JSONファイルをpandasのデータフレームに変換したいことがあります。pd.read_jsonというメソッドがありますが、JSONファイルはネスト構造になっていたり、リストを含んでいたり、読み出しルートが違ったりとpd.read_jsonでは望む形に変換できないことがあります。
この記事では
①シンプルな構造のJSON
②ネスト構造のJSON
③ネスト構造とリストを含むJSON
④ルートが読み出しルートではないJSON
という4つのパターンのJSONで読み方を検討し、最終的にはすべてのパターンに対応できるスクリプトを用意しました。
サンプル・ノートブック
サンプル・データ
①シンプルな構造のJSONの読込
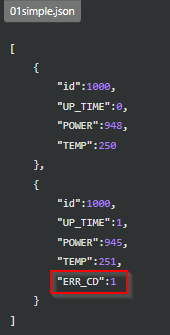
以下のようなシンプルなJSONはpd.read_jsonで読むことができます。
[
{
"id":1000,
"UP_TIME":0,
"POWER":948,
"TEMP":250
},
{
"id":1000,
"UP_TIME":1,
"POWER":945,
"TEMP":251,
"ERR_CD":1
}
]
import pandas as pd
jsonfile='01simple.json'
df=pd.read_json(jsonfile)
ERR_CDは2レコード目にしか存在しませんが、ちゃんと列が用意されています。

②ネスト構造を持つJSONの読込
次のデータはidの下にM_CDとUP_TIMEという2つのデータがぶら下がっています。
[
{
"id":{
"M_CD":1000,
"UP_TIME":0
},
"sensor":{"POWER":948,
"TEMP":250
}
},
{
"id":{
"M_CD":1000,
"UP_TIME":1
},
"sensor":{"POWER":945,
"TEMP":251
},
"code":{
"ERR_CD":1
}
}
]
このように辞書が入れ子構造になってノーマライズされていないJSONもpd.read_jsonを使って読むことはできますが、列の中に辞書構造が残ってしまいます。
以下のようにidという列の中に{'M_CD': 1000, 'UP_TIME': 0}の辞書構造が入っていて、テーブルとして扱いにくい形になります。

そこで、いったんjson.loadで配列に読み出してから、pd.json_normalizeを行います。
import json
jsonfile='02notnormal.json'
with open(jsonfile, encoding='utf-8') as f:
d = json.load(f)
#ノーマライズ
df=pd.json_normalize(d)
これによって、以下のネストされた辞書構造をもつ「id」をid.M_CDとid.UP_TIMEの2列に切り出しています。


参考:PandasでJSON形式の列データを複数列に展開する - そうなんでげす
③ネスト構造とリストを含むJSONのフラット化
次のデータは、ネスト化された辞書があるだけではなく、さらにcodeの下にERR_CDとMESSAGEのデータがリストで複数含まれています。
[
{
"id":{
"M_CD":1000,
"UP_TIME":0
},
"sensor":{"POWER":948,
"TEMP":250
}
},
{
"id":{
"M_CD":1000,
"UP_TIME":1
},
"sensor":{"POWER":945,
"TEMP":251
},
"code":[
{
"ERR_CD":1,
"MESSAGE":"part1"
}
]
},
{
"id":{
"M_CD":1000,
"UP_TIME":2
},
"sensor":{"POWER":943,
"TEMP":255
},
"code":[
{
"ERR_CD":2,
"MESSAGE":"part2"
},
{
"ERR_CD":3,
"MESSAGE":"part3"
}
]
}
]
このようなリスト構造を持つJSONはpd.json_normalizeを使っても、リストのまま列に入ります。

リストの展開の仕方には縦持と横持があり得ますが、ここでは横持に変換してみます。
# 入力JSONファイル名
import pandas as pd
import json
from collections import MutableMapping
jsonfile = '03list.json'
# 列をフラット化する際の区切り文字
sep = '.'
# フラット化
def flatten(d, parent_key='', sep='.'):
items = []
for k, v in d.items():
#列名の生成
new_key = parent_key + sep + k if parent_key else k
# 辞書型項目のフラット化
if isinstance(v, dict):
items.extend(flatten(v, new_key, sep=sep).items())
# リスト項目のフラット化
elif isinstance(v, list):
new_key_tmp = new_key
for i, elm in enumerate(v):
new_key = new_key_tmp + sep + str(i)
# リストの中の辞書
if isinstance(elm, dict):
items.extend(flatten(elm, new_key, sep=sep).items())
# 単なるリスト
else:
items.append((new_key, elm))
# 値追加
else:
items.append((new_key, v))
return dict(items)
# JSONファイルを読込
with open(jsonfile, encoding='utf-8') as f:
d = json.load(f)
# フラット化
dlist = []
for di in d:
dlist.append(flatten(di, sep=sep))
# print(dlist)
df = pd.DataFrame.from_dict(dlist)
スクリプトの解説
少し長いので分割して解説します。
まず、json.loadでJSONファイルを辞書型のリストとして読み込みます。
そして1レコード事にフラット化処理するユーザー定義関数flattenを呼び出します。
# JSONファイルを読込
with open(jsonfile, encoding='utf-8') as f:
d = json.load(f)
# フラット化
dlist = []
for di in d:
dlist.append(flatten(di, sep=sep))
ユーザー定義関数flattenの中を見ていきます。
以下で列名を作っています。
idの下にM_CDがある場合は「id.M_CD」という列名になります。
new_key = parent_key + sep + k if parent_key else k
以下で辞書型項目をフラット化しています。flattenを再帰呼び出しすることで深い階層構造を下っていき、extendを使うことでフラット化しています。
if isinstance(v, dict):
items.extend(flatten(v, new_key, sep=sep).items())
このコードで以下のようにネストされた辞書があるJSONをフラットにしています。json_normalizeで行ったことと同じです。
"id":{
"M_CD":1000,
"UP_TIME":0
},
'id.M_CD': 1000, 'id.UP_TIME': 0
次に、以下でリスト項目をフラット化しています。このスクリプトの肝の部分です。
まずnew_key = new_key_tmp + sep + str(i)でリストの出現順に連番を振った列名を生成しています。
リスト内に辞書構造がある場合にはflattenを再帰呼び出しをしています。
単なるリストの場合にはappendで新規列として追加しています。
elif isinstance(v, list):
new_key_tmp = new_key
for i, elm in enumerate(v):
new_key = new_key_tmp + sep + str(i)
# リストの中の辞書
if isinstance(elm, dict):
items.extend(flatten(elm, new_key, sep=sep).items())
# 単なるリスト
else:
items.append((new_key, elm))
このコードで以下のようにリスト内に辞書があるJSONをフラットにしています。
"code":[
{
"ERR_CD":2,
"MESSAGE":"part2"
},
{
"ERR_CD":3,
"MESSAGE":"part3"
}
]
'code.0.ERR_CD': 2, 'code.0.MESSAGE': 'part2', 'code.1.ERR_CD': 3, 'code.1.MESSAGE': 'part3'
最後にフラット化された辞書をpandasデータフレームに変換しています。
df = pd.DataFrame.from_dict(dlist)
最終的に'code.0.ERR_CD', 'code.0.MESSAGE', 'code.1.ERR_CD', 'code.1.MESSAGE'の4つの列としてフラット化されました。


参考:python - How to flatten multilevel/nested JSON? - Stack Overflow
④ルートが読み出しルートではないJSONの読込
特に、REST APIでJSONデータを取得した場合の多くは、今まで見てきたようなリスト化されたJSONデータだけではなく、ヘッダーのような情報と組み合わせた一つの辞書型構造のデータであることが多いと思います。
例えば以下のようなJSONです。total_rowsという文書全体の属性をあらわすヘッダー的な項目があり、実際のデータはrowsの中のリストとして含まれています。
{"total_rows":3,"rows":
[
{
"id":{
"M_CD":1000,
"UP_TIME":0
},
"sensor":{"POWER":948,
"TEMP":250
}
},
{
"id":{
"M_CD":1000,
"UP_TIME":1
},
"sensor":{"POWER":945,
"TEMP":251
},
"code":[
{
"ERR_CD":1,
"MESSAGE":"part1"
}
]
},
{
"id":{
"M_CD":1000,
"UP_TIME":2
},
"sensor":{"POWER":943,
"TEMP":255
},
"code":[
{
"ERR_CD":2,
"MESSAGE":"part2"
},
{
"ERR_CD":3,
"MESSAGE":"part3"
}
]
}
]
}
このようなデータをpd.read_jsonで読むと3行には展開されますが、ネスト化された辞書が展開されません。
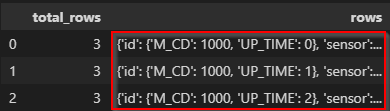
また、pd.json_normalizeで読んだ場合は、1行になり、rows内のリストがそのままになります。

#3で作成したユーザー定義関数のflattenをつかっても、すべて一行に展開されてしまいます。

この場合pandasデータフレーム化したいルート項目(この例では「rows」)から展開させる工夫が必要です。
d = d[rowsroot]で読み出したいルート項目を指定しています。この例では「rowsroot = "rows"」です。
jsonfile = '04notroot.json'
rowsroot = "rows"
# JSONファイルを読込
with open(jsonfile, encoding='utf-8') as f:
d = json.load(f)
# df化したい辞書リストのルート項目を指定
if rowsroot != '':
d = d[rowsroot]
# フラット化
dlist = []
for di in d:
dlist.append(flatten(di, sep=sep))
# フラット化された辞書をpandasデータフレームに変換
df = pd.DataFrame.from_dict(dlist)
これでヘッダー部分の"total_rows":3が無視されて、rows内のデータのみがフラットなpandasデータフレームとして出力できました。


JSONファイルのpandasDF化関数(完成版)
③と④のスクリプトをまとめて、JSONファイルを読み込んでpandas DataFrame化する関数が完成しました。
①から④のすべてを処理できます。
import pandas as pd
import json
# フラット化
def flatten(d, parent_key='', sep='.'):
items = []
for k, v in d.items():
# 列名の生成
new_key = parent_key + sep + k if parent_key else k
# 辞書型項目のフラット化
if isinstance(v, dict):
items.extend(flatten(v, new_key, sep=sep).items())
# リスト項目のフラット化
elif isinstance(v, list):
new_key_tmp = new_key
for i, elm in enumerate(v):
new_key = new_key_tmp + sep + str(i)
# リストの中の辞書
if isinstance(elm, dict):
items.extend(flatten(elm, new_key, sep=sep).items())
# 単なるリスト
else:
items.append((new_key, elm))
# 値追加
else:
items.append((new_key, v))
return dict(items)
def flattenJsonFile(jsonfile, rowsroot, sep='.'):
"""
JSONファイルを読み込み2次元のpandas DataFrameに変換する
Parameters
----------
jsonfile : string
JSONファイルパス
rowsroot : string
フラット化するルートエレメント名。トップからでいい場合は空文字を入力する
sep : string
ノーマライズされていないエレメントを区切る文字
Returns
-------
df : pandas.DataFrame
フラット化されたpandas DataFrame
"""
# JSONファイルを読込
with open(jsonfile, encoding='utf-8') as f:
d = json.load(f)
# df化したい辞書リストのルート項目を指定
if rowsroot != '':
d = d[rowsroot]
# フラット化
dlist = []
for di in d:
dlist.append(flatten(di, sep=sep))
# フラット化された辞書をpandasデータフレームに変換
return pd.DataFrame.from_dict(dlist)

この関数で幅広いパターンに対応できることがわかりました。ただし、リストのフラット化まではしたくないというような場合には②まででやめておくようなことも考える必要があると思います。