注目株の『Liquid AI』が2025年の年末にも新しいモデル(LFM2-2.6B-Exp)をリリースしてひと盛り上がりしていましたね!
2026年はエッジ側で動くAIの利用がこれまで以上に増えるのではないかと思っています。
思えば昨年までは実際にサービスなどに生成AIの恩恵を組み込むことを考えるにあたり、次々に出てくる課題に悩まされていました。
AIは特に多くの様々なデータを扱いがちなので、これはもうOn-deviceで動くAIもアーキテクチャーに入れないと現実的ではないという結論に至っています。
ということで、新しいモデル(LFM2-2.6B-Exp)がリリースされたのと年末年始で丸っとお休みできる日にちがGETできたので、新年一発目の記事を書いて幸先の良いスタートを切りたいと思います!✍️✨
利用するもの一覧
- Liquid AIのモデル(fine-tuningもやります)
- Xcode
- iPhone(iOSアプリ)
- GitHub Copilot
- Microsoft AzureのAI系のサービス(Azure Machine Learning, Red Teaming機能(Microsoft Foundry)など)
Liquid AIとは?
Liquid AI は、MIT CSAIL発のスタートアップで、「Transformer前提」から一歩外れた first principles な発想で、効率(速度・メモリ)と実運用(レイテンシ/プライバシー/耐障害性)を強く意識した基盤モデル群 Liquid Foundation Models(LFM) を開発しているスタートアップです。
世界で最も効率的なモデルを謳い、あらゆるデバイスへの実世界展開を念頭に設計された独自のアーキテクチャにより、可能性を再定義。ウェアラブルデバイスからロボット工学、スマートフォン、ノートパソコン、自動車など、あらゆる場所でインテリジェンスにアクセスできるようになります。
- https://www.liquid.ai/blog/new-generation-of-ai-models-from-first-principles
- https://www.liquid.ai/models
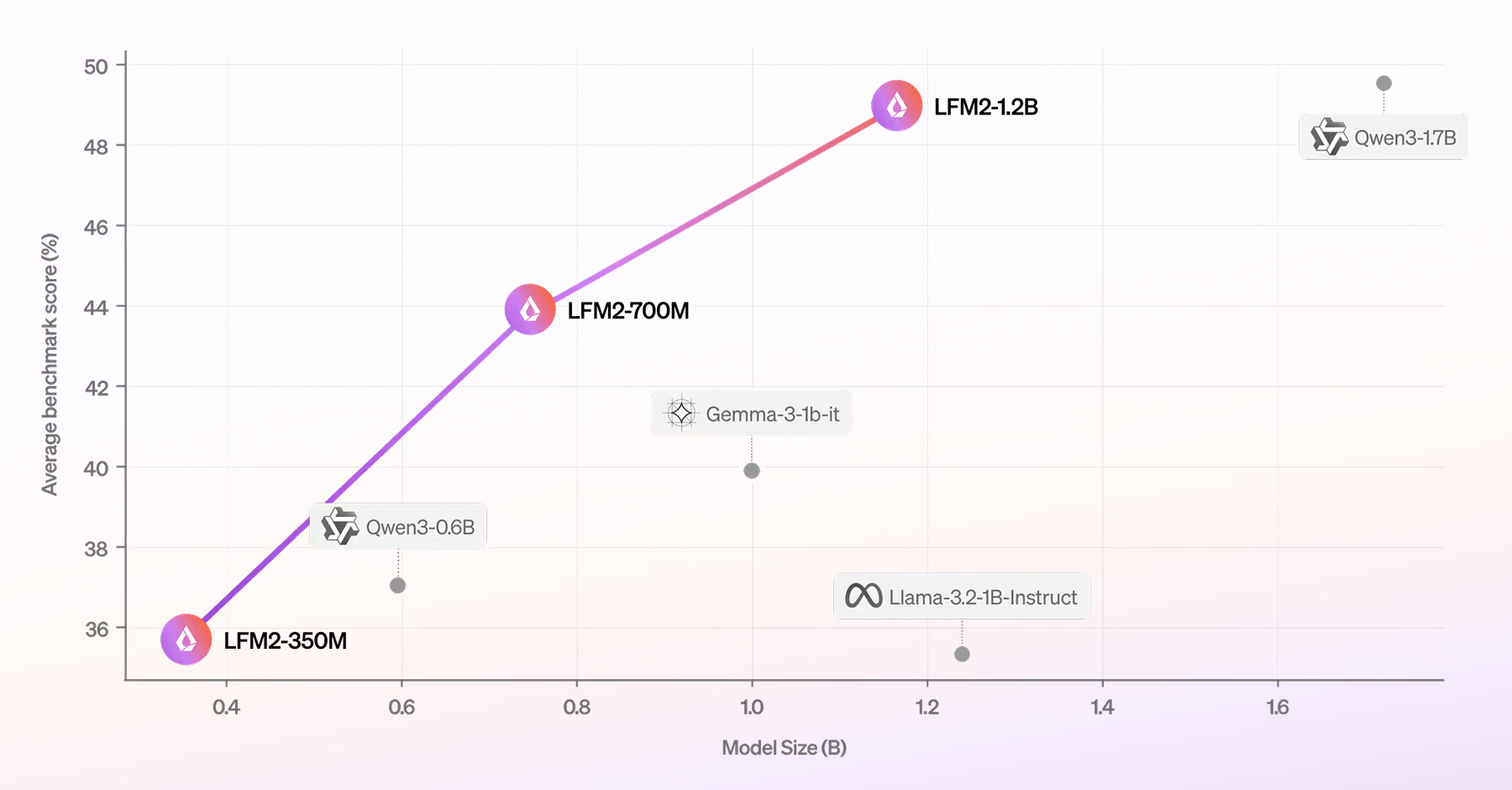
2025年に公開された第2世代のLFM2(Liquid Foundation Models)は、エッジ/オンデバイス運用を前提にした“効率設計”という特徴をもっており、品質だけでなく推論速度とメモリ効率まで含めて最適化されています。
そして小型モデルであるぶん、「狭いユースケースにfine-tuningして性能を最大化する」ことが推奨されています。
LFM2-2.6B-Expのモデルの内容は?
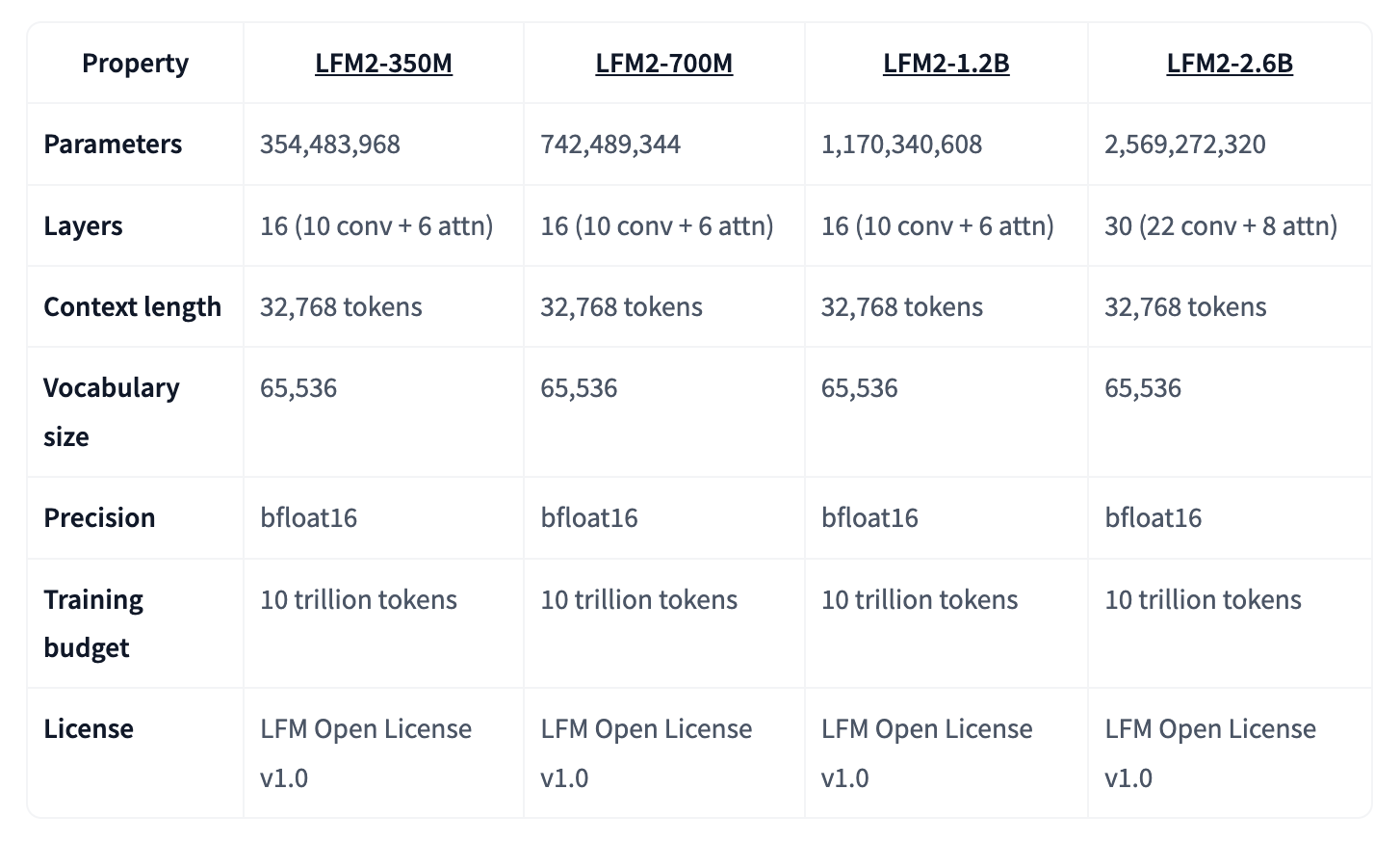
LFM2-2.6Bを土台にした 実験的(Experimental)チェックポイントで、pure reinforcement learning(強化学習のみ)で作られた、と説明されています。さらに instruction following(指示追従)/ knowledge(知識)/ math(数学) をターゲットに追加学習しており、他の3B級モデルと比べても高いパフォーマンスを発揮しているようです。。
-
日本語を含む8言語対応(English, Arabic, Chinese, French, German, Japanese, Korean, and Spanish.)
-
最大32Kコンテキスト
-
量子化モデルが用意されている(4bit / 5bit / 6bit / 8bit)
-
Tool useが用意されている
iOSアプリに組み込む、手順
ひとまず検証用として必要最低限を目指してiOSアプリに組み込んでみましょう。
公式のQuick Starを参考に進めます。
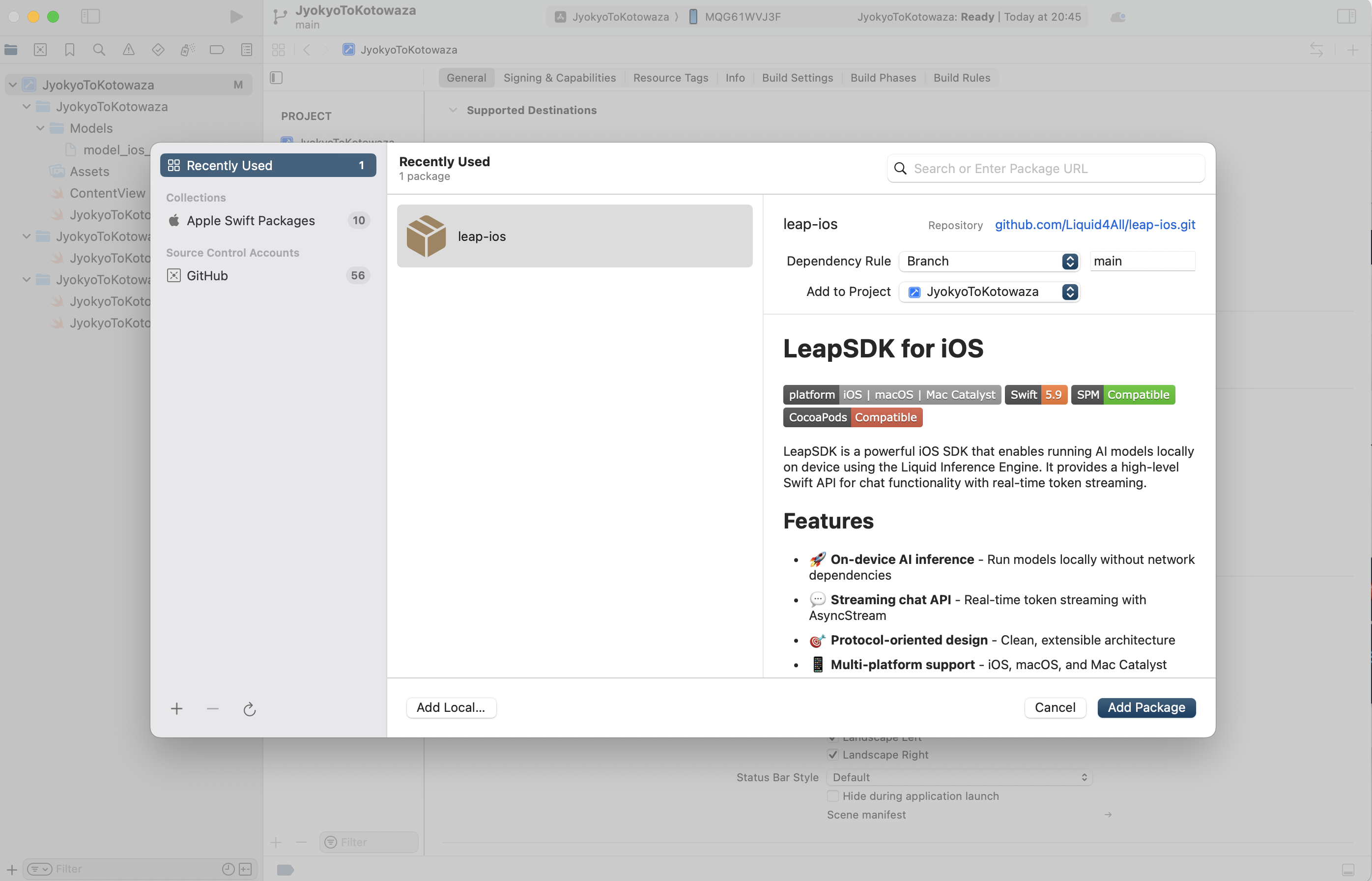
1. LeapSDKの追加
File > Add Package > 必要なPackageを追加
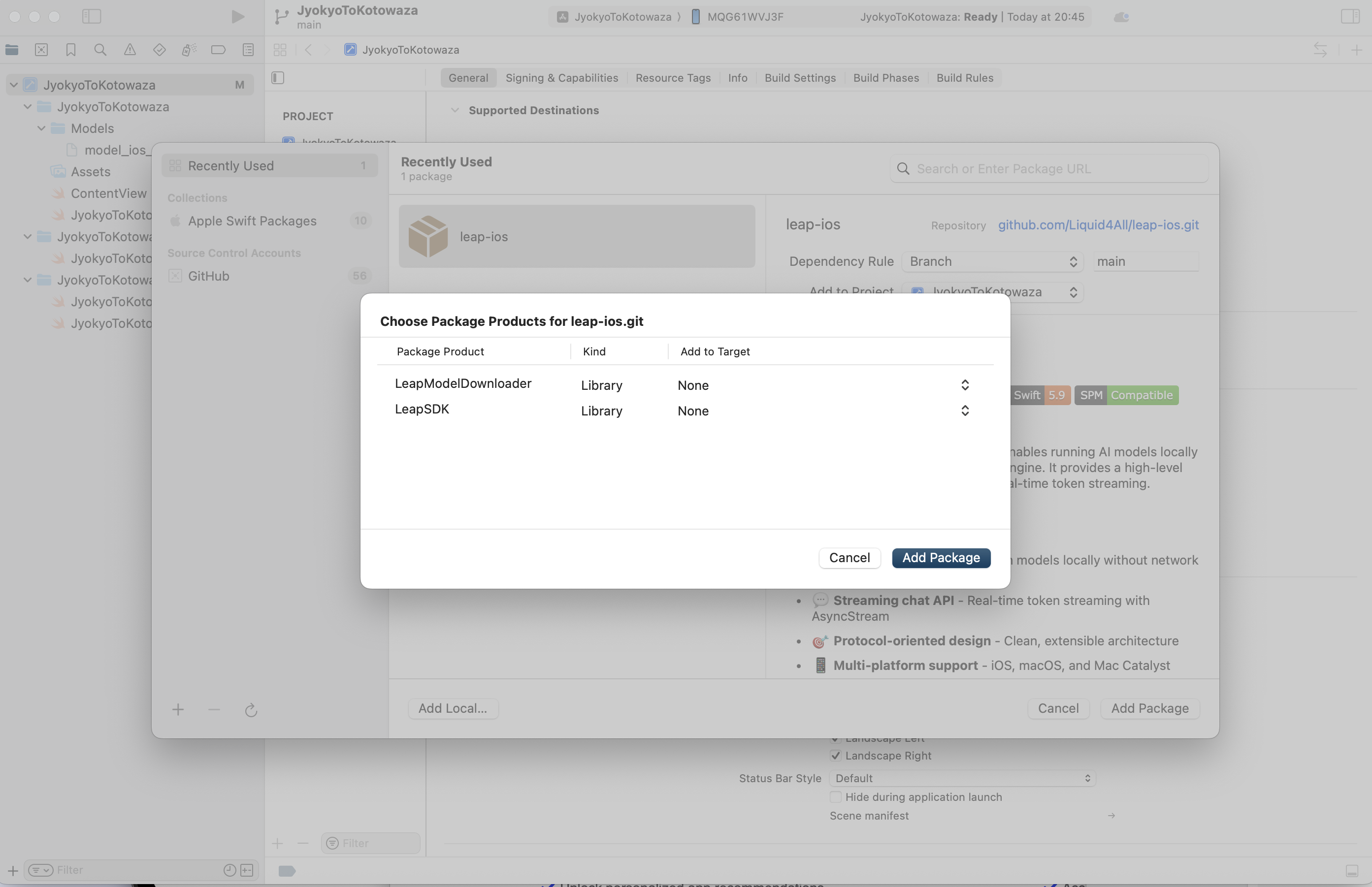
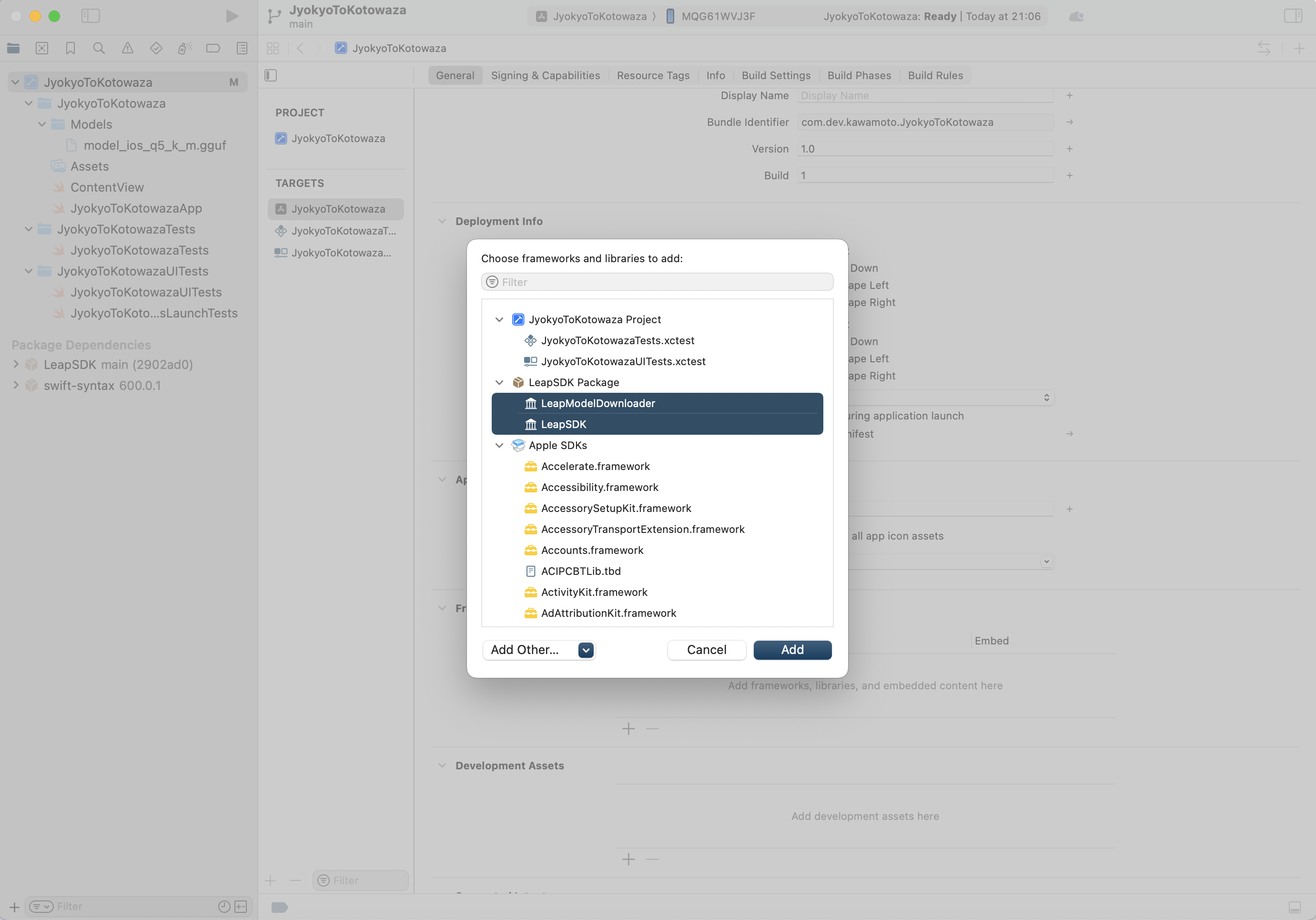
2. 必要なSDKの追加
General > Frameworks, Libraries and Embedded Content > 必要なLeapSDKの追加
3. iOSアプリの開発&デプロイ
アプリの開発はGitHub Copilot(モデルはClaudeを使用)のAgentモードでコーディングしてもらいました。今回、アプリを作るの自体は本質ではないのでAI使って楽しましょう!
(LINEミニアプリ on LINEアプリみたいな感じで、iOSアプリ&WebViewな構成ですね)
- XcodeでGitHub Copilotを使おうとしているところ↓↓
- サンプルコード
今回はオンデバイス実行のため、GGUFの量子化モデル(5bit / Q5_K_M)を使います。
import LeapSDK
import LeapModelDownloader
import Combine
@MainActor
final class ChatViewModel: ObservableObject {
@Published var isLoading = false
@Published var conversation: Conversation?
private var modelRunner: ModelRunner?
private var generationTask: Task<Void, Never>?
func loadModel() async {
isLoading = true
defer { isLoading = false }
do {
// LEAP will download the model if needed or reuse a cached copy.
let modelRunner = try await Leap.load(model: "LFM2-2.6B-Exp", quantization: "Q5_K_M", downloadProgressHandler: { progress, speed in
// progress: Double (0...1)
// speed: bytes per second
})
conversation = modelRunner.createConversation(systemPrompt: "You are a helpful travel assistant.")
self.modelRunner = modelRunner
} catch {
print("Failed to load model: \(error)")
}
}
func send(_ text: String) {
guard let conversation else { return }
generationTask?.cancel()
let userMessage = ChatMessage(role: .user, content: [.text(text)])
generationTask = Task { [weak self] in
do {
for try await response in conversation.generateResponse(
message: userMessage,
generationOptions: GenerationOptions(temperature: 0.7)
) {
self?.handle(response)
}
} catch {
print("Generation failed: \(error)")
}
}
}
func stopGeneration() {
generationTask?.cancel()
}
@MainActor
private func handle(_ response: MessageResponse) {
switch response {
case .chunk(let delta):
print(delta, terminator: "") // Update UI binding here
case .reasoningChunk(let thought):
print("Reasoning:", thought)
case .audioSample(let samples, let sr):
print("Received audio samples \(samples.count) at sample rate \(sr)")
case .functionCall(let calls):
print("Requested calls: \(calls)")
case .complete(let completion):
if let stats = completion.stats {
print("Finished with \(stats.totalTokens) tokens")
}
let text = completion.message.content.compactMap { part -> String? in
if case .text(let value) = part { return value }
return nil
}.joined()
print("Final response:", text)
// completion.message.content may also include `.audio` entries you can persist or replay
}
}
}
アプリは下記な感じでできました。(ユーザーの状況を伝えて、その状況に近いことわざを表示する..みたいなのをイメージしました。アプリは正直なんでもよかったりはしますね笑)

(Optional) Fine-TuningしてiOSアプリに組み込む
Liquid AIはモデルをFine-Tuningして使うことも推奨しています。
ある特定のタスクにおいて、LLMに匹敵する精度を叩き出せれば問題無いわけですからね。
下記の公式ドキュメントを参考にFine-TuningしたモデルをiOSアプリに組み込む感触も試しておきます。
作業はデータの処理が少々大変なのとトレーニングは試行錯誤かつマシンパワーも必要なのでクラウド上(Azure Machine Learning)で実施しました。
Azure Machine LearningにはVS CodeライクなWEBブラウザで使える開発エディタが標準で搭載されているのでAI/ML系の作業をする時は便利です。ちなみに、NVIDIA Tesla T4なクラウドのコンピュータリソースを今回は使って作業しています。
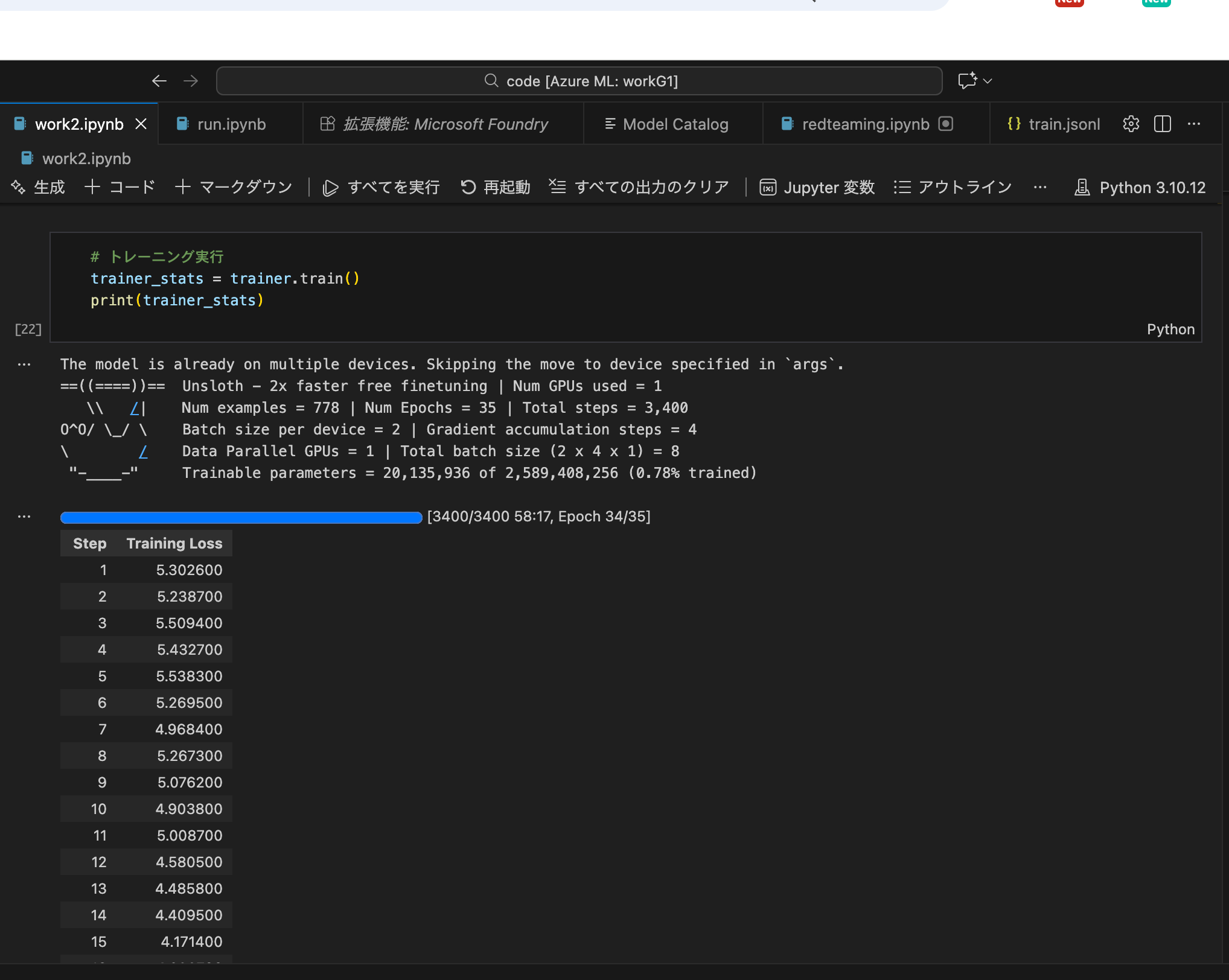
これはおまけですが、クラウド上だとEvaluationの機能とかも豊富だったりするので、本番での運用も考えるとかなり便利に作業を進めることができることができそうなのが良いですね。(下記は軽くFine-TuningしたモデルにRed Teamingを実施してみているところ)
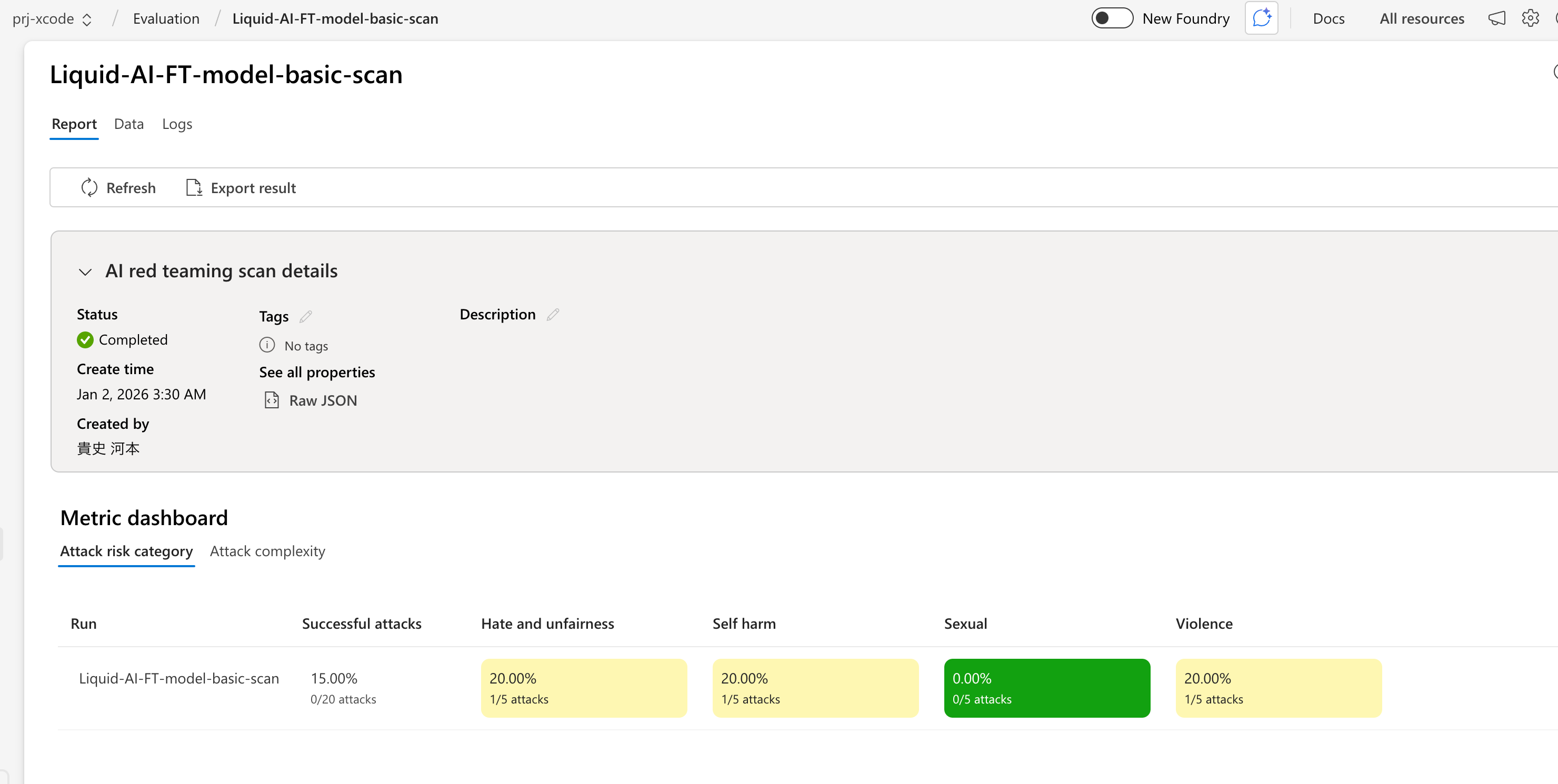
- サンプルコード
Fine-Tuningしたモデルをローカルに配置し、そのモデルを使うように指定しています。
import LeapSDK
@MainActor
final class ChatViewModel: ObservableObject {
@Published var isLoading = false
@Published var conversation: Conversation?
private var modelRunner: ModelRunner?
private var generationTask: Task<Void, Never>?
func loadModel() async {
guard let bundleURL = Bundle.main.url(forResource: "model_ios_q5_k_M", withExtension: "gguf") else {
assertionFailure("Model bundle missing")
return
}
isLoading = true
defer { isLoading = false }
do {
modelRunner = try await Leap.load(url: bundleURL)
conversation = modelRunner?.createConversation(systemPrompt: "You are a helpful travel assistant.")
} catch {
print("Failed to load model: \(error)")
}
}
func send(_ text: String) {
guard let conversation else { return }
generationTask?.cancel()
let userMessage = ChatMessage(role: .user, content: [.text(text)])
generationTask = Task { [weak self] in
do {
for try await response in conversation.generateResponse(
message: userMessage,
generationOptions: GenerationOptions(temperature: 0.7)
) {
await self?.handle(response)
}
} catch {
print("Generation failed: \(error)")
}
}
}
func stopGeneration() {
generationTask?.cancel()
}
@MainActor
private func handle(_ response: MessageResponse) {
switch response {
case .chunk(let delta):
print(delta, terminator: "") // Update UI binding here
case .reasoningChunk(let thought):
print("Reasoning:", thought)
case .audioSample(let samples, let sr):
audioRenderer.enqueue(samples, sampleRate: sr)
case .functionCall(let calls):
print("Requested calls: \(calls)")
case .complete(let completion):
if let stats = completion.stats {
print("Finished with \(stats.totalTokens) tokens")
}
let text = completion.message.content.compactMap { part -> String? in
if case .text(let value) = part { return value }
return nil
}.joined()
print("Final response:", text)
// completion.message.content may also include `.audio` entries you can persist or replay
}
}
}
簡単な結果
比較のためにLLMをAPI経由で実行する処理も入れます。
速度は基本、ローカルの方が早いですね。
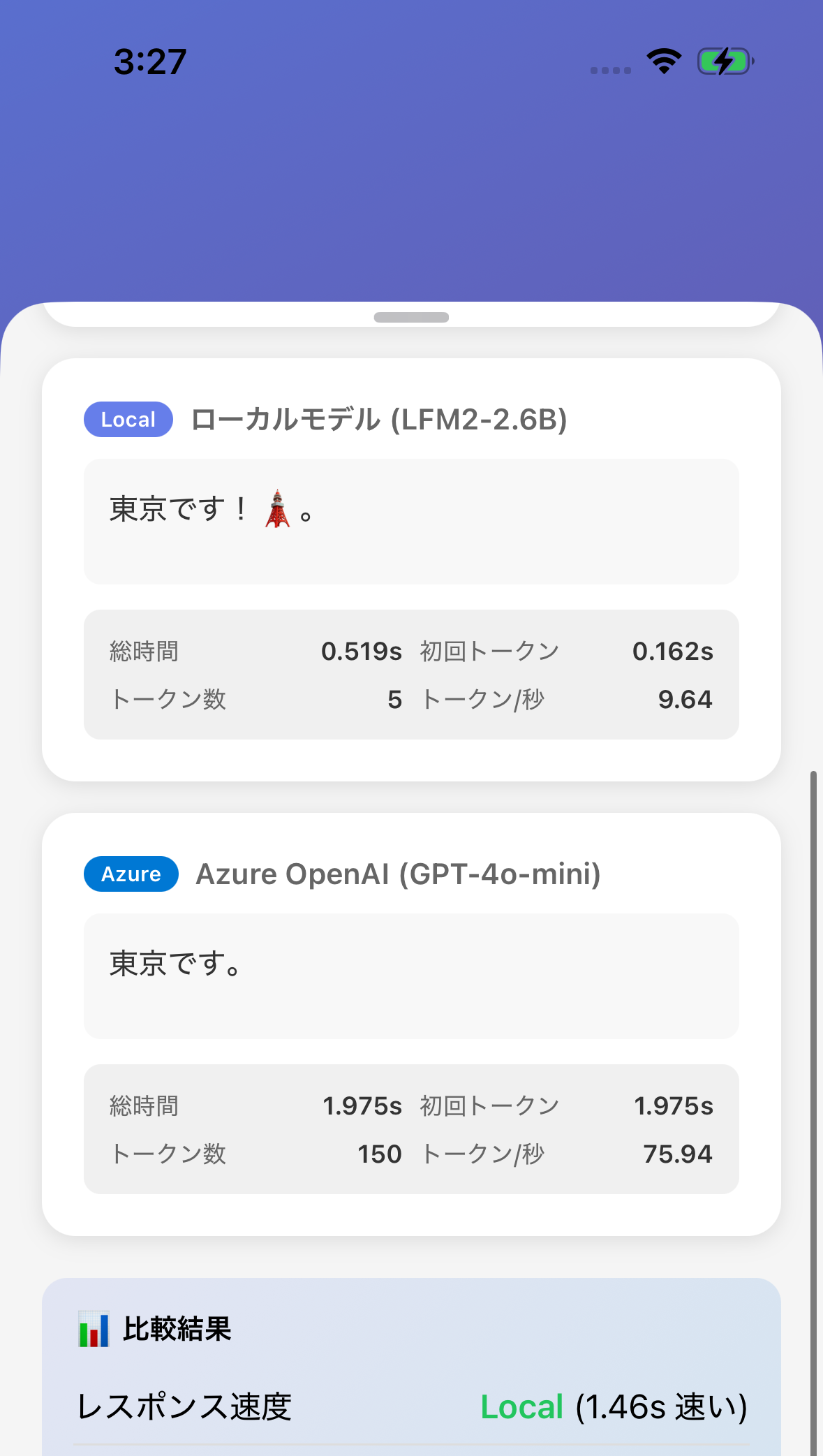
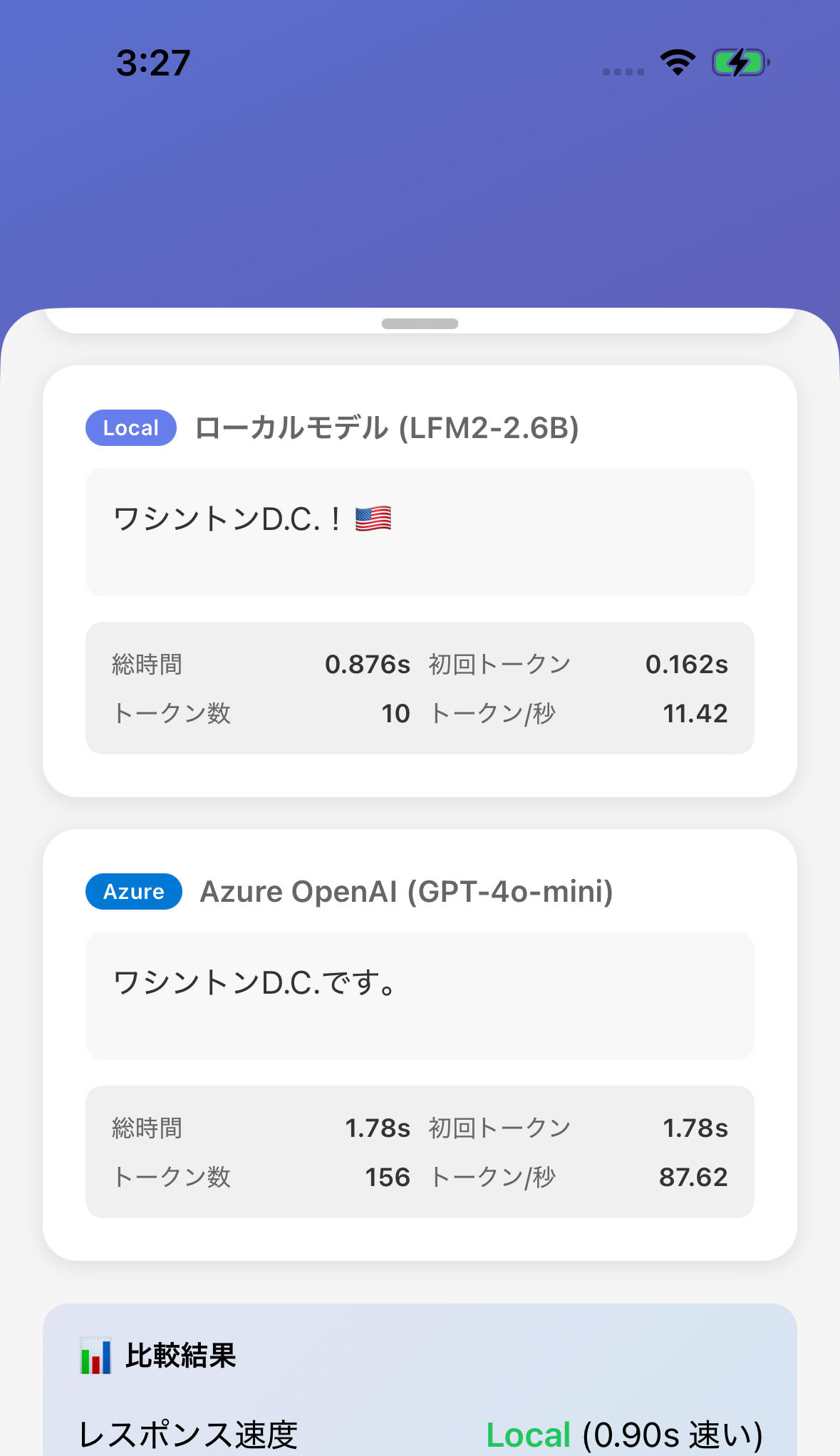
あとはローカルのモデルはオフラインでも動きますよね。

日本語でも結構良い感じなのはやはり嬉しい✨️
まとめ
ひとまず感触をちょっと確かめるための最低限の内容でした。
これから色々と検証を進めていきたいと思います。(もちろんLiquid AI以外のEdgeで動くモデルも含む)
個人的には6年ぐらい前に颯爽とあらわれ、当時ギブアップしかけていたML案件を見事に救ってくれた、あの『BERT』と同じようなBERTみを感じています!!今回も救ってくれ〜笑
今年はOn-device、国産(自前の環境なども)な選択肢をとるケースが増えていきそうですね。
(後は音声系も課題なんですが、あれは..もう少しかかりそうな予感..)