SPSS Modelerでサンプリングを行うのがサンプリングノードです。このサンプリングノードを解説するとともに、Pythonのpandasで書き換えてみます。
サンプリングには、①単純なサンプリングと、データの傾向を反映する②複雑なサンプリングとがあります。前回は①単純なサンプリングについて説明しました。今回は②複雑なサンプリングを説明します。
- ①単純なサンプリング
- ①-1. 先頭N件
- ①-2. ランダムサンプリング
- ②複雑なサンプリング ←今回の記事
- ②-1. 層化サンプリング
- ②-2. クラスターサンプリング
0.元データ
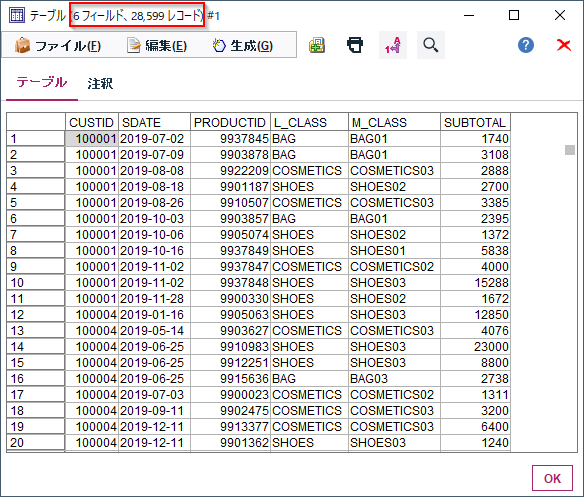
以下のID付POSデータを対象に行います。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
6フィールド、28,599件あります。
1m.②-1. 層化サンプリング Modeler版
ランダム・サンプリングは十分な件数があれば、全データの傾向を反映することができるサンプリング方法です。しかしながら、データの中には分布に大きな偏りがあって小さい割合でしか存在しないデータがあり得ます。そういうデータはサンプリング件数が小さいと傾向を反映できなくなる可能性があります。
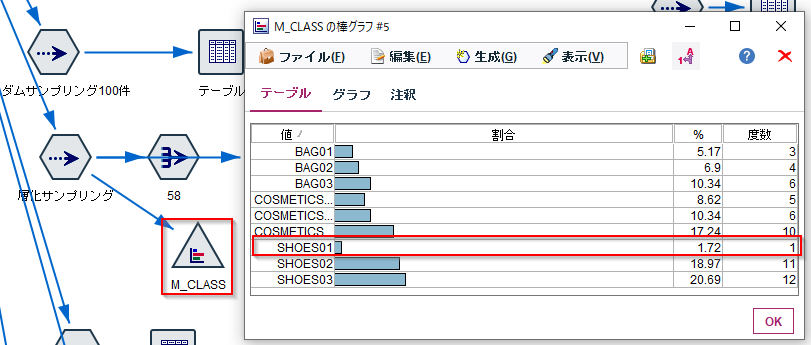
例えば今回のデータのM_CLASS(商品中分類)の分布をみてみます。
SHOES01の売上回数は631回で全体の2.21%ですので大きくありません。
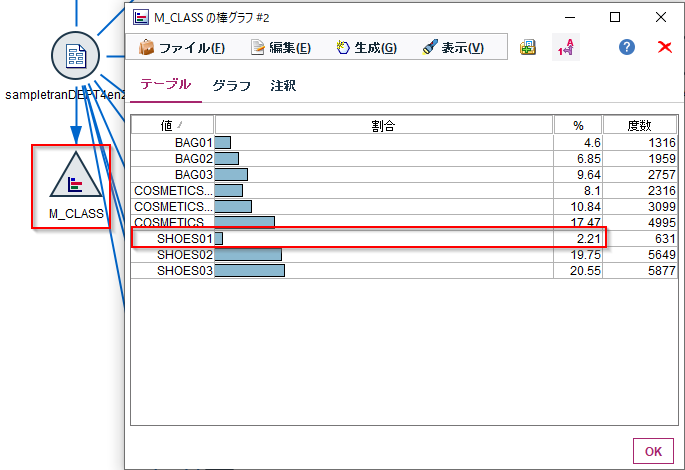
これを0.2%でサンプリングした結果のM_CLASS(商品中分類)の分布をみてみるとSHOES01がなくなってしまっています。また、他の項目も元の分布と違っています。

本来このような場合は、サンプリング数を増やすべきですが、検証用データなどで小さいサンプリングをせざるを得ない場合には、層化サンプリングが使えます。
これは層毎にデータをわけてサンプリングする方法です。この例ですとM_CLASS(商品中分類)の中分類毎にサンプリングするイメージになります。
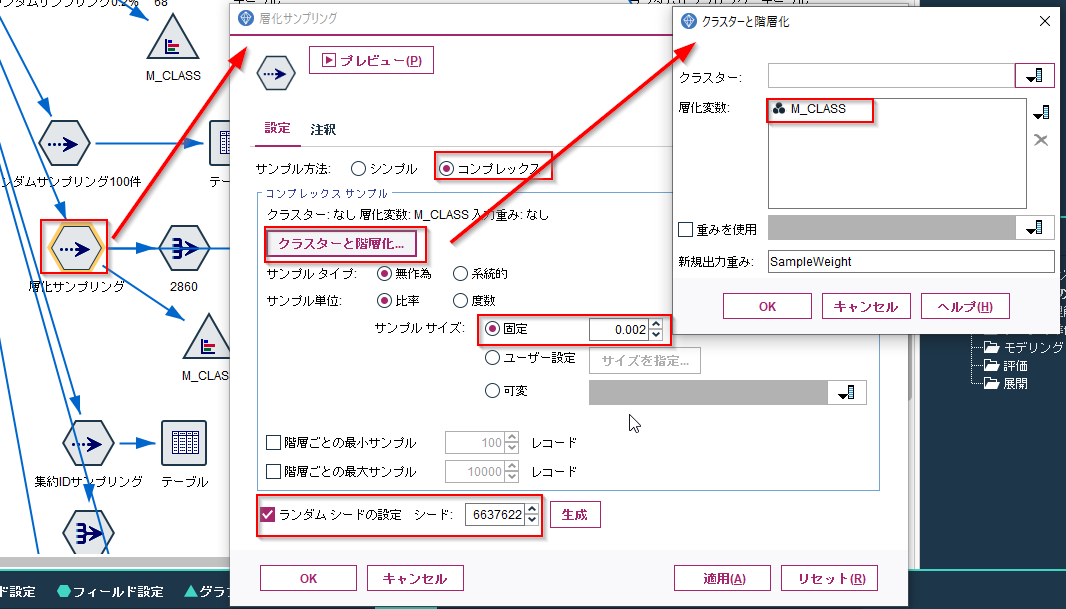
層化サンプリングもサンプリングノードで行います。
サンプル方法が「コンプレックス」になります。次に、サンプル・サイズを指定します。ここでは0.002(0.2%)を指定しています。
そしてクラスターと階層化のボタンをクリックすると層化変数を指定できます。ここでは層化変数としてM_CLASS(商品中分類)を指定しています。
また、サンプリングを再現できるようにランダムシードの設定にチェックをつけています。
結果にはSampleWeightという列ができていて、サンプリングする際に内部的に使われた重みが書き出されています。M_CLASS毎に同じ値になっていることがわかります。通常は不要なのでフィルターノードで除去してしまって構いません。
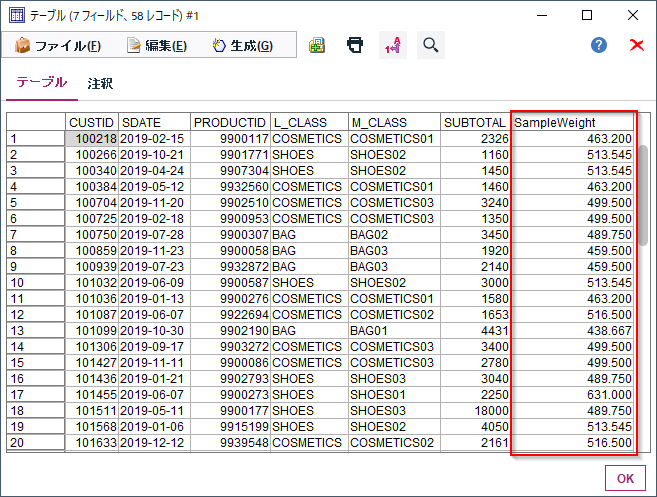
サンプリングした結果のM_CLASS(商品中分類)の分布をみてみるとSHOES01がありますし、もともとの全件に対する分布に近くなっています。
なお、層化サンプリングはSQLプッシュバックが効きません。紫色にはなり、層化する列の空文字を探しているようですが、サンプリング自体はSQLに変換されていません。
1p.②-1. 層化サンプリング pandas版
pandasで層化サンプリングを取得する場合はgroupbyとsample関数を使います。
まずgroupbyで’M_CLASS'毎にグループ化をします。
group_keys=Falseはマルチインデックスにしないようにしています。
そして各M_CLASSのデータの塊毎にlamda式をつかってsampleで0.2%のランダムサンプリングを実行しています。
Stratified_df=df.groupby('M_CLASS', group_keys=False)\
.apply(lambda x: x.sample(frac=0.002, random_state = 1))
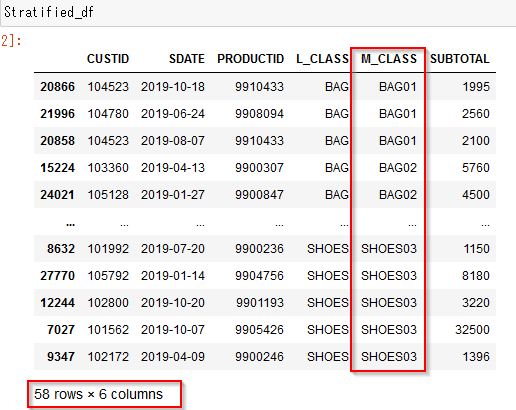
M_CLASS毎にグループ化されて、0.2%のデータになっています。
- 参考
- python-パンダの階層化サンプリング
- https://www.366service.com/jp/qa/2a7f0f8e735384ecbe3b386f1715396e
- python Pandasの層別サンプリング
- https://www.it-swarm-ja.tech/ja/python/pandas%E3%81%AE%E5%B1%A4%E5%88%A5%E3%82%B5%E3%83%B3%E3%83%97%E3%83%AA%E3%83%B3%E3%82%B0/832430095/
他にもStratifiedShuffleSplitを使う方法もあります。これは学習データとテストデータを分けるときに層化サンプリングを行うというオブジェクトです。
StratifiedShuffleSplitの引数のtrain_size やtest_size で学習データとテストデータのサンプリングサイズを決めています。random_stateはランダムシードです。本来は学習データとテストデータを分けるためのオブジェクトなので、必ずtrain_sizeとtest_sizeを決める必要があります。
インスタンス化されたsampleに対してsplit関数でDataframe(df)と層化したい列(df['M_CLASS'])を指定すると、学習データとテストデータのDataframeのindex(train_,test_)が返ります。
そこから新しいDataframe(StratifiedShuffleSplit_df)を作っています。
from sklearn.model_selection import StratifiedShuffleSplit
sample = StratifiedShuffleSplit(n_splits = 1,train_size = 0.002,test_size = 0.01, random_state = 1)
for train_,test_ in sample.split(df, df['M_CLASS']):
StratifiedShuffleSplit_ = df.loc[train_]
# chunk_test = df1.loc[test_]
- 参考
- scikit-learnのStratifiedShuffleSplitを使ってテストデータを作る方法
- https://www.randomlyforest.com/entry/2019/01/14/215102
- sklearn.model_selection.StratifiedShuffleSplit — scikit-learn
0.23.1 documentation - https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedShuffleSplit.html
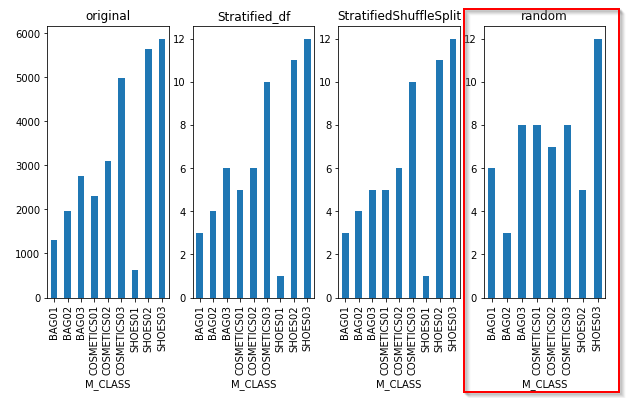
全件データとこれらの層化サンプリングをしたデータと単純ランダムサンプリングしたデータのM_CLASSの分布を比較すると、単純ランダムサンプリングしたデータはSHOES01がなくなっていますし、全件データの分布を反映できていないことがわかります。
2m.②-2. クラスターサンプリング Modeler版
今回のデータは購買トランザクションです。全体のデータからランダムサンプリングしてしまうと、各顧客の購入アイテムが間引かれてしまいます。一人当たりの購入回数や購入額は小さくなってしまいますし、「SHOESをよく買っている」人などの購入傾向がわからなくなってしまいます。全体のトランザクションの中で売れ筋商品は何かを分析することができますが、顧客軸で分析することには向かないデータになってしまいます。
このような場合には顧客IDのレベルでサンプリングするクラスターサンプリング(集約IDサンプリング)を行います。クラスターサンプリングを行うと、顧客IDでサンプリングして、抽出された顧客IDのトランザクションは保持されますので、顧客軸で分析することが可能です。
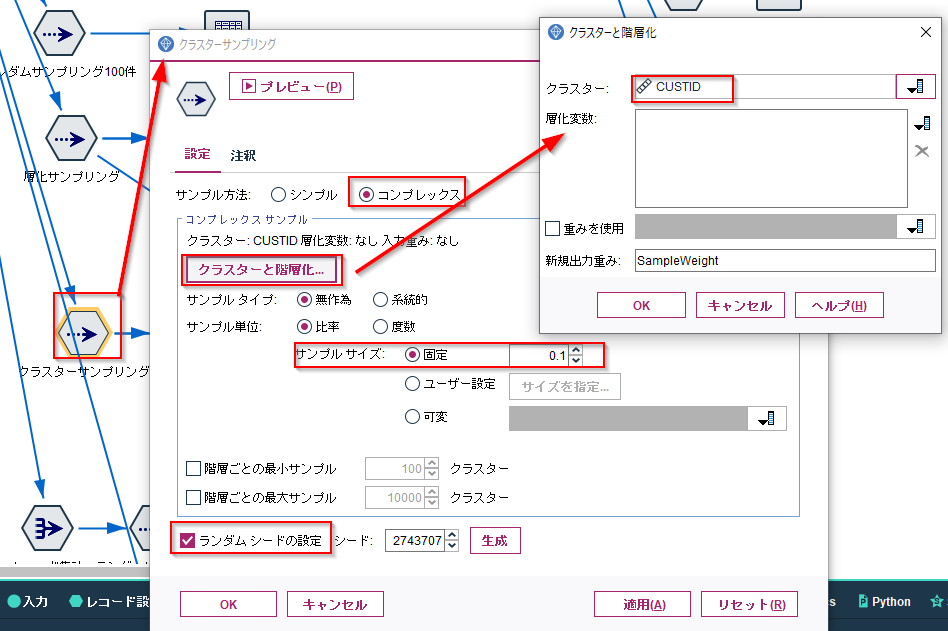
クラスターサンプリングもサンプリングノードで行います。
サンプル方法が「コンプレックス」、サンプル・サイズを指定します。ここでは0.1(10%)を指定しています。
そしてクラスターと階層化のボタンをクリックするとクラスターにする変数を指定できます。ここではクラスターとしてCUSTIDを指定しています。
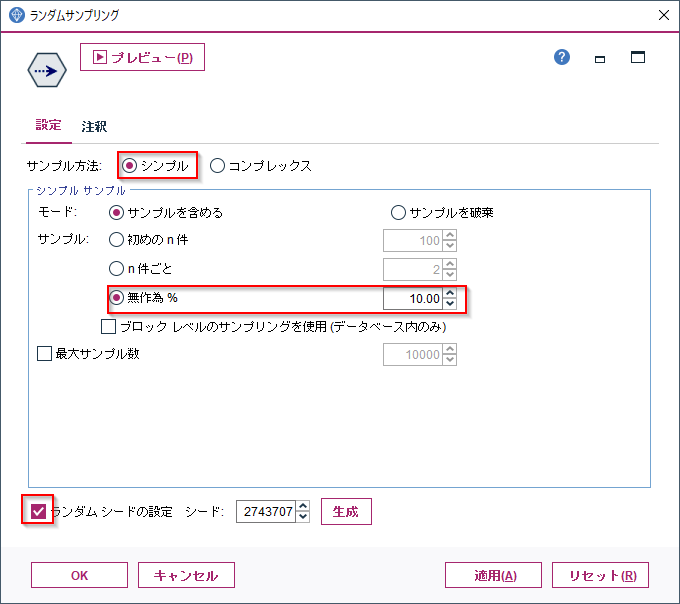
また、サンプリングを再現できるようにランダムシードの設定にチェックをつけています。
全CUSTIDの10%がランダムサンプリングされていて、抽出されたCUSTIDのトランザクションは保存されて、2652件が抽出されました。SampleWeightの列も追加されていますが、コンプレックス・サンプリングには使われていないと思います。
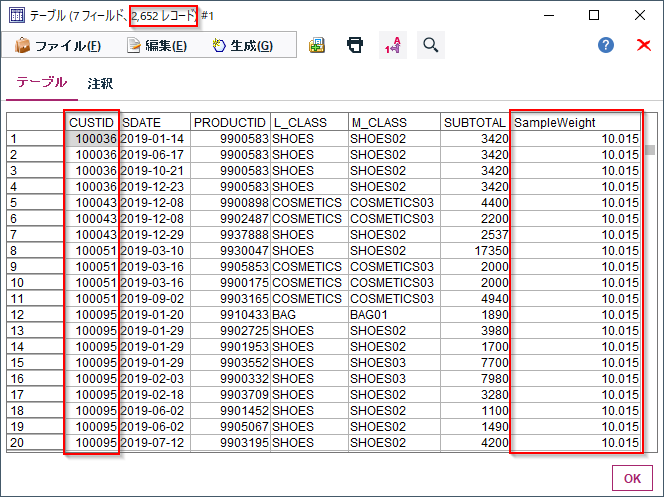
ただ、サンプリングノードの機能でクラスターサンプリングを行ってしまうとSQLプッシュバックが効きません。ですので、レコード集計とランダムサンプリングでCUSTIDをサンプリングしてから元データとJOINしなおすのがお勧めです。
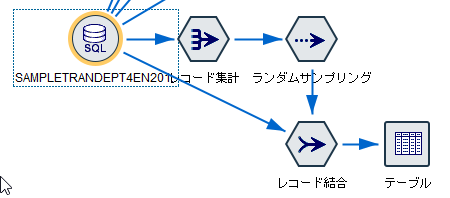
レコード集計でCUSTIDで一意のデータセットを作ります。
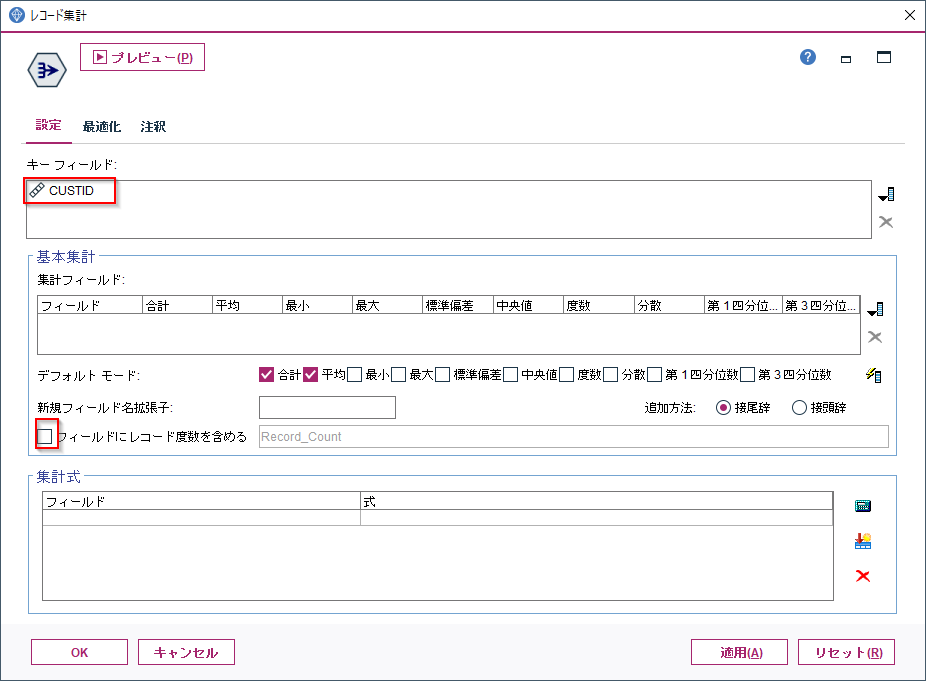
サンプル方法はシンプルで無作為%で10%を指定しています。
そして元データからトランザクションを結合します。
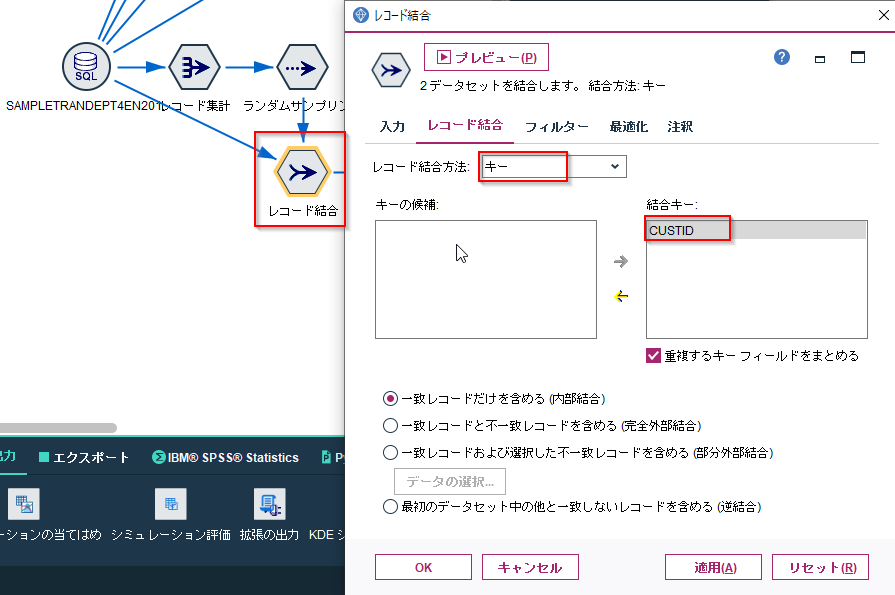
この方法だとSQLプッシュバックがおこなわれます。RAND(2743707) < 1.0000000000000001e-01)でランダムサンプリングが行われて、WHERE (T0.CUSTID = T1.CUSTID)でトランザクションが結合されています。
[2020-08-12 12:58:45] SQL をプレビュー中: SELECT T1.SDATE AS SDATE,T1.PRODUCTID AS PRODUCTID,T1."L_CLASS" AS "L_CLASS",T1."M_CLASS" AS "M_CLASS",T1.SUBTOTAL AS SUBTOTAL,T0.CUSTID AS CUSTID FROM ( SELECT T0.CUSTID AS CUSTID FROM (SELECT T0.CUSTID AS CUSTID FROM SAMPLETRANDEPT4EN2019S T0 GROUP BY T0.CUSTID) T0 WHERE RAND(2743707) < 1.0000000000000001e-01) T0,( SELECT T0.CUSTID AS CUSTID,T0.SDATE AS SDATE,T0.PRODUCTID AS PRODUCTID,T0."L_CLASS" AS "L_CLASS",T0."M_CLASS" AS "M_CLASS",T0.SUBTOTAL AS SUBTOTAL FROM SAMPLETRANDEPT4EN2019S T0) T1 WHERE (T0.CUSTID = T1.CUSTID)
2p.②-2. クラスターサンプリング pandas版
pandasでクラスターサンプリングする場合はunique、sample、isin関数を使います。Modelerで集計ノード、サンプリングノード、レコード結合ノードを使うのと同じ処理になります。
uniqueでCUSTIDが一意のレコード・セットを作ります。
sampleでランダムサンプリングをします。
isinで元のトランザクションからサンプリングされたCUSTIDだけを抽出します。
df_custid =pd.Series(df['CUSTID'].unique()).sample(frac=0.1,random_state=1)
df[df['CUSTID'].isin(df_custid)]
以下のようにクラスターサンプリングができます。
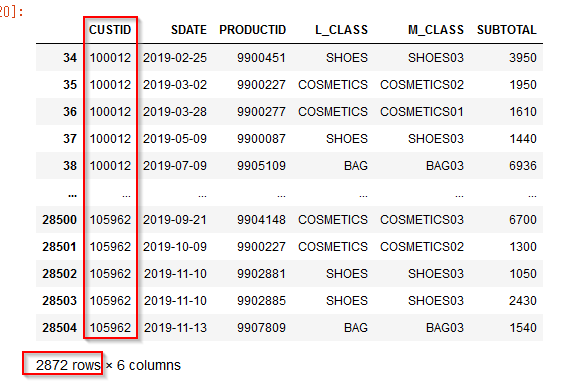
3. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/sample/sample.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/sample/sampling.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.2.1
Windows 10 64bit
Python 3.6.9
pandas 0.24.1
4. 参考情報
無作為抽出 - Wikipedia
https://ja.wikipedia.org/wiki/%E7%84%A1%E4%BD%9C%E7%82%BA%E6%8A%BD%E5%87%BA#%E7%B5%B1%E8%A8%88%E8%AA%BF%E6%9F%BB%E3%81%AB%E3%81%8A%E3%81%91%E3%82%8B%E7%84%A1%E4%BD%9C%E7%82%BA%E6%8A%BD%E5%87%BA%E3%81%AE%E6%89%8B%E6%B3%95
層化抽出法とクラスター抽出法の解説がわかりやすいです。