キーワードやモチーフからアニメを作れたら楽しいのに!と思ったので、ChatGPTやOpenAIの画像生成などを用いて、紙芝居アニメを作成するツールを作ってみました。
今回もツールを使用する時のみ、実行したらいいので、Google colabを使用します。
手順は以下です。
- Cloud Text-to-Speech APIの有効化
- キーワードから動画を生成するプログラムを実行する
1. Cloud Text-to-Speech APIの有効化
Cloud Text-to-Speech APIの有効化の手順は以下です。
- Google Cloud Console にアクセスし、プロジェクトを作成または選択します。
- Cloud Text-to-Speech APIページに移動し、「有効にする」をクリックして API を有効化します。この際、Cloud Text-to-Speech APIの有効化にはクレジットカードの登録が必要です。
- 必要に応じて同意画面を設定します。
- 画面左側のメニューから「認証情報」をクリックし、「認証情報を作成」を選択して「サービスアカウント」をクリックして、必要事項を記入してサービスアカウントを作成します。
- 作成したサービスアカウントの編集ページを開いて、キーのタブを開いて、JSONのキーを作成してダウンロードします。
- 作成したサービスアカウントのキーをGoogle colabで使用するアカウントのGoogleドライブに入れます。
2. キーワードから動画を生成するプログラムを実行する
まず、Google colabで新規ノートブックを開き、Google colabからGoogle ドライブにアクセスして、サービスアカウントのキーを読み込めるように以下の操作を行います。
ファイルを開く
写真の赤枠のマークを押す。

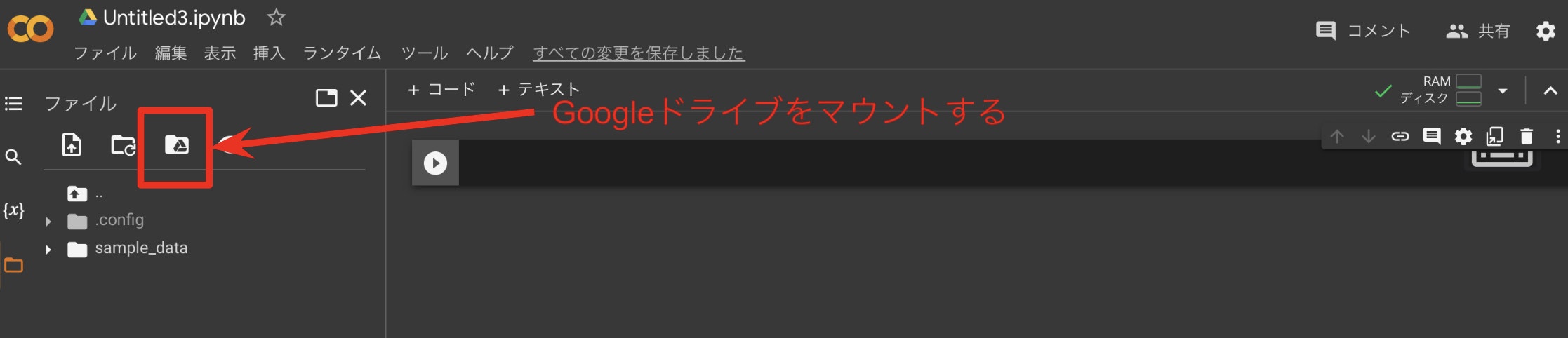
Googleドライブをマウントする
写真の赤枠のマークを押す。メニューが開いたら、ドライブに接続を押す。
次に、以下をインストールします。
!pip install --upgrade pip
!pip install setuptools wheel
!pip install google-api-python-client google-auth google-auth-httplib2 google-auth-oauthlib google-cloud-texttospeech moviepy requests openai
最後に、先程Googleドライブに入れたサービスアカウントのキーのパス、openai APIのキーをコードに入れてから、実行します。
import openai
import os
import time
import urllib.request
from google.cloud import texttospeech
from moviepy.editor import ImageClip, AudioFileClip, concatenate_videoclips
# キーの設定
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "/path/to/your/service-account-file.json"
openai.api_key = 'your-api-key'
# Google Text-to-Speech クライアントの作成
client = texttospeech.TextToSpeechClient()
# 使用するテキスト
user_input = input("作りたい物語は?: ")
# プロローグとエピローグのメッセージ
prologue_message = "このページはプロローグです。以下の物語のはじまりのみ書いてください。物語を完結させず、物語の起点となるシーンを設定してください。ページの説明などのメタ情報は不要です。物語のみを生成してください。"
epilogue_message = "このページはエピローグです。以下に続く物語の終わりを書いてください。前のページの続きを書いて、物語をこのページで完結させてください。ページの説明などのメタ情報は不要です。物語のみを生成してください。"
# 保存するディレクトリの作成
directory = './temp_folder'
if not os.path.exists(directory):
os.makedirs(directory)
summaries = []
# ChatGPTによる物語生成
for i in range(10): # 10ページ分のループ
filename = f'page_{i+1:02}.txt'
filepath = os.path.join(directory, filename)
if i == 0: # プロローグ
system_message = prologue_message
assistant_message = ""
else: # 2ページ目から最終ページの前まで
# 現在の要約の取得
current_summary = '\n'.join(summaries)
summary_message = "以下の内容を300文字以内で要約してください: " + current_summary
# ChatGPTによる要約の生成
summary_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": summary_message},
],
max_tokens=300 # 出力を300トークンに制限
)
# 生成された要約を保存
summary = summary_response["choices"][0]["message"]["content"]
summaries.append(summary)
# 5秒間待つ
time.sleep(5)
# 前のページの内容を読み込む
with open(previous_filepath, 'r') as file:
previous_page = file.read()
assistant_message = "これまでの要約: " + summaries[-1] + "\n" + "前のページ: " + previous_page
system_message = f"このページは10ページ中のページ{i+1}です。前のページの続きを書いて、物語を進行させてください。物語をこのページで完結させず、次のページへの接続点を残してください。同じシーンを繰り返さないようにしてください。ページの説明などのメタ情報は不要です。物語のみを生成してください。"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_message},
{"role": "assistant", "content": assistant_message},
{"role": "user", "content": user_input},
]
)
# レスポンスの保存
assistant_response = response["choices"][0]["message"]["content"]
with open(filepath, 'w') as file:
file.write(assistant_response)
# 5秒間待つ
time.sleep(5)
# 次のループのための準備
previous_filepath = filepath
# 画像を保存するディレクトリの作成
img_directory = './temp_folder_images'
if not os.path.exists(img_directory):
os.makedirs(img_directory)
# 各ページからキーワードを取得し、画像を生成
for i in range(10): # 10ページ分のループ
filename = f'page_{i+1:02}.txt'
filepath = os.path.join(directory, filename)
with open(filepath, 'r') as file:
text = file.read()
# キーワードの取得
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "以下からキーワードをピックアップして英訳して単語区切りで.を入れてください。"},
{"role": "user", "content": text},
],
max_tokens=50 # 出力を50トークンに制限
)
keywords = response["choices"][0]["message"]["content"]
# 5秒間待つ
time.sleep(5)
# 画像の生成
response = openai.Image.create(
prompt=f"anime, oil painting, cg, cinematic lighting, illustration, {keywords}",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']
# 5秒間待つ
time.sleep(5)
# 画像の保存
img_filename = f'page_{i+1:02}.png'
img_filepath = os.path.join(img_directory, img_filename)
urllib.request.urlretrieve(image_url, img_filepath)
# 音声を保存するディレクトリの作成
audio_directory = './temp_folder_audio'
if not os.path.exists(audio_directory):
os.makedirs(audio_directory)
# 各ページのテキストを読み上げ、音声ファイルを生成
for i in range(10): # 10ページ分のループ
filename = f'page_{i+1:02}.txt'
filepath = os.path.join(directory, filename)
with open(filepath, 'r') as file:
text = file.read()
# Text-to-speech APIのリクエスト設定
synthesis_input = texttospeech.SynthesisInput(text=text)
voice = texttospeech.VoiceSelectionParams(
language_code="ja-JP", ssml_gender=texttospeech.SsmlVoiceGender.FEMALE
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
speaking_rate=1.2 # 1.0より大きな値で読み上げ速度を上げる
)
# Text-to-speech APIの呼び出し
response = client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
# 音声の保存
audio_filename = f'page_{i+1:02}.mp3'
audio_filepath = os.path.join(audio_directory, audio_filename)
with open(audio_filepath, 'wb') as out:
out.write(response.audio_content)
# ソートされた音声ファイルと画像ファイルのパスのリストを作成する
slide_audios = sorted([os.path.join(audio_directory, audio) for audio in os.listdir(audio_directory) if audio.endswith('.mp3')])
images = sorted([os.path.join(img_directory, img) for img in os.listdir(img_directory) if img.endswith('.png')])
# 画像と音声を組み合わせて動画を作成する
clips = []
for img, audio_path in zip(images, slide_audios):
audio = AudioFileClip(audio_path)
img = ImageClip(img, duration=audio.duration)
img = img.set_audio(audio)
clips.append(img)
# 動画を結合する
final_video = concatenate_videoclips(clips, method="compose")
final_video.fps = 24
# タイトルの生成
title_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "以下の物語のタイトルを一言で生成してください。"},
{"role": "user", "content": user_input},
]
)
title = title_response["choices"][0]["message"]["content"]
# タイトルに不適切な文字が含まれている場合の処理
invalid_chars = ['<', '>', ':', '"', '/', '\\', '|', '?', '*']
for char in invalid_chars:
title = title.replace(char, '')
output_path = title + ".mp4"
final_video.write_videofile(output_path, codec="libx264", audio_codec="aac", bitrate="8000k")
実行したら、作りたい物語のテーマを聞かれるので、何かしら入力します。
openaiのサーバーが不調だとエラーが発生しますが、上手くいくと30分くらいで15分ほどの紙芝居アニメが生成されます。
動画をダウンロードして再生出来れば、成功です!
最後に
これもただの遊びツールですが、面白いですね。
GPT4を使ってこれを試したいので、もう一度、GPT4の申請してみます。
また何か作ってみます。