はじめに
Snowflake は非常に強力なクラウドDWHですが、Iceberg を前提とした設計を考え始めると、
「データの実体はどこにあるのか?」という問いに必ず行き当たります。
Iceberg は、メタデータとデータファイルを分離し、S3 などのオブジェクトストレージ上にオープンな形でデータを保持することを前提としています。
本記事では、Qlik Talend Data Integration の Lake Landing Task / Storage Task と
Snowflake の 外部ボリューム(External Volume) を組み合わせることで、
Snowflake をメタデータ管理点としつつ、データの実体を Amazon S3 に配置する構成を解説します。
これは Iceberg や Qlik Open Lakehouse へ進むための、実務的な第一歩です。
公式ドキュメント
※ ちなみになのですが、Qlikの公式ドキュメントを確認する際は、英語版を確認することをお勧めします。
というのも日本語版では、情報が古い、誤訳があるなどの問題が少なからずあるようなので、、
■ Lake Landingタスク
https://help.qlik.com/en-US/cloud-services/Subsystems/Hub/Content/Sense_Hub/DataIntegration/Landing/Lake-Landing-settings.htm
Icebergとは
Iceberg は「テーブルの形式」
Apache Iceberg は、Amazon S3 などのオブジェクトストレージ上に置かれたデータを、信頼できる “テーブル” として扱うためのオープンなテーブル形式です。
Iceberg 自体はデータベースでも分析エンジンでもありません。
あくまで 「どのファイルが、どの時点で、どのテーブルを構成しているか」を管理するためのルールとメタデータ仕様です。
なぜ Iceberg が必要なのか
従来のデータレイクでは、S3 に Parquet ファイルを置くだけで、
・更新や削除ができない
・同時書き込みで壊れる
・途中失敗時の整合性が保証されない
・複数エンジンで安全に共有できない
といった問題がありました。
Iceberg は、この問題を メタデータ管理によって解決します。
Iceberg テーブルは、大きく次の 2 つで構成されます。
■ データファイル
・Parquet など
・実体は S3 などのストレージにそのまま存在
■メタデータ
・テーブル定義
・スナップショット(履歴)
分析エンジンは、S3上のファイルを直接読むのではなく、Icebergのメタデータを通して参照します。
これにより、
・ACIDトランザクション
・UPDATE / DELETE / MERGE
・タイムトラベル
・高速なファイル読み取り
といった DWH 的な操作性が、データレイク上で実現できます。
外部ボリューム(External Volume)とは何か
外部ボリュームとは、Snowflake が「自分の外にあるクラウドストレージ(例:S3)」を、安全かつ一貫した方法で読み書きするための“公式な入出力口"です。
Snowflake から見ると
「この S3 バケット(パス)には、この IAM ロールを使って、この用途でアクセスする」
という ストレージ接続定義そのものを指します。
従来、Snowflake は自前の内部ストレージにデータを格納する クローズドな DWH でした。
しかし Iceberg の登場により、
・データ本体は S3 などのオープンなストレージ
・メタデータを介して 複数エンジンで共有
という使い方が前提になりました。
そのため Snowflake には、
「どの S3 を使うのか」
「どの IAM 権限でアクセスするのか」
「Iceberg 用として安全に管理する」
これらを 一元的・宣言的に定義する仕組みが必要になり、それが外部ボリュームの登場のきっかけでした。
今回実施したいこと
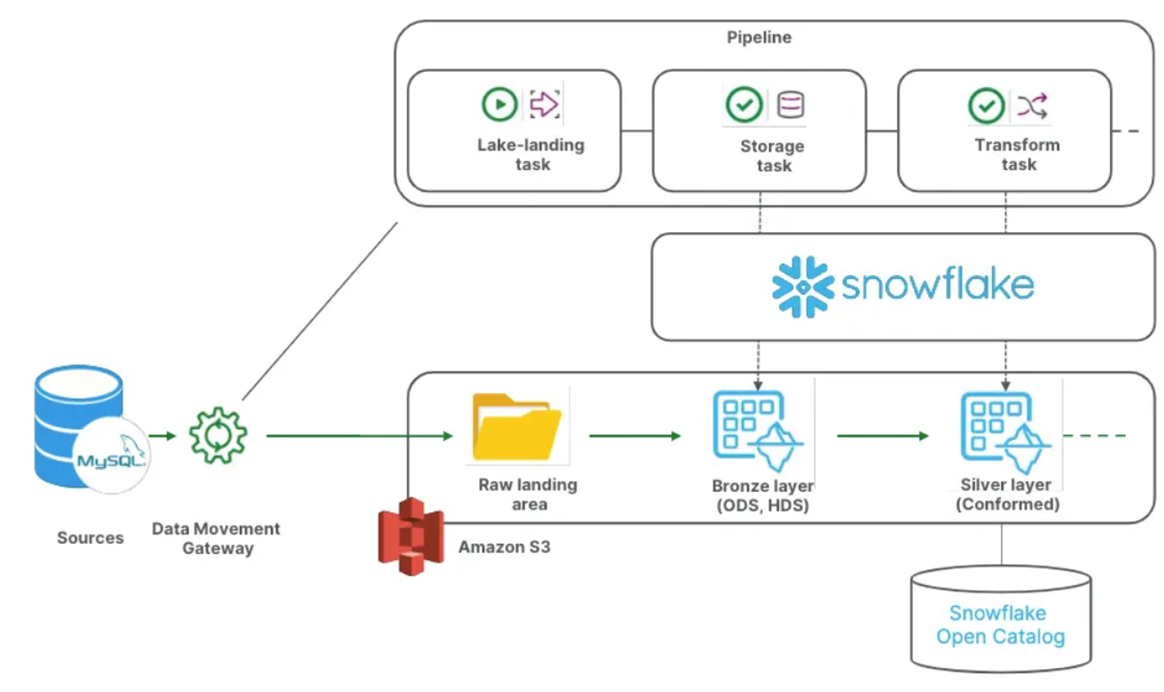
MySQLをソースとして、Snowflakeをターゲットとしてパイプラインを作成します。
レイクランディングタスクで生データはSnowflakeに置かず、S3上に置きます。
※ この際、Snowflakeの外部ボリュームとしてS3を設定しておく必要があります。
S3に置くことで、特定エンジンに閉じない状態にすることができます。
イメージ図
事前準備
- MySQLサーバーを立ち上げて、DMGと相互に通信ができるようにしておきましょう。
- MySQLに適当なサンプルデータを放り込んでおきましょう。(※1)
- 読み取りたいデータベースに適切な権限を与えておきましょう。(※2)
- DMGにドライバーを設定しておきましょう。(今回ですと、MySQLとSnowflakeのドライバー)(※2)
- DMGを立ち上げておきましょう。(※3)
(※1)
#データベースを作成する
CREATE DATABASE qlikdb;
#作成したデータベース一覧を確認する
SHOW DATABASES;
#データベースを使用
use qlikdb;
#サンプルデータ導入1
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50),
department VARCHAR(50),
hire_date DATE,
salary DECIMAL(10, 2)
);
INSERT INTO employees (name, department, hire_date, salary) VALUES
('Tanaka', 'Sales', '2021-01-10', 5500000),
('Suzuki', 'IT', '2020-07-15', 6000000),
('Sato', 'HR', '2019-03-20', 4800000),
('Kato', 'Sales', '2022-11-01', 5300000);
(※2)必要に応じて参考にして下さい
https://help.qlik.com/en-US/cloud-services/Subsystems/Hub/Content/Sense_Hub/DataIntegration/TargetConnections/mysql-target.htm
python --version
cd opt/qlik/gateway/movement/drivers/bin
#MySQLドライバーインストール
sudo -E ./install mysql
#Snowflakeドライバーインストール
sudo -E ./install snowflake
#停止
sudo systemctl stop repagent
#再始動
sudo systemctl start repagent
# Active: active (running) を確認
sudo systemctl status repagent
(※3)必要に応じて参考にして下さい
https://qiita.com/kazu_1994/items/859f81f08926a3c85466
データパイプラインタスクの作成と実行
-
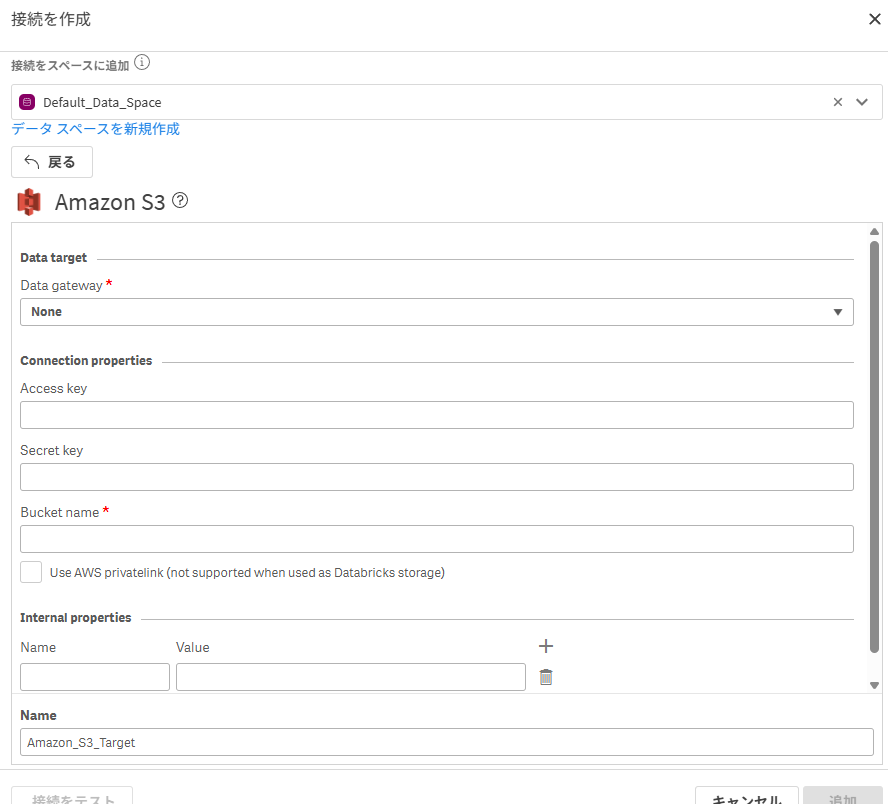
まずはレイクランディングタスクのデータ格納先となるS3の接続を確立
a. 接続 > 新規作成
b. S3の接続情報を入力して、接続完了のステータスへ
※ 今回は閉じた環境のS3ではないので、DMGはNoneで良いです。
-
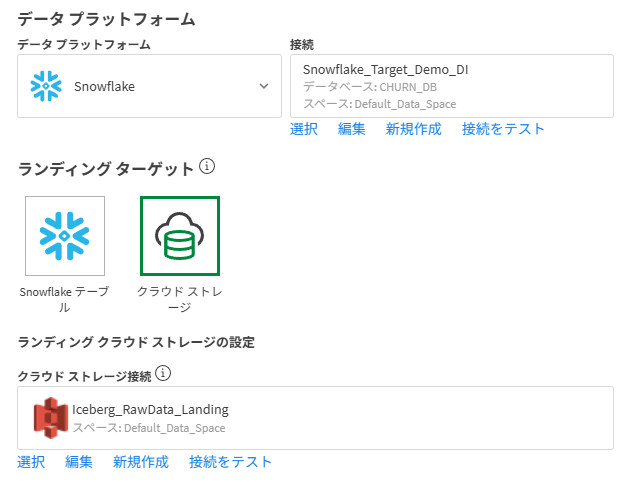
プロジェクトを新規作成し、設定を進める
a. ユースケースは「データパイプライン」を選択し、ターゲットはSnowflake、ランディングターゲットは1で作成したS3を指定(ここがRawデータの保管場所となります。)
b. 該当する外部ボリューム設定時の「ストレージ統合」、「既存の外部ボリューム」の名前を指定(大文字にしておきます。)
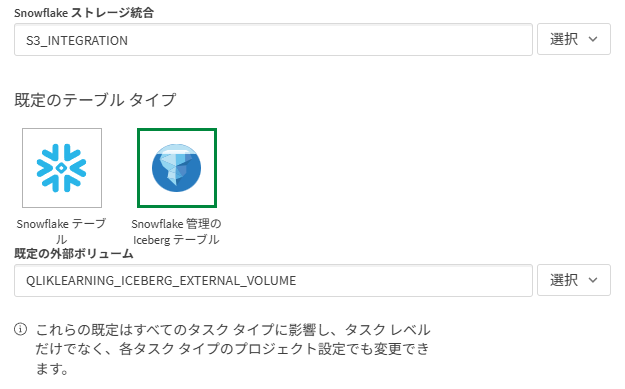
ストレージ統合と外部ボリュームにSnowflakeにおけるUSAGE権限がないことで後のストレージタスクが失敗する恐れがありますので、以下のようにUSAGE権限を割り当てると安心です。

-
データのオンボードを押下
-
MySQLサーバーをソースとして選択し、テーブルを選択、番号に沿って設定を進める

-
「検証」→「準備」→「実行」を実施
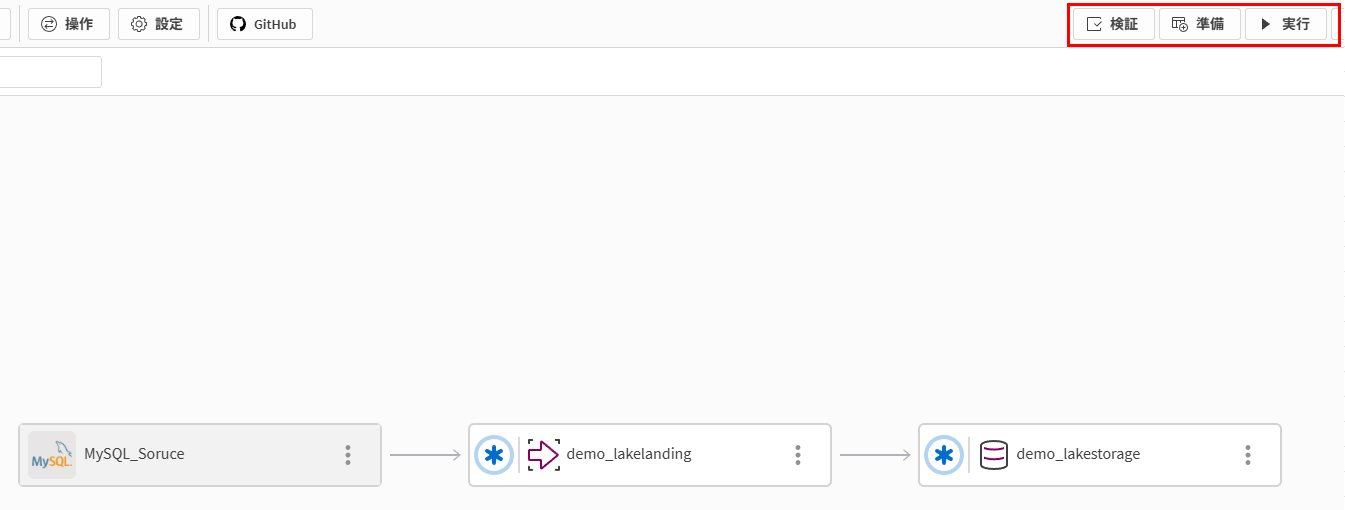
-
無事、実行されたことを確認

-
S3ではランディングタスクによって2つフォルダが生成されたことを確認

-
Snowflakeではストレージタスクによって、結果が格納されていることを確認

S3の中身をチラ見してみた
・「Demo_○○」ではランディングタスクの派生出力が格納されている
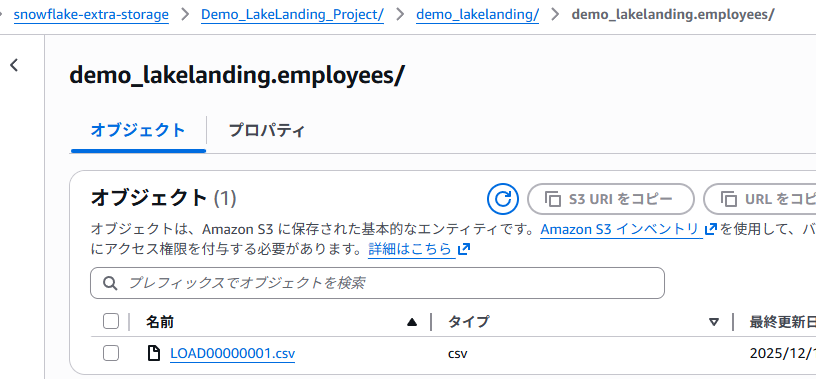
※ 以下.csvの中身

・「demo_○○」ではストレージタスクでの__internalが格納されている
試しに、_current内を覗くと、data/ 、metadata/などIcebergの構造が垣間見える

おわりに
今回扱った構成は、Iceberg や Qlik Open Lakehouse を"今すぐ使う"ためのものではありません。
しかし、後から Iceberg にできるかどうかという観点で見たとき、データの着地点を S3 に置き、Snowflake を制御点として使うこの構成は非常に重要です。
Qlik Open Lakehouse は、Iceberg を軸に「ストレージに閉じないデータ活用」を目指しています。
その土台として、まずは 生データをオープンに置く。
本記事で紹介した Lake Landing 構成は、そのための現実的なスタート地点だと考えています。
それでは皆様、ごきげんよう。