はじめに
機械学習のコンペサイトでは、世界的にはKaggleが有名ですが、その日本版とも呼ばれているSIGNATEというサイトがあります。
経済産業省主催Tellusデータの海岸線抽出コンペで3位に入賞できたので、そのときの話をまとめます。
4人チームで挑みましたが、私が一度Kaggleに見様見真似で参加したくらいの経験がある程度で、他の方はほぼ初めてのビギナーチームです。
コンペ概要:海岸線抽出
衛星データプラットフォーム「Tellus(テルース)」のデータを使ったコンペで今回が第4回になります。
衛星で撮影された海岸のSAR画像から、海岸線を検出するのが今回の課題です。

この画像は主催からお借りしました。詳細はSIGNATEのコンペページをご覧ください。
https://signate.jp/competitions/284
データの特徴
データ概要について、コンペページの情報を引用します。
・LバンドSAR画像
衛星:ALOS2(JAXA)
大きさ:600×600~10000×10000(画像により異なる)
解像度:3m × 3m
HH偏波, 波長:約24cm
海岸数:17
画像数:55枚(学習用)25枚、(評価用)30枚
※偏波とは電波の性質を表す一つの指標で、電界の振動方向の向きを表します。HHは水平偏波を送信し水平偏波で受信します。
・アノテーション(学習用データに対する海岸線の座標情報)
形式:JSON
このとおり解像度は変わらないが画像の大きさがまちまちなので、元画像をクロップして解析した方がいいと考えられます。ほとんどのチームがそうしていたと思います。
また、追記すると
- 32bit tiff画像(けど、情報としてはほとんど16bit(0~65535)で欠損値の一部に65536が入っている)
- 画像の一部がざっくり写ってないなど、欠損値あり
アプローチ
期間中の試行錯誤の末、最終的に次のアルゴリズムで提出しました。
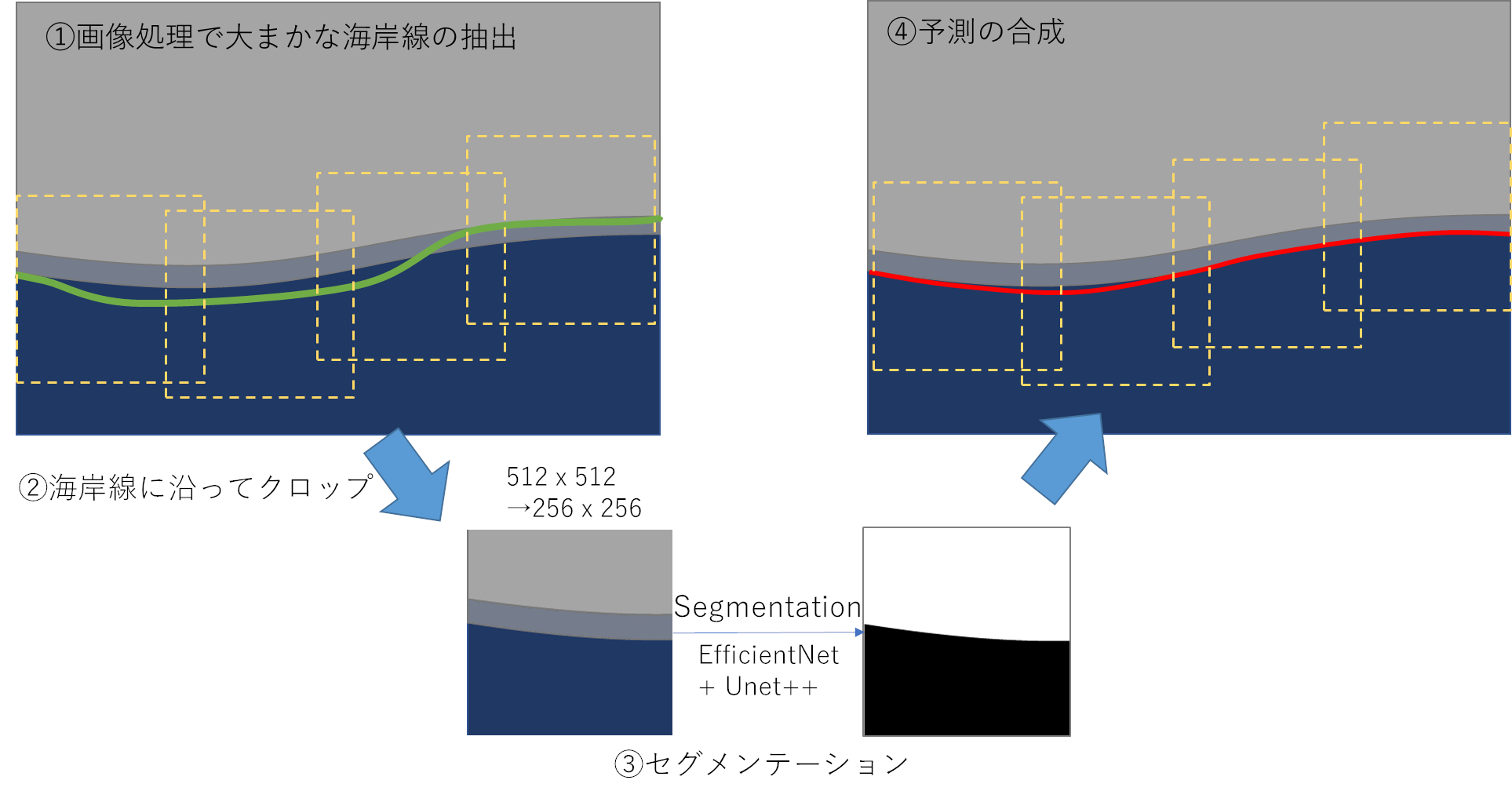
①画像処理で大まかな海岸線の抽出(緑)
- 1: 32bit画像の輝度を特定の範囲で8bitに線形変換
- 2: 画像処理によって大まかな海岸線を抽出
②海岸線に沿ってクロップ(黄)
- 画像処理による海岸線を元に一定の距離(密度高めが良)で512x512にクロップして256x256にダウンスケール
③セグメンテーション
- EfficientNetB5 + Unet++ で陸(1)と海(0)にセグメンテーション
- 移動・回転クロップで水増し
- そのほか水増し:random Flip, salt and pepper, random erase
④予測の合成(赤)
- 1: Flipした入力画像でTTA、平均値を算出
- 2: 二値化したエッジを最終の海岸線として採用
スコア推移
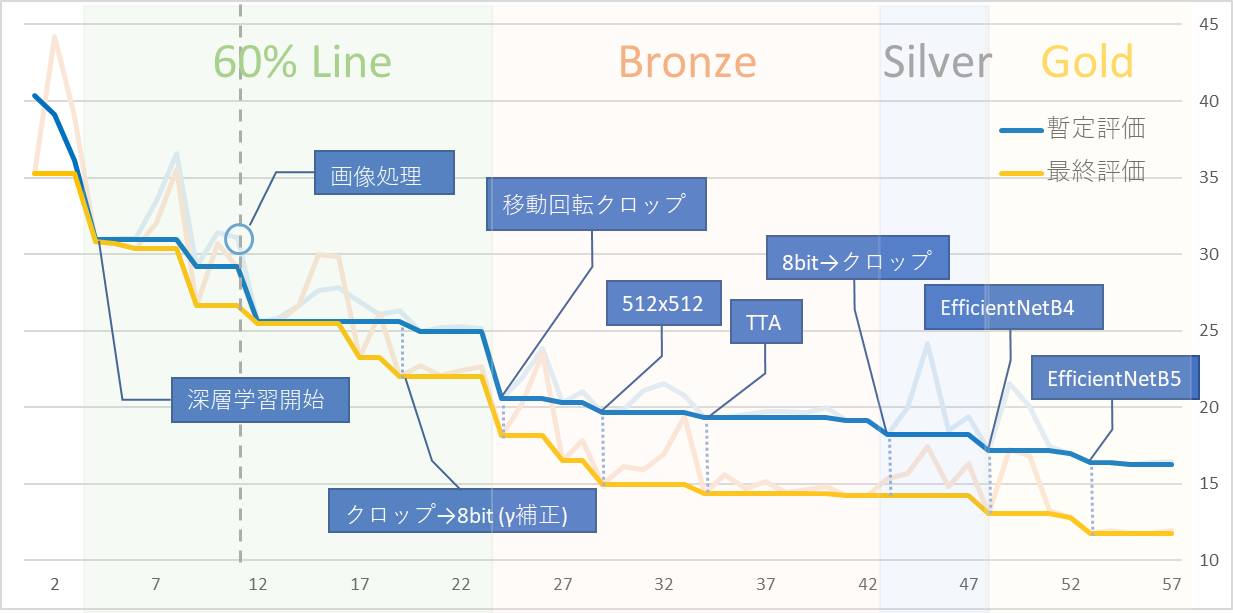
横軸が投稿回数で縦軸がスコアです。
今回の評価指標は正解との誤差なので、小さい方が成績が良いということになります。
暫定評価31pointの画像処理で抽出した海岸線を元に、深層学習で更に寄せていきました。
最終日は暫定評価9位で、入賞するとは微塵も思わず終わりにしました。何かのミスで0点になっているのが怖くて結果発表直後夜中1時くらいにすぐに確認したのですが、見てびっくり。すぐに興奮をチームのチャットに書き込みましたが誰もおらず(当たり前か)気持ち空ぶった感じでその日は床に就きました![]() 笑い
笑い
道のり
モデルを作るごとに出力していた画像が溜まっていたので、せっかくなので改善経過を動画にしてみました。
青い線が画像処理の線、黄色い線が深層学習の線です。
GIFにして更によくわからなくなっていますが、実際の海岸線ははっきり見える陸のエッジよりも海寄りに存在しています。

防波堤があると引き寄せられるように海岸線が出来るそうですが、その形もとれるようになりました。
(ただ離散的な評価なので細かい部分はあまりスコアに響かないとは思いますが)
こんな感じで、はじめから上位に居たわけではなく、じわじわと改善して上り詰めた感じでした。
前処理
32bit の情報をいかに深層学習しやすいようにするかが重要だと考えて進めていました。
あまり陸と海に輝度差のないデータもあったりと、いかに陸と海に差がつくように加工するかが課題でした。
いくつか試しましたが、上手くいきそうだったのが下の二つでした。
①クロップ→8bit (γ補整)
32bit画像をクロップしてから、γ補正で8bit変換。
画像ごとに輝度が違ったので、クロップした領域ごとに補整かけた方がいんじゃないかという考えです。


②8bit→クロップ
全体画像を特定の範囲で8bitに線形変換してからクロップ。
これは画像処理で海岸線抽出する際に使ったものと同じ処理です。


全体的には②の方が綺麗に見えます。輝度が低くて、海と陸の差がほとんどない2枚目のような例では、①の方が陸と海の差がよく出ています。
暫定評価では若干②が勝っていたので、後半は②のみで試行を続け、最終提出も②を採用しました。
ただ、最終評価を見ると①もかなり改善していたので、①も使ってアンサンブルにもっていけたら良かったなぁと反省。
この前処理は画像処理に強いチームメイト(Aさん,Kさん)にやって頂き、あれこれ注文にも答えてもらいました。本当に心強い。
少ない訓練データへの対処
オグメンテーション
- クロップ時の回転と移動
- ごま塩ノイズ
- random erase
- random Flip
今回はジェネレーター内で画像を加工するだけではなく、クロップ時に回転や移動をかけて元々の訓練画像を水増しする方法をとりました。合計で約1万枚くらいにしておきました。多すぎても学習に時間がかかるので丁度いい塩梅にしないといけないです。
過学習の傾向が強くてかなり困ったのですが、正直このAugmentationでどうにかなってたわけではないです。気持ち安定するかなという感じ。val損失値は全くあてにならないと思って、結果悪くてもそのま進めました。
転移学習
はじめは軽いモデルresnet18で試行回数を増やし、最後はEfficientNetに切替えて学習。最後の方は何やってもなかなか改善できなかったのですが、流石、これでようやくGoldまでたどりつきました。
私が確認した解法ではほとんどの人がEfficientNetを使っていました。
振り返って
限られた時間で効率よく試行錯誤を繰り返す
当たり前のことかもしれませんが、1度の試行で変える箇所は1つに絞り、効果をひとつひとつ検証しながら進めました。チームの良いところで、Noアイデアの時間がほとんどなく試行錯誤を繰り返せたのが今回は良かったなあと思います。
書きませんでしたが、クロップ方法を変えてみたり、複数の補整方法で加工した画像を3chに突っ込んだりとか色々やってみましたが、結局はシンプルな方法に落ち着きました。
Seedしよう
コンペ終了後、入賞候補者は事務局の方でスコアの再現性を確認してから入賞が確定するのですが、まさか入賞するとも思っていなかったので全く配慮が足りていませんでした。訓練データのクロップにランダム値を使っていたので、スコアが変わる可能性があり、ちょっとひやりとする…。ランダム値はSeedすると肝に銘じます。
定石の手法
日進月歩で変わるものですが、EfficientNetの転移学習、アンサンブル、TTAなど、機械学習コンペでは定石になっている手法がいくつかあります。上位に入るにはそれは当たり前にできて、プラスの発想と工夫で順位が決まるように思いました。
今回、私はアンサンブルまで出来なかったのが心残りで…。
アンサンブルは複数モデルを作る必要があるので経験とバリエーション豊かな発想が必要だな~と、他の方の解法見て思いました。
他の参加者の解法を見るのは本当に勉強になります。
おわりに
以前Kaggleに参加したときは、初心者の私は上位カーネルでどうにかやろうとしていたんですが、SIGNATEはあまりフォーラムが活発でなかったので一からチームメイトと考えなければなりませんでした。
それが逆に思考停止せず、良い結果につながったように思います。
実務とはまた違った緊張感とスピード感で楽しかったです。非常に良い経験になりました。
まだ入金されてないけど賞金で加湿空気清浄機買いました![]()
追記
宙畑さんで入賞回答をまとめてらっしゃいます。面白いのでこちらもぜひ。
https://sorabatake.jp/18087/