はじめに
本記事は、Pythonで機械学習を始めてみたいが、とりあえず手頃な例で簡単に実装し、自分の手を動かすことで機械学習のモデル作りの過程を体験してみたい人向けの内容となっています。
内容としては、機械学習のモデル作成〜実際に学習してモデルの精度を測る、というところまでを簡単に体験できるようになっています。
自分が機械学習をやり始めた時に、簡単でもいいから実装しながら流れを一通り体験したいなと思い、同じような思いをしている方の一助になればと思い、作成しました。
【想定読者】
・ 機械学習をあまりやったことは無いが、Pythonを使うと機械学習が出来ると聞いてやってみたい
・ Pythonの基本的なことはある程度理解している(pip installが使える、numpyでarrayの意味がわかる、くらいのレベル)
・ とりあえず簡単な例でいいので、自分で写経して機械学習を実感してみたい
・ サポートベクターマシン(SVM)は聞き覚えがあるが使ったことがないので、実際に実装してみたい
機械学習とは?
世の中には、すでに機械学習とはなんぞやということを解説された記事や書籍などはすでに大量に存在しているので、ここであえてそれを書くことはしません。
個人的には、Wikipedia先生の記述の中のこちらの一節が好きなのでご紹介します。
学習用データセットを使って訓練した後に、未知の例について正確に判断できるアルゴリズムの能力をいう。
機械学習 - Wikipedia
機械学習のモデル実装の流れ
機械学習がどのように行われるのか、どのようにモデルが構築されるのかの大まかな流れです。
- データ前処理、訓練データの作成(ここが一番大変)
- モデルの学習(データが多いとめっちゃ時間がかかる)
- モデルの精度をテストデータで計測
- 未知のデータから予測
というような実装の流れです。今回はこの1〜3を以下で実装していきます。
いざ実装!
個人的によくjupyter notebookを使っているので、以下のコードをjupyterにぺたぺた貼り付けてセルを順次実行するなどすると分かりやすいと思います。
前準備
今回用いるライブラリは以下。入れていない人は事前に pip install しておいてください。
- numpy
- matplotlib
- sklearn
- mlxtend
まずはじめにデータを準備します。scikit learn の実装例でよく用いられるアヤメデータセットを用います。
# -*- coding: utf-8 -*-
%matplotlib inline
# 必要なライブラリを import
from sklearn import datasets
import numpy as np
# アヤメデータセットを用いる
iris = datasets.load_iris()
# 例として、3,4番目の特徴量の2次元データで使用
X = iris.data[:, [2,3]]
# クラスラベルを取得
y = iris.target
データの前処理
機械学習では過学習と呼ばれる、トレーニングデータに対して過剰に学習してしまい、未知なるデータへの予測精度がかえって悪くなってしまう現象があります。
過学習や汎化性能といった話は以下のブログが参考になるかと思われるので、ぜひご一読ください。
(参考: 「そのモデルの精度、高過ぎませんか?」過学習・汎化性能・交差検証のはなし -六本木で働くデータサイエンティストのブログ )
過学習を避けるために交差検証と呼ばれる手法を用いてモデルを評価する必要があります。
具体的には、データセットをモデルの学習に用いられる「訓練データ」と、そのモデルの汎用的な性能を測る「テストデータ」に分割します。テストデータモデル作成に使用しません。
実装コードはこちら。
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
# トレーニングデータとテストデータに分割。
# 今回は訓練データを70%、テストデータは30%としている。
# 乱数を制御するパラメータ random_state は None にすると毎回異なるデータを生成する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=None )
# データの標準化処理
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
※今回はデータが既に綺麗なものなので、標準化くらいしかやることがありませんが、普段扱うようなデータは異常値や欠損値などがあるので、その処理をして綺麗なデータとしてデータセットを作成する必要があります。なんだかんだ、ここの作業が一番大変です。。。
モデルの学習
いわゆる機械学習モデルの学習とはこの工程を指します。機械学習のモデルには様々なアルゴリズムがあり、scikit-learn, Chainer, Tensorflow など有名なライブラリやフレームワークにはそれらが実装されており、簡単に利用することができます。
今回は scikit-learn に実装されているサポートベクターマシン(SVM)を用いて学習をしてみます。(コメントアウトしてますがロジスティック回帰モデルも合わせて記載しておきます)
実装はこちら。
from sklearn.svm import SVC
# 線形SVMのインスタンスを生成
model = SVC(kernel='linear', random_state=None)
# モデルの学習。fit関数で行う。
model.fit(X_train_std, y_train)
ちなみに、この部分を以下のように書き換えるだけでロジスティック回帰のモデルも実装できます。モデルの切り替えも簡単なので、ぜひ色々なアルゴリズムを試してみてください。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(random_state=None)
モデルの精度を評価する
まずはトレーニングデータに対してどれくらいの精度が出たか見てみます。
predict関数でモデルにデータを読ませることで予測結果を返す仕組みとして実装されていることが多いです。
from sklearn.metrics import accuracy_score
# トレーニングデータに対する精度
pred_train = model.predict(X_train_std)
accuracy_train = accuracy_score(y_train, pred_train)
print('トレーニングデータに対する正解率: %.2f' % accuracy_train)
手元の環境では、
トレーニングデータに対する正解率: 0.95
と出ました。
そして、過学習していないか確かめるためにテストデータを用いて精度を計測してみます。
# テストデータに対する精度
pred_test = model.predict(X_test_std)
accuracy_test = accuracy_score(y_test, pred_test)
print('テストデータに対する正解率: %.2f' % accuracy_test)
こちらは手元の環境では、
テストデータに対する正解率: 0.98
と出ました。
これで過学習せず汎用的な性能があるモデルが作成できました。
※データ量が多いとこの学習作業自体が長時間に及びます。解決方法としては、GPUなど高性能な処理能力を持ったマシンで学習するなど工夫が必要になります。
実際の分類の様子
以上のデータを可視化してみましょう。実装コードは以下です。
# 分類結果を図示する
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
plt.style.use('ggplot')
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
fig = plt.figure(figsize=(13,8))
plot_decision_regions(X_combined_std, y_combined, clf=model, res=0.02)
plt.show()
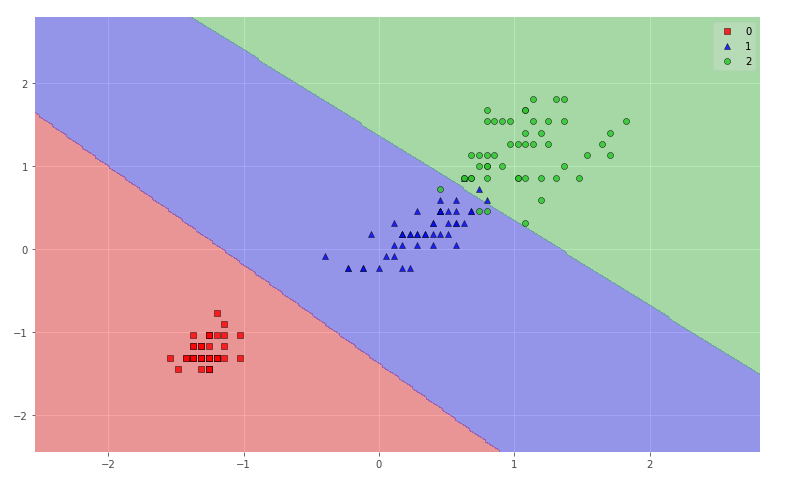
これは訓練データもテストデータも含めての図示ですが、割りと良い感じに分類できていることがわかります。
このモデルを活用して、データを入力して出力を予測する、という流れで機械学習を活用することになります。
実用上は、
・精度の高いモデルを作成する
・そのモデルを用いてデータからラベルなど予測する
という運用になるかと思われます。