可能にするため MIME タイプで拡張される場合があります。
(翻訳外メモ: クエリは複数投げるが、単一 API で、API が適切なデータソースにルーティングしてほしい…のだけど今回はやはり単一データソースだからそこの話は関係ない)
先行研究では、これらの問題を緩和するために、ツール使用と検索拡張生成(RAG)の2つのアプローチが活用されてきました。ツール使用では、LLM は自然テキストと外部ツールへの関数呼び出しを交互に配置するマークアップ言語を生成するように fine-tune されます。幻覚に対処するため、ツールはデータベースや検索エンジンに問い合わせる可能性があります。RAG では、補助的な検索システムを使用して、ユーザーのクエリに関連する大規模コーパスからの背景知識を特定します。その後、ユーザーのクエリは関連する知識で拡張されます。
本論文では、数値および統計的事実に関するモデルの幻覚に対処するための我々の取り組みについて説明します。統計データの例には、国勢調査局、国連、疾病管理予防センター(CDC)や世界保健機関(WHO)などの公衆衛生機関によって収集されたものが含まれます。統計データは新たな課題をもたらします:
-
統計的事実に関するユーザークエリには、様々な論理、算術、または比較演算が含まれる可能性を含みます。単純な例としては、「世界のCO2排出量トップ5の国はどこですか?」、「アメリカと中国のCO2排出源を比較してください」などのクエリがあります。より複雑なクエリの例として、「カリフォルニアは世界最大の経済ですか?」(比較対象の実体(カリフォルニアと他の国、米国の州ではない)がクエリで暗黙的にしか言及されていない)や、「石炭火力発電量が多い米国の州はCOPD率も高いですか?」(実体と指標の両方にわたる比較を含む)などがあります
-
公開統計データは幅広いスキーマとフォーマットで配布されており、正しく解釈するにはしばしば相当な背景知識が必要です。これは RAG ベースのシステムに特別な課題をもたらします
我々は、前述の課題に対処するため、最大級の統一された公開統計データリポジトリの1つである Data Commons とLLM をインターフェースする取り組みを紹介します。我々は、検索交互生成(RIG)と検索拡張生成(RAG)という 2 つの異なる方法を採用しています。Google のオープンソース Gemma および Gemma-2 モデル を活用して、RIG と RAG 両方の fine-tuned バリアントを作成しました。各 fine-tuned モデルについて、数値および統計的事実に関するモデルの幻覚を軽減する効果を評価するために使用したパイプラインと評価タイプの詳細を説明します。
関連研究
本セクションでは、4 つの既存の研究分野を取り上げ、我々の研究がこれらの取り組みをどのように発展させているかについて議論します。
Toolformer:
Toolformer テクニックは、自己教師あり学習を用いて大規模言語モデル(LLM)が外部ツールを活用できるようにするアプローチを説明しています。この方法では、モデルはどの API を呼び出すか、いつ呼び出すか、どの引数を渡すか、そして結果をどのように最適に組み込むかを決定するよう訓練されます。検索交互生成(RIG)は、Toolformer テクニックの応用です。我々のアプリケーションでは、LLM に自然言語でデータストアから統計を問い合わせて取得するタイミングを知らせるよう訓練を試みており、構造化された質問を必要としません。
(翻訳外メモ: 自然言語の質問でいつデータストアを使えばいいかをトレーニングしている)
検索拡張生成(RAG):
RAGは、言語モデルに外部の知識ソースへのアクセスを与えることで、その能力を向上させる fine-tuning アプローチです。これにより、モデルは訓練データを超えた関連情報を取り込むことができ、より包括的で有益な出力が可能になります。本論文では、Data Commons の自然言語インターフェースから関連するデータ検索クエリを生成するRAG の応用を紹介します。長いコンテキストウィンドウを持つLLMを使用し、このアプローチはユーザーのクエリを Data Commons から取得した包括的なデータテーブルで補完し、それらのデータテーブルに基づいた引用付きの微妙な推論を可能にします。
Knowledge Graphs(KG): KG の応用は、Google 検索と Data Commons の両方にとって極めて重要です。本論文では、Data Commons が標準化されたデータとスキーマを持つ相互運用可能な KG の集合としてどのように機能し、自然言語インターフェースを使用して多様なデータセットをシームレスに探索できるかを説明しています。Data Commons の KG と RAG の組み合わせは、本論文で最も説得力のある結果の一部を生み出しています。
Less Is More for Alignment(LIMA): LIMA は、限定的かつ精密な例のセットを利用して、エンドタスクをユーザーの好みにより適切に合わせる Instruction Tuning と強化学習のアプローチです。LIMA の顕著な性能により、モデルは訓練データのわずかな例から特定の応答フォーマットに従うことができます。本論文は、LIMA を基に、Data Commons の KG を用いた RIG と RAG の探索に小規模セット訓練を活用しています。
Data Commons の概要
Data Commons は、Google によるオープンソースイニシアチブで、世界の公共データセットを整理し、普遍的にアクセス可能で有用なものにすることを目指しています。Data Commons は、国連、国勢調査局、保健省、環境機関、経済部門、NGO、学術機関などの公共ソースからの幅広い統計データを包含しています。現在、このコーパスには世界中の数百のソースから2,500億以上のデータポイントと2.5兆以上のトリプルが含まれています。
(翻訳外メモ: トリプル?)
Data Commons はグローバルなデータカバレッジを積極的に拡大していますが、現在の制限を認識することが重要です。米国では、Data Commons は国レベルで18万以上の統計変数、郡レベルで10万以上の統計変数を持っています。OECD諸国を見ると統計変数の数は急激に減少し、世界の他の地域ではさらに減少します。また、米国以外では州や地区レベルの詳細なデータはData Commonsにおいて乏しいです。
Data Commons には2つの革新が含まれています。
第一に、私たちは何年もかけて多数の公開データセットにアクセスし、データの背後にある仮定を追跡し、構造化データをエンコードするためのオープンな語彙である Schema.org を使用して正規化しました。これにより、すべてのデータを組み込んだ共通のナレッジグラフが作成されます。
第二に、私たちは自然言語(NL)インターフェースを作成するためにLLMを使用しています。これにより、ユーザーは一般的な言語で質問し、膨大なデータベースを探索するための一連のチャートやグラフにアクセスできます。明確にしておくと、LLM は単にクエリを Data Commons の語彙に翻訳するだけです。基礎となるデータを修正したり相互作用したりすることはなく、出力を生成することもないので、幻覚や類似の問題の心配はありません。
私たちの現在のアプローチは、この NL インターフェースを活用し、LLM に Data Commons NL インターフェースといつどのようにコミュニケーションを取るかを教えることです。
Data Commons と LLM のインターフェース
本セクションでは、LLMと Data Commons のインターフェースを実現する2つの異なるアプローチについて説明します [図1]。
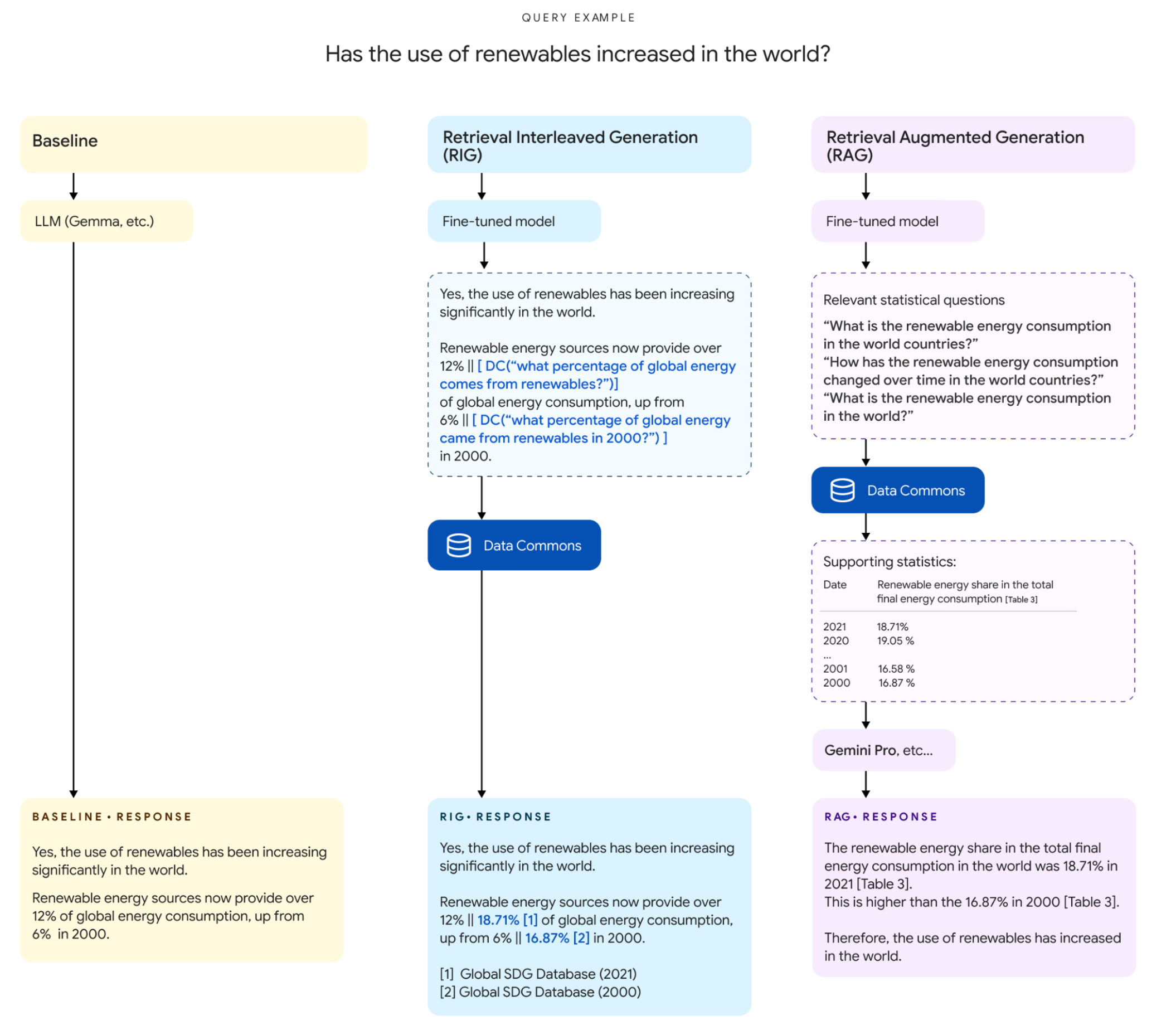
図1. 統計データを用いた回答生成におけるベースライン、RIG、RAG アプローチの比較。ベースラインアプローチは根拠なしで直接統計を報告するのに対し、RIG と RAG は Data Commons を活用して信頼性の高いデータを利用します。点線の枠は中間ステップを示しています:RIG は統計トークンと Data Commons から検索するのに適した自然言語の質問を交互に配置し、一方 RAG は Data Commons によって回答されるより細かい粒度の自然言語の質問を生成し、それらを最終的な回答を作成するためのプロンプトに提供します。
1つ目は、検索交互生成(RIG)と呼ばれるツールに触発されたアプローチで、LLM が統計とともに自然言語の Data Commons クエリを生成するように fine tune されています。マルチモデルパイプラインがこの自然言語クエリを構造化データクエリに変換し、それを使用して Data Commons データベースから回答を取得します。これらの結果をベースラインとして base Gemma 7B IT と base Gemma 27B IT の結果と比較します。
2つ目のアプローチは、検索拡張生成(RAG)と呼ばれる、より伝統的な検索アプローチです。まず、fine-tuned LLM(fine-tuned Gemma 2 9B ITとGemma 2 27B IT)を使用してクエリで言及された変数を抽出し、Data Commons から関連する値を取得し、この追加のコンテキストで元のユーザークエリを拡張し、LLM(Gemini 1.5 Pro)を使用して回答を生成します。これらの結果をベースラインとして Gemini 1.5 Pro の結果と比較します。
(翻訳外メモ: もう伝統的なんだ…)
検索交互生成 (RIG)
このセクションでは、RIG パイプラインのステップについて詳しく説明します。最初のコンポーネントは、Data Commons の自然言語クエリを生成するようにファインチューニングされたモデルです。2番目のコンポーネントは、自然言語クエリを構造化データクエリに変換するポストプロセッサーです。最後のコンポーネントは、Data Commons から統計的な回答を取得し、LLM 生成に提供するクエリメカニズムです。
モデルの fine tuning
LLM に統計的なクエリが与えられると、通常は数値の回答を含むテキストが生成されます [図2]。この数値の回答を LLM 生成統計値 (LLM-SV) と呼びます。LLM-SV を取り巻く文脈から、Data Commons データベース内で最も関連性の高い値を特定し、元の生成値とともにユーザーに提供することで、ファクトチェックのメカニズムとして機能させたいと考えています。この取得された値を Data Commons 統計値 (DC-SV) と呼びます。
(翻訳外メモ: LLM-SVには幻覚を含む可能性が高い)
私たちのアプローチは、LLM をファインチューニングして、元の LLM-SV と並んで LLM-SV を説明する自然言語クエリを生成することです。LLM に形式的な構造化データクエリ(例:SQL)ではなく、自然言語クエリを生成させることには、いくつかの利点があります。
まず、自然言語クエリは構造化クエリよりも簡潔であることが多いです。これは、LLM が複数の LLM-SV を含む生成を行う場合に意味を持ちます。
次に、Data Commons データベースには何百万もの変数と関係が含まれています。すべてのこのような変数 ID の知識を持つように LLM をファインチューニングすることは、コストがかかりすぎ、他の面でのパフォーマンスを低下させる可能性があります。
最後に、LLM にクエリを自然言語で表現させることは、周囲の文脈から実体や関係を言い換えたりコピーしたりする、より簡単なタスクです。
我々は、この動作を生成するために、instruction-response データセットにモデルを fine-tuning します。このアプローチは、LLM が次のトークン生成による回答を生成するのではなく、そのようなツールを利用するように調整される、ツール使用に関する研究と類似しています。ツール使用の文献と同様に、我々はファインチューニングされたモデルが元のモデルと同じ語彙的な応答スタイルを維持することを望んでいます。ファインチューニングはモデルの流暢さに影響を与えるべきではありません [図2]。
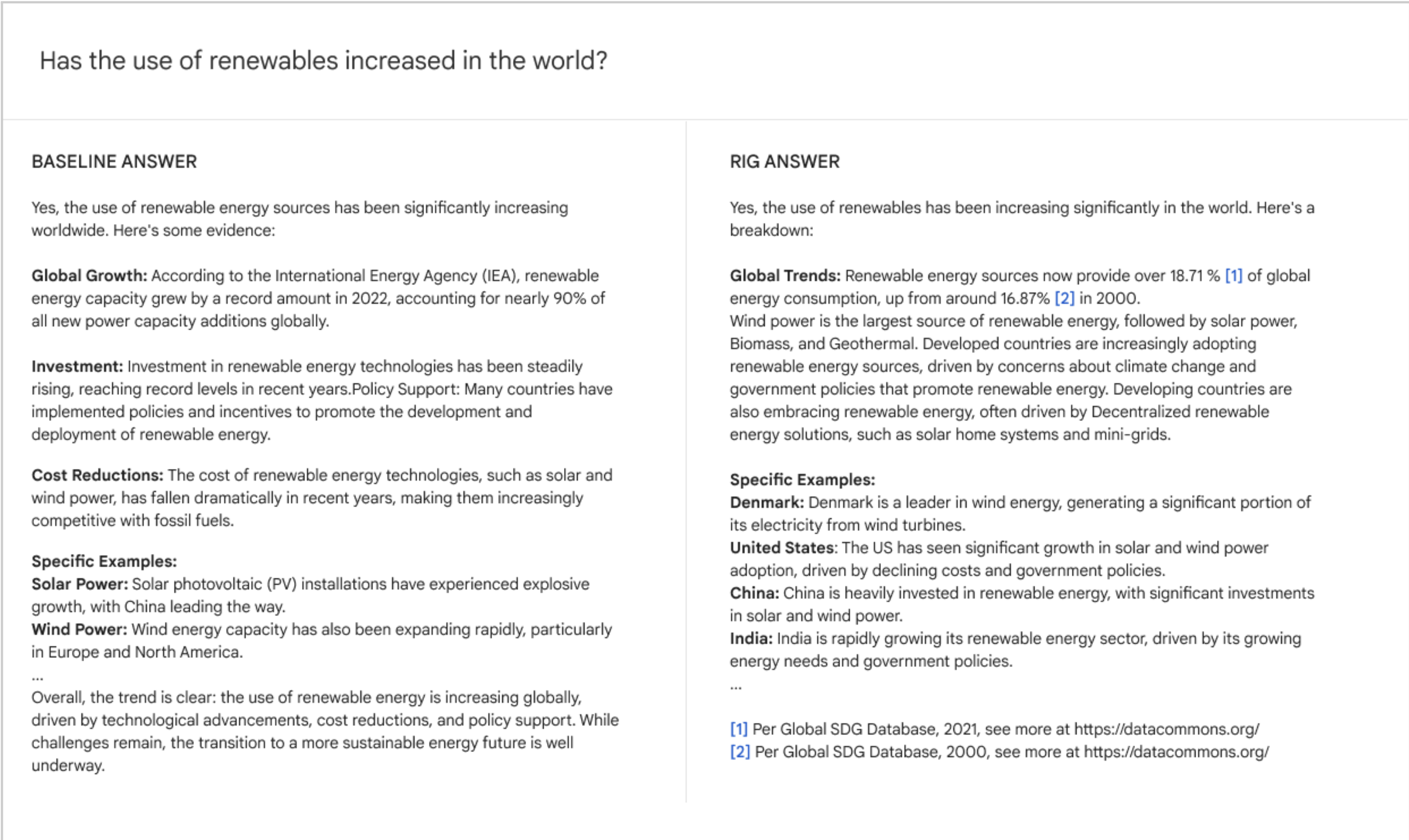
図2. クエリへの回答を比較する例; Data CommonsとのインターフェースなしのベースのGemma(Gemma 7B IT、Gemma 2 27B IT)の回答と、検索交互生成(RIG)の回答。
私たちは、異なる統計的質問に対応する約 700 のユーザークエリのセットから始めます。これらの質問それぞれに対して、ベースモデルから統計情報を含む回答を選択します(この場合、約 400 の例)。これらの回答は、より高性能な LLM(Gemini 1.5 Pro)に提供され、統計データポイントの周りに自然言語の Data Commons の呼び出しを導入するよう指示されます(プロンプトを通じて)。具体的には、使用されるプロンプトには 3 つの少数ショット例がガイダンスとして含まれており、統計値と単位(ある場合)のみに注釈を付けるよう指示しています。また、Data Commons の呼び出しには場所名、表される指標/変数名、日付(ある場合)を含めるよう指示しています。その後、生成された回答を確認し、指示に従っていない Data Commons の呼び出しを手動で書き直します。付録 A には、プロンプトと手動書き直しの例が含まれており、400 の例には統計的回答に注釈が付けられています。
クエリ変換
パイプラインの 2 番目のコンポーネントは、LLMによって生成された自然言語の Data Commons クエリを、Data Commons データベースに適用できる構造化クエリへ変換します。私たちの主要な直感は、可能なクエリの数は非常に多い(Data Commonsには何百万もの変数とプロパティがある)にもかかわらず、ほとんどが少数のカテゴリーに分類されるということです。これにより、自然言語の生成から構造化データクエリを抽出するプロセスを簡素化できます。
クエリが与えられると、まず以下のコンポーネントに分解します:1 つ以上の統計変数またはトピック(「unemployment rate」、「demographics」など)、1 つ以上の場所(「california」など)、そして有限の属性セット(「ranking」、「comparison」、「change rate」など)。変数と場所はさらに Data Commons の対応する ID にマッピングされます。各コンポーネントに対して、我々が独立して反復してきた異なる自然言語処理(NLP)アプローチを適用します。統計変数やトピックには埋め込みベースの意味検索インデックスを使用し、場所には文字列ベースの固有表現認識実装を使用し、属性検出には正規表現ベースのヒューリスティックセットを使用します。進行中の作業には、固有表現認識と属性検出のための fine-tuned カスタムモデルの探索が含まれます。
次に、特定されたコンポーネントに基づいて、クエリを固定のクエリテンプレートのセットに分類します。これらのテンプレートの例は 表 1 に示されています。
表1. 特定されたコンポーネントから導き出された例クエリテンプレート
| Template | Example |
|---|---|
| How many XX in YY | How many auto thefts in Palo Alto |
| What is the correlation between XX and YY across ZZ in AA | What is the correlation between poverty and diabetes in the US counties |
| Which XX in YY have the highest number of ZZ | Which city in California has the highest number of households receiving food stamps |
| What are the most significant XX in YY | Most significant health conditions in California |
実行
クエリテンプレートと変数および場所の ID が与えられると、それらの呼び出しを Data Commons の構造化データAPIに変換する単純な「実行」ロジックがあります。Data Commons からの最終的な応答は、通常、オプションの単位を伴う単一の数値(例:「37.5年」)を含みます。
我々の実装では、この回答は LLM が生成した元の統計と並べて提示され、ユーザーが LLM の事実確認を行う方法を提供します。LLM が生成した Data Commons のクエリ文字列を削除し、その代わりに LLM が生成した数値と Data Commons が返した値を出典とともに含めます[図2]。この新しい結果を表示するためのユーザー体験には、並列表示、差異の強調表示、脚注、ホバーアクションなど、さまざまな方法があり、これらは将来の研究で探求することができます。
検索拡張生成 (RAG)
このセクションでは、RAG パイプラインの異なるコンポーネントについて説明します。まず、ユーザークエリが小規模な fine-tuned LLM に渡され、ユーザークエリに関連する Data Commons 自然言語クエリが生成されます。次に、これらのクエリがData Commons自然言語インターフェースに対して発行され、関連するテーブルが取得されます。最後に、元のユーザークエリと取得されたテーブルを使用して long-context LLM(Gemini 1.5 Pro) にプロンプトを与えます。
元のユーザークエリと結果のテーブルを合わせると、かなり長くなる可能性があります。例えば、広範な比較クエリには、50 の米国州や 194 の世界各国の複数年のデータから複数のテーブルを含む場合があります。合成クエリセットから、平均入力長は 38,000 トークンで、最大入力長は 348,000 トークンでした。この大きな入力サイズのため、long-context LLM(つまり、Gemini 1.5 Pro)の使用が不可欠です。
Data Commons 自然言語クエリの抽出
ユーザークエリを入力として受け取り、Data Commons 自然言語クエリのセットを出力として生成するように LLM をファインチューニングします。
トレーニングデータを作成するために、より大規模な LLM(この場合、Gemini 1.5 Pro)の潜在的な知識を活用します。ユーザークエリに応じて Data Commons 自然言語クエリを生成するよう LLM に要求するプロンプトを作成します(付録Bを参照)。プロンプトでは、生成される Data Commons 自然言語クエリが Data Commons NL インターフェースでサポートされている特定の形式に準拠する必要があることを指定しています。例えば、「$PLACE の $METRIC は何ですか?」という形式のクエリのみです。このアプローチにより、入力クエリに関連するトピックのData Commons コールが生成されますが、データの可用性や Data Commons のカバレッジの制限により、必ずしも Data Commons から応答が得られるとは限りません。
プロンプトに Data Commons の変数とメトリクスの完全なリストを含めることで、実際の Data Commons 変数のみを生成する代替アプローチも試みました(付録Cを参照)。しかし、実際には関連する統計変数を抽出する能力が大幅に低下しました。これは、Data Commons にクエリと関連する変数が非常に少ないか、クエリが多くの変数に一致する高レベルのトピックを参照しており、LLM がそれらを適切に絞り込めないためです(例:「最も健康的な国々」)。代替アプローチの精度が低いため、詳細な評価には最初のアプローチの結果を報告し、この代替アプローチについては今後の研究で追跡します。
生成された Data Commons コールをレビューし、特定の質問を手動で書き直します。指示チューニングデータセットでは、元のクエリと関連する Data Commons コールを生成するための短いプロンプトが「ユーザー」の指示を表し、生成された質問リストが「アシスタント」の応答を表します。このような例が 635 あり、これらの例の一部を付録 D に示しています。
テーブルの取得
RIG フレームワークで適用されたのと同じアプローチを使用して、生成された Data Commons 自然言語クエリを変換します。つまり、まず自然言語クエリの変数、場所、属性を特定し、既知のクエリテンプレートにマッピングしてから、Data Commons の構造化データ API を使用して実行します。
この場合、構造化データ API はテーブルを返します。例えば、「国別の平均寿命は何ですか?」というクエリは、国、メトリック名(平均寿命)、メトリック値の列を持つテーブルを返します。
プロンプティング
各クエリに対して Data Commons から関連するテーブルを取得した後、ユーザーの元の自然言語クエリと取得したテーブルのシリアライズされたバージョンを含む新しいプロンプトを作成します。このステップでは、シリアライズされたテーブルのサイズ要件を考慮して、長いコンテキストをサポートする LLM(Gemini 1.5 Pro)を使用します。LLM の応答をユーザーに返します[図3]。
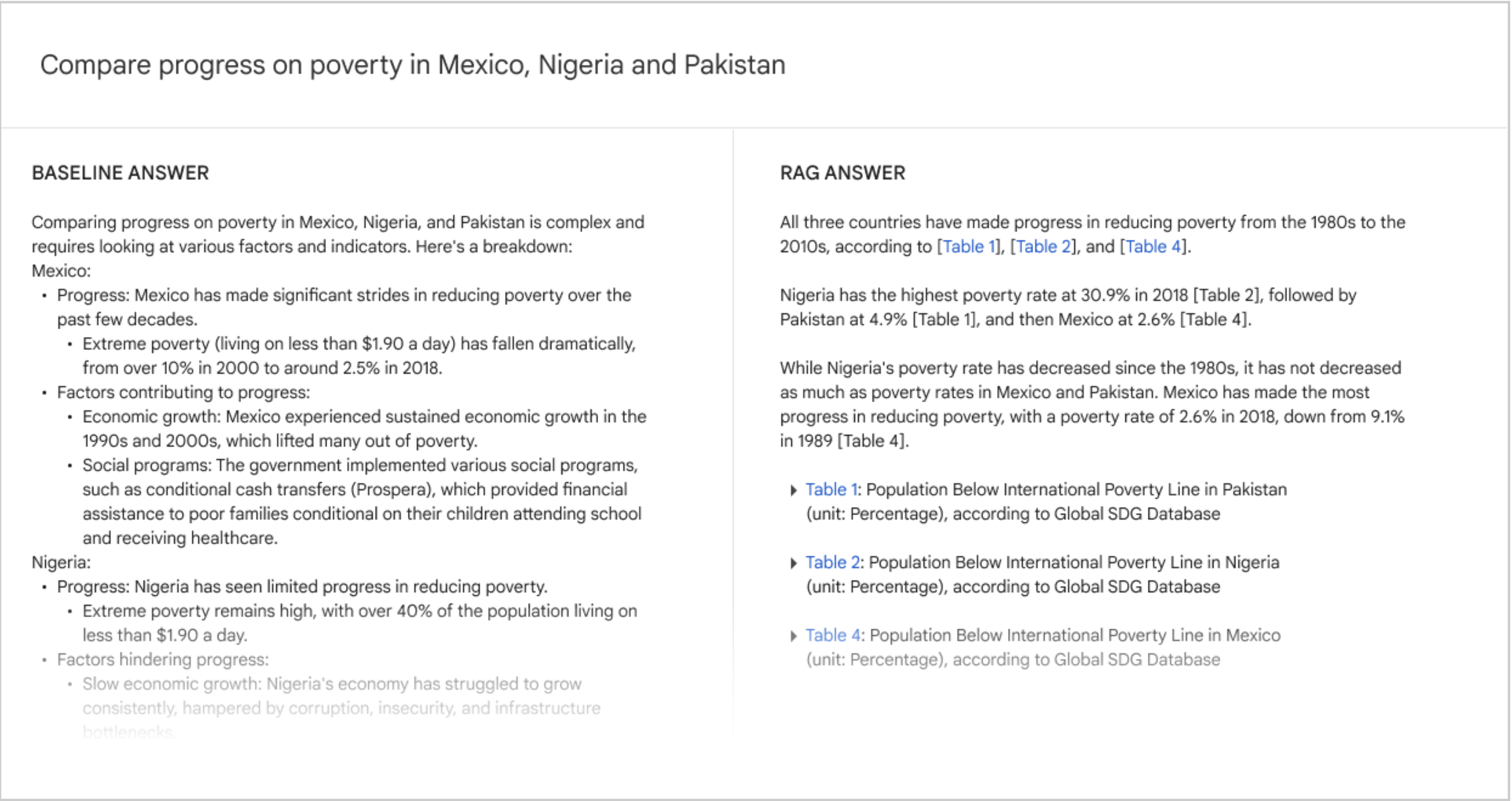
図3. クエリに対する回答の比較例; Data Commons インターフェースなしのGemini 1.5 Pro の回答と、検索拡張生成(RAG)による回答。
RIG および RAG アプローチの評価
本セクションでは、RIGとRAGの両パイプラインについて、評価方法と結果の提示方法を説明します。
結果は説得力があるかもしれませんが、我々のアプローチと結果の限界を強調すべきです。まず、101の評価クエリを手作業で作成しました。この初期セットから、Data Commonsの結果を返し、精度を評価できた小さなサブセットのクエリがあります。さらに、結果と推論の両方を慎重に検討する必要があったため、大部分の評価は論文を執筆したチームによって行われました。これにより、結果の堅牢性と一般化可能性に影響を与える可能性があり、これらの限界を十分に認識しています。
評価クエリ
101のクエリ評価セットには、以下のカテゴリのクエリが含まれています。
スコープ内クエリ(96クエリ)。これらは公的または社会的統計に関連するクエリです。つまり、クエリが統計に言及しているか、統計が回答の一部となっています。この広範なカテゴリ内で、クエリはさらに細かいカテゴリに分類できます:
- 特定の変数クエリ:特定の変数に焦点を当てたクエリ。例:「65歳以上の個人がいる米国の世帯数は?」
- 広範なトピッククエリ:より高レベルのトピックに焦点を当てたクエリ。例:「カリフォルニア州カーン郡の農業統計を教えてください」
- 場所の比較:場所を比較するクエリ。例:「マサチューセッツ州ケンブリッジとカリフォルニア州パロアルトを人口統計、教育、経済統計の観点から比較してください」
- 変数の比較:変数やトピックを比較するクエリ。例:「石炭火力発電量が多い米国の州は、COPDの発生率も高いですか?」
- リストクエリ:リストを求めるクエリ。例:「がん発生率が最も高い米国の州はどこですか?」
さらに、スコープ内クエリの中には、かなり複雑なサブカテゴリ(22クエリ)があります。これらには以下が含まれます:
-
複雑なリストクエリ:リストに対する操作を必要とするクエリ。例:「中央年齢が40歳を超える郡の中で、喘息率が最も高い郡はどこですか?」
-
興味深いクエリ:「興味深い」情報を求めるクエリ。例:「サニーベールの性別、年齢、人種、移民、健康状態、経済状況、犯罪、教育に関する興味深いトレンドは何ですか?」
-
ピアグループクエリ:類似の場所を特定するクエリ。例:「性別、年齢、人種構成の観点から、米国全体と非常に似た人口構成を持つ米国の郡はどこですか?」
-
ドリルダウンクエリ:特定の主題を掘り下げる質問を重ねたクエリ。例えば、単一のクエリ文字列として:「インドは都市部と農村部のどちらに住む人口が多いですか?それは州によってどのように異なりますか?都市人口が最も多い地区は、都市人口が最も多い州にも位置していますか?」
スコープ外クエリ(5クエリ)。これらは統計とは全く関係のないクエリです。例えば、「数字をソートするPythonスクリプトを書いてください」や「データの美しさについて俳句を作ってください」などです。これらは主に、fine-tuningによって基本のLLMに回帰が生じていないことを確認するために含まれています。
我々の評価は101のテストクエリで構成されています。評価結果における記憶効果を避けるため、手動検査と意味的類似性のチェックを組み合わせて、テストクエリとトレーニングクエリの間の明らかな重複を排除しています。
評価基準
このセクションでは、以下の基準を用いて各アプローチを詳細に評価します。
事実の正確性: RIG については、生成された統計の正確性を元のユーザークエリに対して測定します。具体的に以下の4つの量を計算します:
- Data Commons が返す統計値の正しいクエリの割合
- モデルが最初に生成した値が正しいクエリの割合
- モデルが最初に生成した値と Data Commons が返した統計値の両方が正しいクエリの割合
- モデルが最初に生成した値と Data Commons が返した統計値の両方が不正確なクエリの割合
RAG については、LLM が生成した統計的主張のうち、正確な(つまり、幻覚ではない)ものの割合を測定します。これは、生成された統計値を取得されたテーブルと比較して評価することを意味します。
これらの評価タスクの複雑さと詳細なデータのチェックの必要性から、カスタム評価ツールを構築し、自社の内部チーム(上記の著者として記載されているメンバーを含む)を使用してこれらの評価を実施しました。
Data Commons 自然言語の正確性: 元のユーザークエリを正しく解釈した Data Commons の呼び出しの割合を測定します。
質問の正確性: 生成された Data Commons の呼び出しが、文脈(RIG の場合)または元のクエリ(RAG の場合)に関連している割合を測定します。
Data Commons のデータカバレッジ: データ不足によって失敗する Data Commons の呼び出しの割合を測定します。
結果
RIG の結果
評価には fine-tuned 7B モデルと fine-tuned 27B モデルを使用します。評価セットの 101 のクエリの評価では、1つまたは複数の統計的回答に Data Commons の呼び出しを注釈付けする場合があります。それらの Data Commons の呼び出し(# DC calls)は統計(# Stats)を返すか、応答を返さない場合があります。統計が返された場合、その統計は正確、不正確、事実に関連性がない等である可能性があります。
RIG 評価方法
個々のテストクエリの応答を評価するために、部分文字列レベルでの詳細なフィードバックが必要でした。これを実現するために、評価結果の Google スプレッドシートとインターフェースする新しいビジュアルツール[図4]を使用しました。このツールにより、人間の評価者はすべてのクエリをナビゲートし、各クエリの応答にあるすべての Data Commons の呼び出しを調査することができます。評価プロセスは、明らかな事実の不正確さのクイックチェックから始まり、その後、応答に含まれる各統計の評価を行います。
人間の評価者は Data Commons に精通しており(多くは当社のデータインポートプロセスに関わる柔軟な労働力の一部です)、必要に応じて事実の正確性を検証するために統計機関のウェブサイト(census.gov等)をナビゲートする専門知識を持っています。彼らは直接のチームメンバーでも、この論文の著者として記載されている人物でもありません。
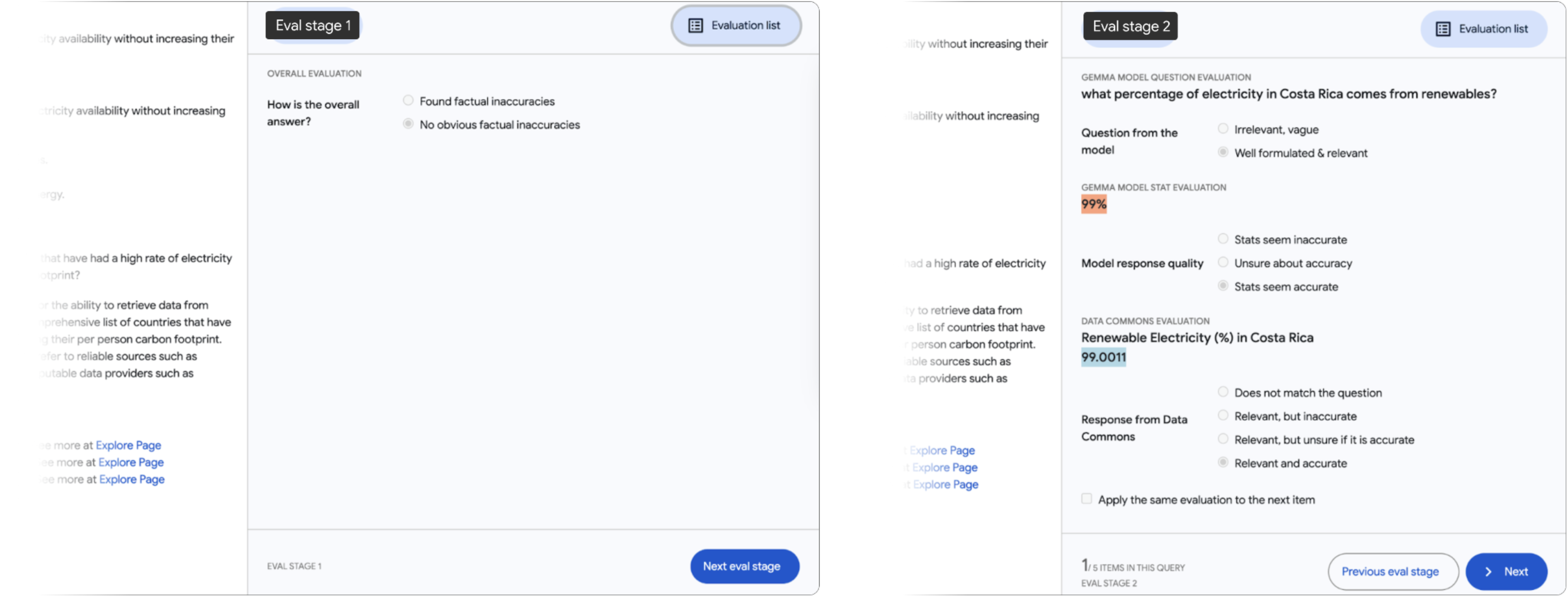
図4. RIG評価ツール。この図は、2つの評価段階のスクリーンショットを並べて示しています。各段階には2つのパネルがあります。左側には、評価対象の完全な回答がユーザーに提示されています(上の画像では空間の都合上除外されています)。右側には評価タスクがあります。ステージ1では、評価者が明らかな事実の不正確さがないかどうかを迅速にチェックします。ステージ2では、評価者が回答に含まれる各統計を評価します。
正確性
表2はRIGアプローチの事実的正確性の指標を示しています。統計数(# stats)は、101のクエリにわたってLLMの応答と比較するためにData Commonsが統計を生成したケースを表しています。全体として、RIGアプローチは事実性を5-17%から約58%に改善しています。
表2. RIGを使用した事実の正確性
| Metric | 7B Fine-tuned Percent of stats(# Statistical Values) | 27B fine-tuned Percent of stats (# Statistical Values) |
|---|---|---|
| When the Data Commons statistic was accurate | 57.7% (366) | 58.8% (114) |
| When the LLM value was accurate | 4.9% (366) | 16.7% (114) |
| When both Data Commons and LLM were accurate | 2.2% (366) | 9.7% (114) |
| When both Data Commons and LLM were wrong | 32.5% (366) | 27.2% (114) |
不正確な統計(すなわち、表2の最後の行の33-27%)は、表3に見られるように2つの理由に起因します:
- Data Commons NL インターフェースの精度の問題:Data Commons NL の実装は、多くの場合、最も近い回答のデータが不足しているため、やや関連のある回答を返します
- LLM が生成した不適切な質問:LLM は統計を完全に捉えるのに十分な精度の質問を生成しません
表3. RIG を使用した事実の不正確さに関する推論
| Inaccurate Stat Reason | 7B Fine-tuned Percent of stats (# Stats) | 27B fine-tuned Percent of stats (# Stats) |
|---|---|---|
| Incorrect Data Commons NL responses | 26.5% (366) | 21.1% (114) |
| Irrelevant LLM generated questions | 7.1% (366) | 7.0% (114) |
データカバレッジ
統計的および非統計的な検索クエリの両方を含む評価レスポンスにおいて、LLM が生成した質問のうち、Data Commons からレスポンスを引き出せるのは約 23 - 24%に過ぎないことがわかりました。
表4では、約75%のケースで統計が欠落している理由を内訳で示しています。主な理由は、Data Commons が現在、関連するすべてのデータセットを保有していないことです。これは、Data Commons を継続的に拡張し、時間とともにデータセットのカバレッジを改善する持続的な動機となっています。
表4. RIGを使用した統計探索クエリにおける欠損データの推論
| Missing Stats | 7B fine-tuned Percent of DC calls (# DC calls) | 27B fine-tuned Percent of DC calls (# DC calls) |
|---|---|---|
| Data Commons does not have the dataset | 30.0% (793) | 36.6% (407) |
| Data Commons NL understanding issues | 5.9% (793) | 18.9% (407) |
| Out of scope questions (not public statistical data) | 5.2% (793) | 4.7% (407) |
RAG の結果
RAG アプローチでは、Data Commons NL インターフェースとより互換性のある、より細かい粒度の質問を生成する最初のステップのために、Gemma-2 9B IT モデルを fine-tuned しました。
Data Commons からの応答は表形式で、さらに Gemini API を介してアクセス可能な(チューニングされていない)Gemini 1.5 Pro モデルに渡されます。14 このモデルは 2M トークンの長いコンテキストウィンドウをサポートしています。
評価方法
RAG アプローチの 2 段階の性質を考慮し、より細かい粒度の質問とそれに対する Data Commons の応答の質、および Data Commons から返された表形式のデータへの参照を含む可能性のある長文脈 LLM によって生成された最終的な応答の両方を評価しました。ステージ 1 では、人間の評価者が視覚的なツール [図 5] を使用して、Data Commons へのより細かい粒度の質問とそれに対応する応答の質を評価しました。
このプロセスは、すべての質問と Data Commons への呼び出しがユーザーのクエリの対応に関連性があり十分であることを確認するスポットチェックから始まりました。ステージ 2 では、最終的な応答の評価を行いました。ここで評価者は、応答に含まれる数値(または「統計的主張」)と LLM が参照した数値、およびそれらが由来する個別の表の数をカウントしました。さらに、評価者はこれらの数値に基づいて LLM が行った推論や推論(「推論された主張」)の正確性を追跡しました(例:「より大きい」などのテキストによる主張)[図 6]。
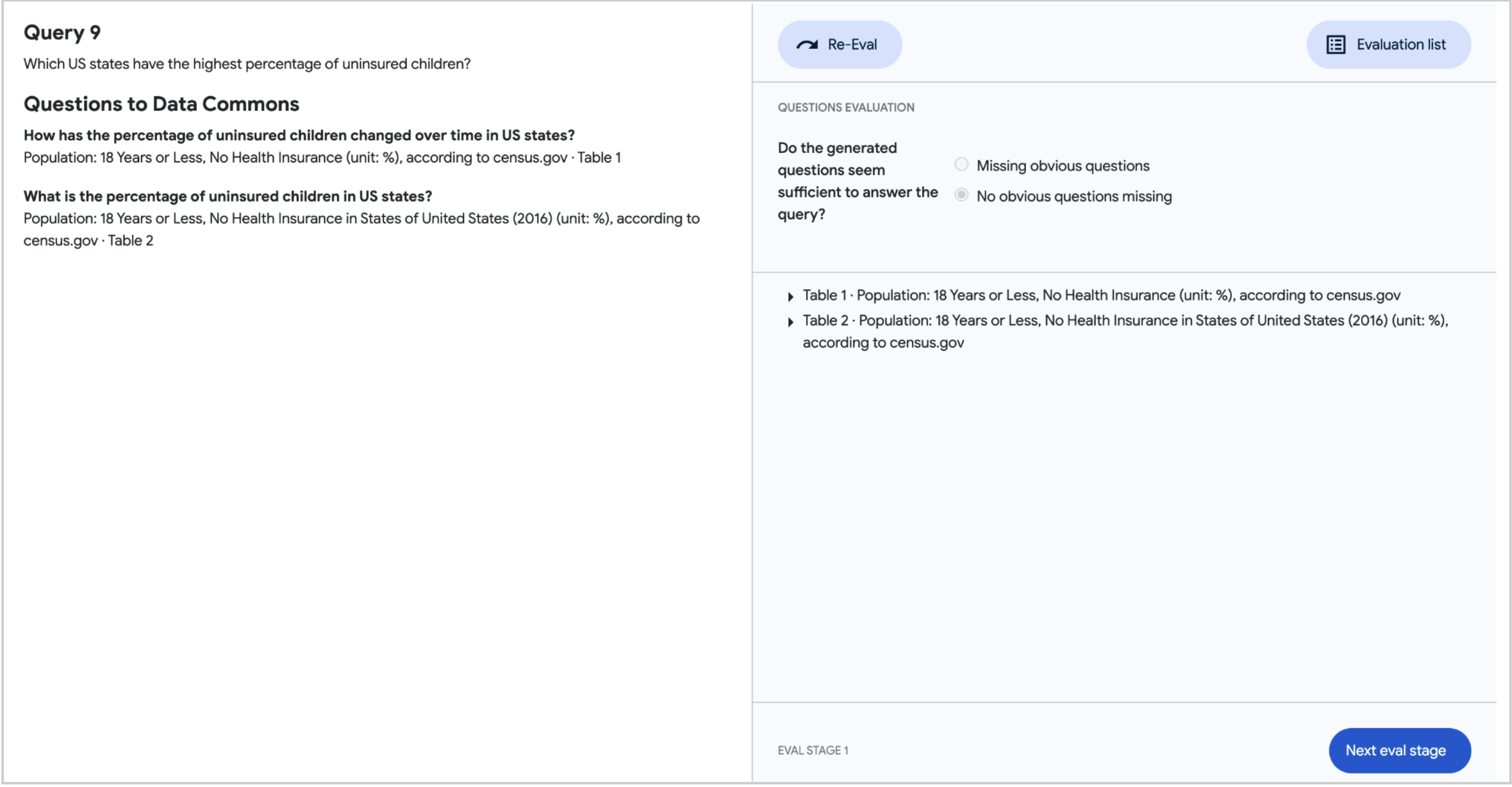
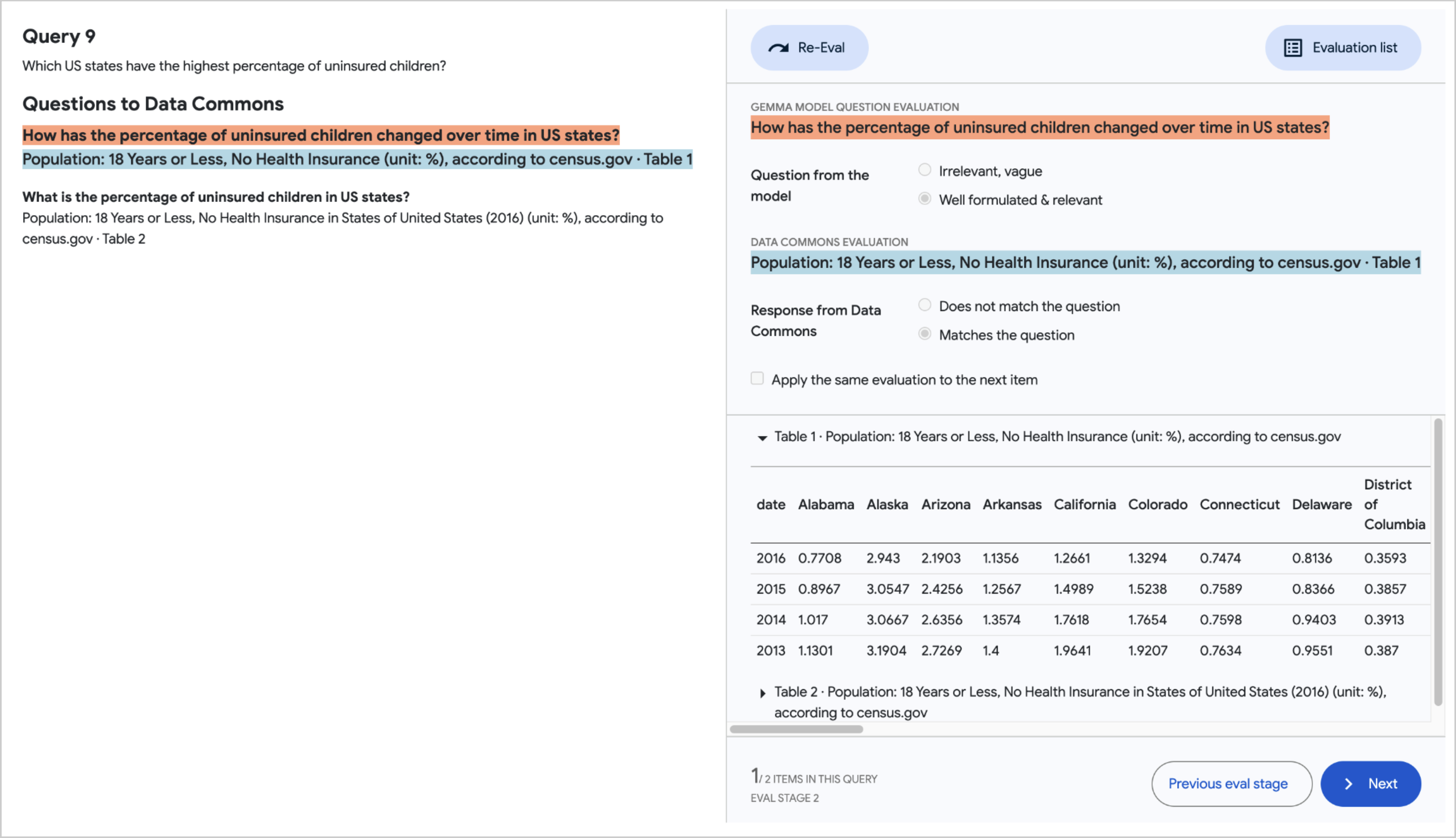
図5. RAG 評価ツールのステージ1。人間の評価者が、LLM によって生成されたより詳細な質問とそれに対応するData Commons の回答の質を評価します。まず、ユーザーのクエリの対応に十分で関連性のある質問が生成されたかどうかを確認します(上の画像)。次に、各個別の質問とそれに対応するData Commonsの回答の質を評価します(下の画像)
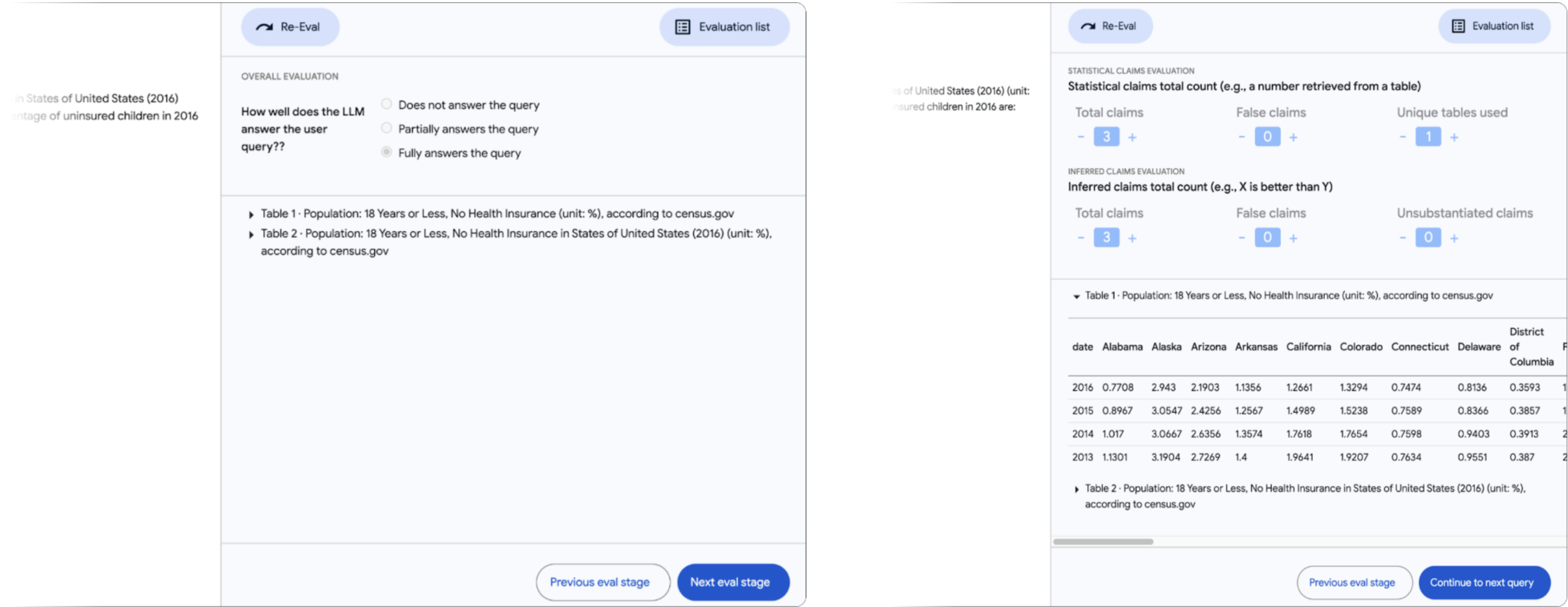
図6. RAG 評価ツールのステージ 2。評価のステージ 2では、人間の評価者がクエリに対する LLM の応答について初期の全体的な印象を提供します。その後、応答で参照されている数値(「統計的主張」)をカウントし、その出典となる表を特定します。さらに、評価者はこれらの数値に基づいて LLM が行った推論や理由付け(「推論された主張」)の正確性を評価します
正確性
表 5 はRAG アプローチの事実的正確性の指標を示しています。LLM は数字を引用する際に一般的に正確である傾向があります(99%)。これらの主張に基づいて推論を行う場合、正確性は低下し、LLM が 6 - 20%の確率で誤った推論を行います(例:トップ 5 に入るべき国を見落とす)、またはデータによって裏付けられていない推論を行います(例:中央年齢 35 歳は若い専門家や家族の大きな人口を示すと推論する)。
表5. RAG を使用した事実の正確性
| Type of claim | 9B Fine-tuned Percent of claims (# Claims) | 27B Fine-tuned Percent of claims (# Claims) |
|---|---|---|
| Accurate Statistical Claims | 98.6% (210) | 98.9% (190) |
| Accurate Inferred Claims | 71.9% (82) | 76.4% (123) |
| • Incorrect Inferred Claims | 6.1% (82) | 19.5% (123) |
| • Unsubstantiated Inferred Claims | 22.0% (82) | 4.1% (123) |
カバレッジ
全体として、LLMは評価セット内のクエリの24〜29%の間でのみ、Data Commons からの統計的な回答を提供しています。カバレッジが低い理由は、RIG 評価で見られたものと同様であり、表 6 に示されている質問生成モデルの有効性も関係しています。
表6. RAG を使用した事実の不正確さに関する推論
| Missing Coverage Reason | 9B Fine-tuned Percent of queries (77) | 27B Fine-tuned Percent of queries (72) |
|---|---|---|
| Fine-tuned model generated incomplete or incorrect queries for Data Commons | 40.3% | 30.6% |
| Data Commons does not have relevant datasets | 37.5% | 43.1% |
| Data Commons NL understanding issues | 2.8% | 6.9% |
| Stats tables not used by answer model | 11.1% | 8.3% |
| Out of scope queries (not public statistical data) | 8.3% | 11.1% |
さらに、表 7 に示すように、評価セット全体の 101 のクエリに対して、RAG アプローチと Gemini 1.5 Pro のベースモデルの性能を比較しました。この表は、LLM に関連データが提供された場合、より具体的な統計的主張を行い、提供されたデータを応答に使用する可能性が高くなるという励みになる結果を示しています。
表7. Gemini 1.5 Pro ベースモデルに対する RAG のカバレッジ
| Metric | 9B Fine-tuned | 27B Fine-tuned | Gemini 1.5 Pro Base Model |
|---|---|---|---|
| Percent of queries with statistical claims | 24% (101) | 29% (101) | 9% (101) |
| Number of statistical claims | 210 | 190 | 28 |
| Accuracy of statistical claims | 98.6% (210) | 98.9% (190) | 39% (28) |
マクロ評価
日常的にウェブを利用するユーザーの視点から、以下のことを明らかにしたいと考えています:
- RIGは 役立つように見えるか?
- つまり、クエリを fine-tune されていないモデルに渡す場合と比較して RIG はどうか
- RAGは役立つように見えるか?
- つまり、Data Commons の統計データなしでクエリをモデルに渡す場合と比較して RAG はどうか
これを達成するために、人間の評価者による側面比較ビジュアルツール[図7]を使用します。評価者はData Commonsやこの取り組みに精通していない人々です。
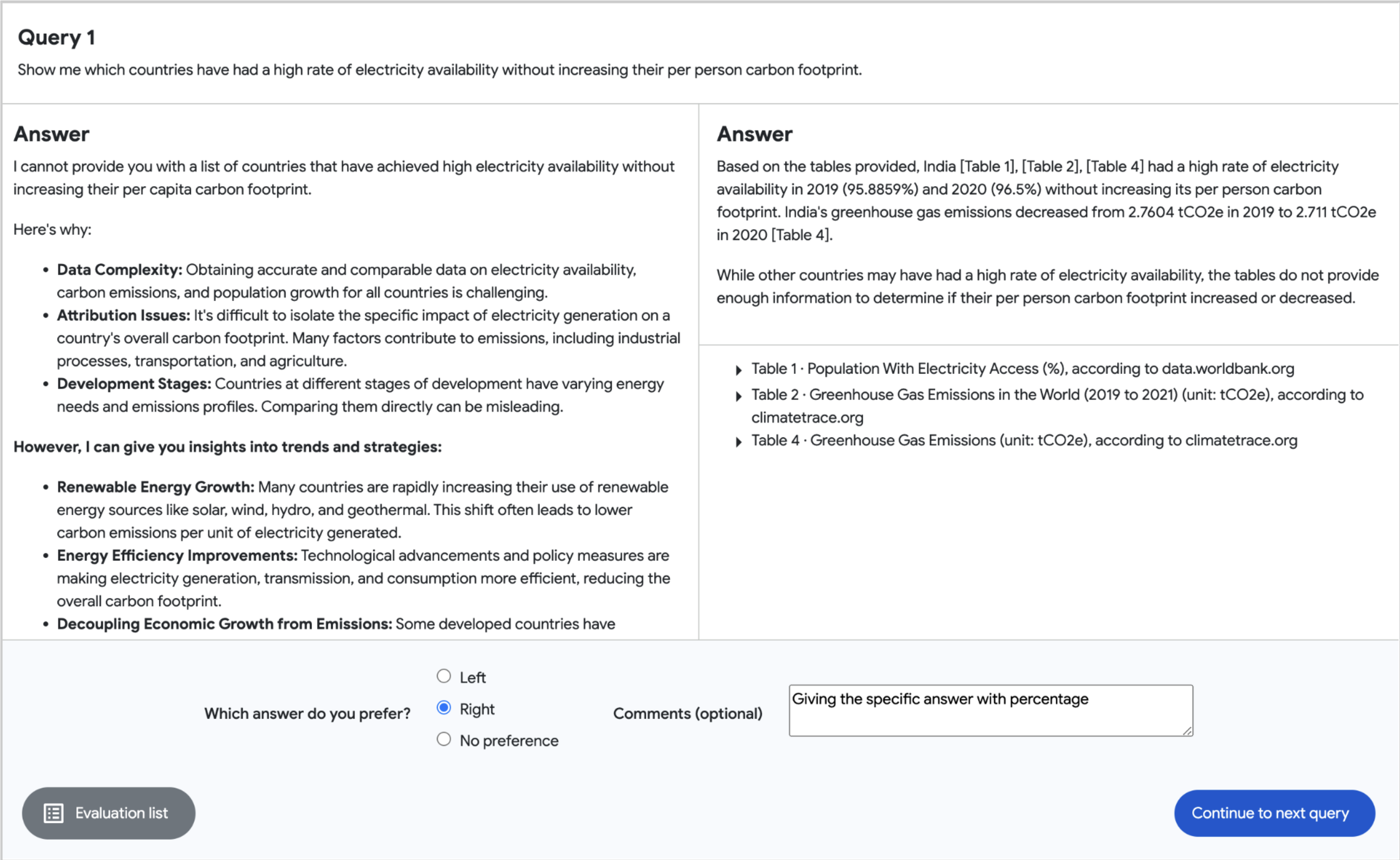
図7. RAG の並列評価ツールのスクリーンショット
RIG
RIG では、プリファレンスは 2 つの側面から影響を受ける可能性があります:fine-tuning がモデルの応答にどのように影響を与えたか、そして回答に統計情報が含まれる場合の脚注の存在です。図 2 は、脚注付きの RIG の回答をどのように視覚で表現したかを示しています。
表 8 は、評価者がベースモデルよりも RIG の回答を好む傾向が多かったことを示しています。27B モデル(76%)の方が 7B モデル(62%)よりもプリファレンスが高くなっています。
回答を比較すると、fine-tuning によってモデルがベースモデルよりも多くの統計情報を生成する傾向にあります。さらに、評価者は統計情報を含む回答を好む傾向があり、これが RIG の回答がベースモデルよりも高いプリファレンスを得た理由かもしれません。
27B RIG の回答が 7B よりも高いプリファレンスを得た理由は、27B ベースモデルが 7B よりも統計情報を生成する傾向が低く、fine-tune された 7B モデルが回答においてより幻覚を起こしやすいためだと考えています。
表8. RIG回答に対するユーザーの選好
| RIG 7B (# samples) | RIG 27B (# samples) |
|---|---|
| 62% (101) | 76% (101) |
RAG
RAGを評価する際、9Bモデルを使用した101件の最終回答のうち24件、27Bモデルを使用した101件の最終回答のうち29件のみがData Commonsの表から統計値を含んでいました。表が使用されたこれらのサンプルのうち、ユーザーはベースラインよりもRAGの回答を好む傾向がありました(表9に示されるように92-100%)。この結果は非常に有望であり、Data Commonsのデータカバレッジが増加するにつれて、RAGアプローチの有効性も向上するでしょう。
表9. RAG回答に対するユーザーの選好
| RAG 9B (# samples) | RAG 27B (# samples) | |
|---|---|---|
| When RAG answer with Data Commons stats is preferred | 92% (24) | 100% (29) |
オープンソースリソース
Data Commons はオープンプロジェクトです。関連するソフトウェアがすべてオープンソースであるだけでなく、データも無料で利用可能です。Data Commons のようなリソースは、LLM をより信頼性の高いものにするために不可欠です。さらに、研究目的のために、Data Commons クエリを解決するためのオープンエンドポイントを無料で提供しています(1日あたり最大100クエリまで)。詳細は docs.datacommons.org をご覧ください。
責任あるAI
- Data Commons 自然言語インターフェースの発表前に、誤解を招く、論争を呼ぶ、または扇動的な結果をもたらす可能性のある潜在的に危険なクエリに対して、レッドチームによるチェックを行いました。
- これらの同じクエリを RIG および RAG モデルの出力に対して実行し、クエリの応答が論争を呼ぶものの、危険ではない例をいくつか発見しました。
免責事項
モデルの初期バージョンをリリースしています。これらは信頼できるテスター(主に学術および研究目的)向けであり、商業利用や一般公開にはまだ準備ができていません。このバージョンは非常に小さな例のコーパスで訓練されており、意図しない、時には論争を呼ぶまたは扇動的な振る舞いを示す可能性があります。この LLM インターフェースを積極的に開発している段階であるため、エラーや制限があることを予めご了承ください。
モデルのパフォーマンス改善に関するフィードバックと評価を歓迎します。既知の制限事項はレビューアーガイドに詳細が記載されており、モデルの現在の能力を包括的に理解するためにそれを参照することをお勧めします。
今後の課題
私たちの研究は継続中であり、この作業を拡大し、厳密なテストを行い、最終的にはこの強化された機能を Gemma と Gemini の両方に段階的な限定アクセスアプローチを通じて統合していくにつれて、これらの方法論をさらに洗練させることに取り組んでいます。
今後取り組む予定のいくつかの分野があります:
- モデルの fine-tuning トレーニングセットの品質と量を改善します。現在、トレーニングセットはかなり小さく(最大約600)、より大規模な fine-tuning データセット(10万または100万)を作成する必要があります。現時点では、トレーニングセットは Data Commons データの限られた範囲しかカバーしておらず、はるかに広範なカバレッジで改善する必要があります。
- Data Commons の自然言語処理能力を向上させます。これは、クエリ理解からデータカバレッジまでの幅広い作業を示し、RIG および RAG アプローチを大幅に改善します。
- 統計情報に対する Gemini のパフォーマンスを評価します。これは fine-tuning データセットの生成に重要な役割を果たし、fine-tuned モデルの動作に直接影響します。結果を表示するための異なるユーザーインターフェースとエクスペリエンスをテストします。LLM 出力の上に根拠のある事実を目立つように表示することで、この作業から最大の価値を引き出すことができます。正しいユーザーエクスペリエンスを確定させるために、複数回のユーザーリサーチとプロトタイピングを行う必要があります。
謝辞
Data Commons チームがオープンソースの取り組みを開発する上でサポートしてくれた Google の同僚たちに感謝します。特に、論文に対する複数回のフィードバックを提供してくれた Neel Guha に感謝します。また、論文の編集とフィードバックを行ってくれた Methods+Mastery チームとサマンサ・ピエコスに感謝します。このプロジェクトにサポートを提供してくれた多くの人々に深い感謝の意を表します:
チームメンバー
- Data Commons: Julia Wu、Carolyn Au、Dan Noble、Keyur Shah、Ajai Tirumali、Hareesh M. S.、Natalie Diaz、Kara Moscoe、Kia Burke、Luiza Staniec、Luke Garske、Samantha Piekos、Christie Ellks。
- Gemma および Google DeepMind: Tris Warkentin、Victor Cotruta、Robert Dadashi、Glenn Cameron、Surya Bhupatiraju、Jeremy Sie、Meg Risdal、Kat Black、Nam Nguyen。
外部パートナー
- 主要なグローバルデータセットが公開されAI対応であることを確保してくれた国連経済社会局統計部(UN DESA)のパートナーに感謝します。
- 結果の評価と評価ツールの複数回の反復をサポートしてくれた Infosys チームと非営利の社会的企業であるDigital Divide Data に感謝します。
著者の貢献
概念化、方法論、評価、分析、可視化、ソフトウェアの作業は著者間で共有されました。原稿は著者によって共同で執筆されました。すべての著者が最終稿を読み、承認しました。
データとコードの可用性
DataGemma を実行するためのクライアントライブラリは、Apache 2.0オープンソースライセンスの下で以下で利用可能です:https://github.com/datacommonsorg/llm-tools
さらに、HuggingFace または Kaggle で DataGemma の埋め込みの重みを試すことができます:
- RIG:
- RAG:
Colab ノートブック:
- RIG: https://colab.research.google.com/github/datacommonsorg/llm-tools/blob/master/notebooks/datagemma_rig.ipynb
- RAG: https://colab.research.google.com/github/datacommonsorg/llm-tools/blob/master/notebooks/datagemma_rag.ipynb
サンプルプロンプトとトレーニングセットは付録に提供されています。
利益相反の宣言
すべての著者は、この作業時に Google に雇用されているか、雇用されていました。
参考文献
- Bubeck S, Chandrasekaran V, Eldan R, Gehrke J, Horvitz E, Kamar E, et al. Sparks of Artificial General Intelligence: Early experiments with GPT-4. CoRR. 2023;abs/2303.12712. DOI: https://doi.org/10.48550/arXiv.2303.12712
- LLM hallucination - Google Scholar [Internet]. [cited 2024 Jul 11]. Available from: https://scholar.google.com/scholar?hl=en&as_sdt=0%2C31&q=llm+hallucination&oq=LLM+hall
- Grounding overview | Generative AI on Vertex AI | Google Cloud [Internet]. [cited 2024 Jul 11]. Available from: https://cloud.google.com/vertex-ai/generative-ai/docs/grounding/overview
- Schick T, Dwivedi-Yu J, Dessì R, Raileanu R, Lomeli M, Zettlemoyer L, et al. Toolformer: Language Models Can Teach Themselves to Use Tools. CoRR . 2023;abs/2302.04761. DOI: https://doi.org/10.48550/arXiv.2302.04761
- Gao Y, Xiong Y, Gao X, Jia K, Pan J, Bi Y, et al. Retrieval-Augmented Generation for Large Language Models: A Survey. CoRR. 2023;abs/2312.10997. DOI: https://doi.org/10.48550/arXiv.2312.10997
- Guha RV, Radhakrishnan P, Xu B, Sun W, Au C, Tirumali A, et al. Data Commons. CoRR. 2023;abs/2309.13054. DOI: https://doi.org/10.48550/arXiv.2309.13054
- Gemma Team: Riviere M, Pathak S, Sessa PG, Hardin C, Bhupatiraju S, et al. Gemma 2: Improving Open Language Models at a Practical Size. CoRR. 2024;abs/2408.00118. DOI: https://arxiv.org/abs/2408.00118
- Lewis PS, Perez E, Piktus A, Petroni F, Karpukhin V, Goyal N, et al. 検索拡張生成 for Knowledge-Intensive NLP Tasks. CoRR. 2020;abs/2005.11401. DOI: https://doi.org/10.48550/arXiV.2005.11401
- Zhou C, Liu P, Xu P, Iyer S, Sun J, Mao Y, et al. LIMA: Less Is More for Alignment. CoRR. 2023;abs/2305.11206. DOI: https://doi.org/10.48550/arXiv.2305.11206
- R. V. Guha, Dan Brickley, and Steve Macbeth. 2016. Schema.org: evolution of structured data on the web. Commun. ACM 59, 2 (February 2016), 44–51. https://doi.org/10.1145/2844544
- Gemini Team, Georgiev P, Lei VI, Burnell R, Bai L, Gulati A, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. CoRR. 2024;abs/2403.05530. DOI: [https://arxiv.org/abs/2403.05530]
- Google. Data Commons API [Internet]. Mountain View (CA): Google; [cited 2024 Sep 4]. Available from: https://developers.google.com/docs/api/reference/rest
- World Bank. Statistical Performance Indicators - World Bank. [Internet]. Washington, DC: The World Bank; [cited 2024 Sep 4]. Available from: https://www.worldbank.org/en/programs/statistical-performance-indicators
- Google. Gemini API Documentation [Internet]. Mountain View (CA): Google; [cited 2024 Sep 4]. Available from: https://ai.google.dev/gemini-api/docs
Appendix
(すみません、省略です)