はじめに
「AIを導入しよう」——この号令、社内で一度は聞いたことがあるのではないでしょうか。
2025年、多くの企業がChatGPTやGeminiを試し始めました。経営層がAI戦略を語り始め、PoC(概念実証)が乱立し、社内はどこか浮足立った雰囲気に。でも1年経って振り返ると、「で、結局何が変わったんだっけ?」という問いに明確に答えられる企業は、実はそう多くありません。
2026年、AIは「試す年」から「評価される年」に移っています。求められるのは「AIで何ができるか」ではなく、「AIでいくら儲かったのか、どれだけコストが削減できたのか」。特に、AIを外部サービスとして「使う」だけでなく、自社のアプリやシステムとして内製する企業にとって、検討すべき論点は広く、そして深くなります。
本記事では、企業がAIを内製開発する際に考えるべき論点を9つのドメインに整理し、MECEフレームワークとして提示します。
対象読者
- AI内製化を検討・推進しているマネージャー・意思決定者
- 内製チームの立ち上げやスケールを担うエンジニアリングリーダー
- 「AIをやれ」と言われたが、何から手をつけるか整理したい方
この記事でわかること
- AI内製開発で押さえるべき9つの論点領域(ドメイン)の全体像
- 各ドメインで「何を考え、何を決めるべきか」の構造化された問い
- 生成AIだけでなく、機械学習・数理最適化などAI手法ごとに異なる留意点
- 各ドメインに対応するAWSサービスの補足マッピング
- 今後のシリーズ記事で深掘りする各ドメインの予告と読み進め方
本記事の位置づけ
この記事は、AI内製化で考えるべき論点の「全体地図」です。9つのドメインを一望できることに価値を置いているため、個々のドメインについては概要レベルの記述にとどめています。
各ドメインの具体的な実現方法やツール選定については、今後のシリーズ記事で深掘りしていく予定です。まずは本記事で全体像を押さえていただければと思います。
AIは一枚岩ではない——手法の分類と「内製」の前提整理
フレームワークの話に入る前に、大前提を整理させてください。
「AI」と一口に言っても、種類がまったく違う
「AI導入」と聞くと、いま多くの方が真っ先に思い浮かべるのは生成AI——ChatGPTやClaude、Geminiのような大規模言語モデル(LLM)でしょう。しかし、企業の課題をAIで解決するとき、生成AIが常に最適解とは限りません。
たとえば——
- 配送ルートの最適化 → 生成AIではなく数理最適化が適切
- 製品の需要予測 → 機械学習(回帰・時系列分析)が本領
- 製造ラインの外観検査 → 画像認識AI(CNN等)が主役
- 社内ナレッジの検索・要約 → ここでようやく生成AI(RAG構成)の出番
課題の性質によって、最適なAI手法は異なります。そして手法が異なれば、必要なデータ、基盤、スキル、コスト構造もすべて変わります。この記事では、以下の4つのAI手法を横断的に扱います。
| AI手法 | 代表的ユースケース | 基盤の特徴 |
|---|---|---|
| 生成AI(LLM) | 文書生成、要約、対話、コード支援 | LLM API or 自社ホスティング、GPU、RAG基盤 |
| 機械学習(予測・分類) | 需要予測、異常検知、レコメンド | 特徴量ストア、学習パイプライン、推論エンドポイント |
| 数理最適化 | 配送最適化、シフト最適化、在庫最適化 | ソルバー(Gurobi, CPLEX等)、制約定義、計算基盤 |
| 画像・音声AI | 外観検査、音声認識、OCR | GPU、エッジ推論、ストリーミング基盤 |
この記事でいう「内製」とは
もうひとつ、「内製」の範囲もはっきりさせておきましょう。
この記事でいう内製とは、自社のチームがAIモデルの選定・開発(またはカスタマイズ)・デプロイ・運用をEnd-to-Endで担うことを指します。具体的には——
- 内製の対象: API経由でLLMを組み込んだ自社アプリの開発、自社データで学習したMLモデルの構築・運用、社内向けAIプラットフォームの整備
- この記事の対象外: ChatGPTやMicrosoft Copilotをそのまま利用するだけのケース(これは「AI活用」であって「AI内製」ではない)
SaaSを「使う」のと、自分たちで「作る」のでは、考えるべきことの幅がまるで違います。内製は自由度が高い分、戦略・データ・基盤・プロセス・人材・ガバナンス・コストのすべてに自ら責任を持つことになります。
フレームワーク全体像——9つのドメイン
本記事で提示するフレームワークは、フロー型の6ドメインと横断型の3ドメインで構成されます。
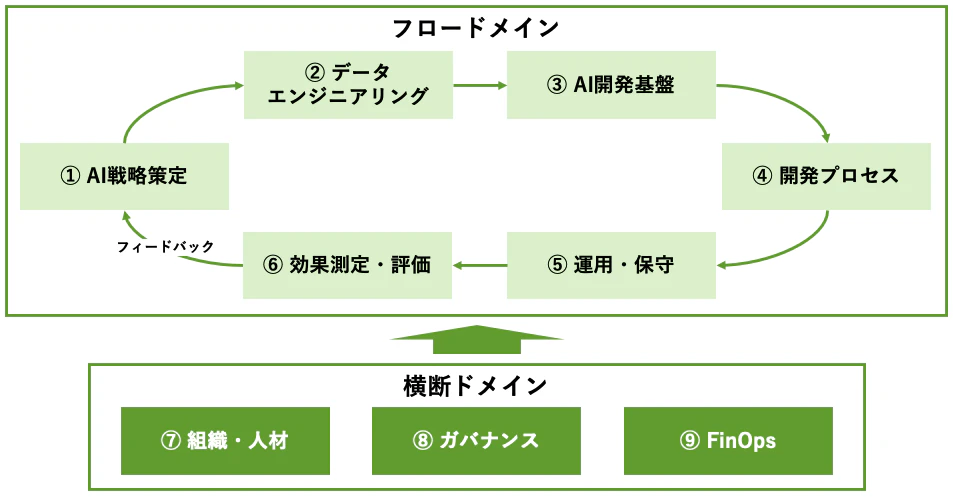
フロードメインは「左から右へ」の流れです。 AI戦略を立て(①)、データ基盤を整え(②)、開発環境を構築し(③)、実際に開発・デプロイし(④)、本番運用を回し(⑤)、効果を測定する(⑥)。そして⑥の結果が①にフィードバックされ、サイクルが回ります。
横断ドメインは、フロー全体に常に関与します。 組織・人材(⑦)はどのフェーズでも必要ですし、ガバナンス(⑧)は戦略策定から運用まで一貫して効かせるべきもの。FinOps(⑨)も、技術選定の段階からコスト意識を持たなければ、気づいたときには「AI貧乏」になりかねません。
以降、各ドメインを順に見ていきましょう。
ドメイン① AI戦略策定——「何を、なぜ、AIで解くのか」
最初の問い: そもそもAIで解くべき課題か?
AI内製化を始める前に、立ち止まって考えたいことがあります。「その課題、本当にAIで解くべきですか?」
「競合がやっているから」「経営層に言われたから」——動機がこれだけだと、高確率でPoC止まりになります。Gartnerは「生成AIプロジェクトの30%がPoC後に放棄される」と予測していますし、MIT NANDA initiativeの2025年レポートでは「企業の生成AIパイロットの95%が、測定可能な損益(P&L)へのインパクトを示せていない」という厳しいデータもあります。
PoC止まりの主因は、実は技術ではありません。ビジネスケースの不在です。「AIで何を解決し、それがいくらの価値を生むのか」が定義されていなければ、PoCの「成功」を判断する基準すらない。そのまま本番に進む意思決定ができず、宙ぶらりんになるのは当然です。
AI手法のフィット判断
課題が明確になったら、次はどのAI手法が適切かの判断です。ここで「AIといえば生成AI」と短絡的に考えると、ミスマッチが起きます。
考え方はシンプルです。
- 「答えを生成したい」 → 生成AI(LLM)
- 「未来を予測したい」 → 機械学習(回帰・分類)
- 「最適な組み合わせを見つけたい」 → 数理最適化
- 「画像や音声を認識したい」 → 画像・音声AI
たとえば「シフトの最適化」に生成AIを使おうとする企業がありますが、これは数理最適化の領域です。生成AIに聞いても「それっぽい答え」は返ってきますが、制約条件(労働基準法、スキル要件、公平性)を厳密に満たす解は出せません。課題の性質とAI手法のフィットを見極めることが、戦略策定の最初の仕事です。
Buy or Build——なぜ「内製」を選ぶのか
AI手法が決まったら、次は「内製するか、外部サービスを使うか」の判断です。
内製を選ぶべきケースは、大きく3つあります。
- 差別化の源泉: AIそのものが競争優位の核になる場合。自社固有のデータ×独自モデルでしか出せない価値がある
- データの機密性: 社外に出せないデータを扱う場合。金融、医療、防衛関連など
- 長期的なケイパビリティ蓄積: AIの知見を組織に蓄積し、継続的に進化させたい場合
逆に、メールの要約や議事録の自動生成程度であれば、既存SaaSで十分なことが多い。内製のコスト・人材負担を考えれば、「作らなくていいものは作らない」も立派な戦略です。
ドメイン② データエンジニアリング——「AIの燃料」を自前で調達する覚悟
内製で最も過小評価される領域
AI内製化で最もリソースを食うのはどこか——多くの人は「モデル開発」と答えますが、実はデータエンジニアリングです。
外部APIを叩くだけなら、データはプロンプトに載せるだけで済みます。しかし内製となると話が変わります。学習データの収集、蓄積、前処理、品質管理、そしてそれらを回し続けるパイプラインの構築と維持——これらすべてを自社で担う必要があります。
よく言われる「AIはデータが8割」は、内製では文字通りの意味を持ちます。
AI手法ごとに「必要なデータ」が違う
ここでもAI手法による差異が大きく出ます。
- 生成AI: RAG構成のための社内ドキュメント整備、ファインチューニング用のQ&Aデータセット。構造化されていないデータを扱うことが多い
- 機械学習: 構造化データ(売上、センサー値、ユーザー行動ログ等)の収集と特徴量設計。過去データの蓄積期間が精度に直結する
- 数理最適化: 制約条件や目的関数に必要なパラメータ(コスト、容量、時間枠等)の定義。データ量よりもデータの正確性が重要
- 画像・音声AI: ラベル付きの大量画像/音声データ。アノテーション(ラベル付け作業)のコストが想像以上にかかる
「うちにはデータがある」と言う企業は多いですが、「AIに使えるデータがある」かどうかは別の話です。欠損だらけ、フォーマットがバラバラ、そもそもラベルがない——内製を始めて最初にぶつかる壁は、たいていここです。
データ品質管理——「ゴミを入れればゴミが出る」
内製ではデータ品質の劣化がそのまま本番モデルの精度低下に直結します。外部サービスなら「品質が悪ければベンダーに文句を言う」で済みますが、内製では自分たちの問題です。
最低限押さえるべきポイントは3つ。
- バイアスの検出と是正: 学習データに偏りがないか。採用AIで特定の属性が不利になる、といった問題は社会的にも大きなリスク
- データリネージの追跡: 「このモデルはどのデータで学習されたか」を後から追跡できる仕組み。障害時の原因特定やコンプライアンス対応に必須
- PIIの除去: 個人情報(Personally Identifiable Information)が学習データに混入していないか。特に生成AI×社内データの組み合わせでは要注意
ドメイン③ AI開発基盤——「何で作るか」はAI手法で根本的に変わる
生成AIとMLで「基盤」の意味が違う
「AI開発基盤を整えよう」と言ったとき、その中身はAI手法によってまったく異なります。同じ「GPU」という言葉ひとつとっても、生成AIの推論に使うのか、画像認識モデルの学習に使うのかで、必要なスペックもコスト構造も変わります。
ざっくり整理するとこうなります。
| 基盤要素 | 生成AI(LLM) | 機械学習 | 数理最適化 |
|---|---|---|---|
| 計算資源 | GPU(推論 or ファインチューニング)。API利用なら不要 | GPU/CPU(学習時)、CPU(推論時) | CPU中心、大規模問題ではHPC |
| 主要ツール | LLMホスティング基盤、RAGフレームワーク | 学習パイプライン、特徴量ストア | ソルバー(Gurobi, CPLEX等) |
| ストレージ | ベクトルDB、ドキュメントストア | データレイク、データウェアハウス | パラメータDB |
| 運用の重心 | プロンプト管理、ガードレール | モデルバージョニング、再学習 | 制約条件の更新、解の検証 |
内製チームが最初にやりがちなミスは、「全部入り」の基盤を作ろうとすることです。まず自社のAI施策の中心がどの手法にあるかを見極め、そこにフォーカスした基盤を整備する。他の手法が必要になったら段階的に拡張する——このアプローチが現実的です。
クラウド基盤の選定: マネージドか、セルフマネージドか
内製といっても、インフラまで全て自前で構築する必要はありません。むしろ「自分たちが価値を出すべきレイヤーはどこか」を見極めることが重要です。
- マネージドサービス優先: Amazon BedrockやAmazon SageMaker AIのようなマネージドサービスを使えば、インフラ構築の負担を大幅に減らせます。内製チームのリソースを「モデル開発」や「業務への組み込み」に集中させたい場合に有効
- セルフマネージド: Amazon EKS上にKubeflowやMLflowを構築するパターン。自由度は高いが、運用負荷も高い。マルチクラウドやオンプレとの併用が必要な場合に選択肢になる
スタートアップフェーズではマネージドから始め、要件が複雑化してきたらセルフマネージドに移行する段階的アプローチが多くの組織にフィットします。
開発環境の標準化——「動いたけど再現できない」を防ぐ
内製チームが複数人になると、「Aさんの環境では動くがBさんの環境では動かない」問題が必ず発生します。これを放置すると、チームのスケールに伴って生産性が劇的に下がります。
標準化すべき最低限の要素は以下の通りです。
- ノートブック環境: JupyterLab / SageMaker Studio等を統一し、ライブラリのバージョンをコンテナで固定
- 実験管理: MLflow等で実験のパラメータ・結果を一元的にトラッキング。「あのときの精度が良かったモデル、どの設定だっけ?」を撲滅する
- モデルレジストリ: 学習済みモデルをバージョン管理し、「いま本番で動いているモデルはどれか」を常に追跡できる状態にする
ベンダーロックインの管理
クラウドのマネージドサービスは便利ですが、依存度が上がるほど乗り換えコストが増大します。完全な中立は現実的ではないにせよ、以下の点は意識しておくと良いでしょう。
- データフォーマット: Apache Icebergのようなオープンフォーマットを採用し、データそのものの可搬性を確保する
- モデル: ONNX等の標準フォーマットでエクスポート可能にしておく
- マルチモデル対応: 特に生成AIでは、特定のLLMに依存しすぎない設計(Amazon Bedrockは複数のモデルプロバイダーに対応しているため、この点では有利)
ドメイン④ 開発プロセス——「実験」と「本番」をつなぐ仕組み
ノートブックで動いたのに本番で動かない問題
データサイエンティストがJupyter Notebookで「精度95%出ました!」と報告する。でもそのモデルを本番環境に載せようとすると、デプロイできない、再現できない、スケールしない——内製チームの多くが経験するこのギャップは、開発プロセスの不在が原因です。
従来のソフトウェア開発にはCI/CD(継続的インテグレーション/継続的デリバリー)という確立されたプラクティスがあります。AIの内製開発でも同様のプロセスが必要ですが、AI固有の変数——データとモデル——が加わるため、より複雑になります。
ここで登場するのがMLOps(Machine Learning Operations)。DevOpsの概念を機械学習に拡張したもので、「ソースコードだけでなく、データと学習済みモデルもバージョン管理・自動化の対象にする」という考え方です。
MLOpsとLLMOps——手法で「Ops」が変わる
ここでもAI手法による違いが出ます。
機械学習のMLOpsが管理するのは、データパイプライン、特徴量、学習ジョブ、モデルバージョン、推論エンドポイントの一連の流れです。比較的確立された領域で、MLflowやKubeflow等のツールエコシステムも成熟しています。
一方、生成AI(LLM)のLLMOpsはまだ発展途上ですが、従来のMLOpsとは異なる固有の論点があります。プロンプトのバージョン管理、ハルシネーションの監視、トークンコストの追跡、ガードレール(出力制御)の設計などです。LLMではモデル自体を学習するケースよりも、「プロンプトエンジニアリング + RAG + ファインチューニング」の組み合わせでカスタマイズするケースが多く、管理対象がMLOpsとは質的に異なります。
さらに2026年現在、AIエージェントの運用(AgentOps)という新しい領域も出てきています。エージェントが自律的に判断・行動するシステムでは、状態管理、意思決定の監査、安全制御といった従来のOpsにはなかった観点が必要になります。
最低限やるべき3つのこと
開発プロセスの成熟度は組織によって差がありますが、内製を始めるなら最低限以下の3つは初日から押さえておくべきです。
1. すべてをバージョン管理する
コードだけでなく、データセット、モデル、パラメータ設定、プロンプトテンプレート。「あのとき精度が良かったモデル、どうやって作ったっけ?」が再現できない状態は、内製チームにとって致命的です。
2. テストを自動化する
MLモデルなら精度テスト・公平性テスト・回帰テスト。LLMなら出力品質評価・ハルシネーション検出・レッドチームテスト。手動テストだけでは、モデル更新のたびにボトルネックになります。
3. 本番監視を組み込む
デプロイして終わりではなく、本番でのパフォーマンスを継続的にモニタリングする仕組みを最初から設計に含める。これがないと、ドメイン⑤(運用・保守)で詰みます。
ドメイン⑤ 運用・保守——AIシステムは「デプロイしてからが本番」
「二重構造」の運用を覚悟する
AIシステムの運用には、通常のシステム運用にはない厄介な特性があります。それは「システム」と「モデル」の二重構造です。
通常のWebアプリなら、サーバーが落ちていないか、レスポンスタイムは正常か、エラーレートは閾値内か——を監視すれば概ね事足ります。しかしAIシステムでは、これに加えて「モデルは正しい答えを出し続けているか」を監視する必要があります。
サーバーは元気に稼働している。レスポンスタイムも正常。でもモデルの推論精度が静かに劣化している——この状態は、従来のインフラ監視だけでは検知できません。
モデルドリフト——静かに忍び寄る精度劣化
AIモデルの精度が時間とともに低下する現象をモデルドリフトと呼びます。原因は大きく2つ。
- データドリフト: 本番環境に入ってくるデータの傾向が、学習時のデータと変わってしまう。たとえば、コロナ禍で消費者の購買行動が激変し、需要予測モデルが役に立たなくなった、というのが典型例です
- コンセプトドリフト: 入力と正解の関係性そのものが変わる。法改正で「正しい」判断基準が変わった場合などが該当します
内製チームが設計すべきは、ドリフトの検知→判断→再学習→再デプロイのサイクルです。「精度がX%を下回ったら自動で再学習をトリガーする」といった仕組みを事前に組んでおくことで、劣化に気づかないまま数ヶ月放置するリスクを防げます。
生成AI固有の運用課題
生成AIの運用では、従来のMLモデルとは異なる課題が出てきます。
- ハルシネーション: もっともらしい嘘を生成するリスク。本番で顧客に誤情報を提供してしまうと、信用問題に発展します
- プロンプトインジェクション: 悪意あるユーザーが入力を操作し、システムの意図しない動作を引き起こす攻撃
- モデル更新への追従: LLMプロバイダーがモデルをアップデートすると、同じプロンプトでも出力が変わることがある。API依存の内製アプリではこの影響を受けやすい
これらに対しては、ガードレール(入出力フィルタリング)の設置、モデルバージョンの固定、出力品質の継続監視といった対策が必要です。
モデルのライフサイクル管理
忘れられがちですが、モデルの「引退」も運用の一部です。古いモデルをいつ廃止するか、新しいモデルへの移行をどう進めるか、モデルカタログをどう維持するか。内製モデルが増えてくると、この管理が意外と重くなります。
ドメイン⑥ 効果測定・評価——「で、結局AIで何が変わったの?」に答える
経営層が聞きたいのは「F1スコア」ではない
AI内製チームが陥りがちなのが、技術指標だけで成果を語ってしまうことです。
「モデルの精度が92%です」「レスポンスタイムが200msに改善しました」——技術的には正しい。でも経営層が聞きたいのは、「それでいくら儲かったのか」「どれだけコストが減ったのか」です。
2026年、AIは「試す年」から「評価される年」に移行しています。ある調査では、導入企業の約60%が効果測定を実施しておらず、成果を定量的に示せないまま「なんとなく使っている」状態にとどまっています。これでは次の投資判断を引き出せません。
技術KPIとビジネスKPIの接続
効果測定で重要なのは、技術KPIとビジネスKPIを事前に紐づけておくことです。事後に「このAIのビジネス効果は?」と聞かれてから考え始めるのでは遅い。
考え方の例を示します。
| AI施策 | 技術KPI | ビジネスKPI | 計測方法 |
|---|---|---|---|
| 問い合わせ対応AI | 正答率、解決率 | 対応コスト削減額、顧客満足度 | A/Bテスト(AI対応 vs. 人間対応) |
| 需要予測モデル | MAPE(予測誤差率) | 在庫回転率、廃棄ロス削減額 | 導入前後の比較 |
| 外観検査AI | 検出率、誤検知率 | 人件費削減額、不良品流出率 | 並行運用での比較 |
ポイントは、AI施策の企画段階(ドメイン①)で、この接続を設計しておくことです。効果測定は最後のドメインですが、設計は最初に行うべきもの。ここが抜けていると、PoC後に「効果があったのか分からない」問題に直面します。
投資対効果(ROI)の伝え方
経営層への報告では、「AIの精度が上がりました」ではなく、以下のようなフレームで伝えると通りやすくなります。
- Before/After: 「AI導入前は月間○○時間かかっていた業務が、導入後は○○時間に削減」
- コスト対効果: 「AI基盤の運用コスト月額○○万円に対し、削減効果は月額○○万円。投資回収期間は○ヶ月」
- 定性的効果の補足: 数値化しにくい効果(従業員の満足度向上、意思決定のスピードアップ等)も併記する
改善サイクルへの接続
効果測定の結果は、ドメイン①(AI戦略策定)にフィードバックされるべきです。
「このAI施策は期待通りの成果を出したのか?」「投資を継続・拡大すべきか?」「別の課題にリソースを振り向けるべきか?」——この問いに答えることで、9ドメインのフレームワークが一巡し、次のサイクルが始まります。
効果が出ていないなら、やめる判断も含めて評価です。 AIに限らず「始めたけどやめられない」プロジェクトは組織のリソースを静かに蝕みます。効果測定は、撤退判断のための材料でもあるのです。
ドメイン⑦ 組織・人材——「誰がAIを作り、誰がAIを育てるか」
内製は「ツール導入」ではなく「組織づくり」
AIの内製化を決めたとき、真っ先に検討されるのは「どのクラウドを使うか」「どのフレームワークを採用するか」といった技術選定です。しかし、多くの失敗事例が示すように、内製化のボトルネックは技術ではなく組織にあります。
データサイエンティストを1人採用しても、その人が作ったモデルを本番に載せるMLエンジニアがいなければ動かない。MLエンジニアがいても、学習データを整備するデータエンジニアがいなければ精度が出ない。全員いても、事業部門との橋渡しをする人がいなければ「技術的には動くが誰も使わないシステム」が出来上がる——内製は、個人の能力ではなくチームとしてのケイパビリティで成否が決まります。
AI CoE(Center of Excellence)の設計
内製チームの立ち上げ方として、多くの企業が採用しているのがAI CoE(Center of Excellence)モデルです。
初期段階では中央集権型——専門家を集中配置し、ガバナンスの基盤を固め、標準ツール・プロセスを整備する。成熟度が上がってきたらアドバイザリー型に移行し、各事業部門がAI開発を自走できるよう支援する。この段階的な移行が、スケールのカギです。
注意すべきは、CoEの「E」を「Experimentation(実験)」ではなく「Excellence(卓越)」で保つこと。PoCを回すだけの組織になってしまうと、CoEは「実験工房」に成り下がります。ユースケースのバックログを管理し、本番投入と効果測定までを一気通貫で担う設計が必要です。
内製に必要なロール
内製チームに必要なロールは、AI手法や組織の規模によって変わりますが、典型的には以下のような構成になります。
- データエンジニア: データパイプラインの構築・維持。内製の「縁の下の力持ち」
- データサイエンティスト / MLエンジニア: モデルの開発・学習・評価。生成AI中心ならプロンプトエンジニアリングの専門性も
- プラットフォームエンジニア: 開発基盤(ドメイン③)の構築・運用。MLOps/LLMOpsパイプラインの整備
- プロダクトマネージャー / ビジネストランスレーター: 事業課題とAI施策の橋渡し。「この課題にAIを使うべきか」の判断を技術チームと事業部門の両方の言葉でできる人材
特に最後の「橋渡し人材」の不在が、PoC止まりの大きな要因として指摘されています。技術がわかる人と、ビジネスがわかる人の間を翻訳できる存在が、内製チームの成功率を大きく左右します。
人材育成: 全員をデータサイエンティストにする必要はない
AI人材の不足は事実ですが、「全員をデータサイエンティストにしなければ」と考える必要はありません。重要なのは、役割に応じたリテラシーの階層設計です。
- 経営層: AIの可能性と限界を理解し、投資判断ができるレベル
- 事業部門リーダー: 自部門の課題にAIが適用可能かを見極められるレベル
- AI専門チーム: モデル開発・運用の実務を担えるレベル
- 全社員: AIツールを安全に利用できるリテラシー
ドメイン⑧ ガバナンス・コンプライアンス——「作る自由」には「責任」がついてくる
内製企業は「開発者」かつ「提供者」かつ「利用者」
AIを内製する企業が見落としがちな点があります。外部サービスを利用するだけなら「AI利用者」としての責任だけですが、内製する場合は「AI開発者」「AI提供者」「AI利用者」の3つの立場を同時に担うことになります。
これは、AI事業者ガイドライン(v1.1)の構造に照らすと、すべての主体に求められる指針——「人間中心」「安全性」「公平性」「透明性」「アカウンタビリティ」等——に自社で対応する必要があることを意味します。外注なら「ベンダーの責任」で済ませられた部分も、内製ではすべて自社の問題です。
規制動向: 2026年は「ルールが固まる年」
2025年は日本のAI法(人工知能関連技術の研究開発及び活用の推進に関する法律)が施行され、AI事業者ガイドラインもv1.1に更新されるなど、国内のAIガバナンスの枠組みが大きく動きました。
グローバルに目を向けると、EU AI Act(欧州AI規制法)がさらに重要です。2026年8月に「高リスク」に該当するAIシステムへの規制が本格施行されます。EU域内に拠点がない日本企業であっても、EU域内でAIシステムを上市・利用する場合には適用される可能性があり、グローバル展開を視野に入れる企業は対応を始める必要があります。
「うちは国内向けだから関係ない」と思うかもしれません。しかしEU AI Actの影響は、GDPRがそうだったように、各国の規制に波及していく可能性が高い。今から備えておいて損はありません。
内製で特に押さえるべきガバナンス要素
- バイアス監査: 自社モデルが特定の属性に対して不公平な結果を出していないか。採用AI、与信AI、医療AIなどは特にリスクが高い
- 説明可能性(XAI): モデルの判断根拠を説明できるか。「AIがそう言ったから」では、顧客にも監査人にも説明責任を果たせない
- セキュリティ: プロンプトインジェクション対策、学習データの汚染防止、モデルの窃取防止。内製だからこそ、セキュリティ設計を自分たちで行う必要がある
- インシデント対応計画: AIが問題を起こしたときの対応フロー。誰が判断し、誰が対外コミュニケーションを行い、どの時点でモデルを停止するかを事前に定義しておく
ドメイン⑨ FinOps——「AI貧乏」にならないために
AIコストは「使ったぶんだけ」では済まない
「クラウドだから使ったぶんだけ払えばいい」——AI以前のクラウドコストならそれでも通用しましたが、AIワークロードのコスト構造はまるで別物です。
FinOps Foundationの2026年レポートによると、回答者の98%がAIコストを管理対象に含めており、2024年の31%から2年で急拡大しています。それだけAIコストが「予測しづらく、膨らみやすい」ことを多くの企業が実感しているということです。
AIコストが厄介な理由は、変動性と不透明性にあります。従来のクラウドコスト(VM、ストレージ)は比較的予測しやすいですが、AIワークロードは推論リクエスト数、トークン長、モデル選択、学習ジョブの回数などで大きく変動し、月次で30-40%のスイングが起きることもあります。
AI手法ごとのコストドライバー
ここでもAI手法による違いが顕著です。
| AI手法 | 主なコストドライバー | 特徴 |
|---|---|---|
| 生成AI(LLM) | トークン課金、GPU推論コスト、RAG基盤のストレージ | 利用量に比例して増大。プロンプト設計の巧拙がコストに直結 |
| 機械学習 | 学習ジョブのGPU/CPU時間、推論エンドポイントの常時稼働 | 学習コストは一時的だが、推論コストは継続的 |
| 数理最適化 | ソルバーライセンス、計算時間 | 問題規模に応じて計算時間が指数的に増加しうる |
生成AIが特に要注意です。開発時に「月額数万円」で動いていたものが、全社展開した途端にトークン消費量が爆発し、「月額数百万円」に化ける——いわゆる「AI貧乏」のパターンです。
コスト最適化の打ち手
いくつか実践的な打ち手を挙げます。
モデルルーティング: すべてのリクエストを最大・最高性能のモデルに投げるのではなく、タスクの複雑さに応じてモデルを使い分ける。簡単な質問は小さなモデルへ、複雑な分析は大きなモデルへ。これだけでコストが大幅に変わります。
推論キャッシュ: 同じ質問に対する回答をキャッシュし、再計算を避ける。FAQ系のユースケースでは20-60%のコスト削減効果が見込めます。
スポットインスタンスの活用: 学習ジョブにはスポット/インタラプティブルインスタンスを使い、70-90%のコスト削減を狙う。チェックポイント機能との併用が前提です。
GPU利用率の最適化: GPUは高価なリソースですが、実際の利用率が15-30%程度にとどまっているケースが少なくありません。オートスケーリングやスケジューリングの見直しで無駄を削減できます。
FinOpsは「設計段階」から始める
FinOpsのよくある失敗は、コストが膨らんでから慌てて始めることです。本来、FinOpsはドメイン③(AI開発基盤)やドメイン④(開発プロセス)の設計段階で組み込むべきものです。
どのモデルを使うか、どのGPUインスタンスを選ぶか、推論エンドポイントを常時稼働させるか——これらはすべて技術的判断であると同時に、コスト判断でもあります。技術チームとファイナンスチームが共通の言語でコストを語れる状態を作ること。それがAI時代のFinOpsの本質です。
まとめ——9ドメインのセルフチェックリスト
ここまで、AI内製化で押さえるべき9つのドメインを駆け足で見てきました。
最後に、意思決定者が自社の現状をざっくりチェックするための問いを並べます。すべてに「Yes」と言える企業はほぼ存在しないので、安心してください。「Noが多い領域=次に手をつけるべき領域」として使っていただくためのリストです。
| # | ドメイン | セルフチェックの問い |
|---|---|---|
| ① | AI戦略策定 |
|
| ② | データエンジ ニアリング |
|
| ③ | AI開発基盤 |
|
| ④ | 開発プロセス |
|
| ⑤ | 運用・保守 |
|
| ⑥ | 効果測定・評価 |
|
| ⑦ | 組織・人材 |
|
| ⑧ | ガバナンス |
|
| ⑨ | FinOps |
|
大事なのは、全ドメインを完璧にしてから始める必要はないということです。まずドメイン①(戦略)で「何を、なぜ、AIで解くのか」を定め、そこから段階的に成熟度を上げていくアプローチが現実的です。
今後について
本記事では全体像の俯瞰に主眼を置いたため、各ドメインの「では具体的にどうするか」には踏み込みを控えています。
今後、各ドメインを深掘りするシリーズ記事を展開予定です。クラウドサービスの活用パターンや実務で使えるツール・フレームワークなど、より実践的な内容に踏み込んでいきますので、ぜひあわせてご覧ください。
参考文献
- The GenAI Divide: State of AI in Business 2025 — MIT NANDA Initiative(2025年7月)
- Gartner Predicts 30% of Generative AI Projects Will Be Abandoned After Proof of Concept By End of 2025(2024年7月)
- AI事業者ガイドライン(第1.1版) — 総務省・経済産業省(2025年3月)
- 令和7年版 情報通信白書 — 総務省(2025年)
- State of FinOps 2026 Report — FinOps Foundation
- FinOps for AI Overview — FinOps Foundation
- 生成AIに関する実態調査 2025春 5カ国比較 — PwC Japanグループ
- Establishing an AI/ML Center of Excellence — AWS
- Establish an AI Center of Excellence — Microsoft Cloud Adoption Framework