RTX3090環境でローカル音声認識+翻訳アプリのレイテンシを可視化してみた
先日作成したローカル環境で動作する音声認識+翻訳アプリについて、実際のレイテンシを計測・可視化してみました。
今回は 「どの処理にどれだけ時間がかかっているのか」 を明確にすることが目的です。
■ 検証環境
GPU:RTX3090(24GB)
音声認識:Faster-Whisper
翻訳:M2M100(418M)
実行環境:ローカルCUDA
■ 読み上げた検証文章
本システムは騒音環境下における現場作業の円滑化を目的として開発されています。リアルタイム音声認識にはWhisperモデルを使用し、翻訳にはM2M100を使用しています。現在はGPUメモリ使用量、ASR処理時間、翻訳処理時間、総レイテンシを同時に計測し、性能最適化を行っています。
やや長めの文章でテストしました。
(アプリ画面・ターミナルログ)
特に処理時間が増加した箇所をピックアップして分析しています。

■ 計測項目
アプリでは以下をログ出力しています。
総レイテンシ(発話終了後から表示まで)
ASR処理時間
翻訳処理時間
GPUメモリ使用量
ログはCSVに保存し、Pythonでグラフ化しました。
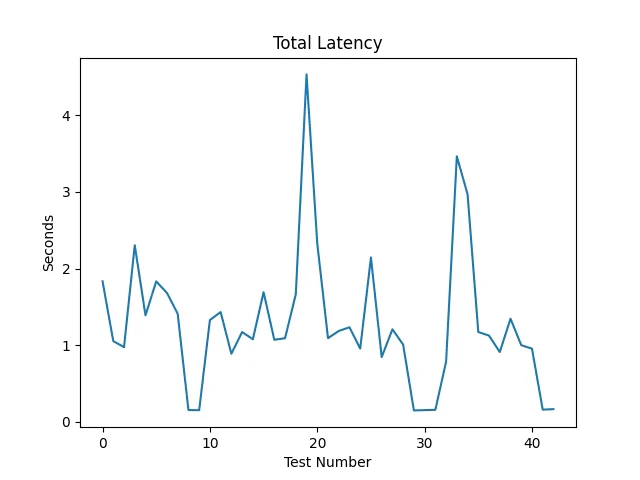
■ 総レイテンシ
グラフ(Figure_1)を見ると、
通常は 約1.0〜1.5秒
長文では 最大4秒台
まで増加するケースがありました。
短文ではほぼ1秒前後で処理可能です。
→ ローカル環境でも実用可能な速度であることが確認できました。
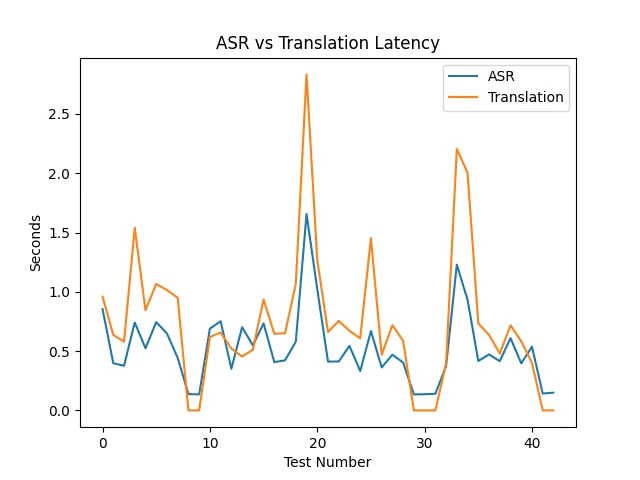
■ ASRと翻訳の内訳
処理時間を分解すると(Figure_2):
ASR:おおよそ0.4〜0.7秒
翻訳:0.6〜2秒以上(ばらつきあり)
レイテンシが増加している箇所は、翻訳側の処理時間増加と一致していました。
つまり今回の構成では、
ボトルネックは翻訳モデル側
であることが明確になりました。
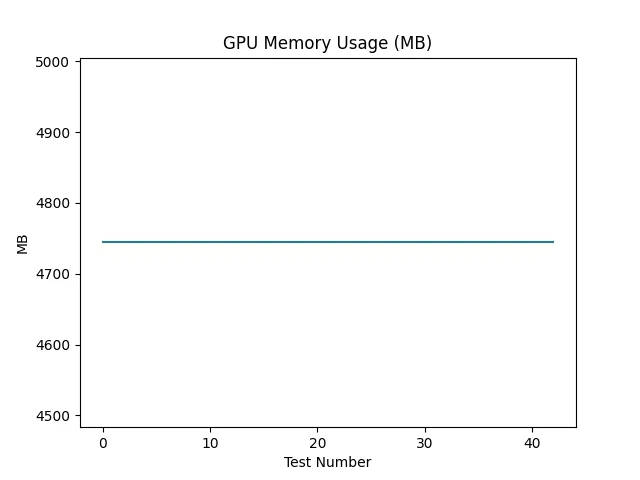
■ GPUメモリ使用量
GPUメモリは約4744MBで横ばいでした(Figure_3)。
これは異常ではありません。
モデルをGPUへロードした時点で必要メモリが確保される
PyTorchがメモリをキャッシュする設計になっている
ため、処理中も大きく変動しない挙動になります。
今回のレイテンシ増加は、メモリ不足ではなく生成処理の計算時間に起因していると考えられます。
■ 今回分かったこと
短文は約1秒前後で処理可能
長文では3〜4秒程度まで増加
ボトルネックは翻訳処理
GPUメモリは約4.7GBで安定
RTX3090環境では十分実用レベルであることが確認できました。
■ 今後の改善
翻訳のbeam数調整による高速化
生成トークン上限の最適化
より軽量な翻訳モデルの検証
引き続き最適化を進めていきます。