SPSS Modelerの決定木ノードのCARTをPythonで書き換えます。
0.データ
以下のようなデータを用いて決定木モデルを作ります。
目的変数
Credit_rating:信用リスク
説明変数
Age:年齢
Income:収入ランク
Credit_cards:クレジットカード枚数
Education:学歴
Car_loans:車のローン数
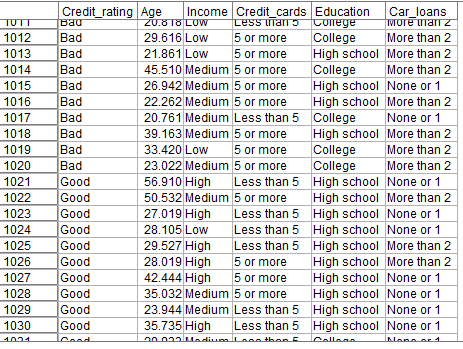
年齢や収入ランクから信用リスクを判定するモデルを作ります。
1m.①説明変数、目的変数の定義 Modeler版
まず、データ型ノードで説明変数、目的変数の定義を行う必要があります。
「値の読み込み」ボタンをクリックし、Credit_ratingのロールを「対象」(目的変数の意味)を設定します。Age、Income、Credit_cards、Education、Car_loansは「入力」(説明変数の意味)のままにします。

Modelerの決定木のモデル作成ノードはカテゴリ変数を数値型にコード化しなくてもそのままつかえますので、これで設定は終了です。
1p.①説明変数、目的変数の定義 scikit-learn版
PythonのScikit-LearnのDecisionTreeClassifierをつかって決定木のモデルを作成します。Sckit-LearnのDecisionTreeClassifierはカテゴリ変数を数値型のコード化しないと受け付けてくれず、「ValueError: could not convert string to float: 'More than 2'」のエラーになります。
そのため、カテゴリ変数の数値コード化をまず行う必要があります。
また、目的変数と説明変数は別の配列やDataframeに分ける必要があります。
まず目的変数の数値コード化し、配列を作ります。
from sklearn.preprocessing import LabelEncoder
# 目的変数のエンコード
le = LabelEncoder()
y = le.fit_transform(df['Credit_rating'].values)
print(le.classes_)
print(type(df['Credit_rating'].values))
print(type(y))
print(y)
数値コード化を行うLabelEncoderをインスタンス化し、fit_transformでnumpy配列を得ます。
「Bad」と「Good」というカテゴリ値が0と1に変換されています。
['Bad' 'Good']
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
[0 0 0 ... 1 1 1]
次に説明変数をコード化します。
import category_encoders as ce
# 説明変数のエンコード
ce_oe = ce.OrdinalEncoder(cols=['Income','Credit_cards', 'Education', 'Car_loans'],
handle_unknown='impute')
X = ce_oe.fit_transform(df)[['Age','Income', 'Credit_cards', 'Education', 'Car_loans']]
X.head()
ここではcategory_encodersのOrdinalEncoderをつかってカテゴリ変数の説明変数を数値化しました。もともと数値型で変換の不要なAgeを除いて、cols=['Income','Credit_cards', 'Education', 'Car_loans']を指定しています。
XにはAgeも含む説明変数のみのDataframeを入力しています。
'Income','Credit_cards', 'Education', 'Car_loans'が1や2という整数に置き換わっているのがわかります。

どのようにmappingが行われたのかはce_oe.mappingをみるとわかります。

例えば、Credit_cardsの「5 or more」は1、「Less than 5」は2にマッピングされていることがわかります。
しかし、Incomeのマッピングはイマイチよくありません。
Medium: 1
Low: 2
High: 3
とマッピングされていますので、Medium<Low<Highの順序なのです。このままでもモデルは作れますが、決定木がとても解釈しにくくなるので、Low<Medium<Highの順序に修正します。
# IncomeのエンコードがMedium<Low<Highの順序なのでLow<Medium<Highの順序に修正
ce_oe.mapping[0]['mapping']={None: 0, 'Low': 1, 'Medium': 2, 'High': 3}
pprint.pprint(ce_oe.mapping)
Incomeのマッピングが修正されました。
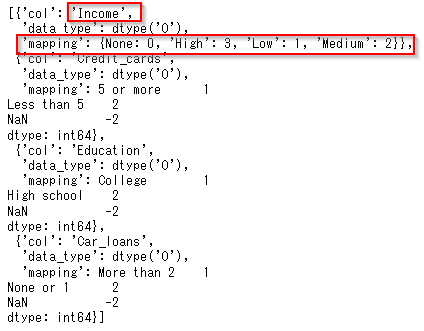
指定しなおしたIncomeのマッピングの記述方法が、自動生成されたものと異なりますが、以下のマニュアルを参考に設定しました。
修正したマッピングで変換しなおします。
X = ce_oe.fit_transform(df)[['Age','Income', 'Credit_cards', 'Education', 'Car_loans']]
X.head()

これで説明変数と目的変数の準備が終わりました。
Modelerと比較するとかなりややこしい処理が必要でした。
2m.②モデル作成 Modeler版
ModelerにはC&RTree(CART)、CHAID、C5.0、QUESTという4つの決定木のアルゴリズムが実装されています。一方ScikitLearnのDecisionTreeClassifierではCARTしか実装されていませんので、ここではCARTのモデル作成を行います。
C&R Treeのモデル作成ノードを接続します。そのまま実行してもモデルは作成できるのですが、ここではDecisionTreeClassifierとなるべく似た設定にします。オプションについての詳しい内容は4. オプション設定の違いにまとめました。
まず、「作成オプション」タブ「基本」項目の「過剰適合を回避するためにツリーを剪定」のチェックを外します。

もうひとつ、詳細設定項目の「オーバーフィット防止設定」を0にし、実行します。

モデルができたら、「編集」で中身を確認します。
「ビューア―」タブで「度数情報を表とグラフで表示」ボタンを押すと以下のようにツリーができます。
Incomeが「Medium」か「High」でCredit_cardsが「Less than 5」だとGoodが91.001%になっていることがわかります。

2p.②モデル作成 Sckit-Learn版
Sckit-LearnのCARTモデルはDecisionTreeClassifierで作ります。
max_depthなどのパラメーターはModelerのデフォルト値に近いもので指定しました。
fit(X, y)で説明変数と目的変数を与えてモデルを作成します。
# Cartモデル作成のパッケージ
from sklearn.tree import DecisionTreeClassifier
# モデル作成
clf = DecisionTreeClassifier(max_depth=5,min_samples_split=0.02,min_samples_leaf=0.01,min_impurity_decrease=0.0001)
clf = clf.fit(X, y)
可視化にはgraphvizを使っています。graphvizの導入については以下を参考にして導入しました。
Download | Graphviz
graphvizがインポートできない - Qiita
以下のコードで可視化します。
export_graphvizでモデルを指定して、dot_dataとして出力しています。
説明変数をfeature_names=['Age','Income', 'Credit_cards', 'Education', 'Car_loans']で指定します。
目的変数のラベルをle.classes_(中身は['Bad', 'Good'])で指定します。
# 下記は決定木可視化のためのツール
from sklearn.tree import export_graphviz
import graphviz
import pydotplus
from IPython.display import Image
from six import StringIO
# 決定木表示
dot_data = StringIO() #dotファイル情報の格納先
export_graphviz(clf, out_file=dot_data,
feature_names=['Age','Income', 'Credit_cards', 'Education', 'Car_loans'],
class_names=le.classes_,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
以下のような決定木のグラフが表示されます。Modelerでみた同じノードをたどると、
NOT Income<=1.5なので、IncomeがMedium(2),High(3)であり、
NOT Credit_cards<=1.5なので、Credit_cardsが「Less than 5」(2)の場合に648/712=91%がGoodだということがわかります。

Modelerの決定木のグラフとDecisionTreeClassifierの決定木のグラフの表示内容の対応を示しました。

まず、Not Credit_cards<=1.5なので2が含まれると判定し、Credit_cards=2は「Less than 5」を意味するというように、カテゴリ値を数値コード化してから、解釈しなければならないので、Modelerの決定木にくらべて圧倒的に読みづらいです。
また、パーセンテージも計算が必要ですし、棒グラフの表示がないため、直感的にどのノードや葉が重要なのかがわかりにくいグラフです。ただ色分けはされていて、この例だとGoodでは青、Badがオレンジになっています。また、gini係数が小さい(つまりBadとGoodの差が大きい)と色が濃くなるようになってはいます。
やはり読みやすさには大きな差があります。DecisionTreeClassifierでは次の分岐の条件がノードの上に来ているのも直感的ではなく分かりにくいと思います。
決定木は、データサイエンティストやITの専門家ではない現場の方にも理解可能なグラフですので、特に読みやすさは重要になります。
3m.③スコアリング Modeler版
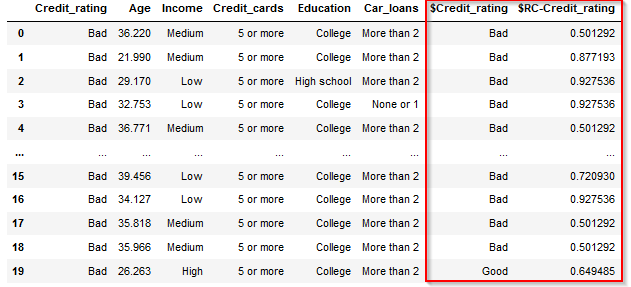
Modelerでのスコアリングはモデルナゲットにテーブルノードをつなげて実行するだけです。
2つ追加された列にスコアリング結果がはいります。$Credit_ratingに予測結果、$RC-Credit_ratingに予測の確信度が入ります。

3p.③スコアリング Sckit-Learn版
Sckit-learnでのスコアリングは.predict(説明変数のdataframe)で行い、結果はnumpyの配列で戻ります。また、この結果は数値コード化後の値です。
print(clf.predict(X))
print(type(clf.predict(X)))
[0 0 0 ... 1 1 1]
<class 'numpy.ndarray'>
Modelerの結果のように元のDataFrameに列で追加する場合は以下のようなコードになります。
le.inverse_transformで数値コードをカテゴリ値に戻しています。
df_pred = df.copy()
# 予測結果を追加
df_pred['$Credit_rating']=le.inverse_transform(clf.predict(X))
また確信度は.predict_proba(説明変数のdataframe)で行い、結果はやはりnumpyの配列が2次元で戻ります。2次元なのはBadとGoodでそれぞれの確信度を戻すためです。
print(clf.predict_proba(X))
print(type(clf.predict_proba(X)))
[[0.50129199 0.49870801]
[0.87719298 0.12280702]
[0.92753623 0.07246377]
...
[0.41304348 0.58695652]
[0.21296296 0.78703704]
[0.12 0.88 ]]
<class 'numpy.ndarray'>
Modelerの結果のように元のDataFrameに列で追加する場合は以下のようなコードになります。max(axis=1)を行うことでBadとGoodの大きい方を返すようにしています。
# 予測結果の確信度を追加
df_pred['$RC-Credit_rating']=clf.predict_proba(X).max(axis=1)
4. オプション設定の違い
ModelerとDecisionTreeClassifierのCARTのツリーを作る際のオプションを比較します。どちらかにしかない設定(NA項目)も多くありました。Modelerには「過剰適合を回避するためにツリーを剪定」や「オーバーフィット防止セット%」などのオーバーフィットを避けるためのオプションがより豊富です。
またデフォルト値についても、Modelerはオーバーフィットをさけるようなデフォルト値がとられているので、とりあえずデフォルトでも過学習しすぎないモデルができます。
一方でDecisionTreeClassifierはmax_depth=NONE,min_samples_split=2,min_samples_leaf=1という、最後の一件まで分割するような設定がデフォルトになっていて、ほぼ間違いなく過学習します。せめて今回設定を行ったような、max_depth=5,min_samples_split=0.02,min_samples_leaf=0.01くらいの設定はしないと使い物にならないと思います。
| Modeler | デフォルト | 今回の設定 | DecisionTreeClassifier | デフォルト | 今回の設定 |
|---|---|---|---|---|---|
| 最大ツリーの深さ | 5 | max_depth | None | 5 | |
| 過剰適合を回避するためにツリーを剪定 | オン | オフ | NA | ||
| リスク (標準誤差) の最大差を設定 | オフ | NA | |||
| 最大代理変数 | 5 | NA | |||
| 停止規則パーセンテージを使用親枝葉 | 2 | min_samples_split | オフ | 0.02 | |
| 停止規則パーセンテージを使用子枝葉 | 1 | min_samples_leaf | オフ | 0.01 | |
| 停止規則絶対値を使用親枝葉 | オフ | min_samples_split | 2 | ||
| 停止規則絶対値を使用子枝葉 | オフ | min_samples_leaf | 1 | ||
| 不純度の最小変化 | 0.0001 | min_impurity_decrease | 0 | 0.0001 | |
| カテゴリー対象の不純度の測度 | Gini | criterion | gini | ||
| オーバーフィット防止セット% | 30 | 0 | NA | ||
| NA | max_leaf_nodes | None |
なお、完全に同じ設定にすることはできず、今回のツリーも細かいところは異なっていて、DecisionTreeClassifierの方がより葉を伸ばしたツリーになっていました。
5. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/blob/mastercarttree/carttree2.str?raw=true
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/carttree/carttree3.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/tree_credit.csv
■テスト環境
Modeler 18.3
Windows 10 64bit
Python 3.8.10
pandas 1.0.5
sklearn 0.23.2
category_encoders 2.2.2
graphviz 0.17
6. 参考情報
ディシジョン・ツリー・ノード - 基本 - IBM Documentation
【機械学習】決定木をscikit-learnと数学の両方から理解する - Qiita
sklearn.tree.DecisionTreeClassifier — scikit-learn 0.24.2 documentation
Ordinal — Category Encoders 2.2.2 documentation