始めに
前回の続きですが出だしは前回の記述をそのまま掲載します。
#概要
最初slurmのactive/standbyを検証してみようかと考えていたのですが、DBの切替めんどいなぁっ、スクリプト書いて切り替えるぐらいなら、active/activeにトライしてみようと思い立ち挑戦することにしました。ただ厳密に言えば、slurm自身にactive/activeの機能はありません。
slurmctld,slurmdbd共にactive/standby機能があるので、ちゃんとフェイルオーバーするのかも検証していきたいと思います。
今回の記事はいつもお世話になっている Server Worldの記事を参考にmariadbとgalera clusterのインストールと設定をしていきます。
ざっくり構成としてはこんな感じです
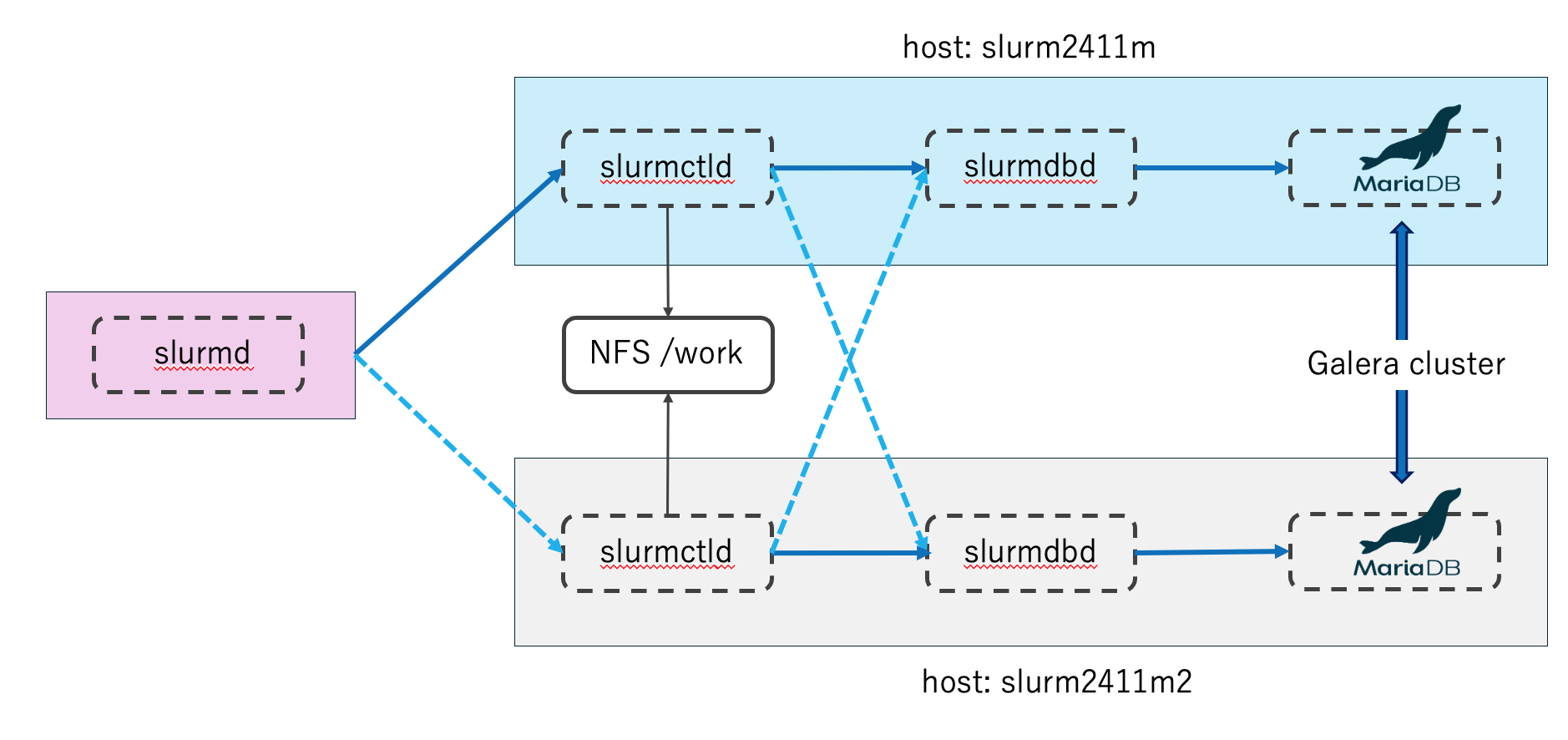
前回はgalera clusterの設定まで終わりました。
次には、slurmのインストールですが、これは以前も書いたのでスキップして、
設定だけ記述していきます。
#プライマリ、セカンダリの順に記述します。
SLURMD_OPTIONS="--conf-server slurm2411m:6817,slurm2411m2:6817"
# slurmDBD info
DbdAddr=10.100.100.71
DbdHost=slurm2411m
DbdBackupHost=slurm2411m2
SlurmUser=slurm
DebugLevel=verbose
LogFile=/var/log/slurm/slurmdbd.log
PidFile=/var/run/slurm/slurmdbd.pid
# Database info
StorageType=accounting_storage/mysql
StoragePass=slurm
StorageUser=slurm
StorageLoc=slurm_acct_db24
# slurmDBD info
DbdAddr=10.100.100.69
#プライマリとバックアップを入れ替える
DbdHost=slurm2411m22
DbdBackupHost=slurm2411
SlurmUser=slurm
DebugLevel=verbose
LogFile=/var/log/slurm/slurmdbd.log
PidFile=/var/run/slurm/slurmdbd.pid
# Database info
StorageType=accounting_storage/mysql
StoragePass=slurm
StorageUser=slurm
StorageLoc=slurm_acct_db24
SlurmctldHost=slurm2411m
SlurmctldHost=slurm2411m2
lurmctldTimeout=10
AccountingStorageHost=slurm2411m
AccountingStorageBackupHost=slurm2411m2
SlurmctldHost=slurm2411m
SlurmctldHost=slurm2411m2
lurmctldTimeout=10
#こちらもプライマリとセカンダリを入れ替える
AccountingStorageHost=slurm2411m2
AccountingStorageBackupHost=slurm2411m
systemctl start slurmdbd
systemctl start slurmctld
systemctl start slurmd
systemctl start slurmdbd
systemctl start slurmctld
以上で検証環境の設定は終わりです。
では実際に検証に入っていきます。
検証1:プライマリ側のslurmdbdを停止したときの挙動
この検証では、プライマリ側のslurmdbdを停止してもsacctが使えるかどうかを見ていきます。
slurmdbdはジョブ投入には影響がないので、一応そこも確認します。

本来ならログインノードを立てるべきなんでしょうが、今回用意していないので、ワーカーノード側から検証します。
まず正常に動いている事を確認します。
(base) testuser@slurm2411c1:/work/temp$ sbatch normal.sh
Submitted batch job 26
(base) testuser@slurm2411c1:/work/temp$ sbatch normal.sh
Submitted batch job 27
(base) testuser@slurm2411c1:/work/temp$ sacct
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
10 test.sh standard 8 COMPLETED 0:0
10.batch batch 8 COMPLETED 0:0
11 test.sh standard 8 COMPLETED 0:0
11.batch batch 8 COMPLETED 0:0
12 test.sh standard 8 COMPLETED 0:0
12.batch batch 8 COMPLETED 0:0
13 test.sh standard 8 COMPLETED 0:0
13.batch batch 8 COMPLETED 0:0
14 test.sh standard 8 COMPLETED 0:0
14.batch batch 8 COMPLETED 0:0
15 test.sh standard 8 COMPLETED 0:0
15.batch batch 8 COMPLETED 0:0
16 test.sh standard 8 COMPLETED 0:0
16.batch batch 8 COMPLETED 0:0
17 test.sh standard 8 COMPLETED 0:0
17.batch batch 8 COMPLETED 0:0
18 test.sh standard 8 COMPLETED 0:0
18.batch batch 8 COMPLETED 0:0
19 test.sh standard 8 COMPLETED 0:0
19.batch batch 8 COMPLETED 0:0
20 test.sh standard 8 COMPLETED 0:0
20.batch batch 8 COMPLETED 0:0
21 test.sh standard 8 COMPLETED 0:0
21.batch batch 8 COMPLETED 0:0
22 test.sh standard 8 COMPLETED 0:0
22.batch batch 8 COMPLETED 0:0
23 test.sh standard 8 COMPLETED 0:0
23.batch batch 8 COMPLETED 0:0
24 test.sh standard 8 COMPLETED 0:0
24.batch batch 8 COMPLETED 0:0
25 test.sh standard 8 COMPLETED 0:0
25.batch batch 8 COMPLETED 0:0
26 test.sh standard 8 RUNNING 0:0
26.batch batch 8 RUNNING 0:0
27 test.sh standard 0 PENDING 0:0
(base) testuser@slurm2411c1:/work/temp$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
27 standard test.sh testuser PD 0:00 1 (Resources)
26 standard test.sh testuser R 0:06 1 slurm2411c1
正常に動いている事を確認したので、プライマリ側のslurmdbdを停止します。
予想外だったのが、ログ出力には特段なにもメッセージが表示されなかった。
これはログレベルの問題かも。
sacctのコマンドをエラー無く実行出来たらslurmdbdのセカンダリにアクセス出来ている。
念のためsqueue,sbatchも問題無いか確認
sacct
squeue
sbatch normal.sh
sbatch normal.sh
slurmdbdを再開するとslurmctld.logに以下のログが出力され、プライマリ側のslurmdbdが復旧した事が分かる。しかしセカンダリに切り替わったメッセージが出ないのが解せない。
accounting_storage/slurmdbd: clusteracct_storage_p_register_ctld: Registering slurmctld at port 6817 with slurmdbd
検証2:セカンダリ側のslurmdbdを停止したときの挙動

セカンダリは、上記手順をセカンダリ側で行いましたが、プライマリと同様で問題無く動作したので割愛します
検証3:両方のslurmdbdを停止したときの挙動

では、両方停止しているときはどんな状態になるのか試してみます。
squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
29 standard test.sh testuser R 0:05 1 slurm2411c1
(base) testuser@slurm2411c1:/work/temp$ sbatch normal.sh
Submitted batch job 30
(base) testuser@slurm2411c1:/work/temp$ sacct
sacct: error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
sacct: error: Sending PersistInit msg: Connection refused
sacct: error: Problem talking to the database: Connection refused
このようにジョブの投入や実行には影響はありませんが、ジョブの統計情報を確認することが出来なくなりました。
[2025-03-13T20:54:16.323] error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
[2025-03-13T20:54:16.323] error: Sending PersistInit msg: Connection refused
[2025-03-13T20:54:26.001] error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
[2025-03-13T20:54:26.001] error: Sending PersistInit msg: Connection refused
[2025-03-13T20:54:45.001] error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
[2025-03-13T20:54:45.001] error: Sending PersistInit msg: Connection refused
[2025-03-13T20:55:03.001] error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
[2025-03-13T20:55:03.001] error: Sending PersistInit msg: Connection refused
[2025-03-13T20:55:21.001] error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
[2025-03-13T20:55:21.001] error: Sending PersistInit msg: Connection refused
[2025-03-13T20:55:31.001] error: _open_persist_conn: failed to open persistent connection to host:slurm2411m2:6819: Connection refused
[2025-03-13T20:55:31.001] error: Sending PersistInit msg: Connection refused
[2025-03-13T20:56:00.291] accounting_storage/slurmdbd: clusteracct_storage_p_register_ctld: Registering slurmctld at port 6817 with slurmdbd
[2025-03-13T20:56:12.022] accounting_storage/slurmdbd: clusteracct_storage_p_register_ctld: Registering slurmctld at port 6817 with slurmdbd
slurmdbdが両方とも通信出来ない事で定期的にエラーメッセージが出力されています。
そしてslurmdbdを両方とも復旧(サービス再開)したときのログが上記になります。
この後にsacctは問題無く実行出来るようになりました。
ここまではジョブの実行に影響がない検証でしたが、今度はslurmctld本体の障害について検証していきます。
検証4:プライマリ側のslurmctldを停止したときの挙動

まずはプライマリのslurmctldを停止します。
そうするとセカンダリのslurmctld.logには以下のようなメッセージが表示されます。
[2025-03-14T08:49:21.132] error: ControlMachine slurm2411m not responding, BackupController1 slurm2411m2 taking over
[2025-03-14T08:49:21.132] Terminate signal SIGTERM received
[2025-03-14T08:49:21.136] accounting_storage/slurmdbd: clusteracct_storage_p_register_ctld: Registering slurmctld at port 6817 with slurmdbd
[2025-03-14T08:49:21.177] Recovered state of 1 nodes
[2025-03-14T08:49:21.178] Recovered JobId=32 Assoc=0
[2025-03-14T08:49:21.179] Recovered JobId=33 Assoc=0
[2025-03-14T08:49:21.179] Recovered JobId=34 StepId=batch
[2025-03-14T08:49:21.179] Recovered JobId=34 Assoc=0
[2025-03-14T08:49:21.179] Recovered JobId=35 Assoc=0
[2025-03-14T08:49:21.179] Recovered information about 4 jobs
[2025-03-14T08:49:21.179] Recovered state of 1 partitions
[2025-03-14T08:49:21.180] Recovered state of 0 reservations
[2025-03-14T08:49:21.181] Running as primary controller
[2025-03-14T08:49:24.012] error: Node slurm2411c1 appears to have a different slurm.conf than the slurmctld. This could cause issues with communication and functionality. Please review both files and make sure they are the same. If this is expected ignore, and set DebugFlags=NO_CONF_HASH in your slurm.conf.
slurmctlTimeout=10にしているので比較的早くフェイルオーバー(takeover)が発生しましたが、デフォルトだと120秒かかります。
またプライマリとセカンダリのslurm.confは微妙に設定が違うためワーカーノードと設定が違うとのメッセージが表示されます。これを解消するにはscontrol reconfigureを実行しますが、今回は行いませんでした。
それではプライマリのslurmctldを再開する場合も見ていきます。
[2025-03-14T08:53:05.019] accounting_storage/slurmdbd: clusteracct_storage_p_register_ctld: Registering slurmctld at port 6817 with slurmdbd
[2025-03-14T08:53:05.043] Recovered state of 1 nodes
[2025-03-14T08:53:05.044] Recovered JobId=32 Assoc=0
[2025-03-14T08:53:05.044] Recovered JobId=33 Assoc=0
[2025-03-14T08:53:05.044] Recovered JobId=34 Assoc=0
[2025-03-14T08:53:05.044] Recovered JobId=35 StepId=batch
[2025-03-14T08:53:05.044] Recovered JobId=35 Assoc=0
[2025-03-14T08:53:05.044] Recovered JobId=36 Assoc=0
[2025-03-14T08:53:05.044] Recovered JobId=37 Assoc=0
[2025-03-14T08:53:05.044] Recovered information about 6 jobs
[2025-03-14T08:53:05.045] Recovered state of 0 reservations
[2025-03-14T08:53:05.045] Running as primary controller
[2025-03-14T08:53:05.055] error: slurm_send_node_msg: [socket:[456585]] slurm_bufs_sendto(msg_type=RESPONSE_JOB_INFO) failed: Unexpected missing socket error
再開時にエラーが出ていますが、これはまだ完全にプライマリに戻らないうちに、コマンドsacct/squeueなどを実行するとこういうエラーが表示されますが一時的な問題です。
[2025-03-14T08:52:36.552] Performing RPC: REQUEST_CONTROL
[2025-03-14T08:52:36.552] Terminate signal SIGTERM received
[2025-03-14T08:53:05.000] error: _slurm_rpc_shutdown_controller: REQUEST_CONTROL reply but backup not completely done relinquishing control. Old state possible
[2025-03-14T08:53:05.001] Saving all slurm state
[2025-03-14T08:53:05.247] slurmctld running in background mode
[2025-03-14T08:53:07.989] error: Invalid RPC received MESSAGE_NODE_REGISTRATION_STATUS while in standby mode
上記は一部問題があります。
error: _slurm_rpc_shutdown_controller: REQUEST_CONTROL reply but backup not completely done relinquishing control. Old state possible
正常に終了出来なかったため、ステータス情報が古い可能性があるとのメッセージがあります。事実、もう一回プライマリをダウンさせると、2度目のフェイルオーバーは失敗します。
これを解消するためには、一度プライマリが正常に戻った段階で、セカンダリのslurmctldを再起動する必要があります。この問題は後日追跡調査する予定
検証5:セカンダリ側のslurmctldを停止したときの挙動

[2025-03-14T14:19:18.001] error: _shutdown_bu_thread:send/recv slurm2411m2: Connection refused
[2025-03-14T14:19:28.002] error: _shutdown_bu_thread:send/recv slurm2411m2: Connection refused
[2025-03-14T14:19:38.001] error: _shutdown_bu_thread:send/recv slurm2411m2: Connection refused
セカンダリを停止すると上記のようにConnection refusedが定期的に発生します。
ただしセカンダリなので、ワーカーノード側での実行には何一つ影響はありません。
セカンダリのslurmctldを再起動しても特段プライマリ側にはログが出力されません。
セカンダリのslurmctld.logでは通常通りのログが出力されるだけです。
[2025-03-14T14:20:06.954] slurmctld version 24.11.1 started on cluster cluster(2175)
[2025-03-14T14:20:06.955] lua: initialized
[2025-03-14T14:20:06.956] slurmctld running in background mode
最後に
検証自身は他にも行っていますが、長くなったので掲載するのは以上です。
正直slurmはあまり冗長構成をしなくてもいいかなと個人的には思います。
理由はサービス障害があっても結構すんなりサービス再起動で治るし、
サーバー自体のハードウェア故障があった場合は、slurm以外にも大きく影響するので、
slurmだけの冗長構成は意味がないです。
ただし、既に他のサービスを冗長構成を組んでいる場合は、slurmも冗長構成を組むのはゆうこうで