
はじめに
今回はスマートフォンを使ってのローカルLLMの実行をやってみたいと思います。
ローカルLLMの実行と聞くと、LLMのソフトウェア実行環境の構築がめんどくさかったり、強力なGPUとVRAMが積まれてるPCじゃないとできないイメージがありますが、軽量なモデルを選定すればスマートフォンでも十分に実行する事ができます。
ただしスマートフォンでやるにしても、比較的新しめの端末でないと厳しいと思います。
(A16以上、Snd8genX以上、TensorGx以上、RAM 8GB以上)
実行環境についてもストア(AppStore/GooglePlay)で公開されてるアプリをインストールするだけで用意でき、非常にお手頃です。
今回は、(1)アプリの導入、(2)モデルの選定~どれを選ぶ?量子化?フォーマット?~、(3)実行、(4)おまけ~手持ちのスマホでのパフォーマンス差分~、の順にまとめてみました。
■今回の実行環境:iPhone15pro
(1)使うアプリについて
今回はiPhone環境で使うためLLMFarmというアプリを選択しました。
プリセットされた有名Modelを選択しての利用、ダウンロードなど自分で用意したModelを利用という事ができます。
Metal(iPhone)とかGPU/SIMDを使う用に最適化されてたり、各種モデルに対してのプロンプトフォーマットの設定など細かな設定ができて便利です。
Android・iPhone共通で使えるアプリという事でPocketPalというアプリもあります。
こちらも任意のモデルを使用できる点は一緒ですが、設定できる項目がLLMFarmに比べて少なかったりします。
(最終章の手持ちスマホでのパフォーマンス比較、にて使いました)
(2)モデル選び
モデルに拘り無し、とりあえず使ってみたいんじゃ、という方はアプリに最初からプリセットされてるgemma2-2b-it辺りを使ってみましょう。
日本語LLMのモデルを選ぶという事で、真っ白な状態からモデル選定もしてみようと思います。
下記のページで代表的な日本語LLMの性能評価がされてますので参考にしてください。
■LLMの性能評価(LLM-jp提供)
ここで注意なのが、あまりパラメータ数が大きすぎるとロードすらできないので7B以下が良いと思います。(スマホだと7Bでもキツイので、スペックに自身の無い端末ではもっと小さなモデルが良いかと)
そもそもパラメータ数ってよく聞くけどなんだ?という話ですが、学習に使った入力データの量と考えると良いと思います。LLMモデルの学習は通常Wikipediaなど大規模な辞典データなどが使われますが、それの数が多ければ多いほどパラメータ数は増加します。
そのため知識を問われるようなプロンプトでは特に大きいパラメータ数のモデルが有利という事になります。その分の実行に必要なメモリサイズも大きくなります。
あとinstrustion(it)モデルにしましょう。これはchatGPTのようにチャット的なユースケースに最適化されたものです。LLMFarmもPocketPalもチャットベースのプラットフォームなのでitが良いという事になります。
LLM-jpの性能評価ページから、7B以下itタイプのモデルをリスト化して、AVGでソートしてみた結果が以下です。
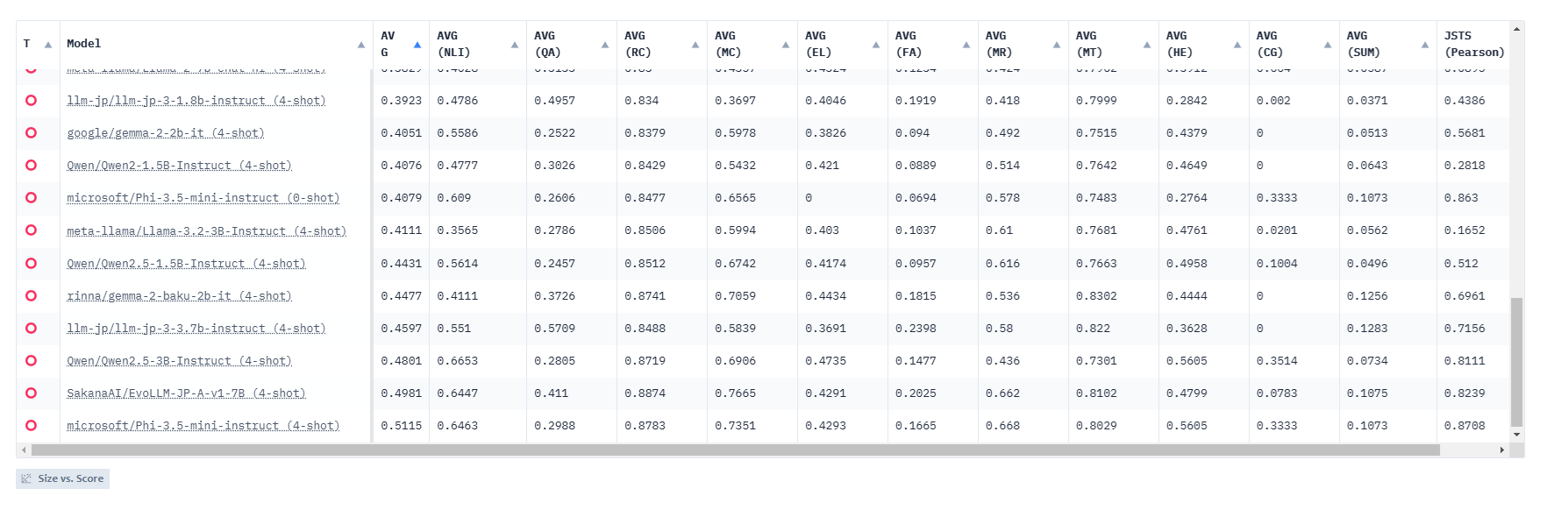
この結果が本当に絶対的な精度評価になるか?といわれると微妙で参考程度かなと思います。実際に使ってみて期待通りの結果になるかの確認は必要だと思います。
とはいえ触る前から新しめのモデルについても数値化してくれるのはありがたいとは思います。
なんとなく感覚で選びますが、Qwen2.5がなかなか良さげと聞くので「Qwen/Qwen2.5-7B-Instruct」を日本語にチューニングした「Kendamarron/Qwen2.5-7B-o1-ja-v0.1」を試してみようと思います。
■Kendamarron/Qwen2.5-7B-o1-ja-v0.1
※下記のけん玉さんが2024/12/8に公開されたモデルの様です。
■日本語reasoningモデルを作る
選ぶべきファイルですが、スマホで実行する場合には量子化+GGUFフォーマット変換されている必要があります。
量子化とはモデルのデータサイズを小さくするための処理です。GGUFとはLLM実行環境向けの比較的新しめのファイルフォーマットです。
量子化やフォーマット変換の手順については、npakaさんの下記のページが非常に参考になるので一読おススメします。
■LLM-jp-3 を gguf に変換する手順
またGoogleColabを使ってGGUF+量子化は出来るみたいです。
■Google ColabでLLM(llm-jp-3-instruct、HF形式)をGGUF形式に変換する
公開されてから時間のたってるLLMモデルでは、大抵の場合有志の方がGGUF+量子化して、再アップされてる事が多いので、"モデル名+GGUF"の検索ワードで検索してみると良いです。(bartowskiさんのページで様々なモデルのGGUF版を公開されてます。)
ファイル名の末尾に.ggufという拡張子がついてればGGUFフォーマット化済、ファイル名に"F16", "Q8_0", "Q4_K_M"というような文字列がついてれば、どの様に量子化されたかを示すものになります。
F16(F32の場合もあり)は量子化されていない状態を示していて、float16の精度が使われています。Q8は8bit量子化された状態で大体F16のサイズから半分程度になると思います。
Q4_K_Mは基本4bit量子化されたモデルですがKがついているのでk-量子化という手法で量子化されています。IQ4~みたいなものもありますが、これはi-量子化(Important Matrix)という新しめの量子化手法が適用されたものになります。
ここら辺の情報は下記のBakuさんのページが参考になりました。
基本的にF16(非量子)>Q8>Q4みたいな感じで、モデルファイルサイズ(必要VRAM量)と生成精度に関わってきます。
スマホで実行する場合は7BのQ4で5~4GB程度なので、ここら辺が限界だと思います。
「Kendamarron/Qwen2.5-7B-o1-ja-v0.1」については公開されてから間もないモデルの為、ColabでIQ4_XSのggufを作成しました。
(3)実行してみる
それでは実行してみましょう
あらかじめ実行するモデルファイル(Qwen2.5-7B-o1-ja-v0.1-iq4_xs.gguf(4.5GB))は端末上にコピーしておきましょう。Webで公開済みのものはSafariなどでダウンロードする事も出来ます。
LLMFarmを開いて右上の「+」ボタンからモデルを選択できます。「〇Sekect model」から端末上にあるモデルファイルを選択します。
また今回はQwenベースのモデルなのでプロンプトフォーマットを下記のように設定しました。


この状態でとりあえず「こんにちは」と入力してみたらこんな感じです。

次は「日本で運転免許を取る方法を教えてください。」と入れてみます

まあ普通ですかね、
次は少し難しい質問にしてみました。
下記のbwgiftさんのブログの質問を参考にしてみました。
■地平線まで行ってくる。
「まどか☆マギカで一番かわいいのは?」

「日本で二番目に高い山を検討して答えてください。」

うーん、少し微妙な結果になってきましたね。
ここで別のモデルも使ってみたいと思います。以前から日本語能力が高いと言われてた「TFMC/Japanese-Starling-ChatV-7B-GGUF(Q4_K_M)」を使ってみます。
「まどか☆マギカで一番かわいいのは?」

凄い、なかなか正確に答えてますね。モデルによって同じ質問でも回答が変わるのが面白いです。
AIの返答の下の方に「xx.xx t/s」の様な値が見えます。これはtoken per secondの事で、どの程度AIが素早く回答できたかを示す数値になります。
基本的にパラメータ数((2)モデル選びで出てきた概念)が大きければ小さくなり、小さければ大きくなります。
また実行する端末のスペックが良ければ大きくなり、悪ければ小さくなります。(ゲーミングPCなどを使えば大きくなります。)
ユースケースに寄りますが、少なくとも6以上は出て無いと実用に厳しいかな、と思います。
(4)おまけ ~手持ちスマホでのパフォーマンス差分~
いま手持ちのスマートフォン端末として「iPhone 15pro」、「Pixel 6」、「Mi11 Lite 5G」があります。
こちらの機種にて「gemma-2-2b-jpn-it-IQ4_XS.gguf」モデルと「japanese-starling-chatv-7b.Q4_K_M.gguf」モデルをPocketPal(iOSとAndroid両対応)で実行してみて、前述のt/sを提示してみたいと思います。
(※本当は12/10にオンラインで購入したGalaxyS24(Snd8gen3)の結果も示したいと思ったのですが、12/14時点で納品されず結果は出せませんでした。)
結果としては下記になります
- 結果
① gemma-2-2b-jpn-it-IQ4_XS.gguf(安定の小型安定モデル)
② japanese-starling-chatv-7b.Q4_K_M.gguf(日本語に強いと噂の)
| 端末 \ LLMモデル | ① | ② |
|---|---|---|
| iPhone15pro | 20.42(t/s) | 6.47(t/s) |
| Pixel6 | 9.14(t/s) | 3.90(t/s) |
| Mi11 Lite 5G | 0.30(t/s) | 0.12(t/s) |
提示した機種ではやはり「iPhone 15pro」が早いですね。「Pixel 6」も古めにしては結構頑張ってる方かと思います。Mi11 Lite 5Gは遅すぎですね、実行出来ただけでも奮闘した結果か、
(5)おしまい
スマートフォンでのLLM推論は実行環境として現状ベストではないと思いますが、スマートフォンの様な身近なデバイスで手軽に使えるようになってはじめて身近な技術になったと言えるのかなと思ってます。
近い将来、推論用のRAMが加味された状態での一般エッジデバイスが売られる様になると思ってますので、その時を楽しみに待ってます。
※参照ページ
https://huggingface.co/spaces/llm-jp/open-japanese-llm-leaderboard
https://huggingface.co/Kendamarron/Qwen2.5-7B-o1-ja-v0.1
https://zenn.dev/kendama/articles/544d7b1216a8d7
https://note.com/npaka/n/n3e99d2a45a4b#7dcd43d7-665f-41a6-a4fa-fbcd33d6f94e
https://note.com/mayu_hiraizumi/n/nb4b94c8c64a3#9291cdc7-adb2-4f20-a59c-fb4677efb6df
https://huggingface.co/bartowski
https://sc-bakushu.hatenablog.com/entry/2024/02/26/062547
https://bwgift.hatenadiary.jp/