MLSE研究会と関わることになってから、ずっと、機械学習を含むシステム(機械学習応用システム)の要求や安全分析は、機械学習を含まないときとどう違うのかに興味があり、最近、要求工学の研究として議論することが多くなりました。今日はその話と最近考えていることを書きたいと思います。
RE'19はついにRE4MLが基調講演
特に、機械学習工学に関する研究は、テストに関する研究が断然多く、機械学習応用システムの要求に関する研究は、最近ワークショップや基調講演で出てくるくらいです。特に今年の9月にあったRE'19(Requirements Engineering Conference 2019)の基調講演は、Marsha Chechik女史が”Uncertain Requirements, Assurance and Machine-Learning"というタイトルで機械学習の要求工学について話していました。そこで紹介されている研究は、ワークショップで発表("Toward Requirements Specification for Machine-Learned Components")した、たった4ページの論文でした。(もちろん、この論文だけではなく複数の成果を交えて全体コンセプトを話していました。)つまり、まだ研究を始めたばかり初期の成果を講演していたのです。
しかし、その研究のベースとなっている技術は、要求工学の中ではずーっと前から議論されている不確実性(Uncertainty)です。Marshaは、Krzysztof Czarnecki教授らが整理した機械学習の不確実性("Towards a Framework to Manage Perceptual Uncertainty for Safe Automated Driving"の論文)を参照し、その不確実性を、ゴール指向の分析法(GSN, Goal Structuring Notation)を用いて分析する方法を提案しています。(実はGSNを使って、機械学習の不確実性はそこそこあって、日本では石川先生(NII)や松野先生(日大)が提案されています。)また、訓練データから要求を抽出する話もされていて、その部分が機械学習というか、ビックデータ特有の要求分析だと思いました。
ただ、Marshaの講演を聞いて、「多少、分析する不確実性が変わるにせよ、それじゃ、いままでの分析とおんなじなんじゃん。だってビックデータから要求を抽出するってマーケティングの世界じゃ当たり前だし!」と思って、「学習そのもから要求を抽出できないの?」という(日頃思っていた)質問をぶつけてみました。そうすると、Marshaは、「学習からももちろん要求を抽出できると思う。でも、研究としてまだやってない」と回答してくれました。
実は、私は今年に入って、ずっと学習から(アナリストが思って見なかったような)要求を抽出したり、機械学習応用システムの安全性をより深く分析できるのではと思っていました。そのため、Marshaの回答にはちょっと不満でもっと「実はこういう要求がこうやって抽出できるんだよ」という回答を期待していました。
AIでも自然には勝てません!
そんなこんなでRE4ML(Requirements Engineering for Machine Learning-based Systems)のことで、もんもんとした頭で10月の機械学習工学に関する湘南会議に望みました。この湘南会議は、少し運営もお手伝いしていたのですが、結構(必要以上)に大変なイベントでした。そう、秋のイベントにつきものの、台風の直撃を受けて、スケジュール通りに参加できない参加者が多数出てしまったのです。自然現象には勝てませんね。実は、9月に大分でやった国内会議でも台風に直撃され、前日入りした我々運営者以外誰も参加者が辿り着けず、それじゃ、ゆっくり温泉入って帰りましょうかという冗談を運営委員に言っていました。
このときは、結局、ほぼ全員大分にたどり着いてくれたのですが、湘南会議は、三分の二は海外からの参加者で、結局たどり着けなかった人が少なからず出てしまいました。特に、成田/羽田空港は着陸制限が出てしまい、便を変更して予定より3日遅れとなり、プログラムの後半しか参加できない人も結構いました。それでも、急遽、webExを使って遠隔で参加してもらったり、前半はOST(Open Space Technology)を使ったグループディスカッションにプログラムを変更して、最終的には参加された方は皆さん満足され、またいっしょに議論したいと言って日本を後にされました。
「なんとかたどり着いた湘南会議の参加者たち」
話をRE4MLに戻すと、湘南会議のOSTの議論テーマの一つに要求に関連した研究が選ばれ、日頃考えていたことを海外の研究者たちと議論することができました。その議論の中で、Amel Bennaceur女史が、要求工学の抽出、モデル化、検証、モニタリングの4つのプロセスで、システムに機械学習が入ると何が変わるのかという議論に整理してくれました。湘南会議の後にMLSE国際シンポジウムで、Amelがそのあたりのことをも含めてパネルに参加してくれました。そちらの内容は丸山さん(PFN)の記事をご覧ください。
「Amelが書いてくれた要求のプロセス」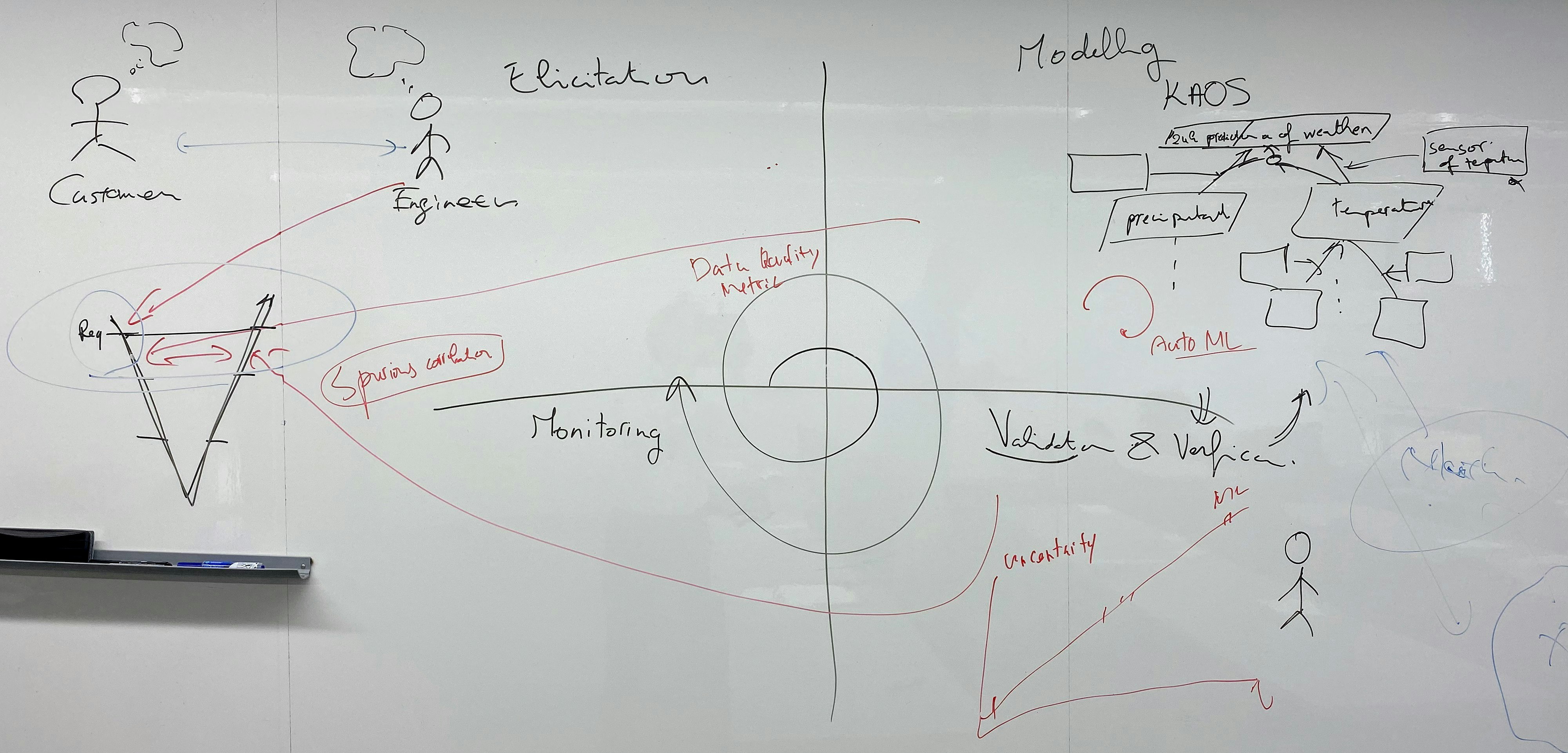
でっ何が難しいの?
私は、機械学習応用システムの要求工学における本質的な難しさは、以下の三つだと(今の所)思っています。
- こういうものができるだろうというエンジニア期待と実際出来上がってくるシステムの間に大きなギャップがあること
- 訓練済みモデルの精度が損失関数を使った全体性能で測られ、実際エンジニアが評価したいリスクや価値との間に大きなギャップがあること
- 機械学習応用システムを作るときの知識やノウハウを再利用するのがとても難しいこと
これらの難しさの原因は、従来型プログラミングは、やりたいことをやる手順を人がプログラムやルールとして実現していた(演繹的パラダイムによるソフトウェア構成)のに対して、機械学習はやりたいことをやる関数をデータから機械が自動的に導出(発見)している(帰納的パラダイムによるソフトウェア構成)ことに起因しています。
自動的にやりたいことの手順が導き出されるので、そもそも、エンジニアは何が導出されるのか分からない、どんな感じの関数が導出されたのか分からない、その関数を因子分解できないので再利用もできないのが、これらの3つの難しさにつながっていると思っています。つまり、機械学習特有の不確実性は、そもそも何が出来上がるか(作っている本人でも)分からないということと、出来上がったものも、作っている本人にもなんだかよく分からないということから生じているのです。
これらの3つが、これから少なくとも5年間は要求工学研究者がチャンレンジすべき社会ニーズが高い重要な課題だと思っています。これらの解決方針は、なんとなく最近見えてきているように思います。まずは、XAI(Explainable AI)の技術、そして、その延長としての訓練データや訓練済みモデルから抽象化した離散モデルもしくは関数を抽出する技術が重要になると思っています。これらの技術の発展により、深層学習などで訓練された訓練済みモデルがいったい何をしているのかがまずはエンジニアが把握し、最終的にはツールで要求を満たしているかどうかを検証できるようになるでしょう。例えば、最近、マイクロソフトやグーグルがXAIのSDKやクラウドサービを開発者向けにリリースしましたが、これらを使って訓練済みモデルをデバック、レビューすることは来年の今頃には現場で当たり前になっていると思います。
さらに、深層学習特にCNNの再利用に関しては、転移学習、ファインチューニングと呼ばれるさまざまなノウハウが蓄積され、実際に広く使われつつあります。研究としては、特定の機械学習アルゴリズム・アーキテクチャの再利用だけではなく、開発プロセスや機械学習のシステム組込み方も再利用できるように整理する必要があります。既に鷲崎先生(早稲田大学)は、機械学習のシステムのデザインパターンをまとめられており、数年後にはGoF等のデザインパターンと同じようにパターンが使われるのではないでしょうか?
期待と妄想の狭間で
実は、今一番期待している基盤研究は、深層学習の理論的解明です。IBIS2019で行われた講演では、今泉先生(統数研)が深層学習の理論を話されていました。その中で、3層のニューラルネットワークがあれば、任意の関数が合成できるから十分という数年前まで研究者の常識だったことを深層学習が覆したのか何故か、なぜ、深層学習が持つ天文学的なパラメータの組み合わせから、現実的な時間で最適な値が見つかるのか、深層学習がどのような関数に分解できるのかという事を話されていて、目からウロコが落ち、この深層学習の理論があれば、きっとこれまで考えていた課題は解決できるに違いない!と(一人で)盛り上がっていました。(講演後今泉先生に興奮したまま話しかけてしまってごめんない。。。)
「IBIS2019での今泉先生の「深層学習の理論」セッション」

今は、これまで現場でやってきたこと言われてきたことの裏付けが得られたにすぎませんが、これら5年後には、その理論に基づいて抽象モデルの抽出や検証、再利用が行えるようになるのではないでしょうか?
統計的機械学習のソフトウェア構成は、自動的に見つけた関数による合成であり、アルゴリズムによる構成と取り扱いが少し違って来ると思っています。現実的は、機械学習とエンジニアが書いたコードは、うまく使い分けるのが、性能とメンテナンス性、安全性などのバランスをとるために必要だと思っています。訓練済みモデルとプログラムが入り混じったコードをデバックしたり、検証したりする開発環境は、これまでとは少し異なり、関数の性質を計算するツールが統合されるのでは思っています。つまり、コードレビューや検証の際に、裏でMatlabが動いて物理現象を検証するシステム検証と同じようなパラダイム統合が起こることを夢見て、今日の筆を置かせていただきます。
[PR]こういう話に興味のある方は、ぜひウィンターワークショップ2020にご参加下さい。参加〆切は12/26です!