1. はじめに
本記事は【Python/AWS】の第5回として前回に引き続き、
AWSのサービスを利用した一連のデータ分析の続きとなります。
▼前回の記事はこちら▼
私自身、AWSのサービスを触るのは初めてだったので、
細かい説明など不足する点はあるかと思いますが、
大まかな流れをこちらで解説していきたいと思います。
本分析の全体像は以下のようになります。

全体の分析目的は以前の分析から継続/発展して、
「Splatoon3」におけるコンテンツのユーザー満足度調査 です。
収集したデータから項目ごとに感情分析を行い、
ポジティブ/ネガティブの値を可視化することが最終目的です。
▼以前の記事はこちら▼
1-1. 本記事の概要と目標
今回のテーマは 「S3のデータをQuickSightで可視化」 で、
全5回の分析フローの最終回となります。
数日分のCSVデータがS3に格納されているので、
Athenaで一度クエリしてから可視化を行います。
今回作成するパートのイメージはこのような形です。
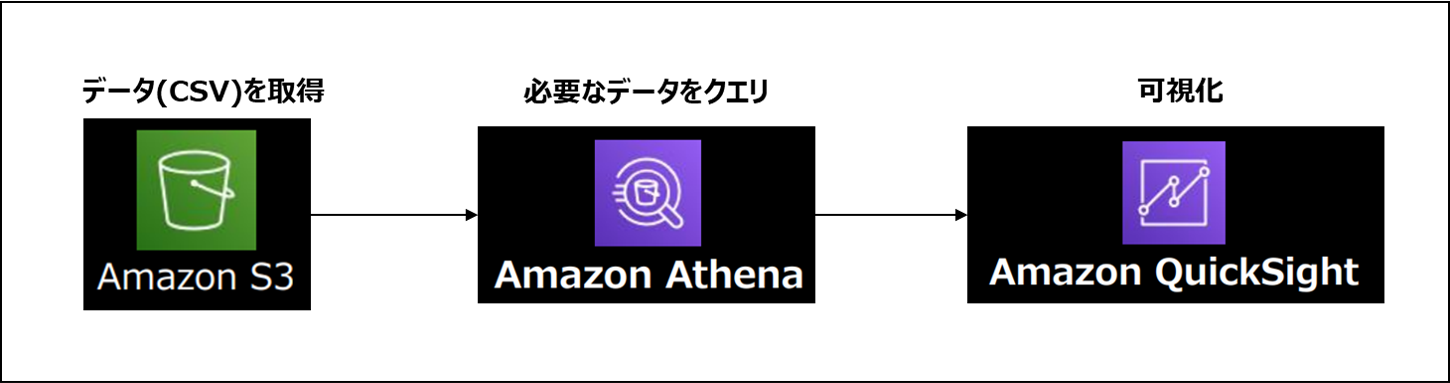
使用するサービスとそれぞれの役割は以下の通りです。
Amazon S3: 様々な形式のデータを保管できるストレージ
Amazon Athena: 標準的なSQLを使用してS3内のデータを直接分析できるクエリサービス
Amazon QuickSight: 様々なソースのデータを結合できるクラウド規模のBIサービス
なお本記事ではAWSの登録方法や初期設定については取り上げていません。
必要に応じて以下の記事を参考にして下さい。
1-2. 全体の流れ
本記事の作業の流れとしては以下の通りです。
1.AthenaからS3のcsvデータをクエリ
2.作成したテーブルを元にQuicksightで可視化
2. Amazon Athenaについて
2-1. Athenaの概要
Amazon Athenaは、SQLを使用してS3内のデータを
直接分析することを容易にするクエリサービスです。
今回は可視化に使うcsvが複数存在しているため、
可視化用のテーブルを作成するために使用しています。
▼AWS Glueの公式紹介▼
2-2. 他の分析ツールサービス
データ分析のツールとしては他にも存在します。
Athenaは最も手軽に使用できるツールで、
データ規模や運用方法による使い分けが推奨されています。

以下リンク先の資料より引用
【初級】AWS でのデータ収集、分析、そして機械学習
3. QuickSightについて
3-1. BIツール

BIは "ビジネスインテリジェンス" の略であり、
企業が持つデータをグラフなどで可視化することで
業務や経営の判断に役立てるためのツールです。
近年は企業が持つビックデータの活用として、
BIツールを利用した経営判断の重要性が高まっています。
▼BIツールの参考ページ▼
3-2. QuickSightの特徴
QuickSightではデータを高速表示、集計するために
内部でSPICEというインメモリDBを採用しています。
そのため様々なデータの可視化方法を
その場で試しながらデータを確認することができます。
またQuickSight内で機械学習による分析も可能です。
例えば使用しているデータが時系列データであれば、
その先の変化を予測する機能も搭載しています。
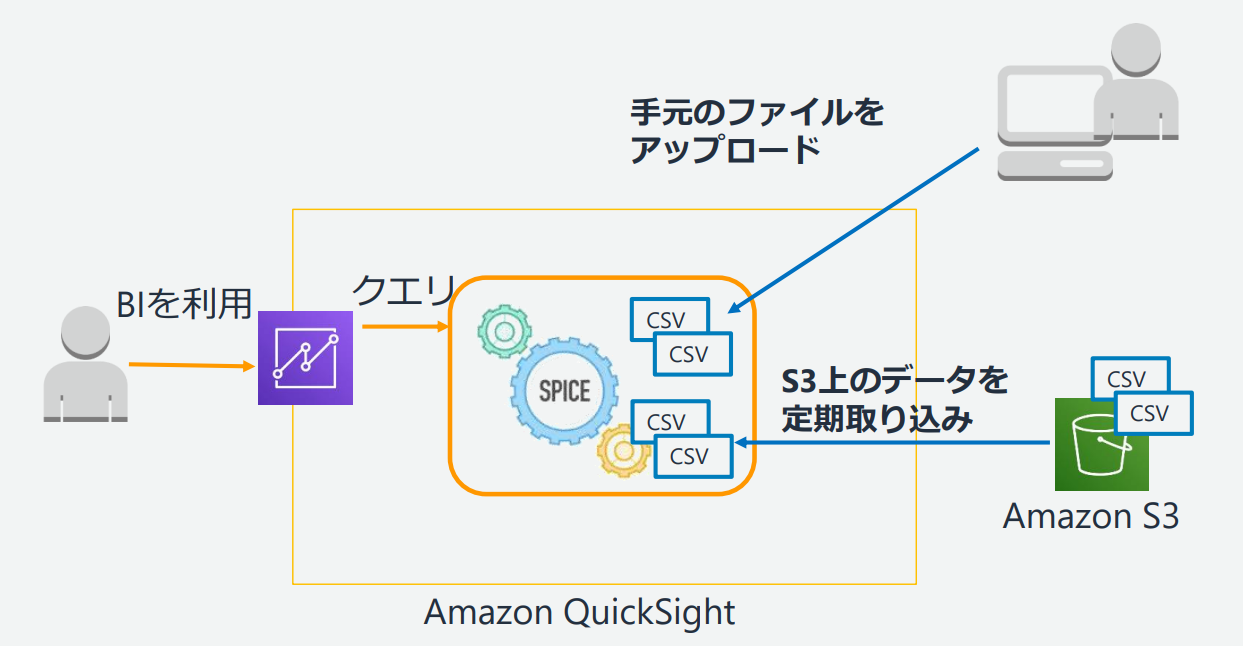
以下リンク先の資料より引用
AmazonQuickSightダッシュボード表示速度の最適化
▼QuickSightの参考ページ▼
4. 実践
大まかなと説明の流れとして、
1.AthenaからS3のデータをクエリ
2.作成したテーブルをQuickSightで可視化
3.可視化したデータの確認
の3段階に分けて確認をしていきます。
4-1. AthenaからS3のデータをクエリ
上記のリンクからAthenaのホーム画面に移動したら、
左側のメニューから [クエリエディタ] を選択します。
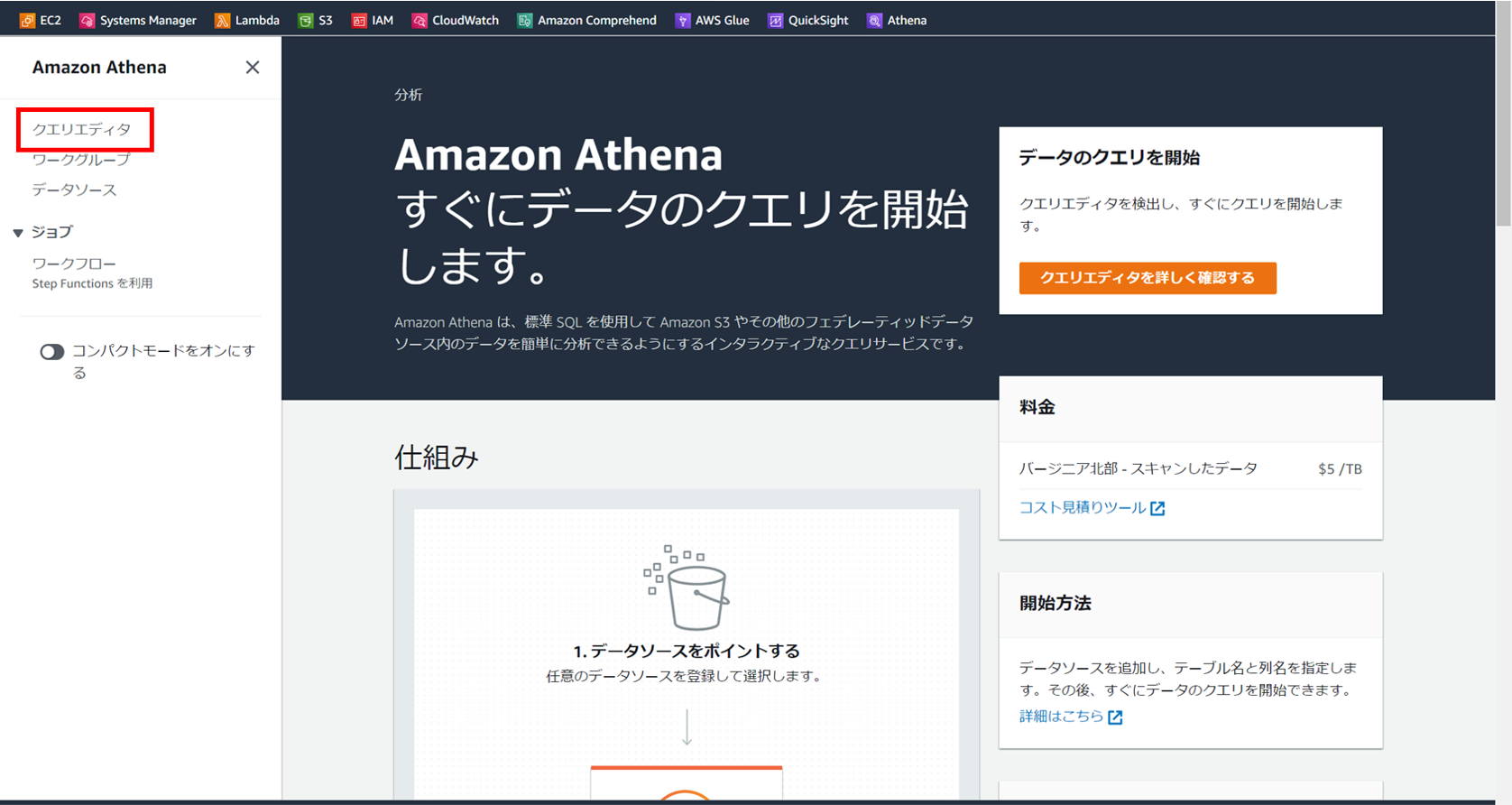
クエリエディタを始めて開いた際には、
出力先をS3フォルダを選択する必要があります。
[設定を編集] を選択します。

[S3を参照] から出力先のフォルダを選択し、
AWSアカウントのID(12桁の数字)を枠に入力します。
また私は個人での利用のみであるため、
クエリ結果に対する完全なコントロールを割り当てました。
最後に [保存] を押しておきます。

エディタ画面に戻ったら以下を入力して実行します。
CREATE EXTERNAL TABLE IF NOT EXISTS sentiment_table (
UserId STRING,
tweetID STRING,
CreatedAt TIMESTAMP,
SearchWord STRING,
Text STRING,
RTcount INT,
RPcount INT,
LKcount INT,
QTcount INT,
NumKeyWord INT,
Sentiment STRING,
Positive FLOAT,
Negative FLOAT,
Neutral FLOAT,
Mixed FLOAT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION 's3://for-twitter-api-bucket/csv_data/'
TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1')
csvデータなのでFIELDS TERMINATED BY ','、
LINES TERMINATED BY '\n'として設定をしています。
LOCATIONはデータの参照先をしており、
'skip.header.line.count'='1'で先頭1行を飛ばしています。
これで可視化に必要なテーブルの作成は完了です。
【csvファイル作成時の注意点】
pandasでデータフレームをcsvに変換する際、
特に引数を設定しないと行の区切りがデフォルトの"\r\n"になります。
AthenaではLINES TERMINATED BY '\n'しか指定できないため、
df.to_csv(line_terminator="\n")を指定しておく必要があります。
▼テーブル作成の参考ページ▼
4-2. 作成したテーブルをQuickSightで可視化
上記のリンクからQuickSightのホーム画面に移動します。
初めてQuickSightを利用する場合は初期設定が必要なので、
必要な方はこちらの記事を参考に設定を進めて下さい。
以下の画面に移動したら、 [新しい分析] を押します。

[新しいデータセット] を選択します。
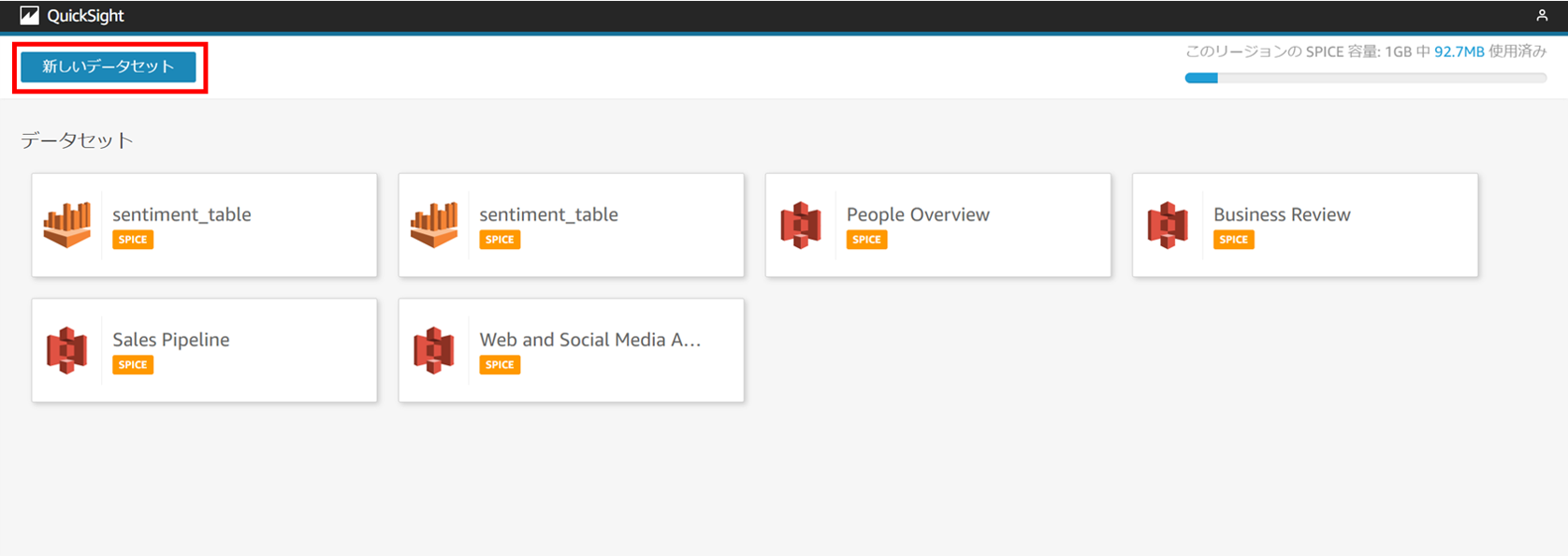
先ほど作成したテーブルを使用したいので、
[Athena] を選択し、名前を入力します。

自分が作成したデータベースを選択し、
可視化するテーブルを選択します。
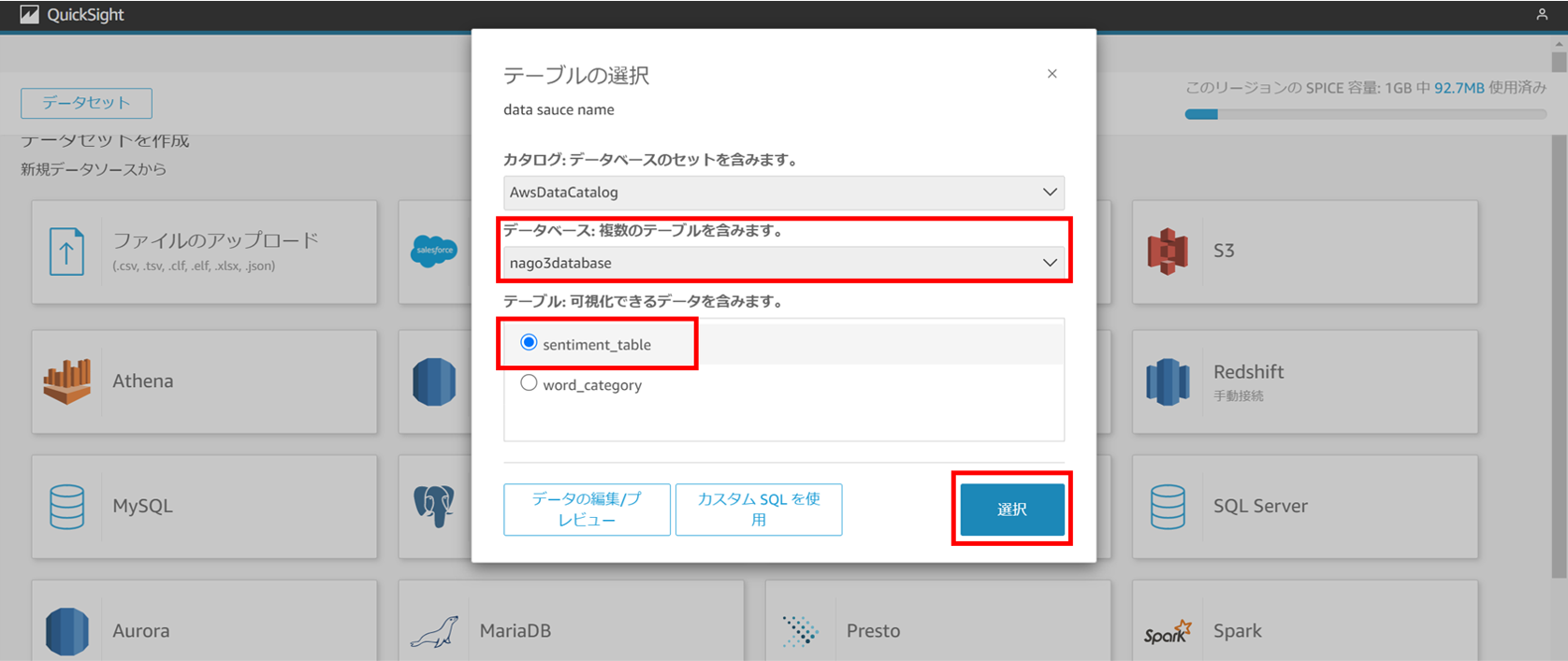
今回はそこまで大規模なデータではないので、
SPICEにインポートして分析を行います。
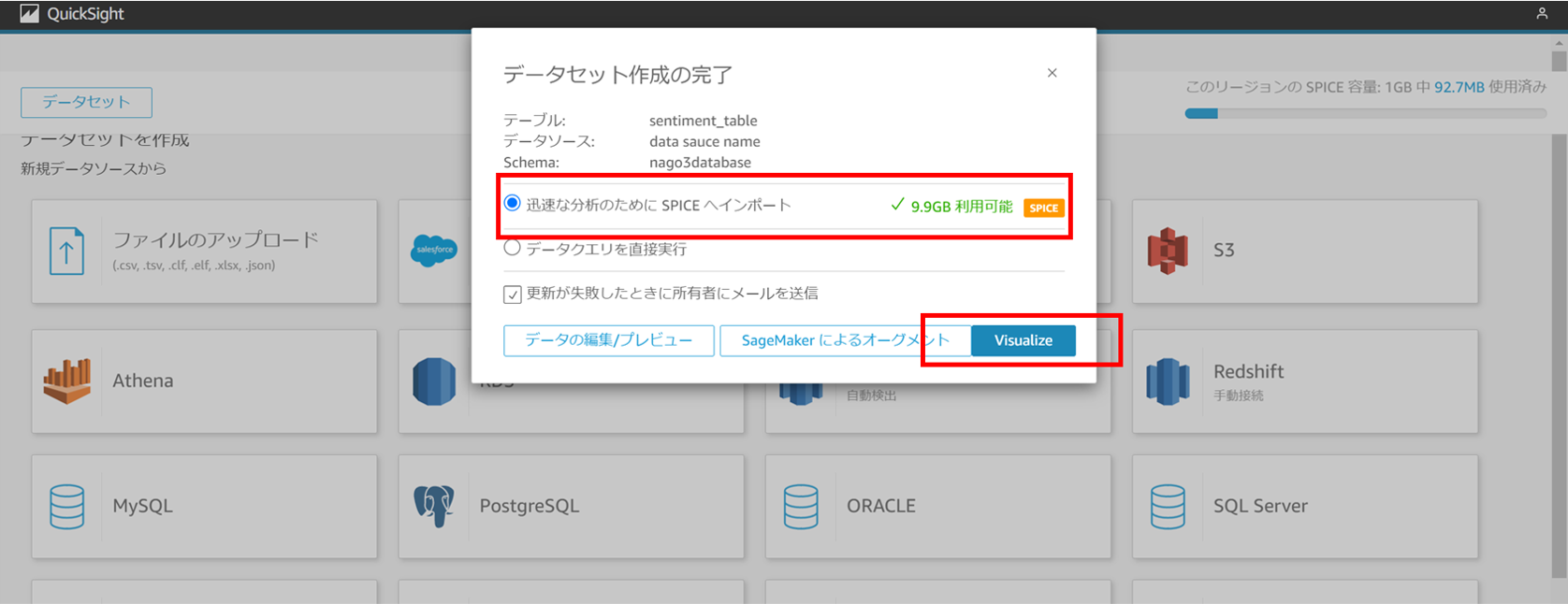
これで可視化の準備は完了です。
4-3. 可視化したデータの確認
画像と同じ画面に移動したら、赤枠部分で
確認したいラベルを選択するだけで可視化が可能です。
今回は [searchword],[negative],[positive] の3つを選択します。
画面右上の▽を開くと表示の設定が可能です。
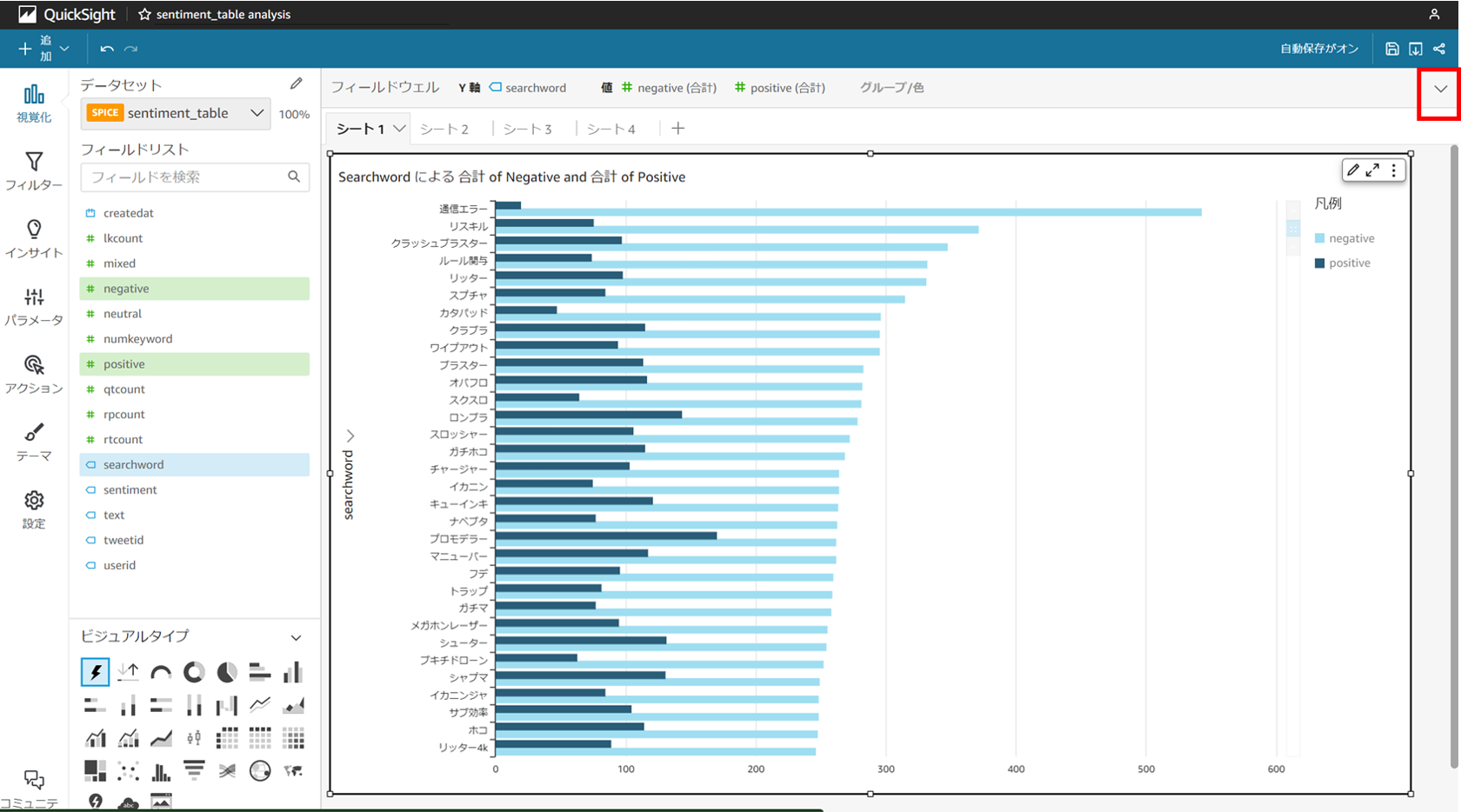
デフォルトの表示では判別確信度の合計なので、
この表示を合計から平均に変更します。

画像は [Negative] で降順になっています。
やはり "通信エラー", "味方落ち" などは上位になっています。

今度は [Positive] で降順に変更します。

"ナイス", "ステージ" などは無関係のデータを含みそうですが、
"333倍マッチ", "グレートバリア" はある程度正確かと思います。
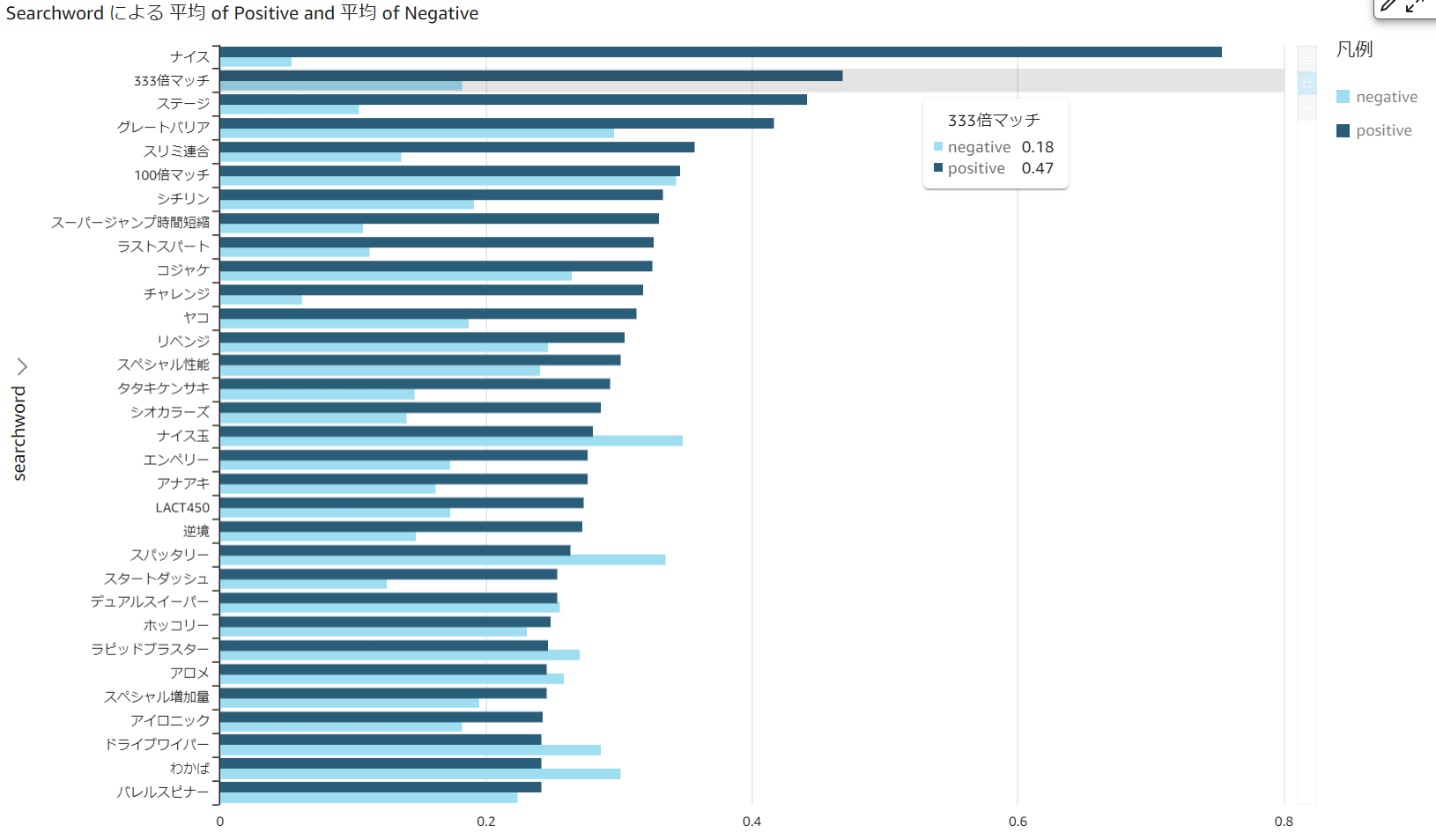
上記のグラフでは各ワードの出現数が分かりません。
ワードによってはサンプル数がとても少なく、
全てを均等に扱うのは不適だと思うので、
ここの表現方法についても検討が必要です。
このデータの純度をもっと高めた後であれば、
各ブキやステージごとの評価を見ることで
コンテンツの改善点などをより明確にできそうです。
5. 所感と今後の展望
5-1. 躓いた点
・クエリする際のSQL文
・csvの区切り文字
まずはAthenaを使ってS3のデータをクエリする際、
シンプルにSQL文に慣れていないことに気づきました。
一通りSQLの学習はしているものの、
再度SQL復習の必要性を感じました。
そして注意書きもしたcsvの区切り文字ですが、
Athenaでクエリする際にとても困りました。
実際にローカルでcsvの中身を見て\r\nに気付き、
Athenaが\nにしか対応していないことを調べてやっと
次に進めたので自分のメモとしても注意書きしました。
5-2. 今後の展望
今回までで目的の可視化は完了したことになりますが、
やはり データの収集と精製にはまだ課題がありそう です。
AWS上での分析フロー構築という目標は達成したので
連投していた記事はここで終わりとなります。
気が向いたらEC2上でjupyter-labを開く方法や
データ精製方法の検討の様子などの記事も
いずれ投稿しようかなぁ、なんて考えています。
また今回のフローを流用した他コンテンツの分析や、
データベース系のサービスにもいずれ触れてみたいと思います。
5-3. さいごに
本記事を読んで頂いてありがとうございました。
また連載した5記事を全て読んで下さった方(もしいたら)、
ご覧頂いて本当にありがとうございます。
まだまだ稚拙な記事ばかりですが、
同じく初学者の方の参考になっていたら嬉しい限りです。
ぜひコメントや質問、お気軽に宜しくお願い致します。
連載記事一覧