なにこれ
非プログラマーの経理屋向け。
経理屋の自分が書き溜めたスニペットがそれなりの量になってきたので、共有します。
普段はsimplenoteに保存しといてコピペして使ってます。simplenote軽くておすすめ。
使用環境:Windows、VSCode、Jupyterエクステンション(主に使うのは#%%の方)
使用環境:Windows、VSCode、Jupyterエクステンション(主に使うのは#%%の方)
ひとこと
Pythonを学び始めてもうすぐ4年になりますが、最初の頃はいくつか関数を覚えてもなかなか便利になった感を感じられずにいました。これは多分英語も単語をバラバラに覚えただけでは話せるようにならないのと同じで、ある程度のまとまりのある熟語や文章でどんなことをできるか覚えたほうが、やりたいことができるようになると思いました。
スニペット
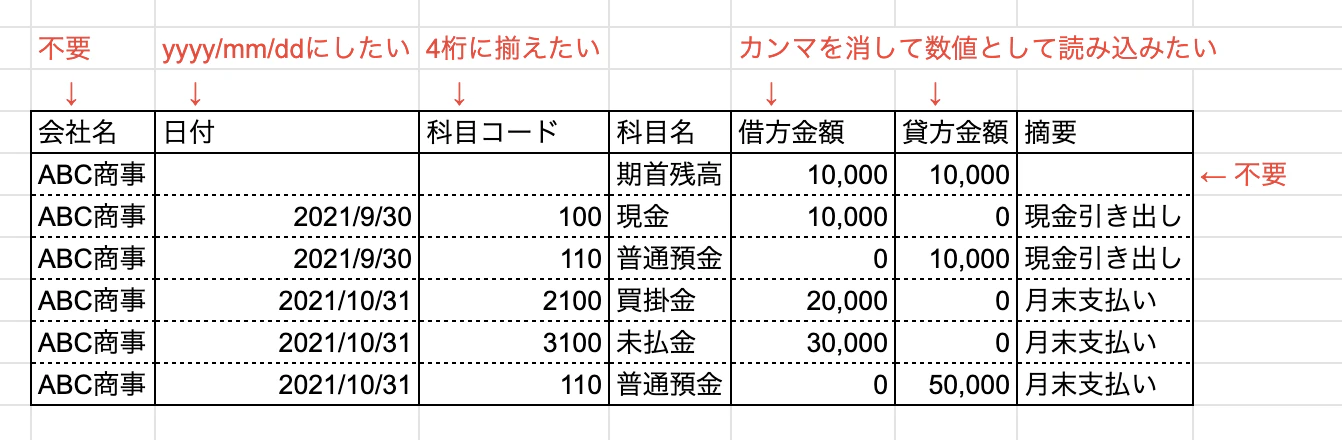
サンプルデータ
モジュールのインポート
sample.py
from glob import glob
import pandas as pd
ファイル読み込み
sample.py
df = pd.read_csv('csv/data1.csv', encoding='cp932', dtype='str')
メモ:
経理やってるとWindows環境で日本語が入ってるデータが多いと思います。 そうするとencodingの記述が必要です。面倒です。 また、予期せぬデータ型の変換(取引先コード”001”を勝手に数字型の"1"にしてしまうとか)が嫌なのと、読み込み速度を速くするため、一旦全てのデータを文字列型として読み込むようにしています。不要な列を削除
- 読み込みの時点で除外する場合
sample.py
df = pd.read_csv('csv/data1.csv',
encoding='cp932',
usecols=[1,2,3,4,5,6],
dtype='str')
メモ:
読み込む時点で不要な列を読み込まないパターンです。0列目の会社名を飛ばしてます。 コードの記述量は少ないです。どの列を使っているかはコードからはわかりにくいです。- 全部読み込んでから必要な列だけ抽出する場合
sample.py
df = pd.read_csv('csv/data1.csv', encoding='cp932', dtype='str')
df.columns
出力結果を列の指定欄にコピペして編集
sample.py
df = df[['日付', '科目コード', '科目名', '借方金額', '貸方金額', '摘要']]
メモ:
一旦全部読み込んでから必要な列だけを抽出するパターンです。どの列を使っているか、後からコードを見返した時もわかりやすい。複数ファイルをまとめて読み込み
sample.py
# ファイルパスをリストとして取得
f_list = glob('csv/*.csv')
# f_listのそれぞれのファイルパスごとにread_csvして結果をd_listに追加
d_list = []
for f in f_list:
d = pd.read_csv(f, encoding='cp932', dtype='str')
d_list.append(d)
# データを結合、列を絞り込み
df = pd.concat(d_list)
df = df[['日付', '科目コード', '科目名', '借方金額', '貸方金額', '摘要']]
df
メモ:
glob関数の中で使っている「*(アスタリスク)」は、任意の文字列に合致するワイルドカードです。
f_listの中身は
['csv/data1.csv', 'csv/data2.csv', 'csv/data3.csv']
のようになります。
次にf_listの中身1つずつに対してread_csvして、結果をd_listの中に追加していきます。 d_listの中身は [1個目のデータ, 2個目のデータ, 2個目のデータ] のようになります。
最後にpd.concat()で全部繋げます。 サンプルコードでは列も必要な列だけに絞ってます。 実行結果↓ 
次にf_listの中身1つずつに対してread_csvして、結果をd_listの中に追加していきます。 d_listの中身は [1個目のデータ, 2個目のデータ, 2個目のデータ] のようになります。
最後にpd.concat()で全部繋げます。 サンプルコードでは列も必要な列だけに絞ってます。 実行結果↓ 
不要な行を削除
sample.py
df = df.dropna(subset=['日付'])
df
メモ:
たまに、csvの中に合計行のような行がいて、いらないなーと思うことがあります。今回の例ですとその行は日付が空欄(NA)になっているので、日付が空欄(NA)=削除対象として行を削除します。 実行結果↓ 日付をyyyy/mm/ddに変換
sample.py
df['日付'] = pd.to_datetime(df['日付']).dt.strftime('%Y/%m/%d')
df
メモ:
経理やってると会計システムだけではなく、固定資産管理システムや売上管理システムなどいろいろなシステムからデータが出てきます。日付の書式が統一されていないと地味に不便なので、自分の中でyyyy/mm/ddの文字列型に統一してます。 コードの内容としては、日付を一旦文字列型からdate型に変換して、yyyy/mm/ddの形式の文字列型に再度変換してます。 実行結果↓ 科目コードを4桁に統一
sample.py
df['科目コード'] = df['科目コード'].map(lambda x: x.zfill(4))
df
メモ:
経理やってると、なんとかコードとかという名前のものは、「100」ではなく「0100」という書式に統一して扱いたいときがあります。 上記のコードについてはlambda使うので正直難しいです。mapもapply、sapplyとかと頭の中で混ざってて理解しきれてないです。でもスニペット作っといて使えばなんとかなってます。 kaggleではzfill()とかあまり使いませんが、経理ではよく使います。 実行結果↓ 「,(カンマ)」を消して数値型に変換する
sample.py
df['借方金額'] = df['借方金額'].str.replace(',', '').astype(int)
df
メモ:
数字にカンマが混ざっているデータに対して、データ型を指定せずに読み込むと文字列として読み込まれます。また、カンマを消さずにastype()で数値型に変換しようとするとエラーになります。なので一旦カンマを取り除いてから数値型に変換してやります。カンマがあっても数値型として読み込んでくれればいいのに。 実行結果↓  重複しない要素の取得
sample.py
# 見づらいが、お手軽
df['日付'].unique()
メモ:
重複しない要素がどんな感じか見たい時に。 実行結果↓ sample.py
# 見やすい
pd.Series(df['日付'].unique())
メモ:
同上。 実行結果↓ 重複した要素の数を数える
sample.py
# 日付列に重複しない要素がいくつあるか数える
df['日付'].nunique()
メモ:
実行結果↓ sample.py
# すべての列に対して重複しない要素がいくつあるか数える
df.nunique()
メモ:
実行結果↓ その他
実行結果を貼り付ける元気がなくなってきたので、以下はコードだけ貼り付けていきます。
pathの変換(「\」を「/」に変換)
sample.py
f_path = r'C:\sample\csv\data1.csv'.replace('\\', '/')
メモ:
Windowsでエクスプローラーからファイルのパスをコピってくると\が入ってしまう時に。 \はエスケープ文字の意味があるので、replace()の中では2つ重ねて、後ろの\をエスケープしてやってます。列名の変更
sample.py
df = df.rename(columns={'日付': '年月日'})
メモ:
学習コストを下げるため、オプションのinplace=Trueは使わない方向で統一しています。pd.queryで絞り込み
sample.py
df.query("科目名 == '普通預金'")
メモ:
SQLとは違って、「=」は2つじゃないとだめです。SQLiteにデータ追加
sample.py
import sqlite3
# sample.pyと同じフォルダ内に「data.db」を作り、
# その中に「sample_table」というテーブルを作って
# dfのデータを保存。
dbname = 'data.db'
table_name = 'sample_table'
conn = sqlite3.connect(dbname)
df.to_sql(table_name, conn,
if_exists='append',
index=False)
conn.close()
メモ:
データをきれいにしたら、SQLiteやその他データベースに保存しておくと後で再利用しやすいです。 JupyterやVSCodeだとデータを全画面でざっと見たい時には不便なので、DBBrowser for SQLiteで見たりします。もしくはCSVで吐き出してExcelで見たりとか。SQLiteのデータを取り出し
sample.py
dbname = 'data.db'
table_name = 'sample_table'
sql= f'''
select *
from {table_name}
limit 5
'''
conn = sqlite3.connect(dbname)
df = pd.read_sql(sql, conn)
conn.close()
df
メモ:
pandasのread_sqlでDBにSQLを投げてやります。終わりに
まだまだ本職のプログラマーの人たちと比べると知識浅いので、もっといい書き方あるよ、とか教えてもらえるとありがたいです。
また自分と同じく勉強中の人からも、こんなことしたいけどいいやり方ある?みたいなリクエストいただければ、知ってる範囲で回答したいと思います。
全部自動化して楽したい。
全部自動化して楽したい。