自分
経理屋です。35才から趣味でpythonを始めて3年が経ちました。最近は徐々にwebアプリなんかも作れるようになってきてすごく楽しいです。よろしくお願いします。
まだまだ未熟ですが、誰かの役に立つかなーと思って記事を書いてみました。
とっかかり
ここ最近まで長野県は新型コロナの発生が少なかったんですが、最近になってかなり増えてきました。出かける時もどこに出かければいいか少々不安です。
そんなタイミングで長野県のホームページにコロナ発生状況のCSVデータが公開されているのを見つけたので(今さら)グラフで見れるサイトを作って見ました。
出来上がりはこちら →covid19 in nagano
全体イメージ
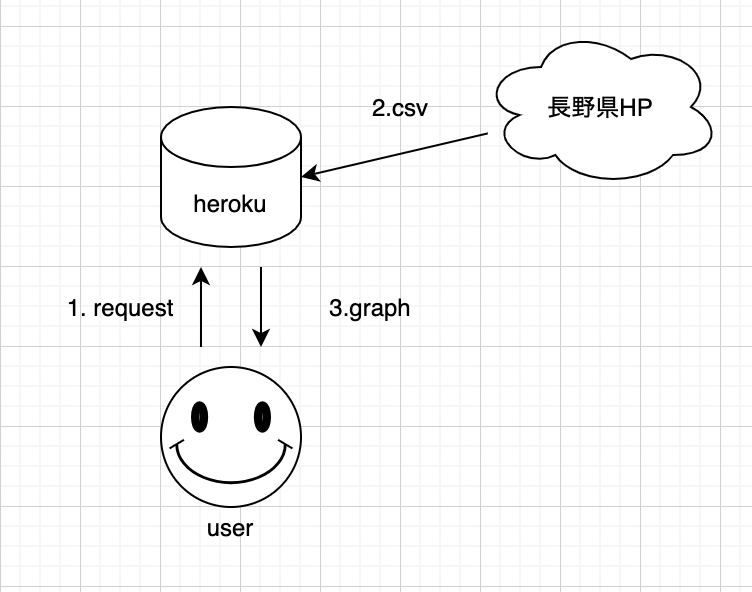
手順
目次
- データ確認
- streamlitでアプリケーション作成
- herokuへアップ
- GASでherokuを起こす設定
番外編: 継続管理
1.データ確認
下記リンクに長野県内のコロナ発生状況がアップされているので、お手軽にgoogle colaboratoryで内容を確認します。
今回は最終的にstreamlitでアプリを作成するので、データ分析に使ったpythonコードはstreamlit用のファイルでも使います。
import pandas as pd
df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1)
df.head()
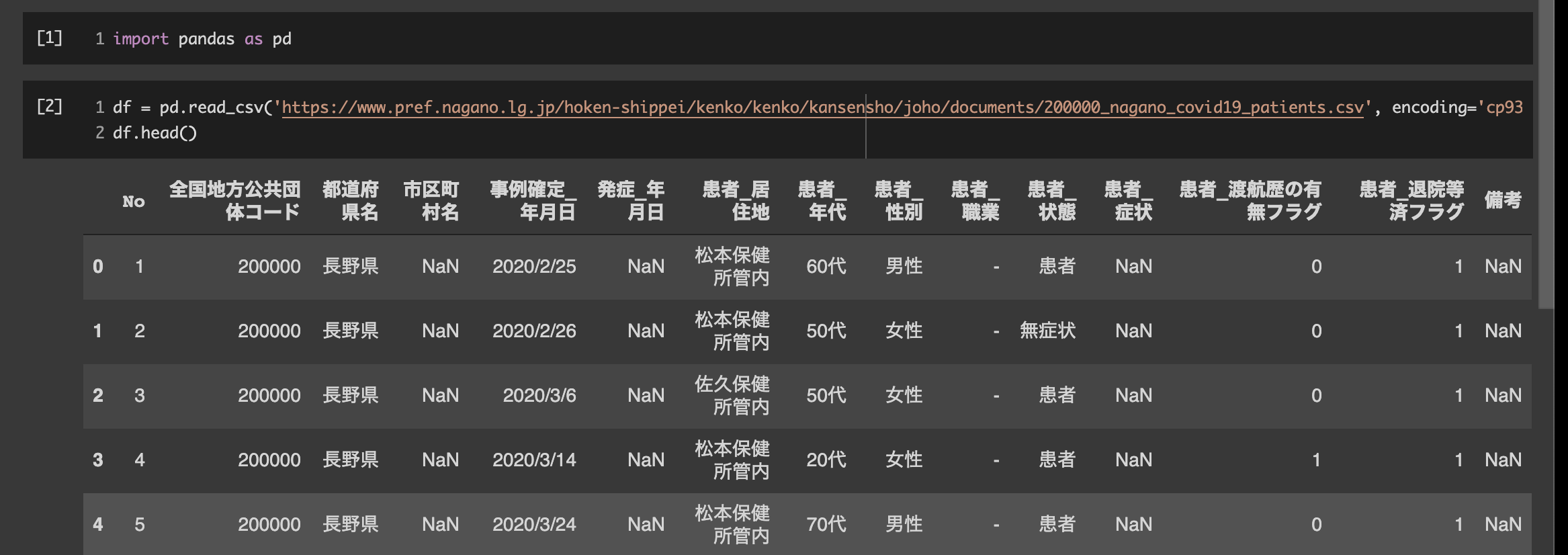
いろんな項目がありますが、必要なデータだけに絞り込みます。
項目名をわかりやすい名前に変更します。
ついでに日付のデータ型をdatetimeに変換します。
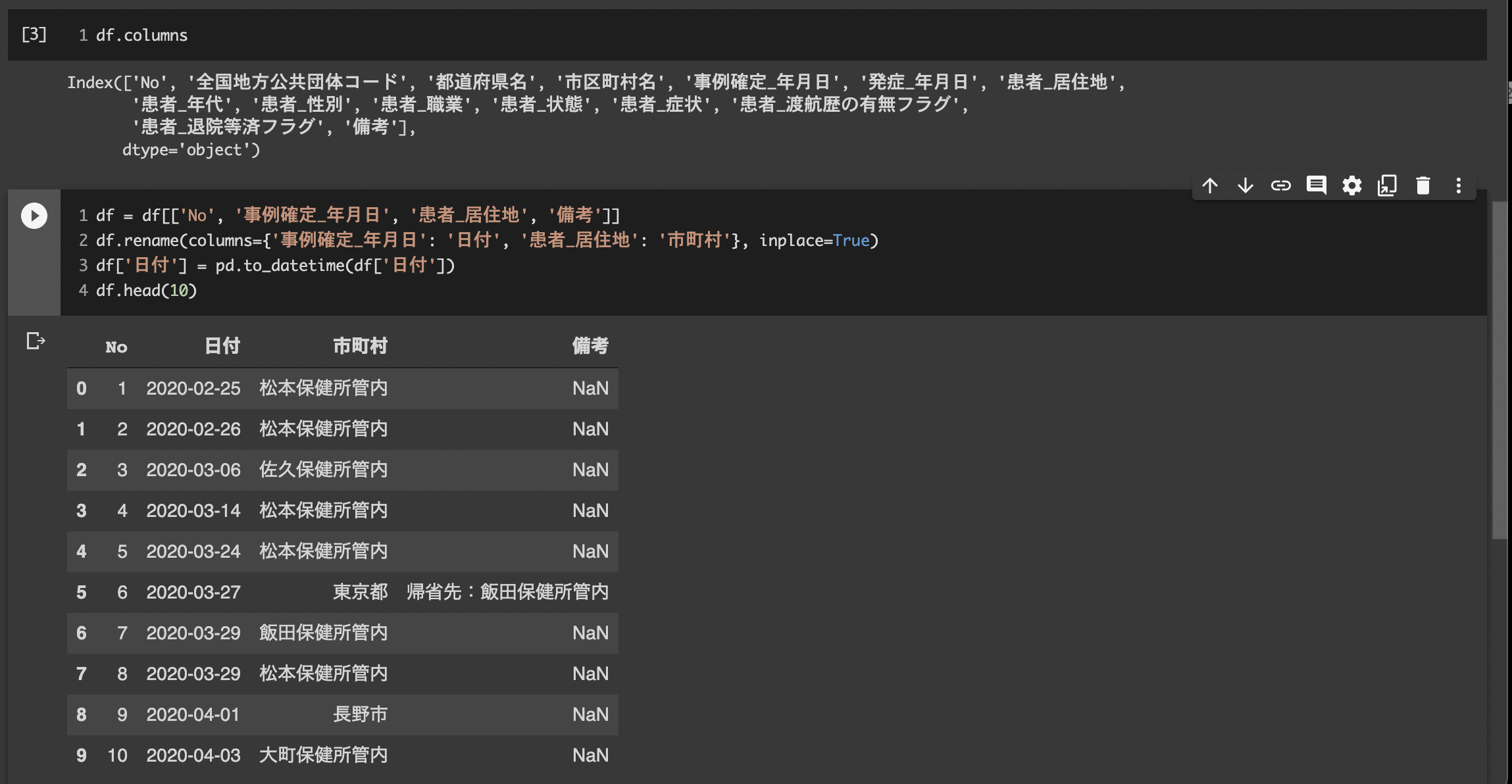
df.columns
df = df[['No', '事例確定_年月日', '患者_居住地', '備考']]
df.rename(columns={'事例確定_年月日': '日付', '患者_居住地': '市町村'}, inplace=True)
df['日付'] = pd.to_datetime(df['日付'])
df.head(10)
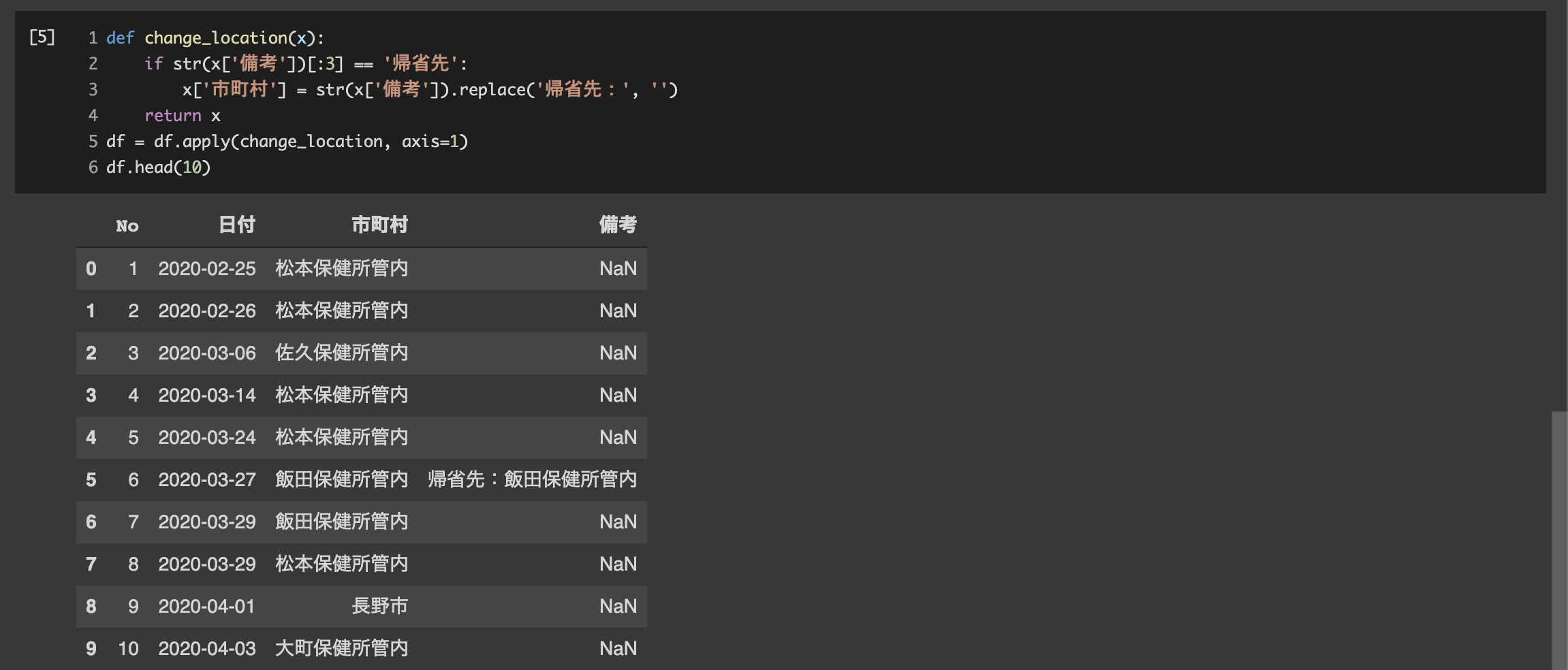
東京に住んでて長野で発症したみたいな人は居住地が東京で備考に県内の市町村名が記載されているので、そういった人については市町村を「帰省先:」の後の文字列に変換します。
def change_location(x):
if str(x['備考'])[:3] == '帰省先':
x['市町村'] = str(x['備考']).replace('帰省先:', '')
return x
df = df.apply(change_location, axis=1)
df.head(10)
変換された市町村を見ると、まだ市町村名でないものが含まれているので、仕方ないので手作業でリストを作って市町村名のものだけ抽出します。それ以外のものは「その他」に変換します。
市町村名も'南箕輪村'だったり'上伊那郡南箕輪村'だったり'上伊那郡\r\n南箕輪村'だったりしているので、バシッと1本に統一します。
また、このリストに含まれていない市町村もあるので、たまにそういった市町村が新たに出てきていないか確認してリストを更新してやる必要があります。
この辺は少し大変です。もっといいアイデアがあれば教えて欲しいです。
df['市町村'].unique()
towns = ['長野市', '山ノ内町',
'上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村',
'小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市',
'生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村',
'原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村',
'木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村',
'南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町',
'南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町',
'天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村',
'北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町',
'駒ケ根市', '小川村', '喬木村', '松川町']
def change_towns(x):
if x['市町村'] not in towns:
x['市町村'] = 'その他'
return x
df = df.apply(change_towns, axis=1)
df['市町村'] = df['市町村'].str.replace('上伊那郡南箕輪村', '南箕輪村')
df['市町村'] = df['市町村'].str.replace('上伊那郡\r\n南箕輪村', '南箕輪村')
df['市町村'] = df['市町村'].str.replace('下高井郡\r\n野沢温泉村', '野沢温泉村')
df['市町村'] = df['市町村'].str.replace('南佐久郡川上村', '川上村')
df['市町村'] = df['市町村'].str.replace('北佐久郡御代田町', '御代田町')
df['市町村'].unique()

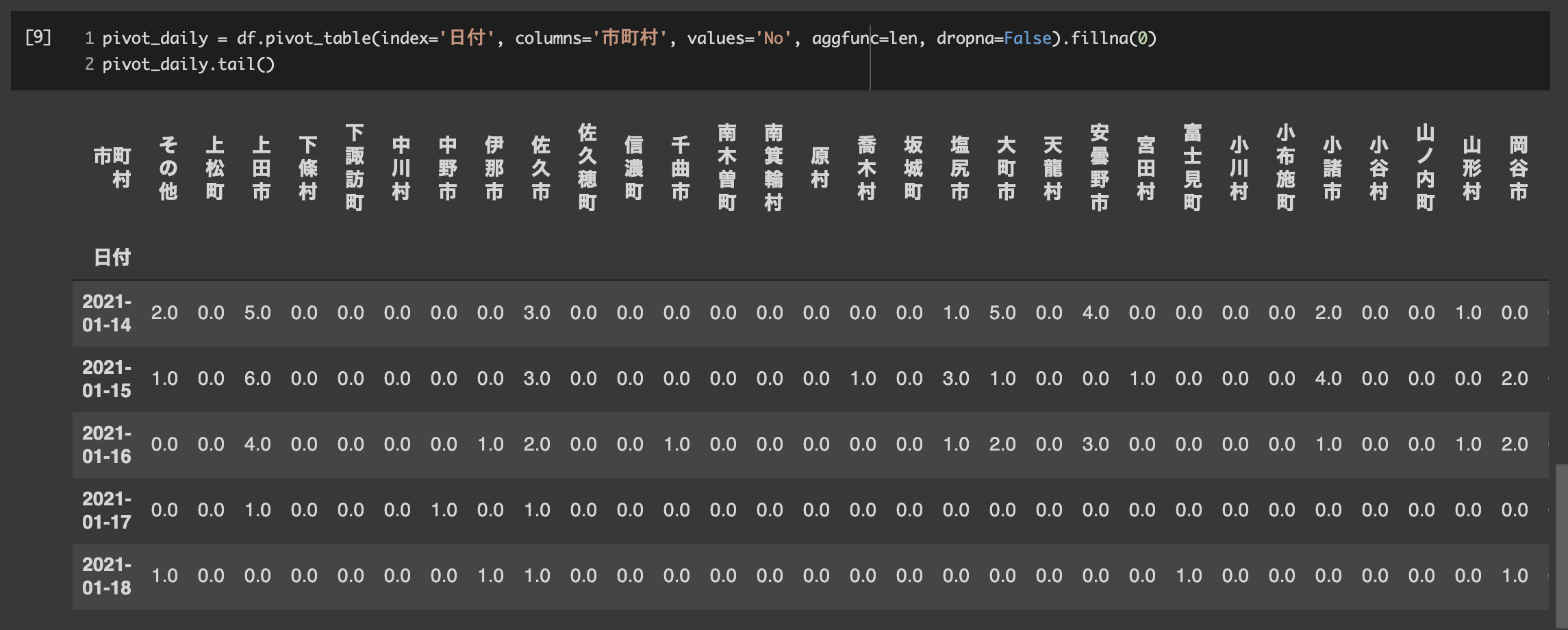
pivot_tableすると無事に市町村別の発生件数が集計されました。
pivot_daily = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0)
pivot_daily.tail()
累計はcumsumです。
pivot_daily_cum = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0).cumsum()
pivot_daily_cum.tail()

2.streamlitでアプリケーション作成
データが確認できたので、streamlitで実際のアプリケーションを作成します。
streamlitをインストールし、pythonファイルを作成します。streamlitの使い方に関しては私よりわかりやすく説明されている方がネット上に大勢いるのでそちらにお任せします。
またstreamlitは公式のtutorialが非常に充実しているので、そちらを一通りやるだけでわかった気になれます。大丈夫です。
import streamlit as st
import plotly.express as px
import pandas as pd
import datetime
df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1)
df = df[['No', '事例確定_年月日', '患者_居住地', '備考']]
# 項目名を変更、日付のデータ型変更
df.rename(columns={'事例確定_年月日':'日付', '患者_居住地':'市町村'}, inplace=True)
df['日付'] = pd.to_datetime(df['日付'])
# 備考に「帰省先:」と入っているデータは市町村を変換
def change_location(x):
if str(x['備考'])[:3] == '帰省先':
x['市町村'] = str(x['備考']).replace('帰省先:', '')
return x
df = df.apply(change_location, axis=1)
# 市町村欄に市町村名以外のものが入っていたら変換
towns = ['長野市', '山ノ内町',
'上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村',
'小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市',
'生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村',
'原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村',
'木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村',
'南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町',
'南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町',
'天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村',
'北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町',
'駒ケ根市', '小川村', '喬木村', '松川町']
def change_towns(x):
if x['市町村'] not in towns:
x['市町村'] = 'その他'
return x
df = df.apply(change_towns, axis=1)
df['市町村'] = df['市町村'].str.replace('上伊那郡南箕輪村', '南箕輪村')
df['市町村'] = df['市町村'].str.replace('上伊那郡\r\n南箕輪村', '南箕輪村')
df['市町村'] = df['市町村'].str.replace('下高井郡\r\n野沢温泉村', '野沢温泉村')
df['市町村'] = df['市町村'].str.replace('南佐久郡川上村', '川上村')
df['市町村'] = df['市町村'].str.replace('北佐久郡御代田町', '御代田町')
# sidemenu
st.sidebar.markdown(
'# Covid-19 in Nagano'
)
town_selected = st.sidebar.selectbox(
"市町村", list(df['市町村'].unique()), 1 # デフォルトではリスト番号1の'長野市'を表示
)
st.sidebar.markdown(
'「その他」には、「松本保健所管内」や「東京都」などの、市町村名でない表記のものが含まれます。'
)
today = datetime.date.today()
start_date = st.sidebar.date_input('開始日', df['日付'].min())
end_date = st.sidebar.date_input('終了日', today)
if start_date < end_date:
st.sidebar.success('OK')
else:
st.sidebar.error('Error:終了日は開始日より後の日付にしてください。')
df = df[df['日付'].between(pd.to_datetime(start_date), pd.to_datetime(end_date))]
# body
# 1日あたり発生件数グラフ
st.markdown(
'# 市町村別発生件数(日付別)'
)
st.markdown(
'チャートをドラッグすると拡大できます。'
)
pivot_daily = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0)
st.write(
px.bar(pivot_daily, x=pivot_daily.index, y=town_selected)
)
# 発生件数累計推移のグラフ
st.markdown(
'# 市町村別発生件数(累計)'
)
pivot_daily_cum = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0).cumsum()
st.write(
px.area(pivot_daily_cum, x=pivot_daily_cum.index, y=town_selected)
)
# 市町村別累計発生件数の全市町村比較
st.markdown(
'# 市町村別発生件数(累計, 全市町村比較)'
)
data_span = st.radio(
"集計期間",
('直近30日', '全期間')
)
if data_span == '直近30日':
df = df[df['日付'] >= str(today - datetime.timedelta(days=30))]
town_cum = pd.DataFrame(df.groupby('市町村')['No'].count().sort_values())
town_cum.rename(columns={'No':'発生件数累計'}, inplace=True)
st.write(
px.bar(town_cum, x='発生件数累計', y=town_cum.index, orientation='h', height=1500, hover_data=['発生件数累計', town_cum.index])
)
Terminalでview.pyのあるディレクトリにcdしてrunするとアプリケーションが立ち上がります。
$ streamlit run view.py
3.herokuへアップ
herokuへのアップする方法は全然わからなかったので、下記のサイト様を参考にさせていただきました。
→【簡単爆速第2弾】Streamlitをherokuにデプロイ
他にも色々なサイト様を見せていただいたんですが覚えていません。すみません。
よくわかっていませんが、下記の手順でやったら動きました。
・必要なディレクトリとファイルを自分のPC内に準備
web: sh setup.sh && streamlit run view.py
streamlit==0.74.1
plotly==4.14.3
pandas
※下記のメールアドレス部分はご自分のものに変更してください。
mkdir -p ~/.streamlit/
echo "\
[general]\n\
email = \"mailaddress@dmain.com\"\n\
" > ~/.streamlit/credentials.toml
echo "\
[server]\n\
headless = true\n\
enableCORS=false\n\
port = $PORT\n\
" > ~/.streamlit/config.toml
・herokuにアカウント作成
・Terminalを立ち上げて下記を実行
※appnameの部分は自分の好きなアプリ名に変えてください。
$ heroku login
$ heroku create appname
$ git init
$ heroku git:remote -a sample
$ heroku buildpacks:set heroku/python
$ git add .
$ git commit -m "1st commit"
$ git push heroku master
$ heroku open
上手くいっていればこれでCSVをグラフ化したページが見れると思います。
間違えてたらすみません。
4.GASでherokuを起こす設定
herokuは30分間何も実行されないと自動的にスリープになってしまい、次の立ち上がりの時に時間がかかってしまうようです。そこで定期的にherokuにアクセスしてherokuをスリープさせないようにしました。
いろんなやり方があるようですが、自分はherokuにクレジット登録をしないでおこうと思ったのでGASを選びました。「GAS heroku」で検索すると、非常に丁寧に説明してくれているサイトがたくさん出てきました。ありがたや。
継続管理
データ分析の中で少し触れましたが、今回のプロジェクトでは市町村のリスト(towns)を手で作成して使っています。なのでこの先townsに入っていない市町村名がCSVに入力されてくるとグラフ用の集計から漏れてしまいます。
そのためどうしても手作業で市町村名の漏れがないかどうかの確認が必要になってしまいます。めんどいですね。
1/20の例だと、早速松川町が新たに出てきてました。
import pandas as pd
towns = ['長野市', '山ノ内町',
'上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村',
'小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市',
'生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村',
'原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村',
'木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村',
'南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町',
'南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町',
'天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村',
'北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町',
'駒ケ根市', '小川村', '喬木村']
df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1)
df[~df['患者_居住地'].isin(towns)]['患者_居住地'].unique()
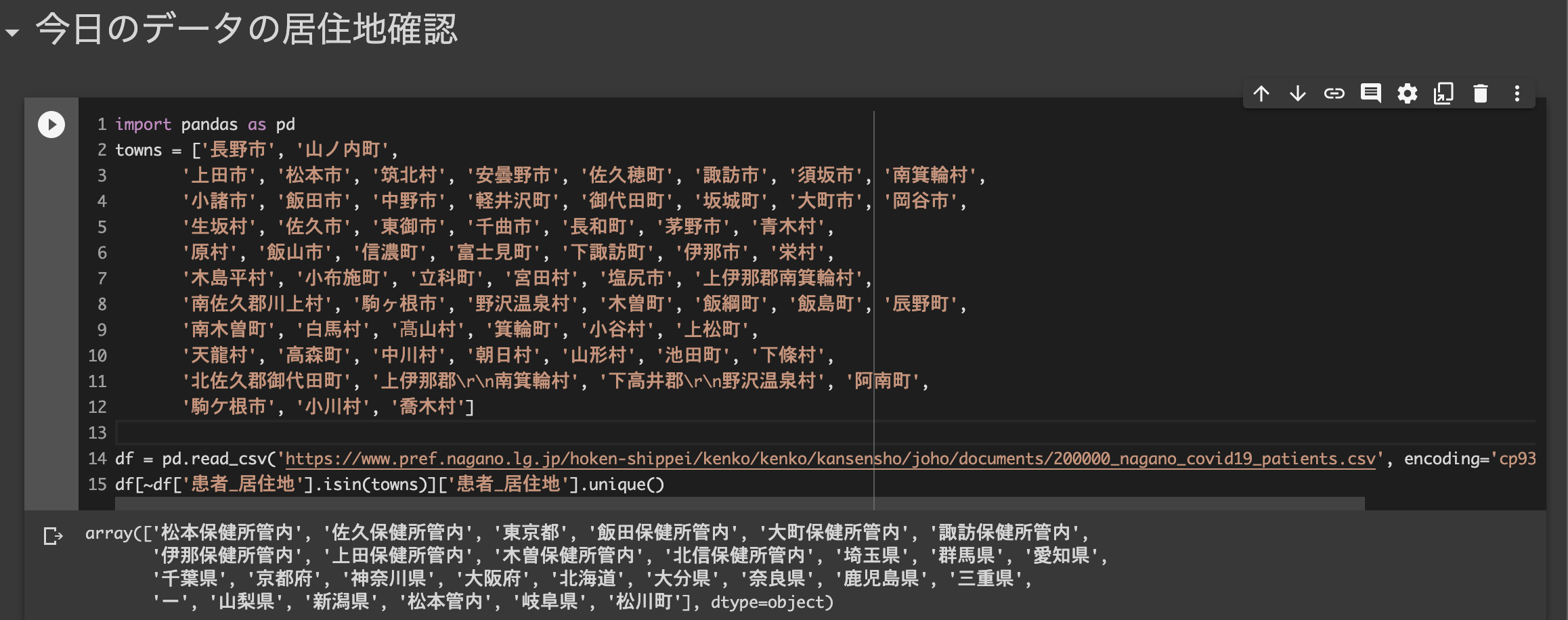
目視で漏れを確認
↓
手元でview.pyを編集してherokuにpush
もしくはherokuで直接編集でしょうか?
自分は前者でやってます。
終わりに
今回は長野県のCSVデータでやってますが、他県でも似たようなデータを公開している(そして自動的に毎日更新されていく)ものがあれば今回の手順がすぐに応用できると思います。
たいしたコードではないですがもし参考になる部分があれば使って、他県のグラフも作っていただければと思います。
そして今より少しでも世の中便利になっていけばいいなと思います。
また、自分は独学で勉強してきたので、もっといいやり方あるよとかここのコードはこう書いた方がいいよとかありましたら教えていただけるとありがたいです。よろしくお願いします。
終わり。