大量レコードのデータを扱う場合、分析処理には時間がかかります。そういう場合には、全件の中からサブセット(標本)をつくって、処理可能なサイズにしてから分析することはよくあります。
また、最終的には全件で分析をするとしても、小さなサブセットで処理を軽くして、下分析を行うこともよくあります。
このように全件のデータから小さな標本をつくることをサンプリング(標本抽出)といいます。
SPSS Modelerでこのサンプリングを行うのがサンプリングノードです。このサンプリングノードを解説するとともに、Pythonのpandasで書き換えてみます。
サンプリングには、①単純なサンプリングと、データの傾向を反映する②複雑なサンプリングとがあります。それぞれについて2回の記事にわけて説明します。
- ①単純なサンプリング ←今回の記事
- ①-1. 先頭N件
- ①-2. ランダムサンプリング
- ②複雑なサンプリング
- ②-1. 層化サンプリング
- ②-2. クラスターサンプリング
#0.元データ
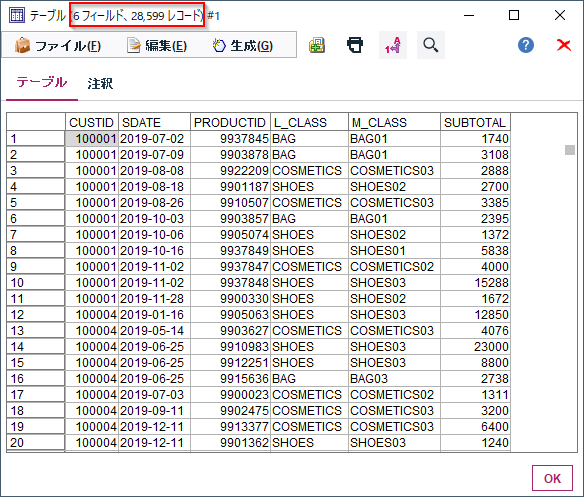
以下のID付POSデータを対象に行います。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。
6フィールド、28,599件あります。
#1m.①-1. 先頭N件Modeler版
先頭から100件を抽出します。これは非常に軽い処理です。大きいことがわかっているデータをプレビューするときにも役立ちます。Modelerのサンプリングのデフォルトモードです。
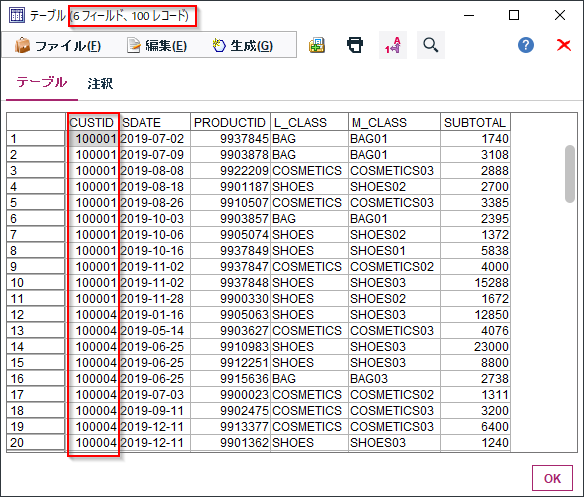
■加工後イメージ
順番はかわらず、100件が抽出されています。
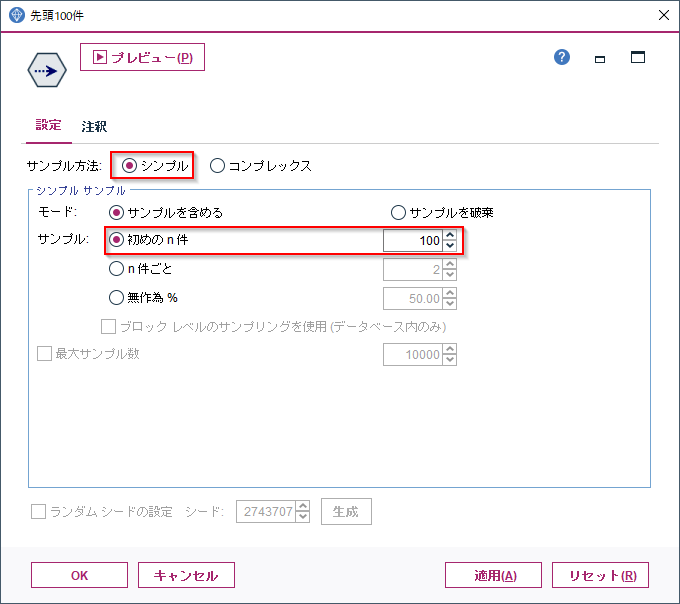
サンプリングノードを使います。

サンプル方法が「シンプル」、サンプルの方法として「初めのn件」で件数で100件を指定しています。
ちなみにサンプリングノードの「初めのn件」はSQLプッシュバックが効きます。以下はDb2に対してSQLプッシュバックを効かせた例です。FETCH FIRST 100 ROWS ONLYが使われています。
SELECT T0.CUSTID AS CUSTID,T0.SDATE AS SDATE,T0.PRODUCTID AS PRODUCTID,T0."L_CLASS" AS "L_CLASS",T0."M_CLASS" AS "M_CLASS",T0.SUBTOTAL AS SUBTOTAL FROM (SELECT T0.CUSTID AS CUSTID,T0.SDATE AS SDATE,T0.PRODUCTID AS PRODUCTID,T0."L_CLASS" AS "L_CLASS",T0."M_CLASS" AS "M_CLASS",T0.SUBTOTAL AS SUBTOTAL FROM SAMPLETRANDEPT4EN2019S T0 FETCH FIRST 100 ROWS ONLY) T0
なお、ファイル入力の場合、「初めのn件」は繰り返し実行した場合に毎回同じ結果が返ってきます。しかしRDBは順序の保証はしませんので、必ず同じ結果が返るとは限りません。もし、同じ結果を保証したい場合にはソートノードなどをいれて順番を固定してからサンプリングノードを使ってください。
#1p.①-1. 先頭N件 pandas版
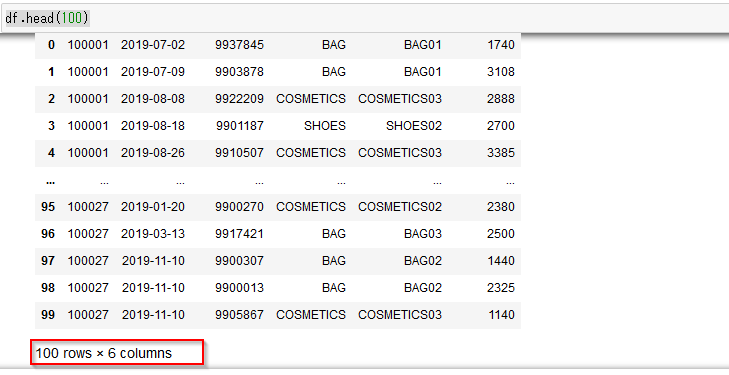
pandasで先頭N件を取得する場合はhead関数を使います。
df.head(100)
#2m.①-2. ランダムサンプリング Modeler版
全件から無作為にn%を抽出します。
先頭N件のサンプリングは、もともとのデータが順序によって特に偏った傾向がなければ軽くてよい方法です。しかし、一般的にはデータは発生順によって記録されていることが多く、発生順によってデータの傾向が違うことはよくあります。例えば1日分のデータなら、朝と夜でデータの傾向が違うということはありえるということです。
こういう問題に対応できるのがランダムサンプリング(単純無作為抽出法)で、もっとも一般的なサンプリング方法です。
この処理は全レコードに対してサイコロをふっていくイメージになりますので、データ量が多い場合にはそれなりに重い処理になりますので注意が必要です。
やはりサンプリングノードで行います。
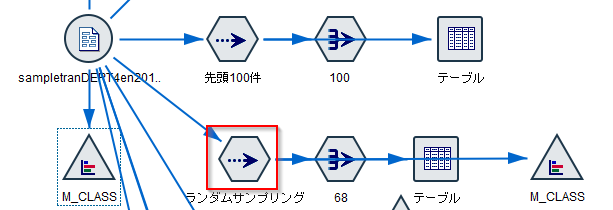
サンプル方法が「シンプル」、サンプルの方法として「無作為%」で0.2%を指定しています。
また、ランダムシードの設定にチェックをつけています。このチェックをつけることで、繰り返してサンプリングを実行した際に同じ結果が返ります。データが変わると分析が不安定になるので、通常はチェックを付けます。サンプリング結果を変えたい場合にはシードの生成ボタンをクリックして、シードを変えると次回のサンプリング結果が変わります。
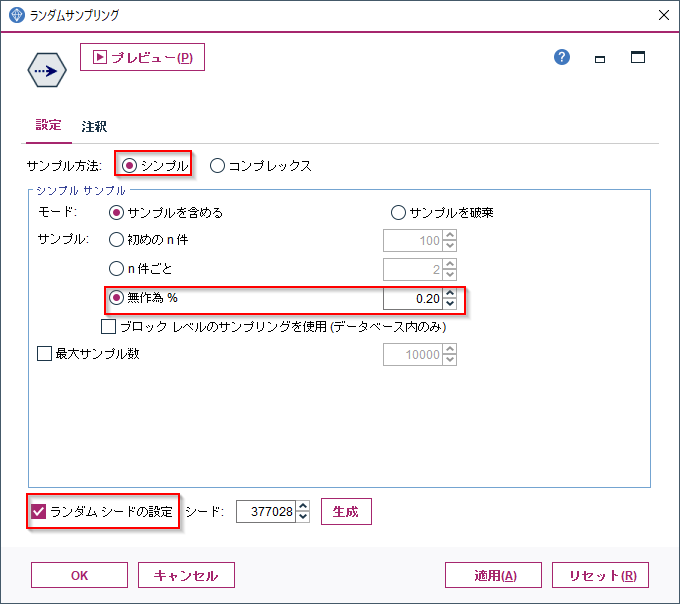
■加工後イメージ
無作為に0.2%を抽出しました。
28,599件から68件が抽出されました。先頭N件と異なり、先頭にいた100001の顧客のデータは選ばれていませんし、各顧客のトランザクションもまばらに選ばれています。
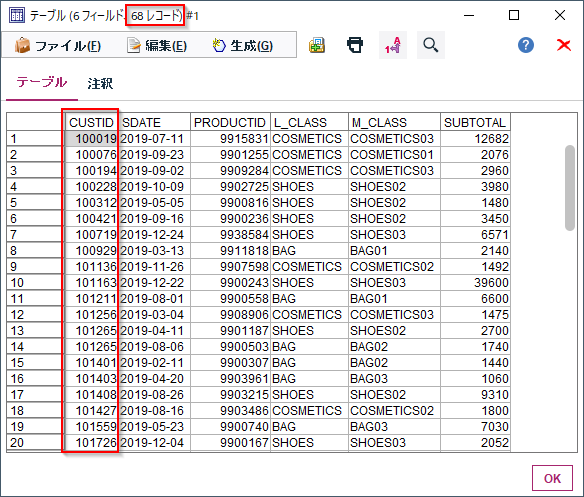
ちなみにサンプリングノードの「無作為%」はSQLプッシュバックが効きます。以下はDb2に対してSQLプッシュバックを効かせた例です。BERNOULLI(0.200000) REPEATABLE(377028)が使われています。RDBによっては違う方法が使われるかもしれません。特にシードに対応していない(サンプリング結果の再現性がない)RDBもありそうな気がします。
SELECT T0.CUSTID AS CUSTID,T0.SDATE AS SDATE,T0.PRODUCTID AS PRODUCTID,T0."L_CLASS" AS "L_CLASS",T0."M_CLASS" AS "M_CLASS",T0.SUBTOTAL AS SUBTOTAL FROM (SELECT T0.CUSTID AS CUSTID,T0.SDATE AS SDATE,T0.PRODUCTID AS PRODUCTID,T0."L_CLASS" AS "L_CLASS",T0."M_CLASS" AS "M_CLASS",T0.SUBTOTAL AS SUBTOTAL FROM SAMPLETRANDEPT4EN2019S T0 TABLESAMPLE BERNOULLI(0.200000) REPEATABLE(377028)) T0
なお、先ほども指摘したようにランダムサンプリングは全件を処理する重い処理になる可能性があるので、サンプリング結果をキャッシュしたり、いったんファイルやテーブルに出力したほうが、その後の分析を効率的に行えます。
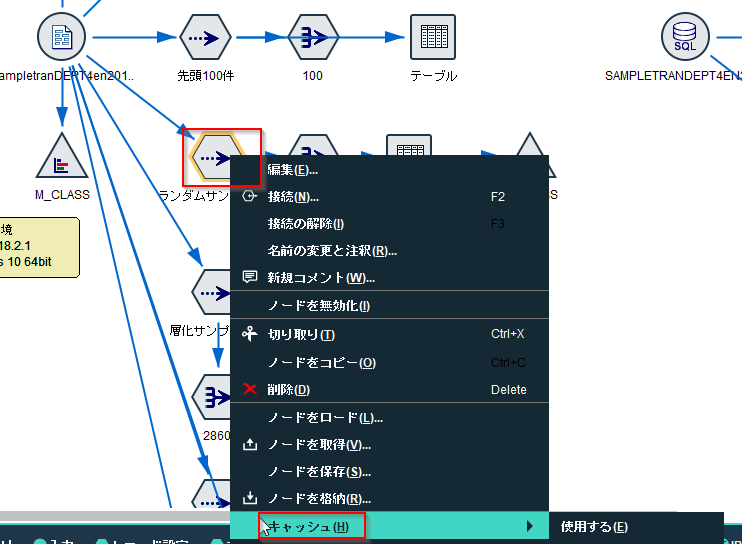
また、件数を決めてランダムサンプリングをしたいこともあるかもしれません。
その場合は(サンプリング件数)/(総件数)100分率で割合を計算してセットしてください。このデータで100件分のランダムサンプリングをしたい場合は100/28599100=0.349%になります。
無作為の%を0.35にセットし、さらに最大数を100に指定すると100件以内で制限されます。
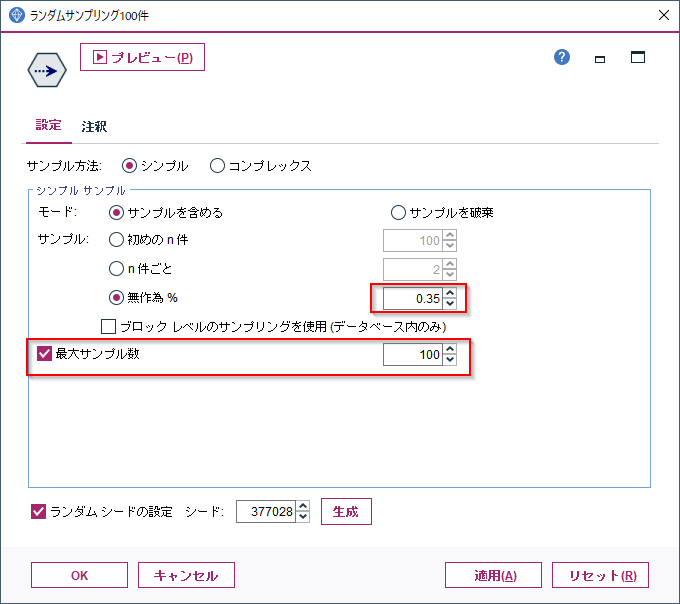
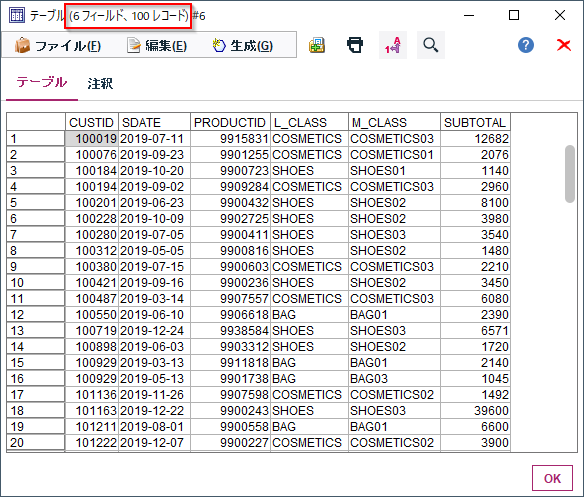
■加工後イメージ
100件のランダムサンプリングができました。
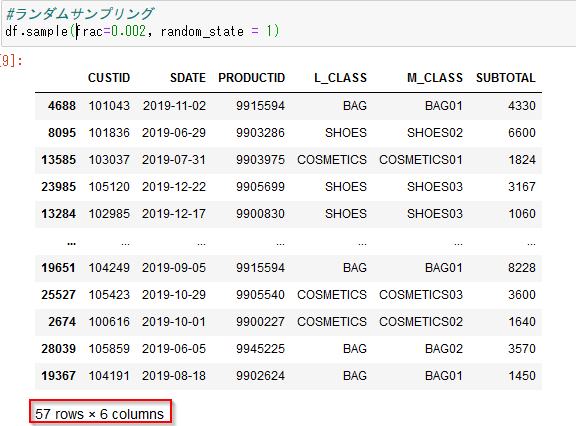
#2p.①-2. ランダムサンプリング pandas版
pandasでランダムサンプリングを取得する場合はsample関数を使います。
fracで割合を設定します。100分率ではなく小数です(1が100%)。ここでは0.2%を指定しています。
random_stateでランダムシードを指定します。
df.sample(frac=0.002, random_state = 1)
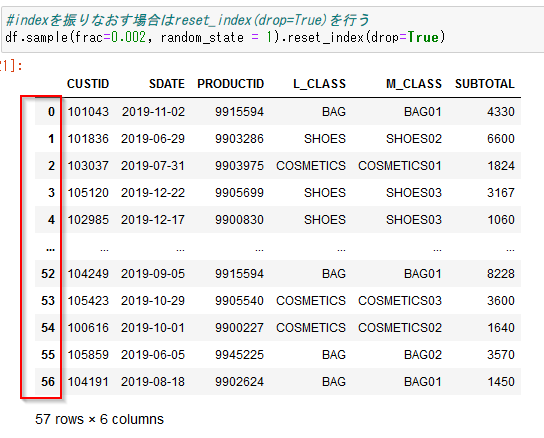
なお、indexを振りなおす場合はreset_index(drop=True)を行います。
df.sample(frac=0.002, random_state = 1).reset_index(drop=True)
件数指定の場合はfracではなくnで指定します。
df.sample(n=100, random_state = 1)
#3. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/sample/sample.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/sample/sampling.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv
■テスト環境
Modeler 18.2.1
Windows 10 64bit
Python 3.6.9
pandas 0.24.1
#4. 参考情報
サンプリング・ノード
https://www.ibm.com/support/knowledgecenter/ja/SS3RA7_18.2.1/modeler_mainhelp_client_ddita/clementine/mainwindow_navigationstreamsoutputtab.html