こんな記事が出ていたので翻訳してみました。
この記事は何?
このチュートリアルは、Anthropic が公開した 2 部構成のクイックスタート(part 1、part 2)に基づいています。本稿では、Amazon Bedrock をモデルプロバイダーとして Model Context Protocol(MCP)を 機能させる方法を紹介します。
さらに、実際のビジネス問題を解決するためにツールボックスを拡張します:ブログ投稿を要約し、含まれているすべてのリンクが読者にとって利用可能かどうかを確認するエージェントシステムを構築したいと考えています。
Anthropicのモデルコンテキストプロトコル(MCP)とは?
公式ドキュメントから引用すると、
MCP は Anthropic によってリリースされたオープンプロトコルで、アプリケーションがLLMにコンテキストを提供する方法を標準化します。MCP は AI アプリケーション用の USB-C ポートのようなものと考えてください。USB-C がデバイスをさまざまな周辺機器やアクセサリに接続する標準化された方法を提供するように、MCP は AI モデルをさまざまなデータソースやツールに接続する標準化された方法を提供します。
詳細については、公式ドキュメントのこの紹介をご覧ください。
高レベルでは、MCP は双方向通信を備えたクライアント/サーバーアーキテクチャを実装しています。その通信プロトコルは、2 つの転送メカニズムを通じて提供されます:
- 標準入出力(Stdio transport)
- 通信に標準入出力を使用
- ローカルプロセスに最適
- HTTP with SSE transport
- サーバーからクライアントへのメッセージにServer-Sent Eventsを使用
- クライアントからサーバーへのメッセージに HTTP POST を使用
すべての転送は JSON-RPC 2.0 を使用してメッセージを交換します。Model Context Protocol メッセージ形式の詳細については仕様を参照してください。
このサンプルでは標準入出力を探索します。つまり、MCP クライアントとサーバーの両方を同じマシン上でホストすることになります。
HTTP を介して通信する MCP サーバーを実装・デプロイする方法を見たい場合は、コメントでお知らせください。Fargate や Lambda などでの実装を検討しています...!
なぜ MCP が優れていると考えるのか
MCP の主な利点は、異なるチームが AI 駆動アプリケーションで協力しやすくなることです。マイクロサービスアーキテクチャの異なるチームが独立して作業できるようにするのと同様に、MCP は異なる組織機能間に明確な境界を作り出します。
ツール開発者は、コア AI システムを妨げることなく機能を自由に作成・更新でき、AI チームはツール実装の詳細に巻き込まれることなく(LLM との)会話品質の向上に集中できます。コンポーネント間の明確なインターフェースにより、各チームは独自のペースで、独自の開発サイクルに従って作業できます。
おそらく最も重要なのは、組織がシステム全体の変更を必要とせずに新しい機能を段階的に追加できることで、時間の経過とともに AI システムを進化させやすくなります。AI の開発に対するこのモジュラーアプローチは、コンポーネント間の疎結合がより保守性の高い拡張可能なシステムにつながる、現代のソフトウェアアーキテクチャで見られる成功したパターンを反映しています。
さらに、例えば SaaS プロバイダーについて考えると、顧客はインターフェースや差別化されていない重労働について心配するのではなく、自社製品の機能構築に集中できます。この標準が整備されていれば、時間のかかる統合作業なしに簡単に自社のサービスを組み込むことができます。
最後に、技術的な観点から、完全に分散されたアーキテクチャのすべての利点(そして負担!)を得ることができます。これにより、コンポーネントのライフサイクルを独立してスケールおよび管理でき、パフォーマンス向上、コスト最適化、簡単な実験のためにツールとモデルを A/B テストでき、リソースを細かく割り当てて需要に素早く対応し、クラウド構築の弾力性を十分に活用できるようになります。
Architecture & Flows
以下は、私たちが実装するアーキテクチャと会話の流れの内訳です。
下の 2 枚の画像に示されている「この $URL にあるブログ記事の要約を取得して」という単純なプロンプトの旅を、ステップバイステップで追跡していきます。これにより、簡単に理解できるようになります。
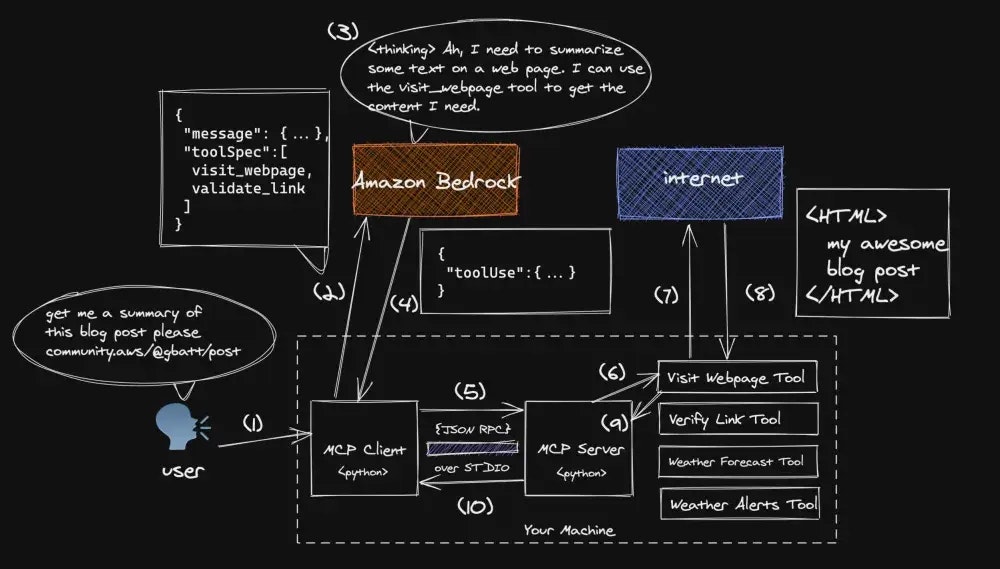
-
人間にとってウェブページを読んでその要約を提供するタスクは簡単ですが、LLM は通常、ウェブページにアクセスしてパラメトリックメモリ外のコンテキストを取得することができません。そのため、ツールが必要です
-
ユーザープロンプトと、MCP サーバーを介して Amazon Bedrock Converse API に仲介される利用可能なツールのリストを提供します。この場合、Amazon Bedrock は多くのモデルへの統一インターフェースとして機能しています
-
ユーザープロンプトとツールインベントリに基づいて、選択されたモデルは適切な応答を計画します
-
この場合、モデルは正しく提供された URL のコンテンツをダウンロードするために
visit_webpageツールを使用する計画を立てます。Bedrock はクライアントにtoolUseメッセージを返し、選択されたツールの名前、ツールリクエストの入力、および後続のメッセージで使用できる一意のtoolUseIdを含みます。Bedrock Converse API におけるtoolUseの構文と使用法についての詳細は、これらのドキュメントをお読みください -
クライアントは
toolUseメッセージをMCPサーバーに転送するようプログラムされています。私たちの実装では、通信は同じマシン上で JSON-RPC を介して標準入出力で行われます -
MCP サーバーは
toolUseリクエストを適切なツールにディスパッチします -
visit_webpageツールが呼び出され、提供された URL に HTTP リクエストが行われます -
ツールは提供された URL にあるコンテンツをダウンロードし、そのコンテンツをマークダウン形式で返すようプログラムされています
-
コンテンツは MCP サーバーに転送されます
-
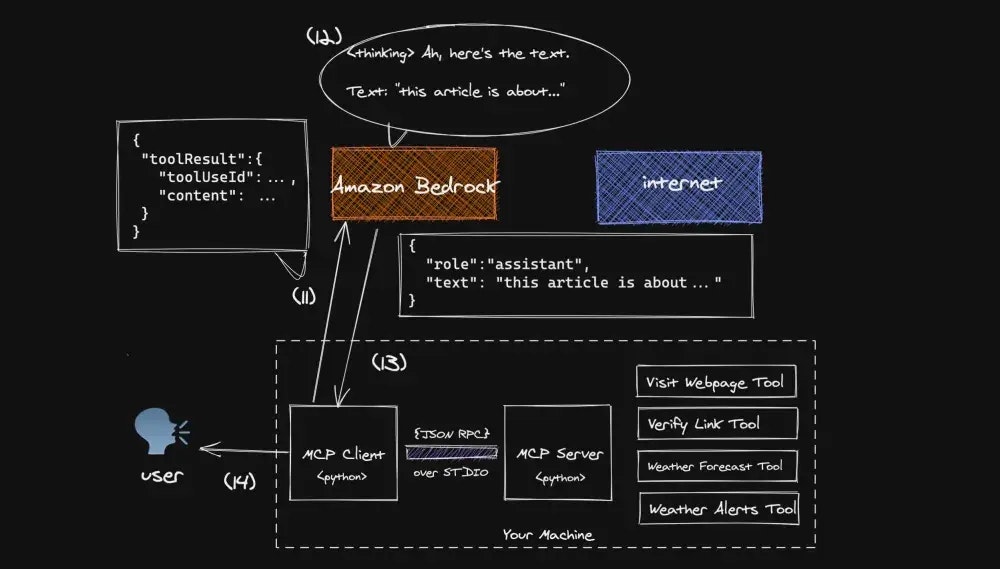
フロー制御はMCPクライアントに戻ります。次の図に示されている11-14のステップで旅を完了します
-
MCP クライアントは、Step 4 で提供された
toolUseIdを含むtoolResultメッセージを会話履歴に追加し、それを Bedrock に転送します。toolResult構文の詳細については、ドキュメントをお読みください -
Bedrockは、ツールの結果を使用して最終的な応答を作成する計画を立てます
-
応答はクライアントに送り返され、クライアントは会話フローの制御をユーザーに戻すようプログラムされています
-
ユーザーはMCPクライアントからの応答を受け取り、新しいフローを開始する自由があります
前提条件
始める前に、以下のタスクを完了する必要があります:
- Python で MCP サーバーを作成する方法を示すこのチュートリアルを完了してください。チュートリアルの最後には、
get_alertsとget_weatherという 2 つのツールを提供する動作中の MCP サーバーが完成しているはずです。これには、高速で安全な Python ランタイムとパッケージマネージャーである uv のインストールも含まれています - 環境内で AWS 認証情報をエクスポートして、boto3 から利用できるようにしてください
💡 この方法についての詳細は、AWS Boto3 ドキュメント(Developer Guide > Credentials)を参照してください。
Bedrock 用の MCP クライアントを作る
さあ、MCP と Amazon Bedrock を実際に使ってみましょう。新しいクライアントを構築する前に、上記の前提条件セクションにリンクされているチュートリアルを完了していることを確認してください!
プロジェクトのセットアップ
プロジェクトツリーは、(これから作成する mcp-client フォルダを除いて)このようになっているはずです。

weather/ ディレクトリにいる場合は、一つ上の階層に移動して新しい Python プロジェクトを作成してください。
cd ..
uv init mcp-client
main.py を削除して、client.py という新しいファイルを作成します。
cd mcp-client
rm main.py
touch client.py
uv を通じて以下のパッケージをインストールする必要があります。
uv add mcp boto3
Imports
MCP サーバーセッションへのアクセスを管理するために mcp パッケージを使用し、もちろん Bedrock の良さを加えるために boto3 も少し使っています。
# client.py
import asyncio
import sys
from typing import Optional, List, Dict, Any
from contextlib import AsyncExitStack
from dataclasses import dataclass
# to interact with MCP
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
# to interact with Amazon Bedrock
import boto3
Bedrock メッセージのマッピング
このヘルパークラスでは、Bedrock Converse API から送られてくるメッセージを、ビジネスロジックで使用できるオブジェクトにマッピングしています。また、MCP サーバーでのツール定義を Bedrock Converse API 構文にマッピングするユーティリティメソッドも定義しています。データを少し加工しているだけで、特に凝ったことはしていません。
# client.py
@dataclass
class Message:
role: str
content: List[Dict[str, Any]]
@classmethod
def user(cls, text: str) -> 'Message':
return cls(role="user", content=[{"text": text}])
@classmethod
def assistant(cls, text: str) -> 'Message':
return cls(role="assistant", content=[{"text": text}])
@classmethod
def tool_result(cls, tool_use_id: str, content: dict) -> 'Message':
return cls(
role="user",
content=[{
"toolResult": {
"toolUseId": tool_use_id,
"content": [{"json": {"text": content[0].text}}]
}
}]
)
@classmethod
def tool_request(cls, tool_use_id: str, name: str, input_data: dict) -> 'Message':
return cls(
role="assistant",
content=[{
"toolUse": {
"toolUseId": tool_use_id,
"name": name,
"input": input_data
}
}]
)
@staticmethod
def to_bedrock_format(tools_list: List[Dict]) -> List[Dict]:
return [{
"toolSpec": {
"name": tool["name"],
"description": tool["description"],
"inputSchema": {
"json": {
"type": "object",
"properties": tool["input_schema"]["properties"],
"required": tool["input_schema"]["required"]
}
}
}
} for tool in tools_list]
クライアント定義
簡潔にするため、クライアントのすべてのビジネスロジックを1つのクラス、MCPClient にパッケージ化しています
# client.py
class MCPClient:
MODEL_ID = "anthropic.claude-3-sonnet-20240229-v1:0"
def __init__(self):
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
async def connect_to_server(self, server_script_path: str):
if not server_script_path.endswith(('.py', '.js')):
raise ValueError("Server script must be a .py or .js file")
command = "python" if server_script_path.endswith('.py') else "node"
server_params = StdioServerParameters(command=command, args=[server_script_path], env=None)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
response = await self.session.list_tools()
print("\nConnected to server with tools:", [tool.name for tool in response.tools])
async def cleanup(self):
await self.exit_stack.aclose()
-
self.sessionは、確立している MCP セッションにマッピングするオブジェクトです。この場合、同じマシン上でホストされているツールを使用するため、stdioを使用します -
self.bedrockは、Amazon Bedrock のランタイム API とやり取りするためのメソッドを提供する AWS SDK クライアントを作成します。これにより、基盤モデルと通信するための converse などの API 呼び出しが可能になります -
self.exit_stack = AsyncExitStack()は、プログラム終了時に複数の非同期リソース(ネットワーク接続やファイルハンドルなど)を自動的に逆順にクリーンアップするコンテキストマネージャーを作成します。これは入れ子になったasync withステートメントのスタックに似ていますが、より柔軟でプログラム的です。self.exit_stackは、公開されているcleanupメソッドで未処理の処理を終了するために使用されています -
connect_to_serverメソッドは、MCP ツールを実装する Python または Node.js スクリプトとの双方向通信チャネルを確立します。メッセージの受け渡しには標準入出力(stdio)を使用し、クライアントがサーバースクリプトによって公開されているツールを検出して呼び出すことを可能にするセッションを初期化します
クエリの処理
ビジネスロジックの核心に近づきましょう。
# client.py
def _make_bedrock_request(self, messages: List[Dict], tools: List[Dict]) -> Dict:
return self.bedrock.converse(
modelId=self.MODEL_ID,
messages=messages,
inferenceConfig={"maxTokens": 1000, "temperature": 0},
toolConfig={"tools": tools}
)
async def process_query(self, query: str) -> str:
# (1)
messages = [Message.user(query).__dict__]
# (2)
response = await self.session.list_tools()
# (3)
available_tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
} for tool in response.tools]
bedrock_tools = Message.to_bedrock_format(available_tools)
# (4)
response = self._make_bedrock_request(messages, bedrock_tools)
# (6)
return await self._process_response( # (5)
response, messages, bedrock_tools
)
-
_make_bedrock_requestメソッドは、Amazon Bedrockの会話APIにリクエストを送信するプライベートヘルパーです。会話履歴(messages)、利用可能なツール、およびモデル設定パラメータ(トークン制限や temperature)を渡して、会話の次のターンに対する基盤モデルからの応答を取得します。これを複数の異なるメソッドで使用します -
process_queryメソッドはクエリ処理フロー全体を統括します:- ユーザーのクエリからメッセージを作成
- 接続されたサーバーから利用可能なツールを取得
- ツールをBedrockの期待する構造にフォーマット
- クエリとツールを使用してBedrockにリクエストを送信
- 会話の複数のターンを通じてレスポンスを処理(ツールの使用が必要な場合)
- 最終的な応答を返す
これはユーザークエリを処理し、ユーザー、ツール、基盤モデル間の会話フローを管理するためのメインエントリーポイントです。会話が実際にどう処理されるかを詳しく見ていきましょう。
会話の順番
これは、ユーザーと Bedrock の両方からのあらゆる種類のリクエストを処理する会話ループです。さあ、始めましょう!
# client.py
async def _process_response(self, response: Dict, messages: List[Dict], bedrock_tools: List[Dict]) -> str:
# (1)
final_text = []
MAX_TURNS=10
turn_count = 0
while True:
# (2)
if response['stopReason'] == 'tool_use':
final_text.append("received toolUse request")
for item in response['output']['message']['content']:
if 'text' in item:
final_text.append(f"[Thinking: {item['text']}]")
messages.append(Message.assistant(item['text']).__dict__)
elif 'toolUse' in item:
# (3)
tool_info = item['toolUse']
result = await self._handle_tool_call(tool_info, messages)
final_text.extend(result)
response = self._make_bedrock_request(messages, bedrock_tools)
# (4)
elif response['stopReason'] == 'max_tokens':
final_text.append("[Max tokens reached, ending conversation.]")
break
elif response['stopReason'] == 'stop_sequence':
final_text.append("[Stop sequence reached, ending conversation.]")
break
elif response['stopReason'] == 'content_filtered':
final_text.append("[Content filtered, ending conversation.]")
break
elif response['stopReason'] == 'end_turn':
final_text.append(response['output']['message']['content'][0]['text'])
break
turn_count += 1
if turn_count >= MAX_TURNS:
final_text.append("\n[Max turns reached, ending conversation.]")
break
# (5)
return "\n\n".join(final_text)
-
_process_responseメソッドは最大10ターン(MAX_TURNS)の会話ループを初期化し、応答をfinal_textで追跡します - モデルがツールの使用をリクエストすると、思考ステップ(
text)とツール実行ステップ(toolUse)の両方を処理してリクエストを処理します - ツール使用の場合、ツールハンドラーを呼び出し、ツールの結果を含む新しいリクエストを Bedrock に送信します。ツールはローカルの MCP サーバーでホストしていることを覚えておいてください
- また、適切なメッセージを追加してループを終了することで、様々な停止条件(最大トークン数、コンテンツフィルタリング、停止シーケンス、ターン終了)も処理します
- 最後に、蓄積されたすべてのテキストを改行で結合し、完全な会話履歴を返します
ツールリクエストのハンドリング
# client.py
async def _handle_tool_call(self, tool_info: Dict, messages: List[Dict]) -> List[str]:
# (1)
tool_name = tool_info['name']
tool_args = tool_info['input']
tool_use_id = tool_info['toolUseId']
# (2)
result = await self.session.call_tool(tool_name, tool_args)
# (3)
messages.append(Message.tool_request(tool_use_id, tool_name, tool_args).__dict__)
messages.append(Message.tool_result(tool_use_id, result.content).__dict__)
# (4)
return [f"[Calling tool {tool_name} with args {tool_args}]"]
-
_handle_tool_callメソッドは、提供された情報からツールの名前、引数、IDを抽出してツールリクエストを実行します - このメソッドはセッションインターフェースを通じてツールを呼び出し、その結果を待ちます
- 会話履歴にツールリクエストとその結果の両方を記録します。これは、私たちが他の場所(つまり、あなたのマシン上で実行されているツール)で誰かと会話したことをBedrockに知らせるためです
- 最後に、どのツールがどの引数で呼び出されたかを示す書式化されたメッセージを返します
このメソッドは、基本的にモデルの(Bedrockから来る)ツール使用リクエストと実際のツール実行システム(あなたのマシンで実行される)の間の橋渡しの役割を果たします。
チャットしよう
chat_loop メソッドは、ユーザー入力を継続的に受け付け、システムを通じてクエリを処理し、ユーザーが 'quit' と入力するかエラーが発生するまで応答を表示するシンプルなインタラクティブなコマンドラインインターフェースを実装しています。
# client.py
async def chat_loop(self):
print("\nMCP Client Started!\nType your queries or 'quit' to exit.")
while True:
try:
query = input("\nQuery: ").strip()
if query.lower() == 'quit':
break
response = await self.process_query(query)
print("\n" + response)
except Exception as e:
print(f"\nError: {str(e)}")
最後にこれがエントリーポイントです。
# client.py
async def main():
if len(sys.argv) < 2:
print("Usage: python client.py <path_to_server_script>")
sys.exit(1)
client = MCPClient()
try:
await client.connect_to_server(sys.argv[1])
await client.chat_loop()
finally:
await client.cleanup()
if __name__ == "__main__":
asyncio.run(main())
ここではコマンドライン引数を検証し、指定されたサーバースクリプトに接続するための MCP クライアントを初期化します。その後、Python の asyncio を使用して非同期実行フローを管理しながら、適切なクリーンアップ処理を伴う非同期コンテキストでチャットループを実行します。
行動を見てみよう
これまでに構築したものの動画デモをご紹介します:このチュートリアルの一部として Anthropic がリリースした天気ツールを使って、このクライアントをテストしていきます。
2つのツールを個別にデモします:
- 天気警報ツールは、米国の州の警報を取得するのに役立ちます
- プロンプト:「カリフォルニア州の天気警報の要約を教えて」
- 天気予報ツールは、米国の都市の予報を取得するのに役立ちます
- プロンプト:「バッファロー、ニューヨークの天気予報の要約を教えて」
デモ動画
動かそう
uv を使用して client.py を実行し、ツールを保存した場所へのパスを渡すことを忘れないでください。
uv run client.py ../weather/weather.py
ブログ投稿のレビューを MCP で自動化
クライアントとサーバーのセットアップが完了したので、実際のユースケースの解決に取り組む準備が整いました。このサンプルでは、LLM にウェブブラウジング機能を提供するためのカスタムツールを構築します。
MCP サーバーの拡張は、サーバーファイルに新しい関数を追加するか、新しいサーバーファイルを作成するだけで簡単に行えます。このデモの範囲では、既存のサーバーファイルにいくつかの非常に強力な関数を追加し、Claude がそれらを計画の中でどのように組み合わせて使用し、適切に区別できるかを示します。
さらにコードを書く前に、MCP サーバーフォルダに移動して、追加の依存関係をインストールしてください。
cd ../weather
uv add requests markdownify
Web ページを訪れる
私たちは、ウェブページを訪問してマークダウンを抽出するために、LLM に HTTP クライアントを提供しています。
# wheather.py (I know, I know...)
import re
import requests
from markdownify import markdownify
from requests.exceptions import RequestException
@mcp.tool()
def visit_webpage(url: str) -> str:
"""Visits a webpage at the given URL and returns its content as a markdown string.
Args:
url: The URL of the webpage to visit.
Returns:
The content of the webpage converted to Markdown, or an error message if the request fails.
"""
try:
# Send a GET request to the URL
response = requests.get(url, timeout=30)
response.raise_for_status() # Raise an exception for bad status codes
# Convert the HTML content to Markdown
markdown_content = markdownify(response.text).strip()
# Remove multiple line breaks
markdown_content = re.sub(r"\n{3,}", "\n\n", markdown_content)
return markdown_content
except RequestException as e:
return f"Error fetching the webpage: {str(e)}"
except Exception as e:
return f"An unexpected error occurred: {str(e)}"
visit_webpage 関数は、HTTP GET リクエストを使用して指定されたURLからコンテンツを取得するツールです。取得したHTMLコンテンツを、過剰な改行を削除し、エッジケースを処理することで、よりクリーンなMarkdown形式に変換します。この関数には、ネットワーク関連の問題や予期しないエラーに対する包括的なエラー処理が含まれており、問題が発生した場合は適切なエラーメッセージを返します。
validate_links
# weather.py
@mcp.tool()
def validate_links(urls: list[str]) -> list[str, bool]:
"""Validates that the links are valid webpages.
Args:
urls: The URLs of the webpages to visit.
Returns:
A list of the url and boolean of whether or not the link is valid.
"""
output = []
for url in urls:
try:
# Send a GET request to the URL
response = requests.get(url, timeout=30)
response.raise_for_status() # Raise an exception for bad status codes
print('validateResponse',response)
# Check if the response content is not empty
if response.text.strip():
output.append([url, True])
else:
output.append([url, False])
except RequestException as e:
output.append([url, False])
print(f"Error fetching the webpage: {str(e)}")
except Exception as e:
output.append([url, False])
print(f"An unexpected error occurred: {str(e)}")
return output
validate_links 関数は URL のリストを受け取り、それぞれが有効でアクセス可能なウェブページであるかを確認します。各URLに対して HTTP GET リクエストを試み、リクエストが成功し空でないコンテンツを返す場合、そのリンクを有効と見なします。この関数は URL-validity のペアのリストを返します。各ペアにはURLとそのリンクが有効かどうかを示すブール値が含まれ、ネットワークエラーや一般的な例外に対するエラー処理も行います。
さらにツールを追加
このデモで使用している記事を確認して、私たちが不正をしていないことを確認してください(AWS上のサーバーレス検索拡張生成(RAG))
明示的なオーケストレーションがなくても、Claude がツールの使用を計画し組み合わせて複雑な目標を達成できることは印象的です。このデモでは、私たちのシステムがまずウェブページのコンテンツをダウンロードし、次にすべてのリンクを抽出し、それらすべてを検証し、最終的にエンドユーザーにサマリーを返す方法を見てきました。
で、どうするの?
ツールライブラリを拡張し、会話を独自に管理する新しい方法を探索できるようになりました。
私たちは、完全に分散化することで、この構造を次のレベルに引き上げる新しいユースケースの探索に熱心に取り組んでいます。次に見たい機能やツールについて、コメントでお知らせください。