この記事は、ケーシーエスキャロット Advent Calendar 2020の24日目の記事です。
初めに
お仕事でPrometheusのインストールに携わらせて頂く事になったので、
色々調べてみた事のメモ的なものです。
※いっぱいググっているので、参考とさせて頂いた皆様、本当に助かりました。。
後、本も参考に。

Prometheusとは
超ざっくり言えば プル型のリソース監視ツール。
Prometheus本体から各監視対象サーバのリソースを取得して、
グラフ化したり、予め設定した閾値を超えた場合のアラート通知等が出来ます。
グラフについてはPrometheusのみでは正直グラフィカルな感じではないので、
Grafanaという可視化ツールと連携して、こちらで見る事にします。
※連携はすごく簡単です
exporter
それぞれ、監視したい内容によって、
exporterという監視内容に沿ったデータ(metrics)を出力するツール
(アクセス先のエンドポイントになる)をインストールする必要があります。
※監視対象サーバ全部
また、それぞれ閾値を超えた場合はアラート通知必須なので、
alertmanagerもインストールします。
( https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz )
監視内容に対して利用可能なexporterは以下です。
※代表例のみ
- パフォーマンス監視
- node_exporter
- https://github.com/prometheus/node_exporter/releases/download/v1.0.0/node_exporter-1.0.0.linux-amd64.tar.gz
- ログ監視
- grok_exporter
- https://github.com/fstab/grok_exporter/releases/download/v1.0.0.RC3/grok_exporter-1.0.0.RC3.linux-amd64.zip
- 死活監視
- blackbox_exporter
- https://github.com/prometheus/blackbox_exporter/releases/download/v0.18.0/blackbox_exporter-0.18.0.linux-amd64.tar.gz
- プロセス監視
- process_exporter
- https://github.com/ncabatoff/process-exporter/releases/download/v0.7.2/process-exporter_0.7.2_linux_amd64.rpm
ざっくり全体像
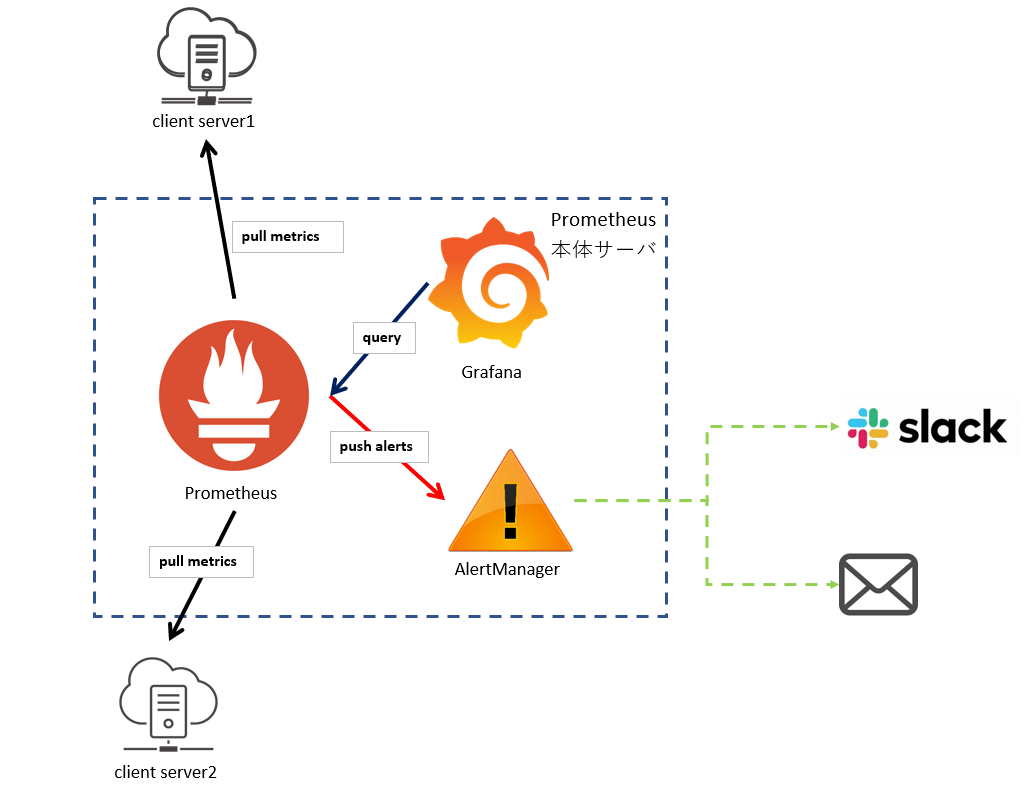
高速でパフォーマンス監視環境構築
※ CentOS8でインストールしてみた手順です
AlertManagerインストール
以下手順でインストール
wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
tar -xzvf alertmanager-0.21.0.linux-amd64.tar.gz
mv alertmanager-0.21.0.linux-amd64 /etc/alertmanager
cd /etc/alertmanager
alertmanager.ymlを以下の内容に書き換える
※Slackの alert-testチャンネルにアラート通知
------------------
global:
slack_api_url: 'https://hooks.slack.com/services/XXXXXXXX/XXXXXXXX/xxxxxxxxxxxxxxxxxxxxxxxx'
route:
group_wait: 30s
group_interval: 30s
repeat_interval: 30s
receiver: default
receivers:
- name: 'default'
slack_configs:
- send_resolved: true
channel: '#alert-test'
title: "{{ range .Alerts }}{{ .Annotations.summary }}\n{{ end }}"
text: "{{ range .Alerts }}{{ .Annotations.description }}\n{{ end }}"
------------------
# 実行(systemctlへの追加推奨)
/etc/alertmanager/alertmanager --config.file /etc/alertmanager/alertmanager.yml
パフォーマンス監視インストール(監視対象サーバでインストール)
以下手順でインストール
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.0/node_exporter-1.0.0.linux-amd64.tar.gz
tar zxvf node_exporter-1.0.0.linux-amd64.tar.gz
mv node_exporter-1.0.0.linux-amd64 /etc/node_exporter
cd /etc/node_exporter
# 起動(systemctlへの追加推奨)
/etc/node_exporter/node_exporter
Prometheusインストール
以下手順でインストール
tar zxvf prometheus-2.18.1.linux-amd64.tar.gz
mv prometheus-2.18.1.linux-amd64 /etc/prometheus
cd /etc/prometheus
prometheus.ymlの内容は以下
------------------
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
rule_files:
- "./alert_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'node'
scrape_interval: 10s
static_configs:
- targets: ['client-host-name:9100']
------------------
alert_rules.ymlを以下内容で作成
------------------
groups:
- name: node
rules:
- alert: memory_used
expr: 100 * (1 - node_memory_MemFree_bytes{job='node'} / node_memory_MemTotal_bytes{job='node'}) > 90
for: 30s
labels:
severity: critical
annotations:
summary: "memory {{ $labels.instance }} used over 90%"
description: "cpu of {{ $labels.instance }} has been used over 90%"
- alert: disk_used
expr: 1 - node_filesystem_avail_bytes{job='node',mountpoint='/'} / node_filesystem_size_bytes{job='node',mountpoint='/'} > 90
for: 30s
labels:
severity: critical
annotations:
summary: "disk {{ $labels.instance }} used over 90%"
description: "disk of {{ $labels.instance }} has been used over 90%"
------------------
# api利用可として実行(systemctlへの追加推奨)
/etc/prometheus/prometheus --config.file=/etc/prometheus/prometheus.yml --web.enable-admin-api
これで監視対象サーバのメモリ/Disk(/)の使用率が90%を超えるとSlackへ通知されます