概要
- 大容量の CSV を出力をしようとした際、レスポンスが返ってくるまでの待ち時間が苦痛
- 最悪、タイムアウトエラーになりかねない
- とりあえずレスポンスだけ先に返しておき、実際の CSV 出力処理はバックグラウンドで非同期処理するみたいな事がしたい
- ActiveJob + S3 + Lambda + Slack を使う事でそれが実現できそう
軽めの CSV 出力であれば何ら問題無いのですが、サービスの運用が長続きしてたくさんのデータが蓄積すると、それらを一気に出力するのはなかなか骨が折れたりします。
実際、自分が担当しているサービスでも先日ついに処理に時間がかかりすぎてタイムアウトエラーになるといった事象が発生しました。
もちろん、 SQL の見直しだったり根本的な部分においては他にも色々やるべき事はあるかもしれませんが、とりあえず手っ取り早く対応するために非同期での CSV ダウンロードを実装してみました。
同期処理の場合
CSV 出力の処理が終わるまでその場で待機し続けなければならない。
非同期処理の場合
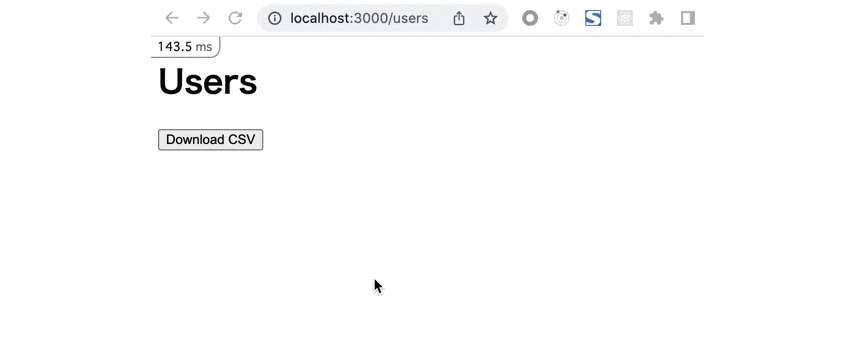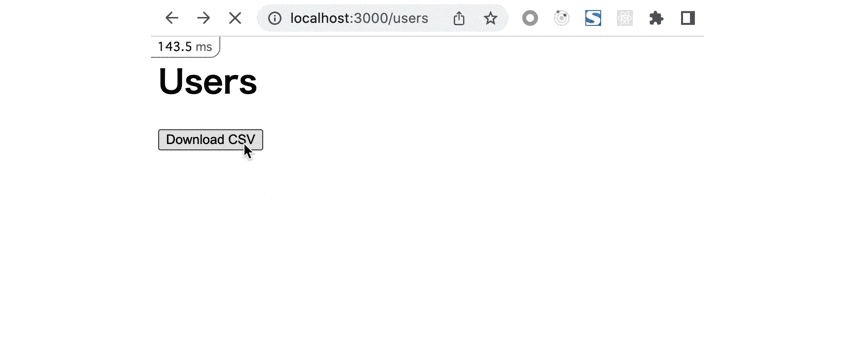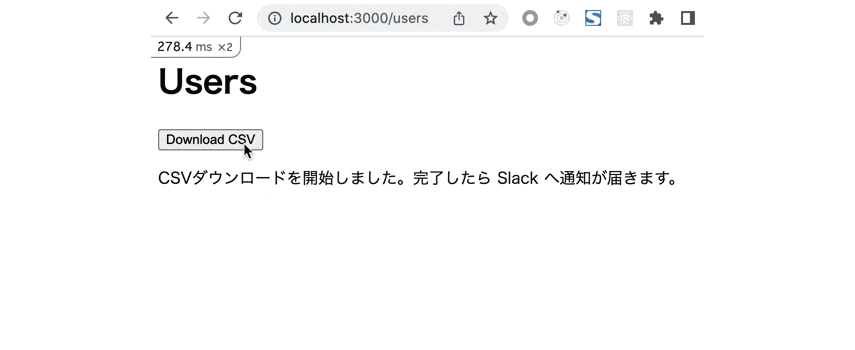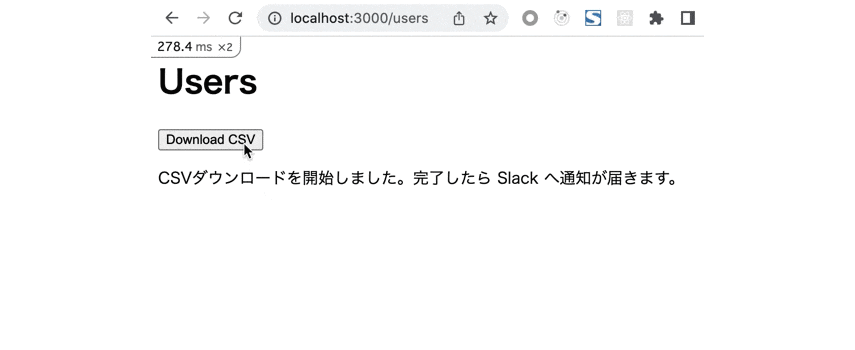
レスポンス自体は速攻で返ってくるので身軽。
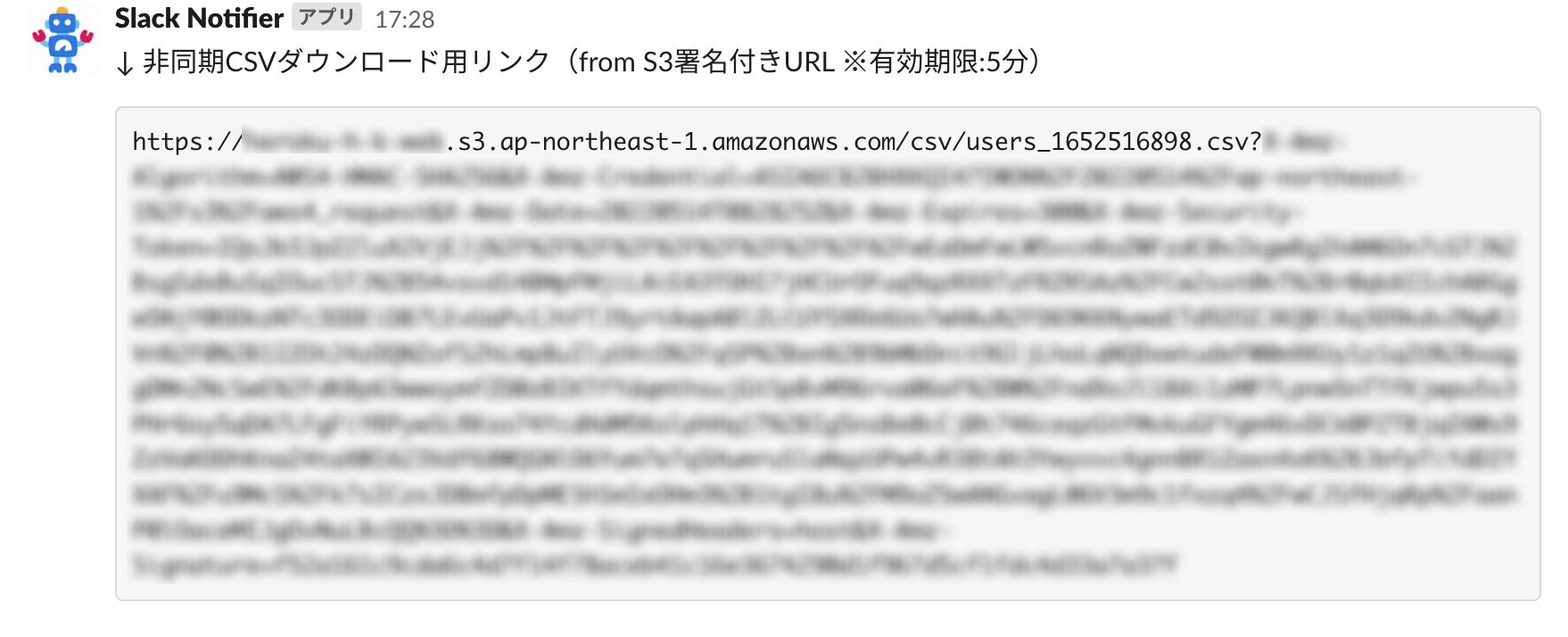
バックグラウンドでの CSV 出力処理が終わると Slack にダウンロード用のリンクが通知が飛んでくる。
実装
それでは実装していきましょう。
作業ディレクトリ & 各種ファイルを作成
$ mkdir mkdir async-csv-download && cd async-csv-download
$ touch Dockerfile docker-compose.yml entrypoint.sh Gemfile Gemfile.lock
FROM ruby:3.0
RUN curl https://deb.nodesource.com/setup_14.x | bash
RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - \
&& echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list
RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs yarn
ENV APP_PATH /myapp
RUN mkdir $APP_PATH
WORKDIR $APP_PATH
COPY Gemfile $APP_PATH/Gemfile
COPY Gemfile.lock $APP_PATH/Gemfile.lock
RUN bundle install
COPY . $APP_PATH
COPY entrypoint.sh /usr/bin/
RUN chmod +x /usr/bin/entrypoint.sh
ENTRYPOINT ["entrypoint.sh"]
EXPOSE 3000
CMD ["rails", "server", "-b", "0.0.0.0"]
version: "3"
services:
db:
image: mysql:5.7
environment:
MYSQL_ROOT_PASSWORD: password
volumes:
- mysql-data:/var/lib/mysql
- /tmp/dockerdir:/etc/mysql/conf.d/
ports:
- 4306:3306
web:
build:
context: .
dockerfile: Dockerfile
command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'"
volumes:
- .:/myapp
- ./vendor/bundle:/myapp/vendor/bundle
environment:
TZ: Asia/Tokyo
RAILS_ENV: development
ports:
- "3000:3000"
depends_on:
- db
volumes:
mysql-data:
#!/bin/bash
set -e
# Remove a potentially pre-existing server.pid for Rails.
rm -f /myapp/tmp/pids/server.pid
# Then exec the container's main process (what's set as CMD in the Dockerfile).
exec "$@"
# frozen_string_literal: true
source "https://rubygems.org"
git_source(:github) {|repo_name| "https://github.com/#{repo_name}" }
gem "rails", "~> 6"
# 空欄でOK
rails new
おなじみのコマンドでアプリの雛型を作成。
$ docker-compose run web rails new . --force --no-deps -d mysql --skip-test
database.ymlを編集
デフォルトの状態だとデータベースとの接続ができないので「database.yml」の一部を書き換えます。
default: &default
adapter: mysql2
encoding: utf8mb4
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
username: root
password: password
host: db
development:
<<: *default
database: myapp_development
test:
<<: *default
database: myapp_test
production:
<<: *default
database: <%= ENV["DATABASE_NAME"] %>
username: <%= ENV["DATABASE_USERNAME"] %>
password: <%= ENV["DATABASE_PASSWORD"] %>
host: <%= ENV["DATABASE_HOST"] %>
コンテナを起動 & データベースを作成
$ docker-compose build
$ docker-compose up -d
$ docker-compose run web bundle exec rails db:create
動作確認

localhost:3000 にアクセスしてウェルカムページが表示されればOKです。
User モデルを作成
$ docker-compose run web rails g model User name:string birthdate:string email:string phone:string address:string
| User |
|---|
| name: String |
| birthdate: String |
| email: String |
| phone: String |
| address: String |
それっぽい属性を持たせておきましょう。
$ docker-compose run web rails db:migrate
さらに app/models/user.rb を以下のように編集。
require "csv"
class User < ApplicationRecord
# CSV出力用ロジック
def self.generate_csv
attribute_names = User.attribute_names
CSV.generate(headers: true) do |csv|
csv << attribute_names
all.find_each do |user|
csv << user.attributes.values_at(*attribute_names)
end
end
end
end
ダミーデータを挿入
それっぽいデータが無いと CSV 出力できないので、適当なダミーデータを挿入していきます。
今回は定番の gem である faker を使ってみました。
gem "faker" # ダミーデータ用
gem "activerecord-import" # バルクインサート用
$ docker-compose build
gem をインストールできたら、db/seeds.rb を以下のように編集。
users = []
50000.times do
users << User.new(
name: Faker::Name.name,
birthdate: Faker::Date.birthday(min_age: 18, max_age: 65).strftime('%Y-%m-%d'),
email: Faker::Internet.email,
phone: Faker::PhoneNumber.cell_phone_in_e164,
address: Faker::Address.full_address
)
end
User.import(users)
大体5万件くらいのデータを入れておけば動作確認用としては十分だと思います。
$ docker-compose run web rails db:seed
それっぽいデータが入っていれば成功です。
コントローラー & ビューを作成
$ docker-compose run web rails g controller users index
class UsersController < ApplicationController
def index
users = User.all
respond_to do |format|
format.html
format.csv { send_data users.generate_csv, filename: "users_#{Time.current.to_i}.csv" }
end
end
end
<h1>Users</h1>
<%= button_to "Download CSV", users_path(format: :csv), method: :get %>
ルーティングを設定
Rails.application.routes.draw do
resources :users, only: %i[index]
end
動作確認
http://localhost:3000/users にアクセスして

こんな感じの画面が表示されていれば OK。
試しにボタンを押して CSV をダウンロードしてみてください。
先ほど5万件もデータを入れたので若干重いかもしれませんが、少し待っていればダウンロードできるはずです。

※ この時点ではまだ同期ダウンロードです。
aws-sdk-s3 をインストール
さて、いよいよここから非同期処理に変えていきます。
冒頭でも触れている通り、その場合は S3 へのファイルアップロードが必要になるので、S3 と疎通を取るために aws-sdk-s3 という gem をインストールしましょう。
gem "aws-sdk-s3" # S3 操作用
gem "dotenv-rails" # 環境変数管理用
$ docker-compose build
あとは .env 内に各種情報を記述してください。
$ touch .env
AWS_REGION=<リージョン>
AWS_ACCESS_KEY_ID=<アクセスキーID>
AWS_SECRET_ACCESS_KEY=<シークレットアクセスキー>
AWS_S3_BUCKET_NAME=<S3バケット名>
※ 各種キーの所有者である IAM ユーザーには、S3 および Lambda へのアクセス権限をあらかじめ付与しておいてください。
※ 出力された CSV ファイルを置くための S3 バケットをあらかじめ作成しておいてください。
S3 用のクラスを作成
$ mkdir lib/aws && touch lib/aws/s3_api.rb
require "nkf"
class Aws::S3Api
def initialize
credentials = Aws::Credentials.new(
ENV["AWS_ACCESS_KEY_ID"],
ENV["AWS_SECRET_ACCESS_KEY"]
)
s3 = Aws::S3::Resource::new(
region: ENV["AWS_REGION"],
credentials: credentials
)
@s3_bucket = s3.bucket(ENV["AWS_S3_BUCKET_NAME"])
end
def upload_file(filepath, data, content_type)
@s3_bucket.put_object(
key: filepath,
body: NKF.nkf("-x -w", data),
content_type: content_type
)
end
end
lib 以下のファイルを読み込むために、config/apprication.rb 内に以下の1行を追記。
config.paths.add "lib", eager_load: true
ActiveJob を作成
非同期処理を行うために、ActiveJob を継承したジョブを作成します。
$ touch app/jobs/users_csv_export_job.rb
class UsersCsvExportJob < ApplicationJob
def perform
filepath = "csv/users_#{Time.current.to_i}.csv"
data = User.all.generate_csv
content_type = "text/csv"
Aws::S3Api.new.upload_file(filepath, data, content_type)
end
end
コントローラーを編集
app/controllers/users_controller.rb を以下のように編集してください。
class UsersController < ApplicationController
def index; end
def download_csv
UsersCsvExportJob.perform_later
redirect_to users_path, notice: "CSVダウンロードを開始しました。完了したら Slack へ通知が届きます"
end
end
ビューを編集
app/views/users/index.html.erb を以下のように編集してください。
<h1>Users</h1>
<%= button_to "Download CSV", download_csv_users_path %>
<p>
<% flash.each do |message_type, message| %>
<%= message %>
<% end %>
</p>
ルーティングを編集
config/routes.rb を以下のように編集してください。
Rails.application.routes.draw do
resources :users, only: %i[index] do
collection { post :download_csv }
end
end
Lambda 関数を作成
ここまでに流れにより「バックグラウンドで CSV を出力 → S3 への送信」までが出来たので、あとは「S3 にアップロードされたファイルを取得してダウンロード用リンクを作成し、Slack へ通知」するための Lambda 関数を作れば完成です。
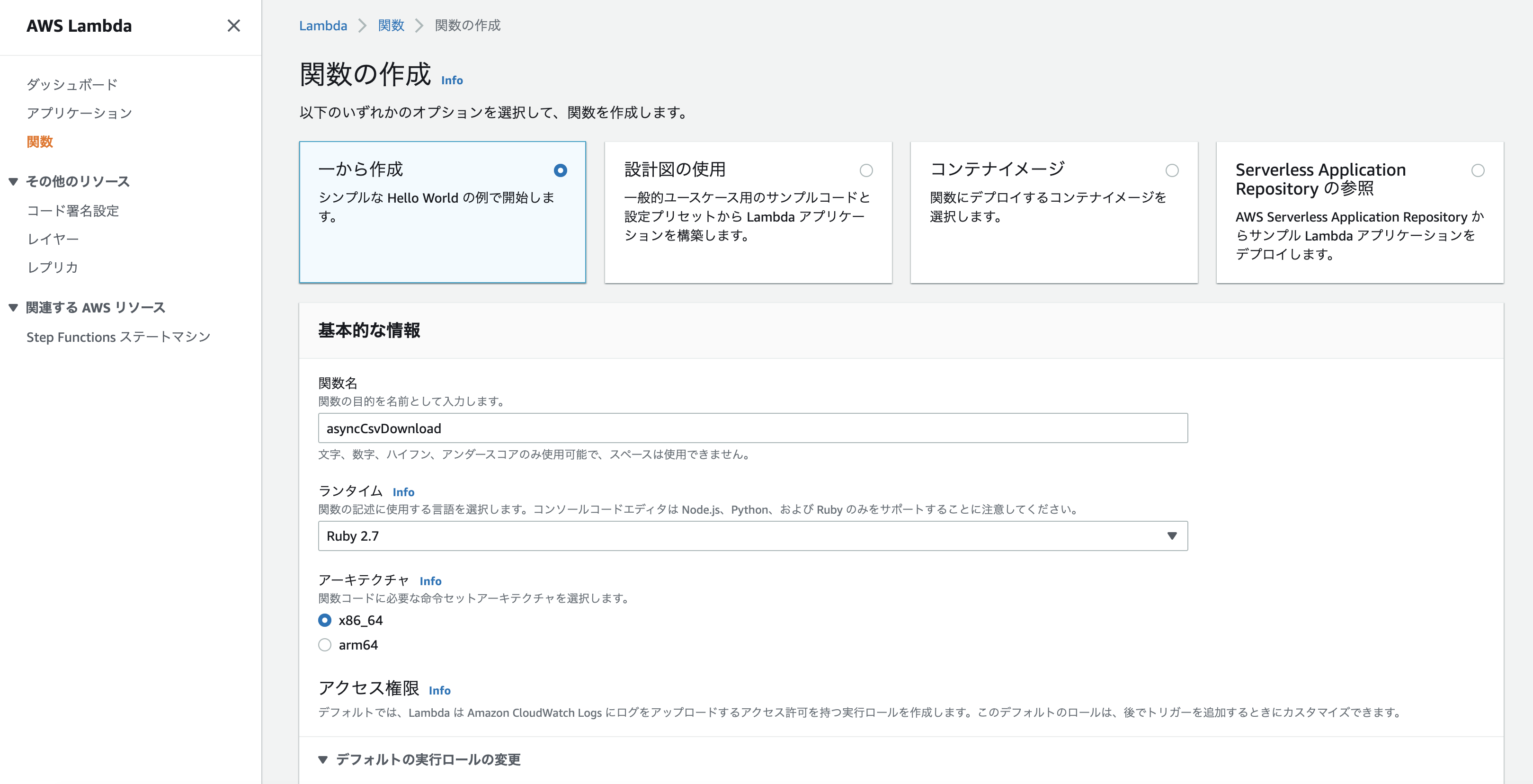
AWS のコンソール画面から「Lambda → 関数 → 関数の作成」へと進み、
- 関数名
- asyncCsvDownload
- ランタイム
- Ruby 2.7
- その他
- デフォルトで OK
それぞれ設定してください。
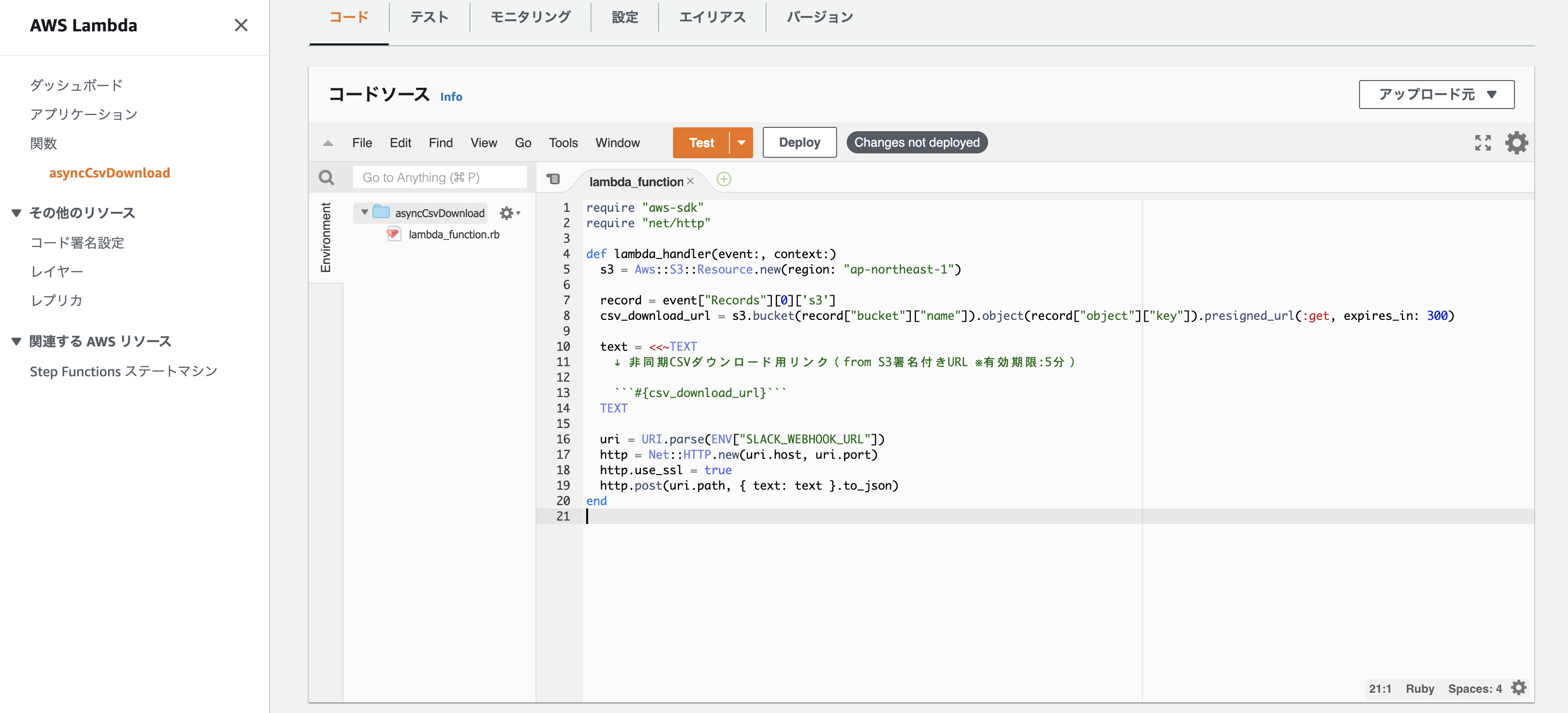
lambda_function.rb の中身は以下の通り。
require "aws-sdk"
require "net/http"
def lambda_handler(event:, context:)
s3 = Aws::S3::Resource.new(region: "ap-northeast-1")
record = event["Records"][0]['s3']
csv_download_url = s3.bucket(record["bucket"]["name"]).object(record["object"]["key"]).presigned_url(:get, expires_in: 300)
text = <<~TEXT
↓ 非同期CSVダウンロード用リンク(from S3署名付きURL ※有効期限:5分)
```#{csv_download_url}```
TEXT
uri = URI.parse(ENV["SLACK_WEBHOOK_URL"])
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true
http.post(uri.path, { text: text }.to_json)
end
SLACK_WEBHOOK_URL には Slack 通知先のチャンネルに紐づいたものをセットしてください。

なお、CSV ダウンロード用リンクを作成する際には S3 の S3 Presinged URL (署名付き URL) という仕組みを使います。
S3上にあるファイルを一時的に不特定多数に公開したい場合や、IAM Userアカウントを持っていない人に対して一時的にファイルのダウンロード/アップロードさせたい場合があります。このような場合に用いることができる手段として「S3 Presinged URL」があります。
今回はセキュリテイ的な観点からあまり長い間パブリックにしておくのは良くないと思ったため、 expires_in: 300 で5分間だけダウンロードが可能なようにしてみました。
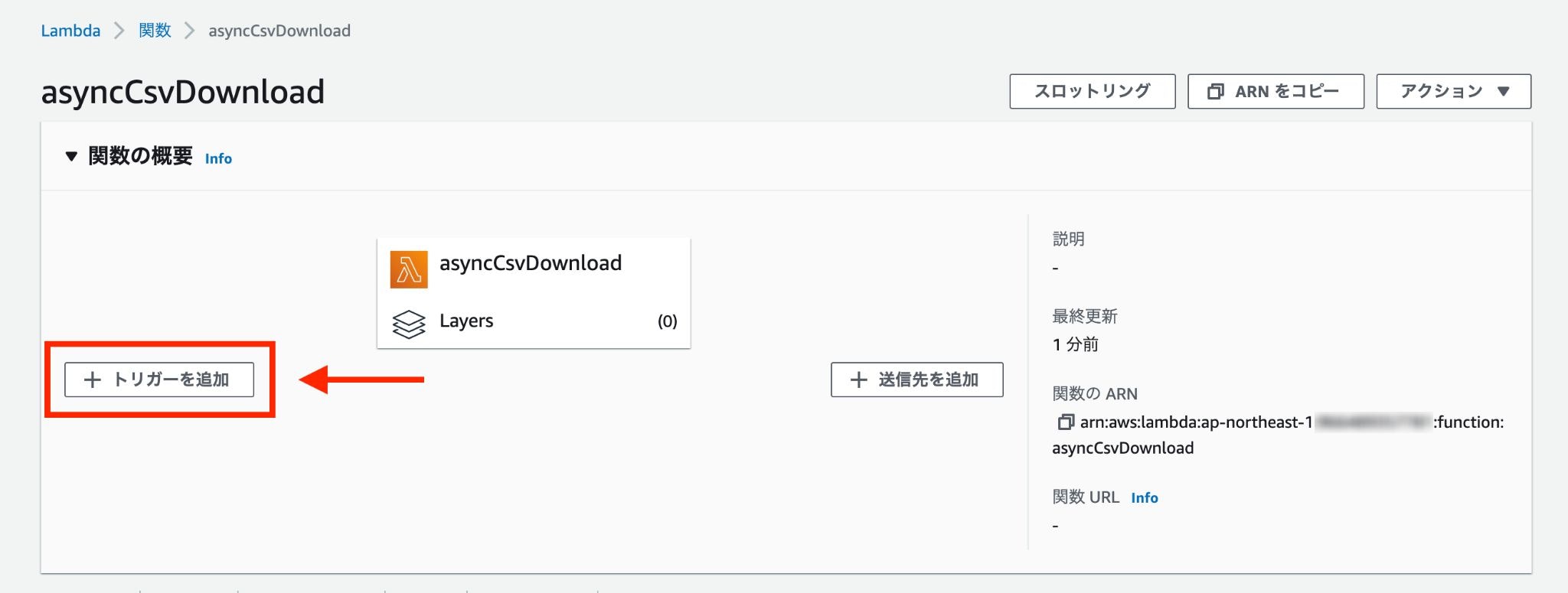
S3 にファイルがアップロードされた事を検知するために、「トリガーを追加」をクリック。
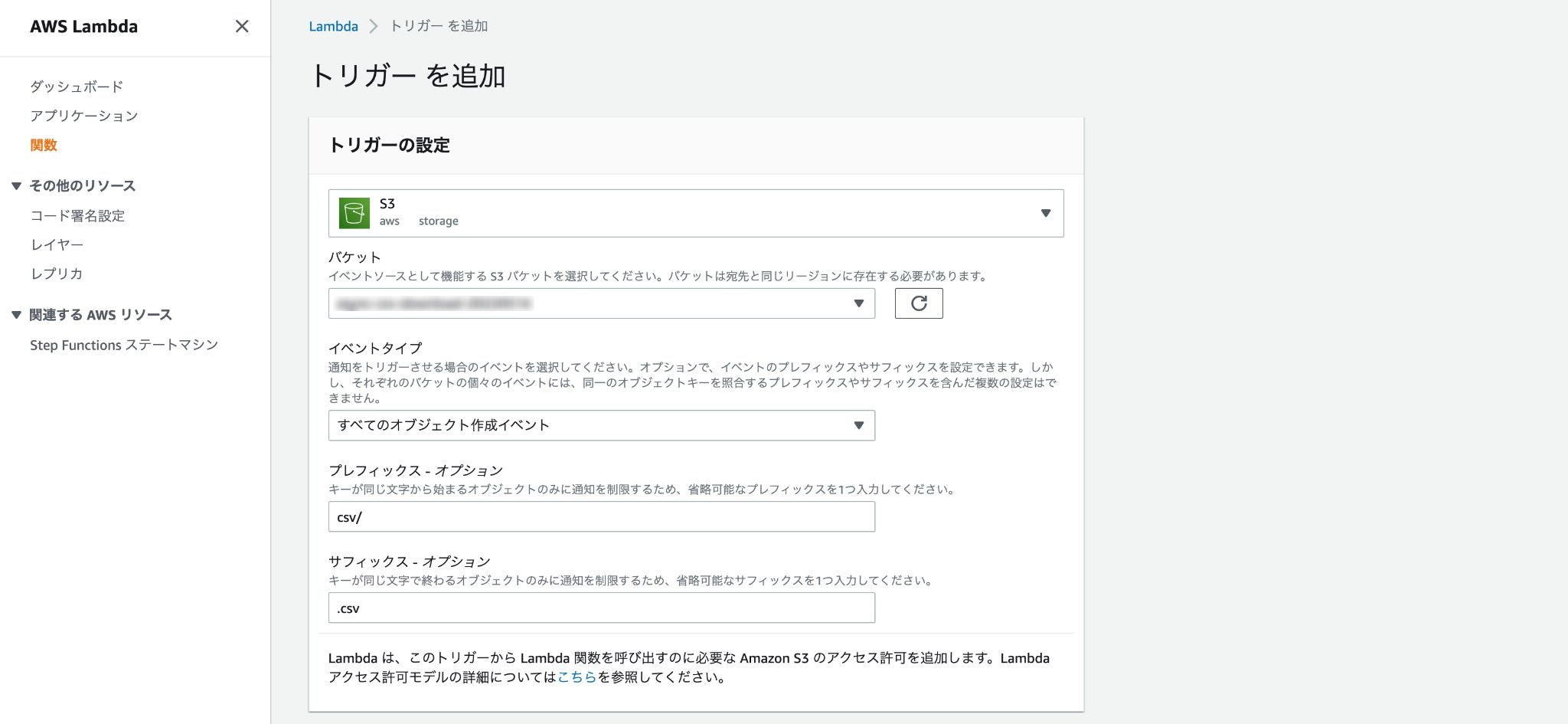
- トリガー
- S3
- バケット
- 対象のバケット
- イベントタイプ
- すべてのオブジェクト作成イベント
- プレフィックス
- csv/
- サフィックス
- .csv
上記のようにそれぞれ設定してください。
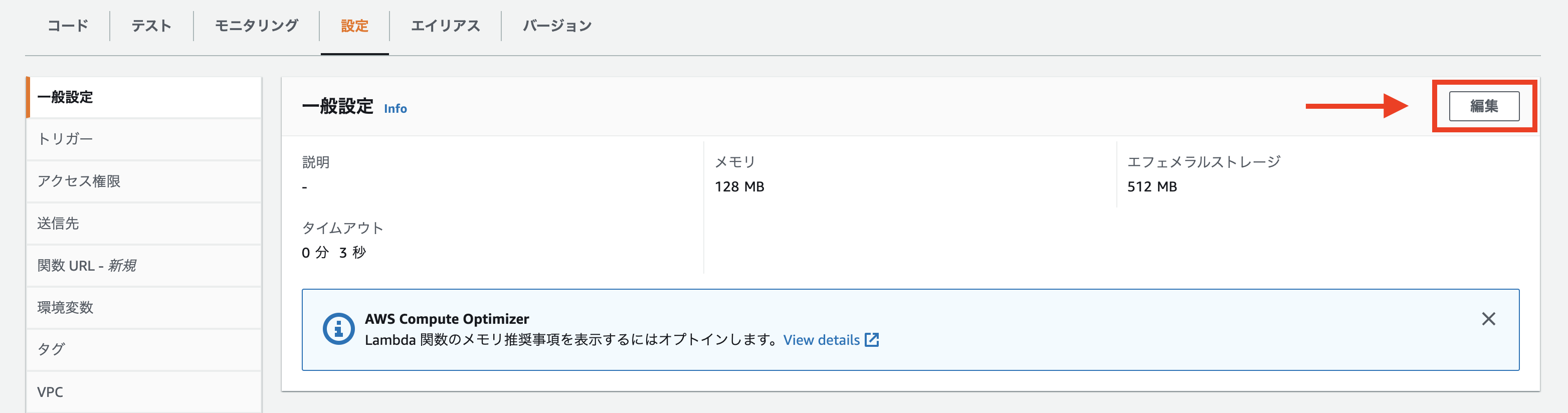
最後に、「一般設定」からタイムアウト値を変更します。
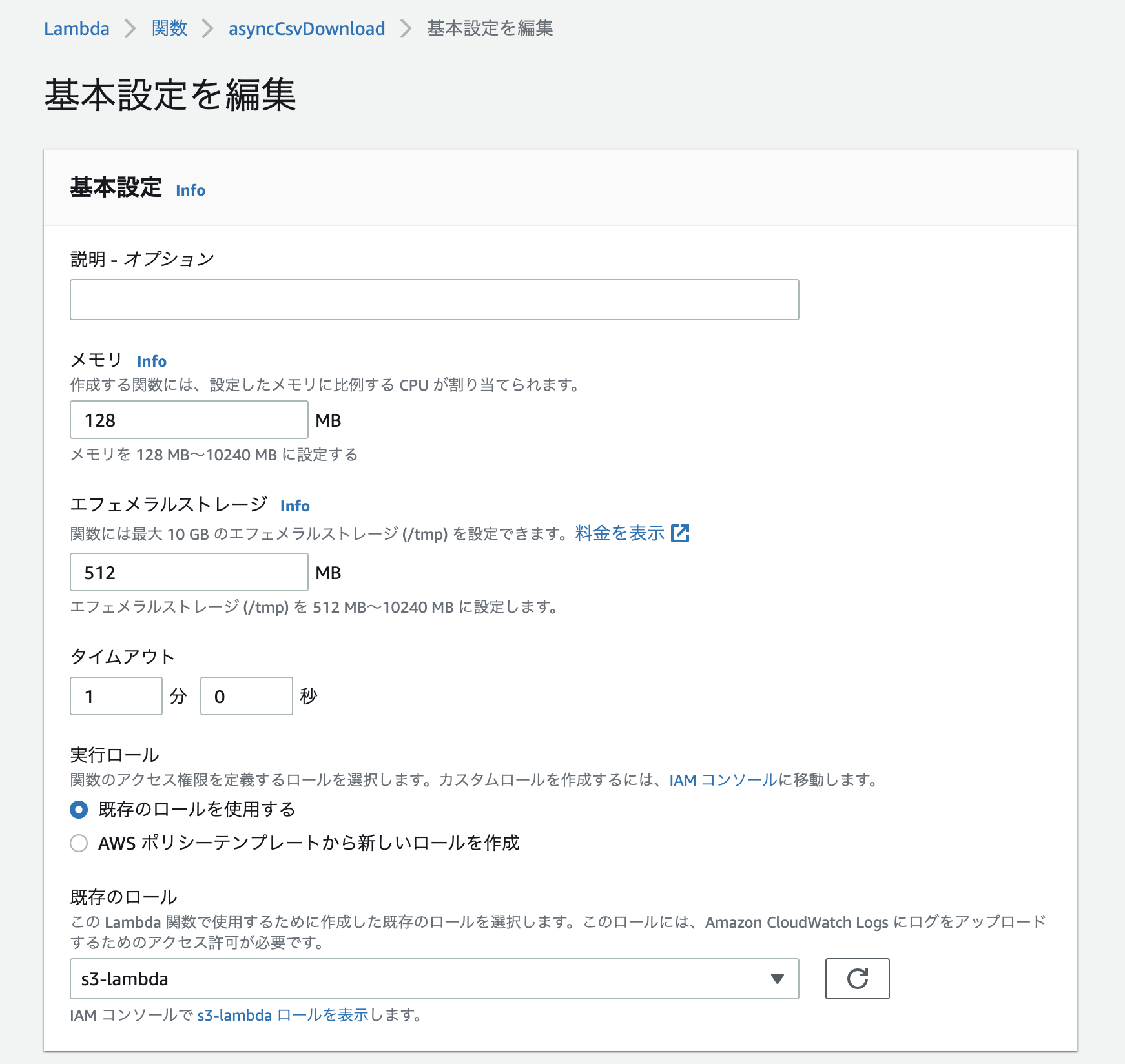
デフォルトの3秒だとさすがにキツいので、とりあえず1分くらいにしておきます。
動作確認
これで全ての作業は完了です。
http://localhost:3000/users に再度アクセスし、ダウンロードボタンを押してください。
しばらくして Slack へ CSV ダウンロード用リンクが届けば成功です。
※ 念のため、5分を過ぎるとリンクが無効になる事も確認してください。
あとがき
以上、ActiveJob + S3 + Lambda + Slack で非同期 CSV ダウンロードを実現してみました。
データが増えて処理がもっさりしてきた場合などには上手く活用していきたいところですね。
今回はローカル環境での動作確認だったので ActiveJob 単体で動かしてみましたが、本番環境で動かすには Sidekiq みたいなバックエンドを用意した方が良いと思います。
少しでも参考になれば幸いです。