テキスト文書からキーワードにフラグを立てる(形態素解析)

1.想定される利用目的
・アンケート結果や業務日誌などのテキストデータを分析に活用する。
・Modeler 18.0以前のバージョンでテキスト分析の機能で分かち書きを行っていた場合の代替案
2.サンプルストリームのダウンロード
サンプルストリーム
サンプルデータ
- テスト環境
- SPSS Modeler 18.4
- Windows 11 64bit
- Python 3.8.10
- numpy 1.23.5
- janome 0.5.0
この加工ではpythonの拡張ノードを使います。事前に以下の記事を参考に拡張ノードでPythonを利用可能な設定を行っておいてください。また、pipなどでjanomeを導入しておいてください。
SPSS Modelerの拡張ノードでPythonを利用する(ミニマム設定)
3.サンプルストリームの説明

a.入力するデータは以下の通りです。
この[レビュー]列を形態素解析してキーワード抽出します。

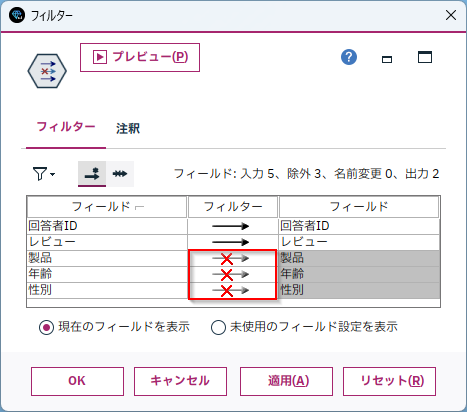
b.[フィルター]ノードを編集します。
ここではわかりやすくするために[回答者ID]と[レビュー]の列のみを残しています(必須ではありません)。
c.[拡張の変換]ノードを利用して、形態素解析をします。
[Python for Spark]を選び[Pythonのシンタックス]に以下のpythonコードを入力します。

#ライブラリのインポート
import spss.pyspark.runtime
from pyspark.sql.types import *
import numpy as np
#janomeを利用
import janome
from janome.tokenizer import Tokenizer
print(np.version.version)
print(janome.__version__)
# コンテキストオブジェクト定義
cxt = spss.pyspark.runtime.getContext()
# 形態素解析関数
def getTokens(row):
# 元行を保存
org = tuple([x for x in row])
# 「レビュー」列を分かち書き
t = Tokenizer()
tokens=t.tokenize(row["レビュー"])
# 名詞、動詞、形容詞、形容動詞を抜き出し
words = [token.base_form for token in tokens \
if token.part_of_speech.split(",")[0] in ["名詞","動詞","形容詞","形容動詞"]]
# 元行に分かち書きしたデータを縦持ちにして追加
res = []
for word in words:
res.append(org + (word,))
return(res)
if cxt.isComputeDataModelOnly():
#スキーマ設定。「Words」という新しい列を追加
inputSchema = cxt.getSparkInputSchema()
outputSchema = StructType(inputSchema.fields \
+ [StructField('Words', StringType(), True)])
cxt.setSparkOutputSchema(outputSchema)
else:
#データ読込
df_in = cxt.getSparkInputData()
#形態素解析
df_out = df_in.rdd.flatMap(getTokens).toDF()
#データ書出し
cxt.setSparkOutputData(df_out)
プレビューをすると[Words]という新しい列ができており、分かち書きされた言葉が抽出されています。また、元のデータは[回答者ID]で一意でしたが、抽出された行数分出力されています。下の例ですと、[回答者ID]=1のレコードは[小さい][軽い]の2レコードになっています。

次からこのデータを横持データに変換します。
d.[データ型]ノードで[値の読み込み]をクリックし、[Words]をインスタンス化します。
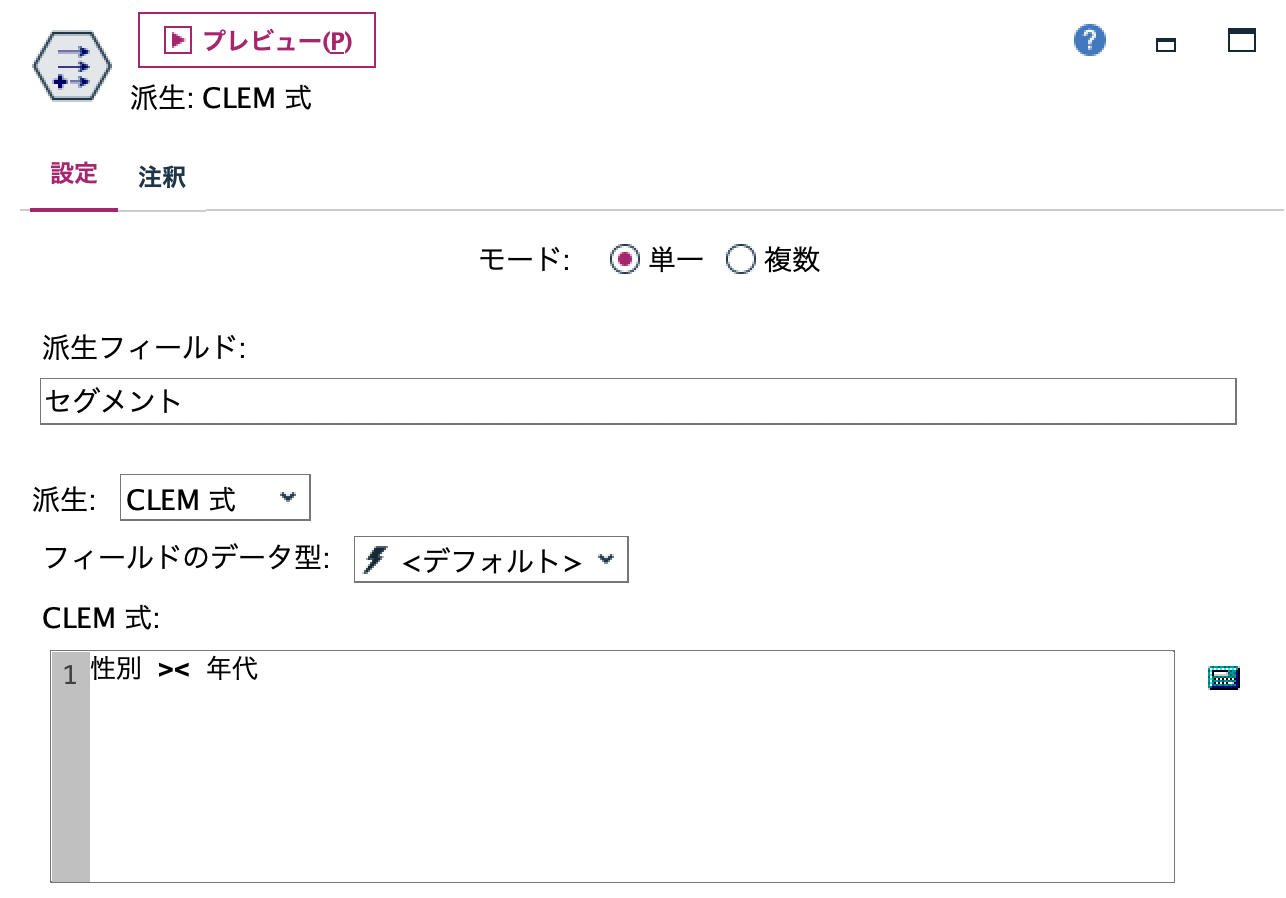
なお、尺度が[名義型]ではなく[不明]になった場合は、[Words]の種類が250を超えています。この記事にあるように[ツール]>[ストリームのプロパティ]>[オプション]から以下の[名義型の最大メンバー]を256以上に変更します。
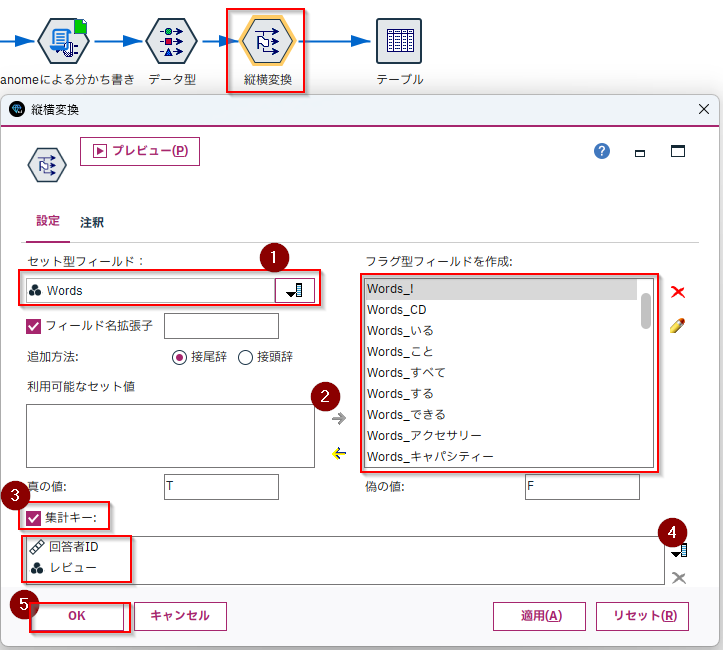
e.[フラグ設定]ノードで縦横変換します。
[セット型フィールド]に[Words]を選択します。
[利用可能なセット値]を[→]ですべて[フラグ型フィールドを作成]のボックスにうつします(欲しいキーワードだけに絞ってもかまいません)。
[集計キー]にチェックをします。
[回答者ID]と[レビュー]を選択します。
これで[回答者ID](と[レビュー]で)で1レコードになります。
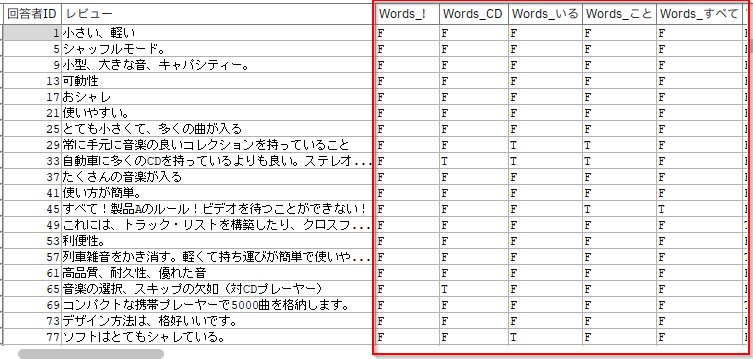
f.[テーブル]を確認します。
レビュー内のキーワードにフラグが立てられたことがわかります。
注意事項
- 単なるフラグではなく、出現回数にする場合には[再構成]ノードと[集計]ノードで件数にすることもできます。
- 単なるフラグではなく、重みも付けたい場合は、TF-IDF、Word2VecなどをつかったPythonコードにすることもできます。
- データソースがRDBの場合、CLOB型はModelerでは読み出せませんので、VARCHAR型への変換が必要です。
4.pythonコードの解説
Pythonコードを少し解説します。
分かち書きしたい列を業務に合わせて変更したり、抜き出したい品詞を選んで修正して利用してください。
def getTokens(row)という関数で形態素解析を行っています。
以下で、[回答者ID]の[レビュー]の列を取り出しています。
org = tuple([x for x in row])
以下で、[レビュー]列を分かち書き(トークン化)しています。
例えば、「小さい、軽い」というテキストから「小さい」と「軽い」の2つの語(トークン)
を抜き出しています。
t = Tokenizer()
tokens=t.tokenize(row["レビュー"])
以下は抜き出した語から名詞、動詞、形容詞、形容動詞のみを選んでいます。逆にいうと副詞、助詞、記号などは捨てています。用途に合わせて、抜き出したい品詞を選んでください。
また、token.base_formで活用されていない基本形(原形)を取り出しています。そのため「おシャレ」が「シャレる」という語(トークン)として抜き出されています。これは活用によってバリエーションが増え過ぎしまうとカテゴリ型として意味がなくなる可能性があるために行っています。
words = [token.base_form for token in tokens \
if token.part_of_speech.split(",")[0] in ["名詞","動詞","形容詞","形容動詞"]]
参考:Python, Janomeで日本語の形態素解析、分かち書き(単語分割)
「words」変数に抜き出した語(トークン)が入っていますので、元行と一語ずつをつなげて、1行にして出力しています。
このため、[回答者ID]=1のレコードが[小さい][軽い]の2レコードになります。
res = []
for word in words:
res.append(org + (word,))
5.参考情報
【リレー連載】わたしの推しノード – 一流エージェント「拡張ノード」。必要なタレントは外から連れてくれば良い! | IBM ソリューション ブログ
この記事は上の千代田さんの記事のPythonコードを利用しています。
janomeマニュアル
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)