ScalyrブログのMicroservices Logging Best Practicesの抄訳に、いくつか補足を加えたものです。
一意のIDをリクエストと関連付ける
複数のサービスの呼び出し関係をトレースできるように一意のIDをリクエストに含めます。
ZalandoのRESTful APIガイドラインをみると、X-Flow-IDというHTTPリクエストヘッダを付けるように規約化されています。
Microsoftにも「マイクロサービスの設計: ログ記録と監視」というガイドがあります。
一意のIDをレスポンスに含める
レスポンスのペイロードにも一意のIDを持っておけば、問題が発生したときに、カスタマからの連絡にも即座に対応できるようになります。
Spring Cloud Sleuthは、それらのコンセプトと実装も提供しています。
https://github.com/spring-cloud/spring-cloud-sleuth
ログを集中管理された場所に送る
すでにログに役に立つあらゆる情報が書かれてたとしても、集中管理された場所にログを送ることは大事なことです。
クラウドやコンテナ、そのハイブリッド環境の場合は、特に何の知らせもなくサーバが終了してしまうことがあるので、ログの集中管理は必須といってよいでしょう。
構造化ログを使う
ログのフォーマットをサービスごとに統一するのはほぼ不可能でしょう。かといって何も決めなければ、フィールドのデリミタに、カンマを使ったり、空白を使ったり、パイプ文字を使ったりとまちまちになってしまいます。
JSONのような標準的に使われる構造もったデータ形式で書いておけば、1つのログイベントにより多くのセマンティクスをもたせることができます。
Javaの場合、slf4jとlogbackを使っている場合でも、設定で構造化ログを出力することは可能です。
https://gquintana.github.io/2017/12/01/Structured-logging-with-SL-FJ-and-Logback.html
残念ながらログメッセージも、JSONにするにはアプリケーション側で、JSON化するより無さそうです…
すべてのリクエストにコンテキストをつける
ログには問題をトレースするためのコンテキストをできるだけ追加するとよいですが、一部の情報は冗長なコードを生みがちなので、ロギングフレームワークで自動的に加えられるようにしましょう。
その一部とは、以下のようなものです。
- 日付と時刻
- エラーのスタックトレース
- サービス名
- エラーが発生した関数、クラス、ファイル名
- 外部サービスとのやりとりの名前
- サーバとクライアントのIPアドレス
- ユーザエージェント
- HTTPステータスコード
ローカルストレージにログを書く
「ログを集中管理サーバに送る」からといって、アプリケーションのログ書き込み要求で即座に直接HTTPなどで送信してしまうと、ネットワークのアウトバウンドを圧迫し、他のマイクロサービス間の通信に影響を与えてしまうかもしれません。
AWSでは次のようにすることもできると、元記事のScalyrブログでは言っています。
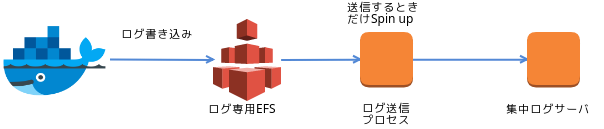
何にせよ、ログを集約してフィルタリングして送信する責務は、別のプロセスやサービスにするべき、ということです。
従来のロギングフレームワークは、アプリケーションからはカテゴリをもとにLoggerを作って何のログかを指定し、ログの設定でそのカテゴリにアペンダを割り当てて、フォーマットを決めたりファイルを分けたりしていましたが、この責務がMicroservicesでは集中ログサーバにいくことになります。