はじめに
「Julia×JuMPで病棟シフト最適化」シリーズで作成してきたコードを Python に変換した実装を提示します。
Julia の導入がハードルに感じられる場合でも、Pythonなら環境構築が容易で現場で試しやすくなります。
入力ファイル構成
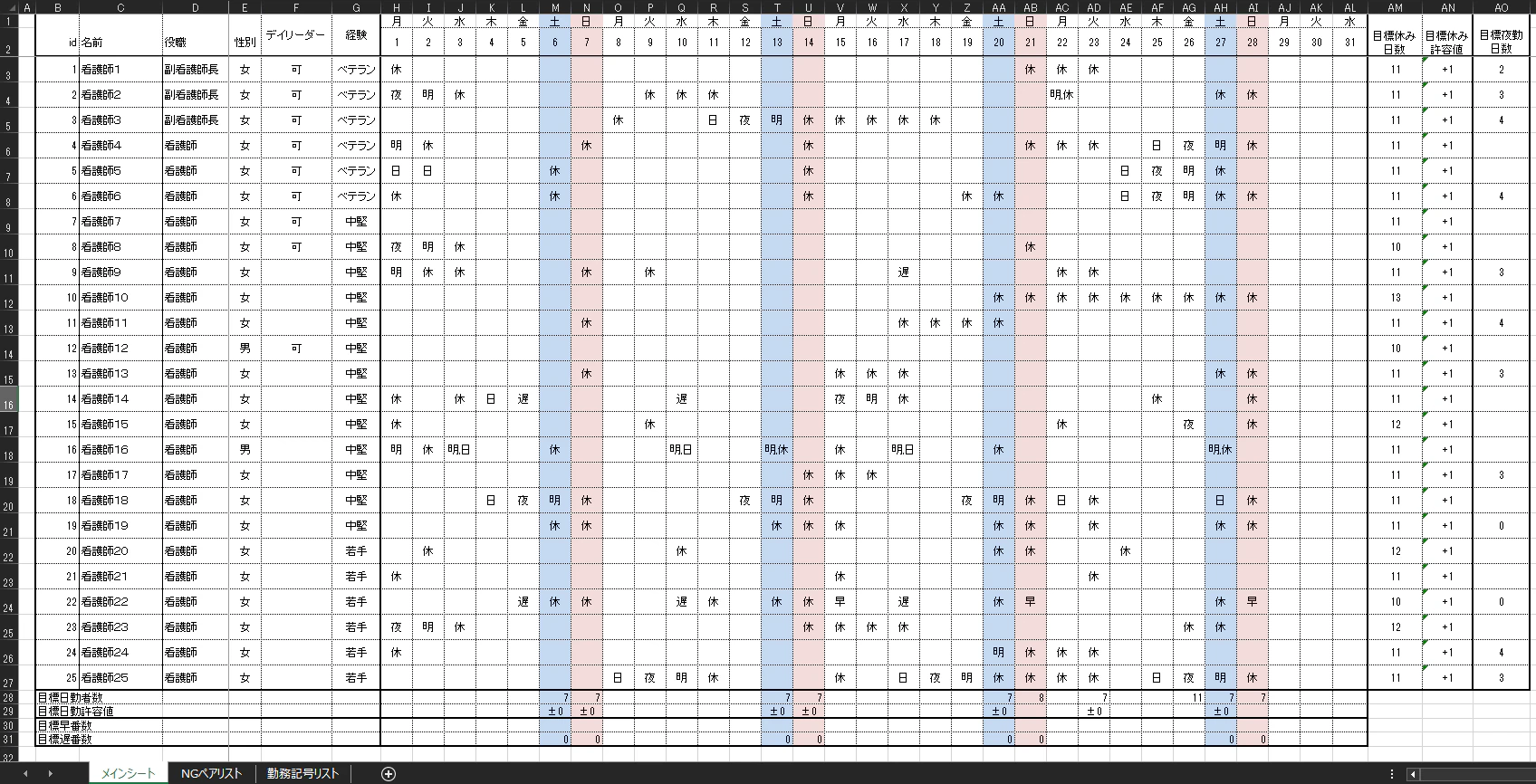

特徴
- エクセルから取得した勤務希望を反映
- 目標休日日数の確保
- 夜勤・明け要員数の確保
- 禁止シフトパターンの適用(連続パターン禁止)
- 5連勤以内制約の適用
- NGペア同時夜勤禁止
- 男性スタッフのみの夜勤禁止
- 3連休抑制
- 5連勤抑制
- 夜勤前はできる限り長日勤にする
- デイリーダー勤務の設定)
- 若手二人以上の夜勤禁止
コード
import os
import mip
import pandas as pd
import itertools
import warnings
import re
from IPython.display import display
#ソルバーの選択
# SOLVER = mip.CBC
SOLVER = mip.HIGHS
warnings.simplefilter('ignore')
#勤務区分リスト
SHIFT_TYPE = ['休', '日', '夜', '明', '早', '遅', '張', 'L', '長']
#禁止シフト
KINSHI_SHIFT = ["夜夜", "休明", "明明", "明夜",
"夜休", "夜日", "日明", "明日",
"夜早","早明","明早",
"夜遅","遅明","明遅",
"夜張","張明","明張",
"夜L","L明","明L",
"夜長","長明","明長",
"長長"
]
INPUT_EXCEL_NAME = "shift_kibou.xlsx"
data = pd.read_excel(INPUT_EXCEL_NAME, sheet_name='メインシート', header=1, index_col='id')
data = data.fillna('0')
#空白値を0で埋める
data = data.replace(' ', '0')
config = pd.read_excel(INPUT_EXCEL_NAME, sheet_name = 'NGペアリスト', header=0)
days_list = [col for col in data.columns.values if str(col).isdecimal()]
staff_list = [index for index, row in data.iterrows() if isinstance(index, int)]
# 最適化モデルの作成
model = mip.Model(name="Scheduling", solver_name=SOLVER)
x = {}
for k, d, s in itertools.product(SHIFT_TYPE, days_list, staff_list):
x[s, d, k] = model.add_var('x_{},{},{}'.format(s,d,k), var_type="B")
# ──────────────────────────────────────────────
# 1. 1日につき必ず1つのシフトを割当
# ──────────────────────────────────────────────
for s, d in itertools.product(staff_list, days_list):
model += mip.xsum(x[s, d, k] for k in SHIFT_TYPE) == 1
# ──────────────────────────────────────────────
# 2. エクセルから取得した勤務希望を反映
# ──────────────────────────────────────────────
for d, s in itertools.product(days_list, staff_list):
request = data.loc[s, d]
if request != "0":
if "," in data.loc[s, d]:
kibou_list = []
for kibou in data.loc[s, d].split(","):
kibou_list.append(SHIFT_TYPE.index(kibou))
if len(kibou_list):
model += mip.xsum(x[s, d, SHIFT_TYPE[k]] for k in kibou_list) == 1
else:
model += x[s, d, request] == 1
# ──────────────────────────────────────────────
# 3. 目標休日日数の確保
# ──────────────────────────────────────────────
for s in staff_list:
target_num = data.loc[s,'目標休み日数']
off_shift_count = mip.xsum(x[s, d, SHIFT_TYPE[0]] for d in days_list) - target_num
if "+" in str(data.loc[s,'目標休み許容値']):
model += off_shift_count <= int(data.loc[s,'目標休み許容値'].replace("+",""))
model += off_shift_count >= 0
else:
model += off_shift_count == 0
# ──────────────────────────────────────────────
# 4. 夜勤・明け要員数の確保(毎日3名ずつ)
# ──────────────────────────────────────────────
for d in days_list:
y = 3
model += mip.xsum(x[s, d, SHIFT_TYPE[2]] for s in staff_list) == y
model += mip.xsum(x[s, d, SHIFT_TYPE[3]] for s in staff_list) == y
# ──────────────────────────────────────────────
# 5. 早番要員数の確保
# ──────────────────────────────────────────────
for d in days_list:
count = 0
for s in staff_list:
if data.loc[s, d] == SHIFT_TYPE[4]:
count += 1
#指定が無い場合は基本1人/day
num = 1
if data.loc["目標早番数", d] != "0":
num = int(data.loc["目標早番数", d])
elif count:
num = count
model += mip.xsum(x[s, d, SHIFT_TYPE[4]] for s in staff_list) == num
# ──────────────────────────────────────────────
# 6. 遅番要員数の確保
# ──────────────────────────────────────────────
for d in days_list:
count = 0
for s in staff_list:
if data.loc[s, d] == SHIFT_TYPE[5]:
count += 1
#指定が無い場合は基本1人/day
num = 1
if data.loc["目標遅番数", d] != "0":
num = int(data.loc["目標遅番数", d])
elif count:
num = count
model += mip.xsum(x[s, d, SHIFT_TYPE[5]] for s in staff_list) == num
# ──────────────────────────────────────────────
# 7. 禁止シフトパターンの適用
# ──────────────────────────────────────────────
for k, s, d in itertools.product(KINSHI_SHIFT, staff_list, days_list):
t = len(k) - 1
if int(d) > t:
model += mip.xsum(x[s, int(d) - t + h, k[h]] for h in range(t + 1)) <= t
#出張希望の日以外は禁止
for s, d in itertools.product(staff_list, days_list):
if data.loc[s, d] != "張":
model += x[s, d, SHIFT_TYPE[6]] == 0
# ──────────────────────────────────────────────
# 8. スタッフ毎の夜勤回数の適用
# ──────────────────────────────────────────────
max_yakin = model.add_var(lb=0, ub=8, var_type="I" , name="max_yakin")
for s in staff_list:
if data.loc[s, '目標夜勤日数'] != '0':
model += mip.xsum(x[s, d, SHIFT_TYPE[2]] for d in days_list) == data.loc[s, '目標夜勤日数']
else:
model += mip.xsum(x[s, d, SHIFT_TYPE[2]] for d in days_list) <= max_yakin
# ──────────────────────────────────────────────
# 9. 日中勤務者(日勤+早番+遅番+デイリーダー)の人数設定
# ──────────────────────────────────────────────
max_nikkin = model.add_var(lb=8, ub=15, var_type="I" , name="max_nikkin")
min_nikkin = model.add_var(lb=2, ub=10, var_type="I" , name="min_nikkin")
kinmu = [SHIFT_TYPE[1], SHIFT_TYPE[4], SHIFT_TYPE[5], SHIFT_TYPE[7], SHIFT_TYPE[8]]
for d in days_list:
day_shift_count = mip.xsum(x[s, d, k] for s in staff_list for k in kinmu)
if int(data.loc['目標日勤者数', d]) != 0:
if "±" in str(data.loc['目標日勤許容値', d]):
model += day_shift_count == data.loc['目標日勤者数', d]
else:
model += day_shift_count <= max_nikkin
model += day_shift_count >= data.loc['目標日勤者数', d]
else:
model += day_shift_count <= max_nikkin
model += day_shift_count >= min_nikkin
# ──────────────────────────────────────────────
# 10. 5連勤以内制約
# ──────────────────────────────────────────────
max = 5
for s in staff_list:
for d in days_list[max:]:
model += mip.xsum(x[s, int(d) - h, k] for h in range(max + 1) for k in SHIFT_TYPE[1:]) <= max
# ──────────────────────────────────────────────
# 11. NGペア同時夜勤禁止
# ──────────────────────────────────────────────
for d in days_list:
for index, row in config.iterrows():
model += mip.xsum(x[s, d, SHIFT_TYPE[2]] for s in [row['スタッフ1'], row['スタッフ2']]) <= 1
# ──────────────────────────────────────────────
# 12. 男性スタッフのみの夜勤禁止
# ──────────────────────────────────────────────
man_staff_list = data[data['性別'] == '男'].index.tolist()
for d in days_list:
model += mip.xsum(x[s, d, SHIFT_TYPE[2]] for s in man_staff_list) <= 2
# ──────────────────────────────────────────────
# 13. 3連休抑制
# ──────────────────────────────────────────────
is_renkyu = {
(s, d): model.add_var(name=f"is_renkyu_{s},{d}_", var_type="B") for s, d in itertools.product(staff_list, days_list)
}
renkyu_days = 3
renkyu_weight = 1
for s in staff_list:
for d in days_list[:-2]:
no_work_count = mip.xsum(x[s, d + h, SHIFT_TYPE[0]] for h in range(renkyu_days))
model += no_work_count - (renkyu_days - 1) <= is_renkyu[s, d]
model += no_work_count - renkyu_days + 0.001 >= -renkyu_days * (1 - is_renkyu[s, d])
renkyu = mip.xsum(is_renkyu[s, d] for s in staff_list for d in days_list[:-2]) * renkyu_weight
# ──────────────────────────────────────────────
# 14. 5連勤抑制
# ──────────────────────────────────────────────
is_renkin = {
(s, d): model.add_var(name=f"is_renkin_{s},{d}_", var_type="B") for s, d in itertools.product(staff_list, days_list)
}
renkin_days = 5
for s in staff_list:
for d in days_list[:-4]:
work_count = mip.xsum(x[s,int(d) + h, k] for h in range(5) for k in SHIFT_TYPE[1:])
model += work_count - (renkin_days - 1) <= is_renkin[s, d]
model += work_count - renkin_days + 0.001 >= -renkin_days * (1- is_renkin[s, d])
renkin = mip.xsum(is_renkin[s, d] for s in staff_list for d in days_list)
# ──────────────────────────────────────────────
# 15. 夜勤前はできる限り長日勤にする
# ──────────────────────────────────────────────
nya = {
(s, d): model.add_var(name=f"nya_{s},{d}_", var_type="B") for s, d in itertools.product(staff_list, days_list)
}
for s in staff_list:
for d in days_list[1:]:
model += nya[s, d] <= x[s, d, SHIFT_TYPE[2]]
model += nya[s, d] <= x[s, d-1, SHIFT_TYPE[8]]
model += nya[s, d] >= x[s, d, SHIFT_TYPE[2]] + x[s, d-1, SHIFT_TYPE[8]] - 1
nya_shift = -1 * mip.xsum(nya[s, d] for s in staff_list for d in days_list[1:])
# ──────────────────────────────────────────────
# 16. デイリーダー勤務の設定
# ──────────────────────────────────────────────
max_leader = model.add_var(lb=0, ub=15, var_type="I" , name="max_leader")
day_leader_list = data[(data['デイリーダー'] == '可')].index.tolist()
non_day_leader_list = [id for id in data[~(data['デイリーダー'] == '可')].index.tolist() if isinstance(id, int)]
model += mip.xsum(x[s, d, SHIFT_TYPE[7]] for s in non_day_leader_list for d in days_list) == 0
for d in days_list:
model += mip.xsum(x[s, d, SHIFT_TYPE[7]] for s in day_leader_list) == 1
for s in day_leader_list:
model += mip.xsum(x[s, d, SHIFT_TYPE[7]] for d in days_list) <= max_leader
# ──────────────────────────────────────────────
# 17. 若手二人以上の夜勤を禁止
# ──────────────────────────────────────────────
staff_rookie_list = data[data['経験'] == '若手'].index.tolist()
for d in days_list:
model += mip.xsum(x[s, d, SHIFT_TYPE[2]] for s in staff_rookie_list) <= 1
# ──────────────────────────────────────────────
# 18. 長日勤と夜勤のバランス制約
# 長日勤のと夜勤の回数はイコールとする
# ──────────────────────────────────────────────
for s in staff_list:
model += mip.xsum(x[s, d, SHIFT_TYPE[8]] - x[s, d, SHIFT_TYPE[2]] for d in days_list) == 0
# ──────────────────────────────────────────────
# 19. 長日勤は夜勤者数と同数とする(今回は3)
# ──────────────────────────────────────────────
for d in days_list:
model += mip.xsum(x[s, d, SHIFT_TYPE[8]] for s in staff_list) == 3
# 目的関数の定義
model.objective = mip.minimize(max_yakin + (max_nikkin - min_nikkin) + renkyu + renkin + nya_shift + max_leader)
# モデルの最適化実行
model.optimize()
result = pd.DataFrame(data=None, index=staff_list, columns=days_list)
for s, d, k in itertools.product(staff_list, days_list, SHIFT_TYPE):
if round(x[s,d,k].x) == 1.0:
result.loc[s, d] = k
print(f"最適性 = {model.status}")
print(f"目的関数値 = {model.objective_value}, ", end="\n")
print(f"max_yakin = {max_yakin.x}, ", end="\n")
print(f"max_nikkin = {max_nikkin.x}, ", end="\n")
print(f"min_nikkin = {min_nikkin.x}, ", end="\n")
print(f"renkyu = {renkyu.x}, ", end="\n")
print(f"renkin = {renkin.x}, ", end="\n")
print(f"nya_shift = {nya_shift.x}, ", end="\n")
print(f"max_leader = {max_leader.x}, ", end="\n")
print(f"", end="\n")
renkin_list1 = {}
renkin_list2 = {}
renkin_list3 = {}
pattern1 = re.compile(r'[休]{3}')
pattern2 = re.compile(r'[日夜明早遅張L長]{5}')
pattern3 = re.compile(r'[日夜明早遅張L長]{6,31}')
for index, row in result.iterrows():
msg = ""
if not str(index).isdecimal(): continue
for column_name, item in row.items():
if str(column_name).isdecimal():
msg += str(item)
renkin_list1[index] = str(len([m.end() for m in pattern1.finditer(msg)]))
renkin_list2[index] = str(len([m.end() for m in pattern2.finditer(msg)]))
renkin_list3[index] = str(len([m.end() for m in pattern3.finditer(msg)]))
result["休"] = ((result=='休').sum(axis=1)).astype("str")
result["夜勤"] = (result=='夜').sum(axis=1)
result["L"] = (result=='L').sum(axis=1)
result["3連休"] = renkin_list1
result["5連勤"] = renkin_list2
result["6連勤以上"] = renkin_list3
result.loc["日勤"] = (result=='日').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64") \
+ (result=='早').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64") \
+ (result=='遅').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")\
+ (result=='L').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")\
+ (result=='長').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["夜勤"] = (result=='夜').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["明け"] = (result=='明').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["早番"] = (result=='早').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["遅番"] = (result=='遅').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["出張"] = (result=='張').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["リーダー"] = (result=='L').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
result.loc["長日勤"] = (result=='長').filter(regex='^([0-9]+)$', axis=1).sum().astype("Int64")
from tabulate import tabulate
print(tabulate(result, headers='keys', tablefmt='simple'))
まとめ
- Julia ロジックを維持しつつPythonにコンバート。
- 上のスクリプトは実務でよく要求される制約群です。現場ルールや運用要件に合わせて制約の緩和やペナルティ化の追加を検討してください。
関連記事
‹‹ 前回 「Julia×JuMPで病棟シフト最適化⑤(最終回):最後の機能追加で実務レベルを高める」
https://qiita.com/kaz_ict_nurse/items/d5185cd6ed65b2366eb4