SPSS Modelerで目的変数のレコード数に不均衡がある場合にそのバランスをそろえるのがバランス・ノードです。
このバランス・ノードを解説するとともに、Pythonのpandasで書き換えてみます。
0.元データ
ここではローン審査での、顧客の属性と判定したリスクの入ったデータを使います。Riskが1の場合はリスクの高い顧客、0はリスクの低い顧客を示しています。
CustID:顧客番号
Age:年齢
Car_loans:車のローンランク
Credit_cards:クレジットカード利用ランク
Education:教育ランク
Income:収入ランク
Risk:リスクありなし
500件あります。

Riskの1と0のレコード件数を比較するとRisk=1のレコードは全体の25%、Risk=0のレコードは75%で、アンバランスになっていることがわかります。
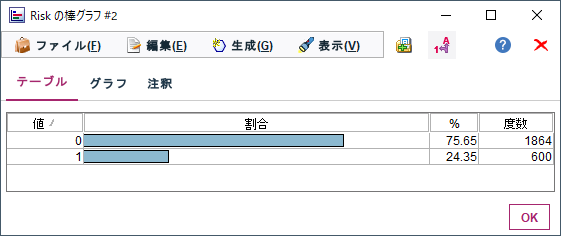
通常こういうデータでRisk予測モデルを作る場合は、Riskがある人を予測したいのですが、仮にすべてをRiskなしと予測しても75%の精度で予測ができ、Riskなしと予想しがちなモデルができてしまいます。
これを避けるために、Riskありとなしのレコードのバランスをとるのがバランス・ノードです。
1m.①アンダーサンプリング Modeler版
バランス・ノードは単体で使うこともできますが、棒グラフノードから作るのが一般的です。
まずRiskで棒グラフを作成します。
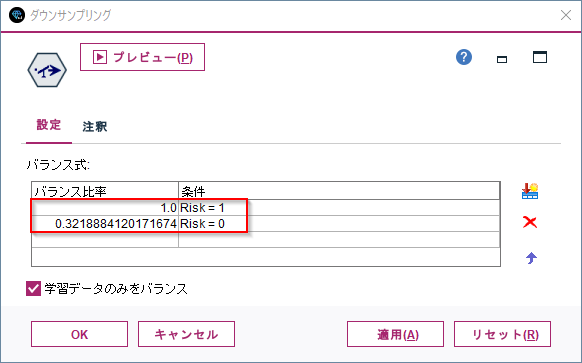
グラフができたら、生成メニューから「バランスノード(減少)」を選びます。
そうするとバランスノードがキャンバスに追加されます。
中身を見るとRisk=1の時には1倍なのでそのまま、Risk=0の時には約0.3倍のレコード数にするというバランス比率が定義されます。
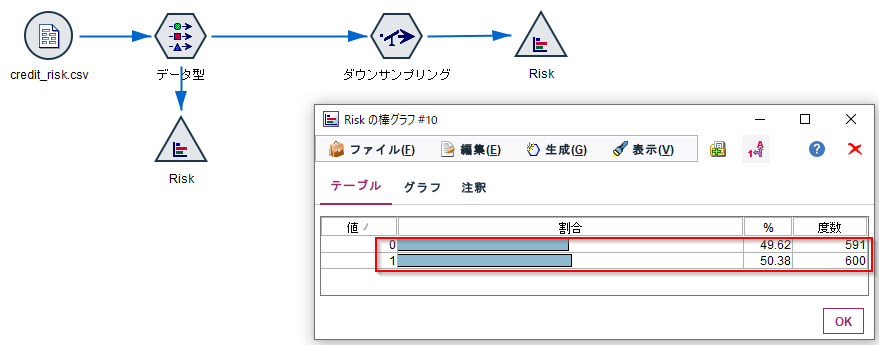
このサンプリングノードを接続したうえで、改めて棒グラフノードで結果を確認すると、Risk=0のデータが約1/3になって、ほぼ同数のレコード数になりました。
注意点はランダムシードが設定できないので、毎回結果が変わってしまうことです。ですので、キャッシュしてキャッシュデータを保存しておくか、エクスポートノードでファイルやDBのテーブルに出力しておくことをお勧めします。

1p.①アンダーサンプリング pandas版
pandasでアンバランスデータの修正を行う場合はimblearnを使います。pipやcondaを使って導入しておきます。
# pip
pip install imbalanced-learn
# conda
conda install -c conda-forge imbalanced-learn
imblearnを使うためには、以下のように説明変数のデータフレームと目的変数のデータフレームに分割しておく必要があります。
df_x=df.drop(['Risk'],axis=1)
df_y=df[['Risk']]
件数とその棒グラフを表示してみます。
df_risk=df_y.groupby('Risk').size()
print(df_risk)
df_risk.plot.bar()

では、このデータをアンダーサンプリングしてみます。
RandomUnderSamplerをImportし、random_stateでランダムシードを指定してインスタンス化します。
その上で説明変数のデータフレームと目的変数のデータフレームを引数にfit_resampleを実行するとアンダーサンプリングされた説明変数のデータフレームと目的変数のデータフレームが戻ります。
from imblearn.under_sampling import RandomUnderSampler
sampler = RandomUnderSampler(random_state=1)
x_resampled, y_resampled = sampler.fit_resample(df_x,df_y)
件数とその棒グラフを表示してみます。どちらも600件と同数になっているのがわかります。
df_risk=df_y.groupby('Risk').size()
print(df_risk)
df_risk.plot.bar()

2m.②オーバーサンプリング Modeler版
先ほどはRiskありの600件に合わせてRiskなしのレコードを減らすアンダーサンプリングをしましたが、Riskありのレコード件数を増やすオーバーサンプリングも可能です。
棒グラフの生成メニューから「バランスノード(増加)」を選びます。

中身を見るとRisk=0の時には1倍なのでそのまま、Risk=1の時には約3倍のレコード数にするというバランス比率が定義されます。
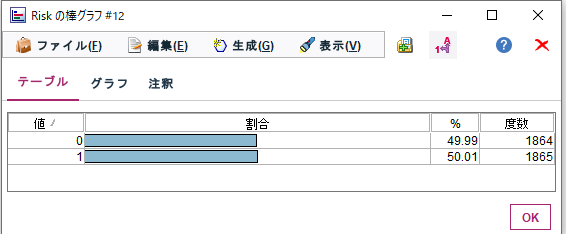
棒グラフで結果を見ると以下のようにRisk=1のレコードが3倍に増えて、同数程度になっていることがわかります。
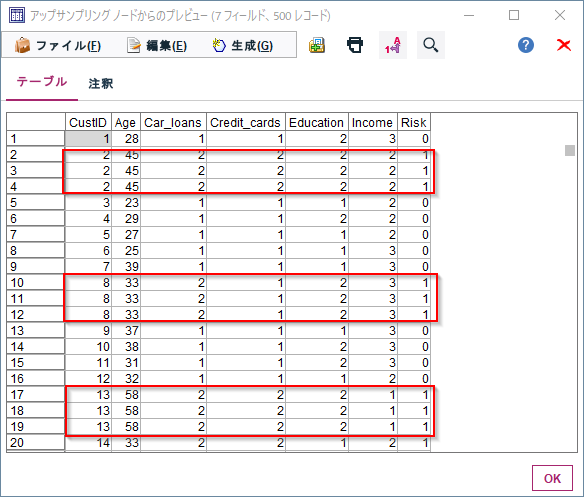
データをみるとRisk=1のレコードが約3倍に重複していることがわかります。
2p.②オーバーサンプリング pandas版
pandasでオーバーサンプリングする場合はRandomOverSamplerを使います。使い方はRandomUnderSamplerと同じです。
from imblearn.over_sampling import RandomOverSampler
sampler = RandomOverSampler(random_state=1)
x_resampled, y_resampled = sampler.fit_resample(df_x,df_y)
Risk=1が増えて同数になったことがわかります。

3. 補足
オーバーサンプリングにはSMOTEという方法もあります。SMOTEは単にデータをコピーするのではなく、似たデータを生成します。
【リレー連載】わたしの推しノード –機械学習時代の申し子「SMOTEノード」が不均衡データの壁を突破する | IBM ソリューション ブログ
ModelerにはSMOTEノードがあります。imbalanced-learnでもSMOTEが可能です。
SMOTE — Version 0.8.0
4. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/balance/balance3.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/balance/balance.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/credit_risk.csv
■テスト環境
Modeler 18.3
Windows 10 64bit
Python 3.8.5
pandas 1.0.5
imblearn 0.7.0
5. 参考情報
Python: 機械学習における不均衡データの問題点と対処法について - CUBE SUGAR CONTAINER
バランス・ノード - IBM Documentation
imbalanced-learn API reference — Version 0.8.0