やりたいこと
- 【こちらから】無料枠でGCEを起動したい
- 【こちらから】SSHの22番ポートを3333番ポートに変更したい
- 【このページ】GCE(仮想マシン) 内の Python(Ubuntu) でSeleniumを使ったスクレイピング
- 【このページ】取得したファイルをGoogle Driveにアップロード
- 【こちらから】スクレイピングを cron で定期的に実行する
- 【こちらから】指定の時間にインスタンスをオン/オフする
※※※※※※※※※※※※※※※※※※※※※
※GCEは作成済みという前提で話を進めます ※
※※※※※※※※※※※※※※※※※※※※※
全体図
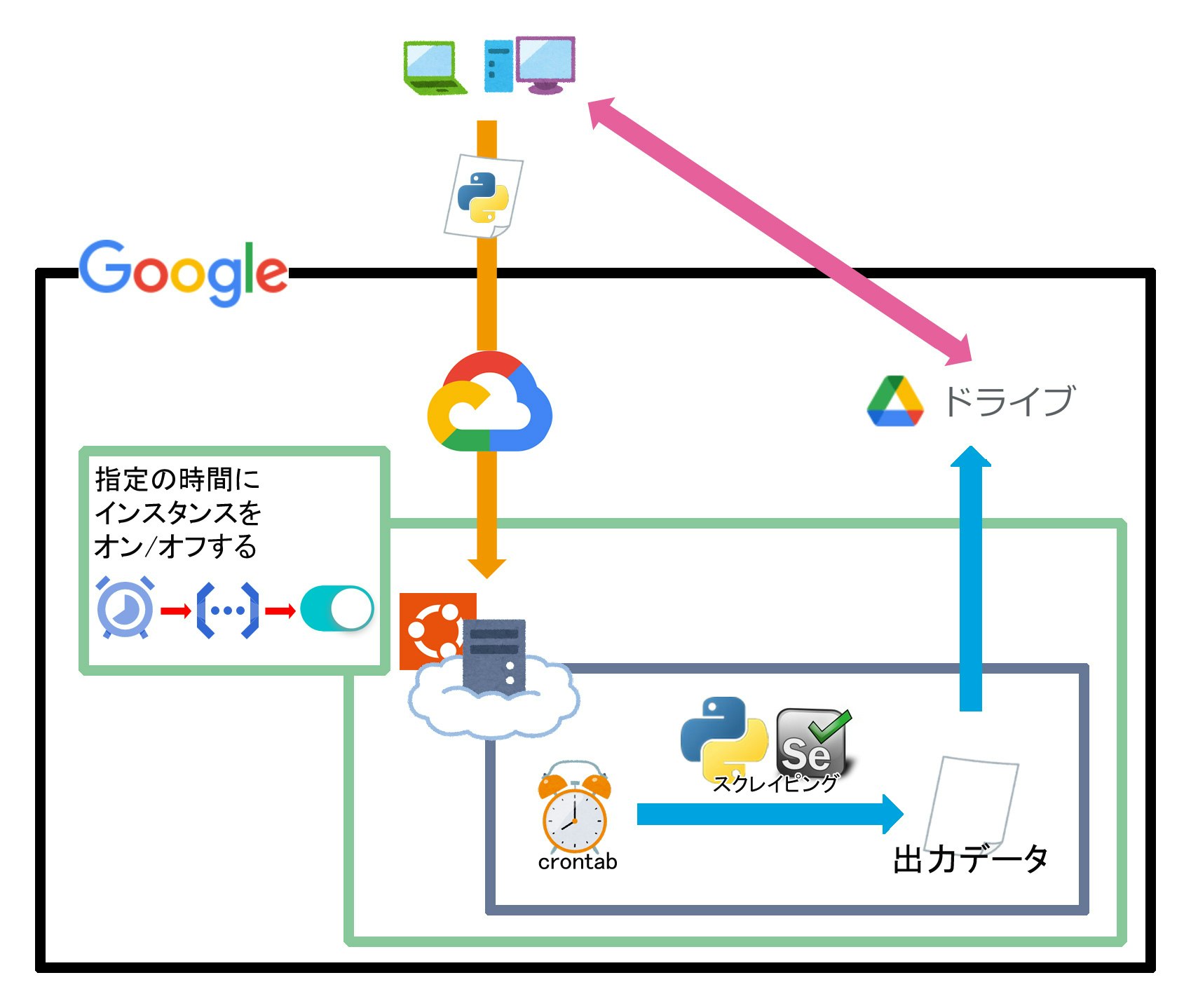
環境
| アイテム | バージョン |
|---|---|
| Ubuntu | 22.04.1 LTS |
| Python | 3.10.6 |
| Selenium | 3.141.0 |
| webdriver-manager | 3.8.3 |
| ChromeDriver | 106.0.5249.91 |
準備編
- 動的ページをスクレイピングできるようにしたい
- webdriver-managerのパッケージを使いたい
① まずは接続先にSSH接続
ssh -i ~/.ssh/my-ssh-key -p 3333 hogehoge@[外部 IP アドレス]
② pip がインストールされてなければインストール
python --version
# Python 3.10.6
pip3 list
# Command 'pip3' not found, but can be installed with: apt install python3-pip
sudo apt update
sudo apt install python3-pip
# After this operation, 273 MB of additional disk space will be used.
# Do you want to continue? [Y/n]
# ディスクを273MB分使いますよ的なことを聞かれたら `Y`
pip3 --version
# pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)
③ 必要なパッケージをインストールする
pip3 install selenium==3.141.0
pip3 install webdriver-manager
pip3 install pandas
pip3 install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
④ GoogleChrome のインストール
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd64.deb
以下のエラーが出た場合
Errors were encountered while processing
google-chrome-stable
sudo apt install -f
sudo dpkg -i google-chrome-stable_current_amd64.deb
⑤ Google Drive APIの有効化、鍵の作成
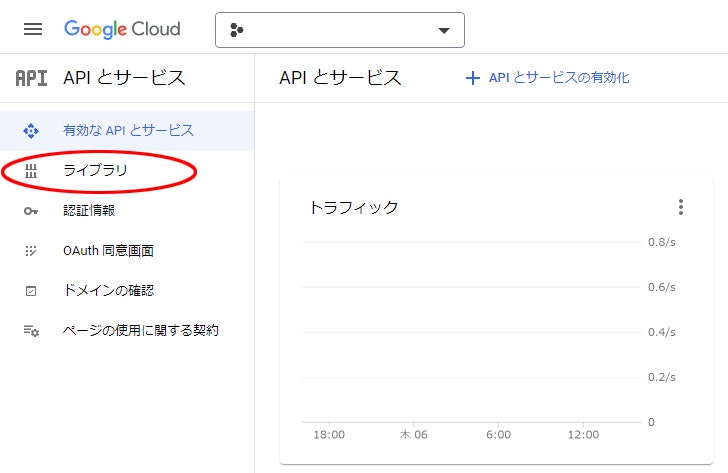
1. 画面左上、Google Cloud ロゴの左にある ナビゲーション メニュー から すべてのプロダクトを表示
2. 管理の API とサービス を選択
3. ライブラリ を選択、一覧 or 検索ボックス から Google Drive API をクリック
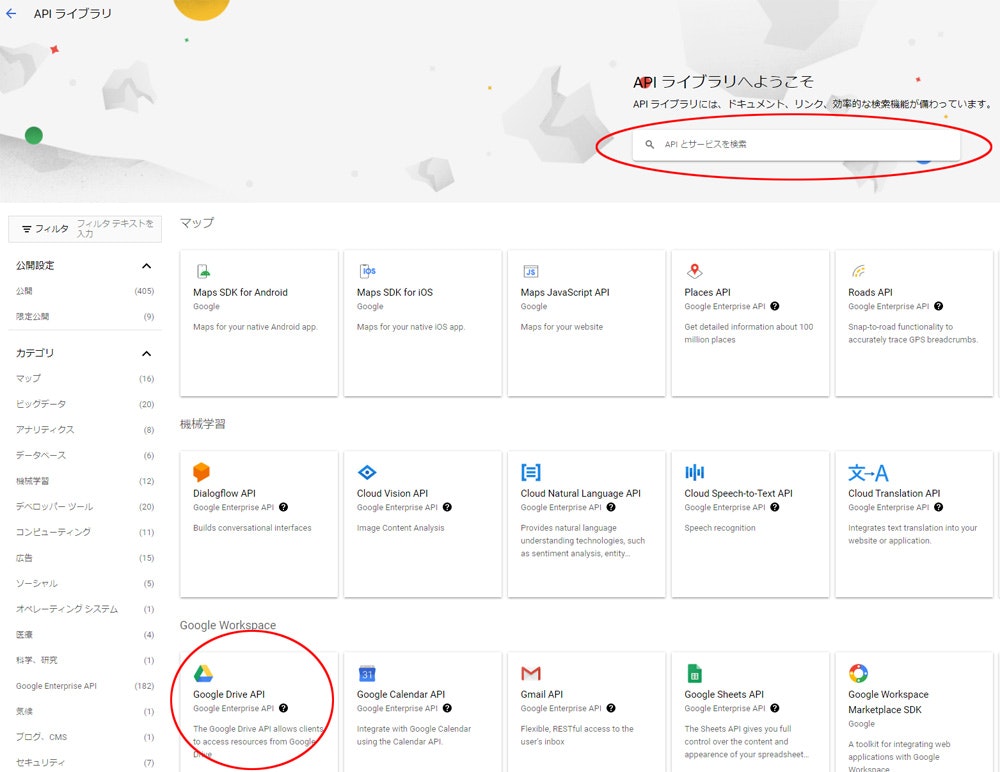
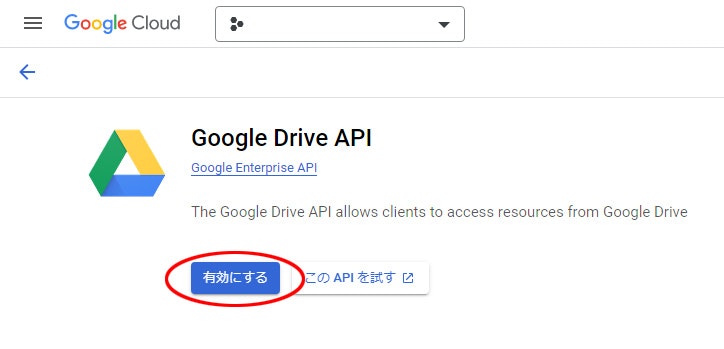
4. Compute Engine APIを 有効にする
5. 認証情報 > 認証情報を作成 > サービス アカウント
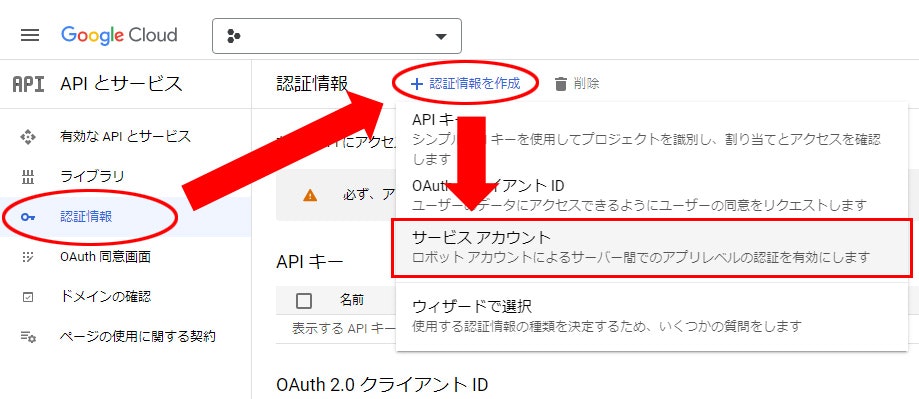
6. わかりやすい サービス アカウント名 を入力して 作成して続行
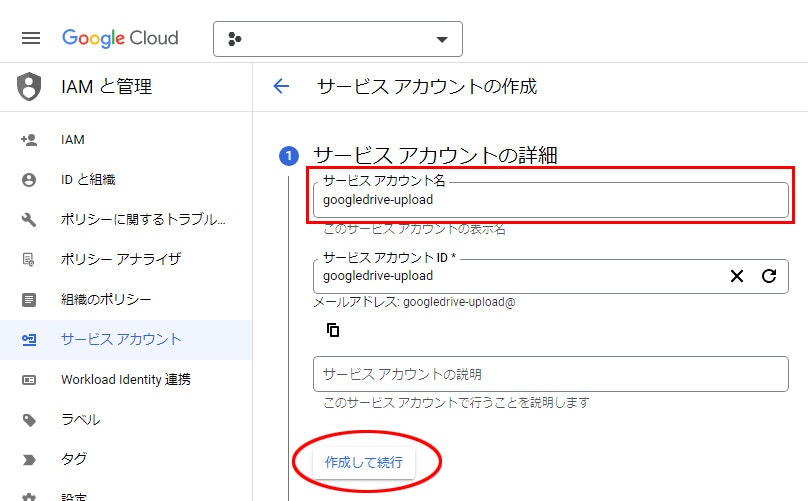
7. ロールを選択
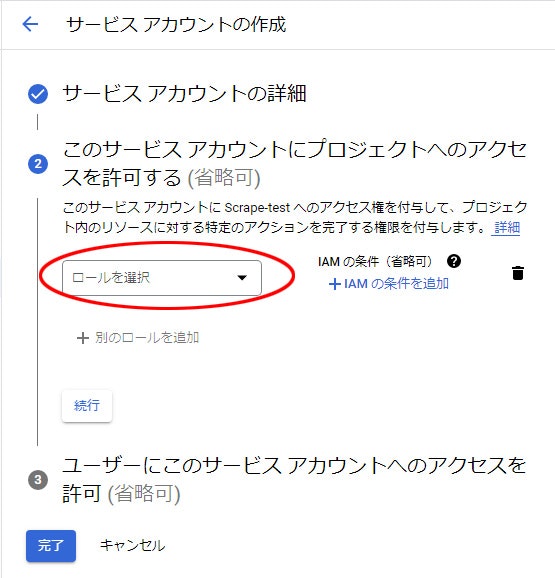
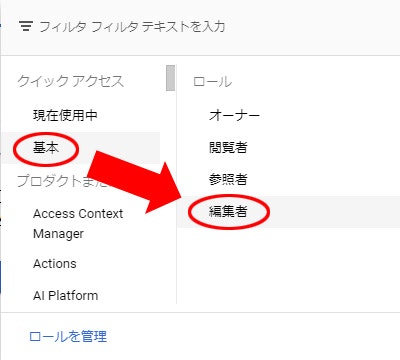
8. 基本 から 編集者 を選択
9. 続行 して 完了
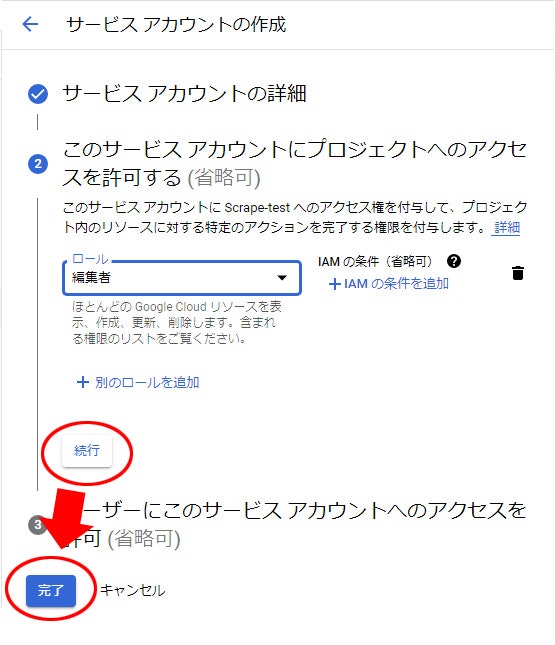
10. 一覧に戻るので、作成した サービス アカウント名 を選択
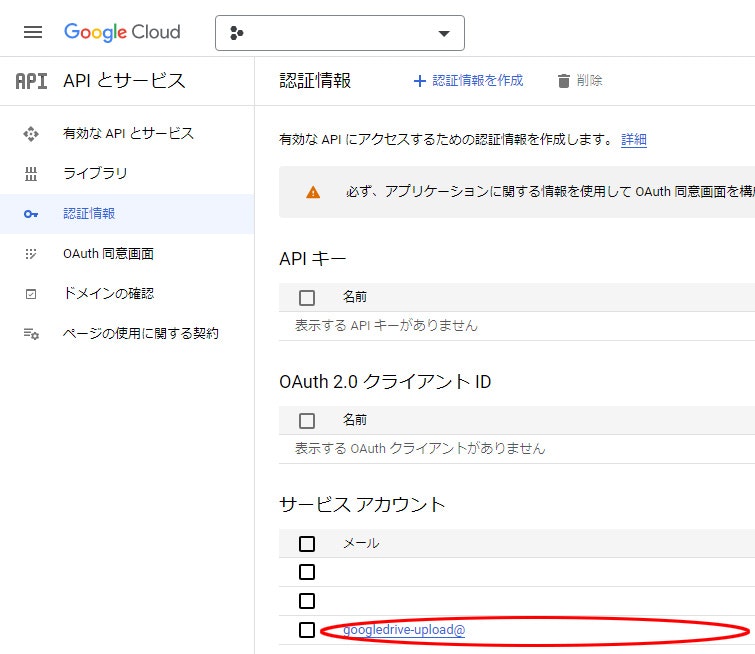
11. キー から 鍵を追加、新しい鍵を作成 を選択
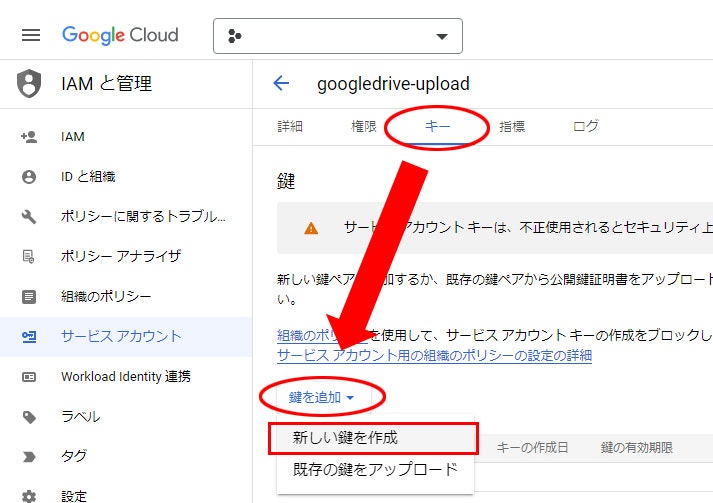
12. 作成
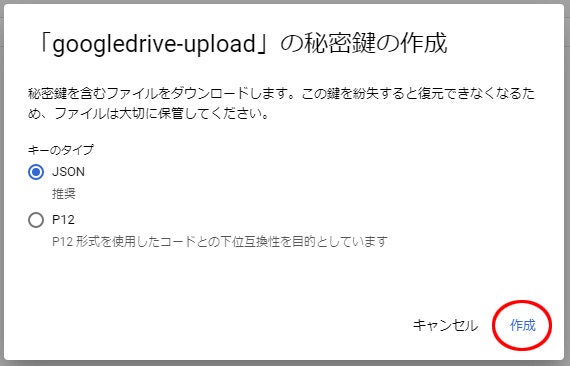
13. ダウンロードされたログを閉じて、サービス アカウント名 の 左矢印 をクリック
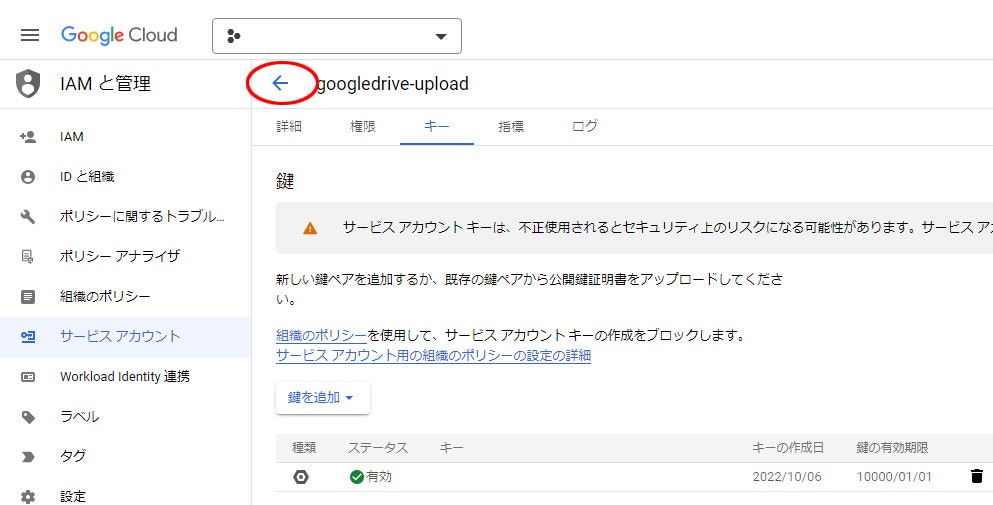
14. メールアドレスをコピーしておく
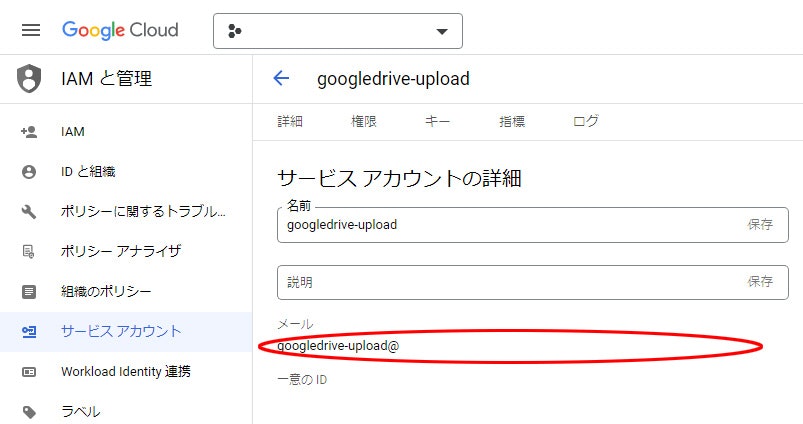
⑥ Google Driveとの連携
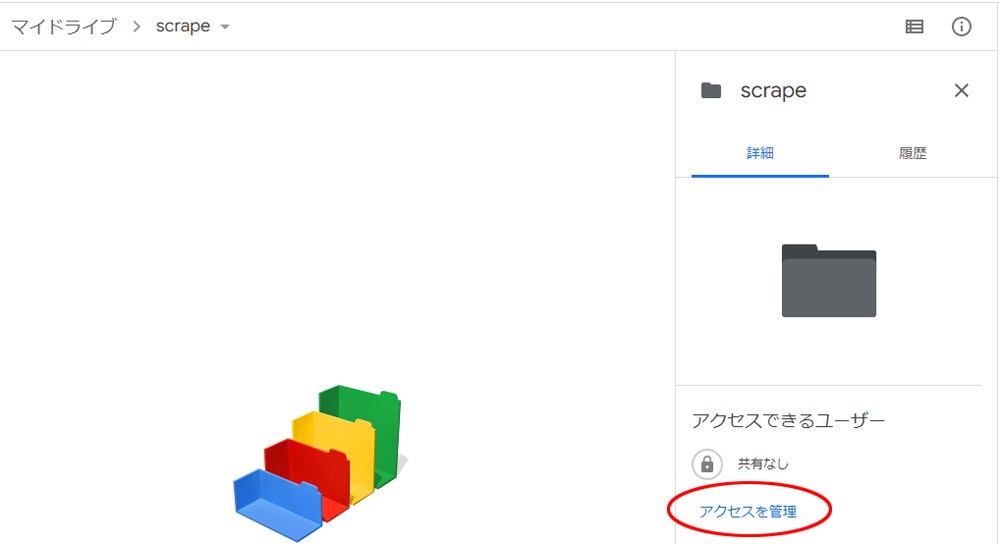
1. Google Drive にフォルダを作って開く
ここでは scrape というフォルダを作ります
2. アクセスを管理
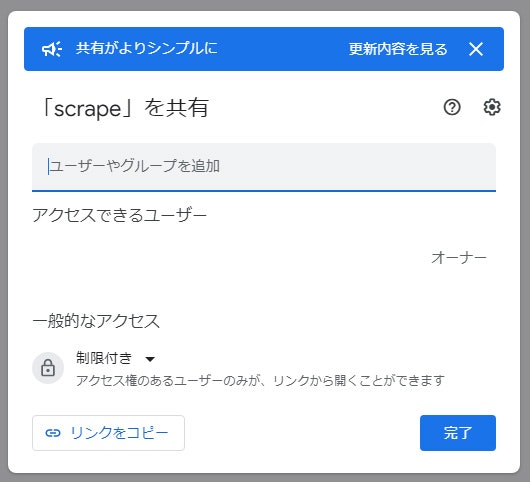
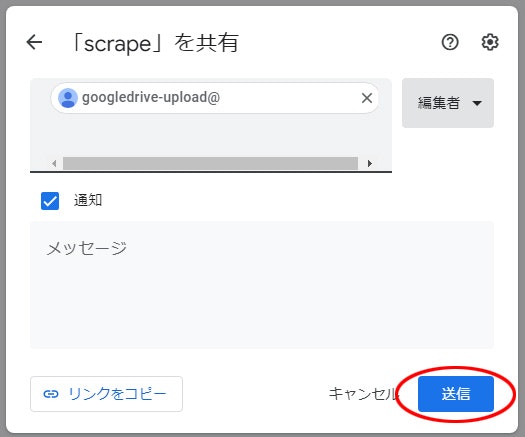
3. ユーザーやグループを追加 に ⑤ の 14. でコピーしたメールアドレスを貼り付ける
4. 送信
スクレイピング編
① Pythonファイルとjsonファイルのアップロード
1. Pythonファイルを用意
コピペですぐに使えるサンプルコード (折りたたみ)
-
folder_idをフォルダのURLへ変える必要がある https://drive.google.com/drive/folders/XXXXXXXXXXXXXXXXXXXX ← この部分だけ -
関数
ext_to_mimeはファイルの拡張子からMIMEタイプを返す処理
.pngと.csvだけ記述したので、必要に応じて以下のURLから探して追加すること- https://developer.mozilla.org/ja/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types
- https://github.com/google/google-drive-proxy/blob/master/DriveProxy/API/MimeType.cs
qiita.py# coding:utf-8 import glob import os import time from datetime import datetime import pandas as pd from google.oauth2 import service_account from googleapiclient.discovery import build from googleapiclient.errors import HttpError from googleapiclient.http import MediaFileUpload from selenium import webdriver from selenium.webdriver.chrome.options import Options from webdriver_manager.chrome import ChromeDriverManager def start(): """処理の開始時間 end() - start() で実行時間を測る """ global start_time start_time = time.time() def end(tag="経過時間"): """処理の終了時間 end() - start() で実行時間を測る """ if "start_time" in globals(): print("{}: {:.3f} [sec]".format(tag, time.time() - start_time)) else: print("start関数が呼ばれていない") def ext_to_mime(file_name): """`extension` -> `mime type` Returns : mime type """ ext = os.path.splitext(file_name)[1] if ext == ".csv": return "text/csv" elif ext == ".png": return "image/png" def upload_basic(upload_list): """Insert new file. Returns : Id's of the file uploaded Load pre-authorized user credentials from the environment. TODO(developer) - See https://developers.google.com/identity for guides on implementing OAuth2 for the application. """ creds = service_account.Credentials.from_service_account_file(f"{home_dir}/key.json") creds = creds.with_scopes(["https://www.googleapis.com/auth/drive"]) try: # create drive api client service = build("drive", "v3", credentials=creds) folder_id = "XXXXXXXXXXXXXXXXXXXX" mime_types = [ext_to_mime(file_name=file_name) for file_name in upload_list] for file_name, mime_type in zip(upload_list, mime_types): file_metadata = {"name": f"{file_name}", "parents": [folder_id]} media = MediaFileUpload(f"{home_dir}/{file_name}", mimetype=mime_type) # pylint: disable=maybe-no-member file = ( service.files().create(body=file_metadata, media_body=media, fields="id").execute() ) print(f'File ID: {file.get("id")}') except HttpError as error: print(f"An error occurred: {error}") if __name__ == "__main__": # 計測開始 start() # 保存先 home_dir = f"{os.path.expanduser('~')}/scrape" # fmt: off options = Options() options.add_argument('--blink-settings=imagesEnabled=false') # 画像の非表示 options.add_argument('--disable-blink-features=AutomationControlled') # navigator.webdriver=false とする設定 options.add_argument('--disable-browser-side-navigation') # Timed out receiving message from renderer: の修正 options.add_argument('--disable-dev-shm-usage') # ディスクのメモリスペースを使う options.add_argument('--disable-extensions') # すべての拡張機能を無効 options.add_argument('--disable-gpu') # GPUハードウェアアクセラレーションを無効 options.add_argument('--headless') # ヘッドレスモードで起動 options.add_argument('--incognito') # シークレットモードで起動 # fmt: on driver = webdriver.Chrome(ChromeDriverManager().install(), options=options) driver.implicitly_wait(10) # URL アクセス url = "https://qiita.com/kawagoe6884/items/cea239681bdcffe31828" driver.get(url) # 画像 保存 img = driver.find_element_by_tag_name("a") with open(f"{home_dir}/qiita.png", "wb") as f: f.write(img.screenshot_as_png) # DataFrame 作成 df = pd.read_html(driver.page_source)[0] # DataFrame 保存 filename = "qiita_table" today = datetime.today() month = datetime.strftime(today, "%Y%m") df.to_csv(f"{home_dir}/{filename}_{month}.csv", index=False, encoding="utf_8_sig") # driver 閉じる driver.quit() print("スクレイピング終了") # ファイルをアップロード upload_list = [] for f in glob.glob(f"{home_dir}/*"): if os.path.splitext(f)[1] != ".py" and os.path.splitext(f)[1] != ".json": upload_list.append(os.path.split(f)[1]) upload_basic(upload_list=upload_list) print("アップロード完了") # アップロードしたファイルを削除 for f in glob.glob(f"{home_dir}/*"): if f.split("/")[-1] in upload_list: os.remove(f) # 計測終了 end()
2. ⑤ の 13. でダウンロードしたjsonファイルを key.json へリネーム
※便宜上、key.json としただけで特に指定なし。
3. 2つのファイルをフォルダに入れる
scrape
├ key.json
└ qiita.py
4. 画面右下、さらに表示
5. アップロードを選択
6. アップロードするフォルダを選択
フォルダをアップロードする前にポップアップで確認される
7. フォルダをアップロード
8. コンソールに以下の1行を入力
scp -i ~/.ssh/my-ssh-key -P 3333 -r ~/scrape hogehoge@[外部 IP アドレス]:~/scrape
② スクレイピングしてみる
1. コンソールに以下の2行を入力
ssh -i ~/.ssh/my-ssh-key -p 3333 hogehoge@[外部 IP アドレス]
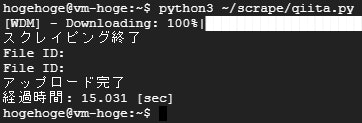
python3 ~/scrape/qiita.py
2. File ID: XXXXXXXXXXXXXXX が2回表示されていればアップロードできてます
エラーでつまったこと
-
scp のポート指定時は 大文字 -P、ssh のポート指定時は 小文字 -p
-
webdriver の '--headless' オプションの付け忘れ
The process started from chrome location /usr/bin/google-chrome is no longer running, so ChromeDriver is assuming that Chrome has crashed.というエラーが出て、seleniumが起動しない -
保存先のパス指定が間違っていた
qiita.py- with open(f"~/scrape/qiita.png", "wb") as f: + with open(f"{os.path.expanduser('~')}/scrape/qiita.png", "wb") as f:
- Chrome 起動
- スクレイピングしたいURLにアクセス
- 取得したデータを画像とCSVで保存
- Google Driveにアップロード
- アップロードしたファイルは削除
ここまでで一連の流れが完成したので、あとは定期実行。
メモ
-
6000を超えるページ(静的ページ) をスクレイピングしてみた結果
- かかった費用: 0円
- かかった時間:3時間20分
- CPU使用率は20%を推移、メモリ使用率は不明(Ops Agent入れると250MBくらいメモリ食われるってどこかで見た)
-
4000を超えるページ(動的ページ) をスクレイピングしてみた結果
- かかった費用: 0円
- かかった時間: 3時間
- CPU使用率は80%を推移、メモリ使用率は不明、1回だけCPU バーストした
- CPU バーストした理由は
print()のコメントアウトし忘れ。2万を超えるリストを print() したなので 実質0回
- CPU バーストした理由は
-
25000を超えるページ(静的ページ) をスクレイピングしてみた結果
- かかった費用: 19円
- かかった時間: 13時間30分
- CPU使用率は30%を推移、メモリ使用率は不明、1回だけCPU バーストした
- CPU バーストした理由は
df.to_csv()? 出力されたCSVが80MBもあったので書き込みにCPUパワーを使った可能性
- CPU バーストした理由は
無料枠のスペックでも十分やれそう。
- gspread でも似たようなことができる。ただ、ファイルが複数あるとその数だけスプレッドシートを用意しないといけない。事前設定・リクエスト回数制限・0落ち対策・画像の保存先は? 気にすべきことが多すぎる。
要はめんどい - Google Drive を Ubuntu にマウントする方法もあるらしい
- サンプルの
qiita.pyはservice.files().create()を使っているのでファイル名が重複していてもアップロードする。- 以下は、
新しい.txtを2回アップロードしたディレクトリの状態。新しい.txt新しい (2).txtとはならない。マイドライブ > フォルダ ├ 新しい.txt └ 新しい.txt - 新規アップロードではなく、更新をしたい場合は
service.files().update()を使う必要がある
参考サイト
- 以下は、
参考先