1ヶ月ほどスクレイピング業務でRを使用しましたのでその備忘に加え、
私のように「R触ってみたいけど難しそうやん...」という初学者の方々の
少しでも助けになればと思っております!頑張るぞ!
このトピックでやること
実際にWeb上にあるデータをスクレイピング
↓
そのテキストデータをちょっと整理して見る
以上!
データ分析の勉強を始めると、いざ手法を学んで自分で試してみようというときに
**「いや、データが無いんですけど!?」**となることありませんか?
(僕はよくなります...)
スクレイピングができれば、自分で分析したいデータを収集・分析できます。
今回はテキストデータを扱いますが、それ以外のデータも取得できますので
みなさんも是非好きなデータを取って、じゃんじゃか分析しましょう!
環境
私は特にRに詳しい人ではないので参考にさせていただいた
ページを紹介させていただきます。
「R」とIDEである「Rstudio」が入っていれば問題ありません。
RとRstudio
RおよびRStudioのインストール方法(Mac/Windows)
https://qiita.com/daifuku_mochi2/items/ad0b398e6affd0688c97
RMeCab
「RMeCab」とはR上で日本語テキストマイニングするために有効なパッケージです。
これを使うにあたって元となっている「MeCab」を準備する必要があります。
こちらの「準備」の段落でMeCabのインストール方法が記載されていますので
参考にしてみてください。
https://qiita.com/hujuu/items/314a64a50875cdabf755
スクレイピング
Rにはスクレイピング用の「rvest」というパッケージが用意されていますので
今回はこれを使って進めていきます。
rvestの導入
install.packages("rvest")
library("rvest")
install.packagesでパッケージをインストールし、
libraryコマンドで対象のパッケージを適用しています。
これだけでスクレイピングの準備はOKです!
Rでスクレイピング
data <- read_html("あなたが情報取得したいURL")
これで指定したWebページの情報がhtml形式で取得され
「data」という入れ物に入ったということになります。
特定の情報を取得するには
例えば私は今回以下のURLを指定しました。
https://www.amazon.co.jp/product-reviews/B01MA1Y0OG/ref=acr_dpx_see_all?ie=UTF8&showViewpoints=1
(このカメラ欲しいんですけど、何回か使ったら飽きそうで迷ってるんですよね...)
今回はAmazonでのこのカメラの「レビュー情報」だけ取得する場合を例にあげて説明していきます。
ページに飛んでいただければわかりますが実際のWebページには
欲しい情報以外の情報もたくさん掲載されています。
その中で「自分が欲しい情報だけ」を取得するにはhtmlの属性で更に細かく指定していく必要があるのです。
HTML情報の調べ方
Webページのhtml情報の調べ方の一般的な方法としてはChromeのデベロッパーツールを使用する方法が一般的です。
Chromeの右上「・・・」ボタンから「その他ツール>デベロッパーツール」で開くことができます。
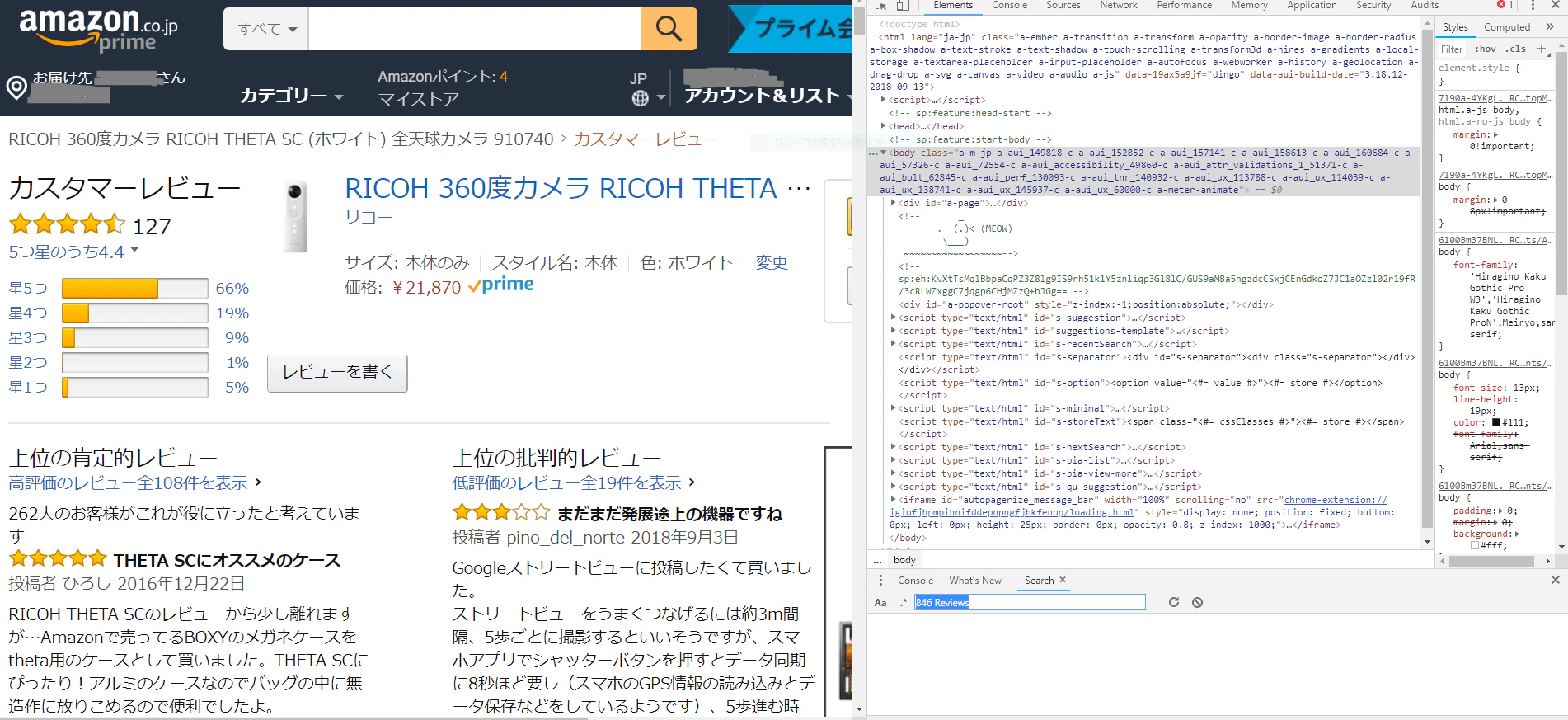
画像のように今開いているWebページの横にHTML情報をそのままくっつけて表示してくれるのですが
正直htmlに普段触れていない方がこれを見ると「うわぁ...」となることもあると思います。
そういう時のためにChromeの拡張機能で「SelectorGadget」というのが用意されていて
これを使うとカーソルをあわせた情報がHTML上のどのクラスに属しているかを判別してくれます!
これを導入するとどうなるかといいますと
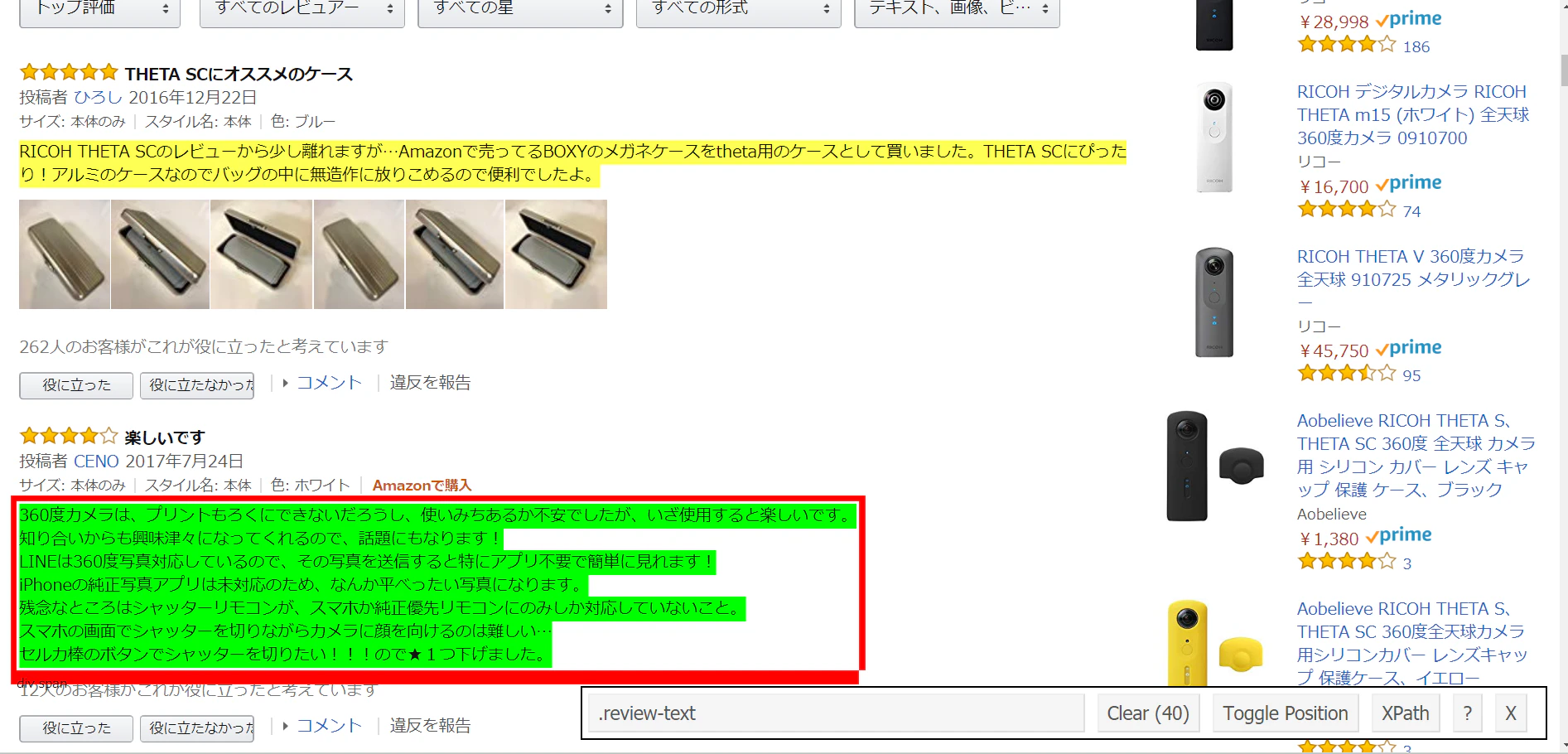
赤い枠で囲まれているのが私が選択している場所です。コメント文ですね。
右下の窓に表示されている**「.review-text」**がこの情報が属しているクラスです。
同じ属性の箇所には黄色いハイライトが入るので、他のコメントも同じ属性であることがわかります。
※selectorgadgetのアイコンをクリックするとこの機能はOFFになります。
これで、htmlを読みたくない方もなんとか属性に辿り着くことができましたね!!
情報の抽出
data <- read_html("あなたが情報取得したいURL")
先程このコードで取得したページの情報から、欲しい情報のみを抽出します。
私の場合欲しいコメント情報は**「.review-text」**に属していることがわかりました。
その場合以下のようなコードになります。
media <- html_nodes(data,".review-text") %>%
html_text()
html_nodesによってHTMLから情報を抽出することができます。
第一引数が対象のhtml、第二引数に抽出する属性を記載しています。
今回はクラス名のみを記載していますが実際は「XPATH」という
html上のPATHを書くことによって、様々な属性から抽出することができます。
(実際、クラス名だけでは欲しい情報が抜けないことも多いです)
※XPATHについてはこちらのページが詳しく解説されています。
https://qiita.com/rllllho/items/cb1187cec0fb17fc650a
%>%はR上でのパイプの役割をします。
パイプの前の処理で出力した結果を、パイプの後ろの処理の第一引数として渡します。
html_nodesで出力した結果はhtmlのタグなどの情報がついているので
結果をhtml_textに渡すことでテキストデータに変換してもらっているのです。
それでは早速ですがコメントデータが取得できたか見てみましょう!
# mediaの中身を確認
media
↓結果
[1] "RICOH THETA SCのレビューから少し離れますが…Amazonで売ってるBOXYのメガネケースをtheta用のケースとして買いました。THETA SCにぴったり!アルミのケースなのでバッグの中に無造作に放りこめるので便利でしたよ。"
[2] "360度カメラは、プリントもろくにできないだろうし、使いみちあるか不安でしたが、いざ使用すると楽しいです。知り合いからも興味津々になってくれるので、話題にもなります!LINEは360度写真対応しているので、その写真を送信すると特にアプリ不要で簡単に見れます!iPhoneの純正写真アプリは未対応のため、なんか平べったい写真になります。残念なところはシャッターリモコンが、スマホか純正優先リモコンにのみしか対応していないこと。スマホの画面でシャッターを切りながらカメラに顔を向けるのは難しい…セルカ棒のボタンでシャッターを切りたい!!!ので★1つ下げました。"
[3] "ふだんの写真撮影は一眼レフを使用しています。 (キヤノン EOS 6D)臨時収入があったので、ポチッと購入してみました。スマホのパノラマ機能ぐらいに考えていたのですが、想像をはるかに超える楽しい写真を撮影することができます。天井から足元(自分も含めて)撮れますので、撮り逃しがありません。スマホアプリで、簡単な加工ができたり、モザイクまで掛けられます。ただ、調子に乗ってサーバーにアップロードしまくると、パケットをかなり消費してしまうので、wi-fi環境下でサーバーにアクセスすることをオススメします。撮影している自分の手が映らないように工夫が必要です。自撮り棒って、外国人観光客みてたいで自分自身で使用する気にはなれないので、『カメラ ハンドグリップ 一脚 手振れ 軽減 ハンディ モノポッド 一眼レフ ミラーレスコンパクト デジタルカメラ(デジカメ)・ ビデオ カメラ用 1/4インチ カメラハンドル MHG Type (ブラック)』http://amzn.to/2Egxczx を使用しています。"
[4] "気軽に全天球画像が取れるのでとても気に入っています。値段もちょうど良いくらいだと思います。(別段安くないけど許容範囲)当たり前ですが商品の特性上、ズーム等は出来ません。写真のバリエーヨンとしての全天球画像専用機って感じです。三脚や自撮り棒がつけれるのですがこれを付けると充電ができなくなる。(充電用のマイクロUSBポートが隠れる)sdカードスロットがない。GPSがない。Bluetooth接続ではなくwifi接続(シータがwifiの電波を出して携帯側で受信して接続)となります。このため、携帯側にsimを入れないでモバイルwifi等で運用してる人は上手く使えない?気がします。全天球画像をGoogleストリートビューなどに投稿するのに何故か一旦wifi接続解除しないと投稿できない。とまあ、不満点を書きましたが現時点では手軽にストレスの少ない運用ができます。"
[5] "前から気になって居ましたが、ここ数年で性能もアップして来た様なのでやっと入手。想像してたよりやはり360度撮影は感動的です。普通のカメラでは例え一眼レフでもこの技は使えません。やはりその一瞬を完璧に切り取り、キチンと思い出に残したいなら、このTHETAしか有りません。だって、その瞬間の周りの全てが一枚に収まるのは本当に凄いの一言に尽きます。画質もズームするととても綺麗に写っているのが判ります。本当にそこに居た、行った思い出を確実に残す事が出来る一台。もうこれは絶対にお薦めの一台です。"
[6] "これは、普通のデジカメのように使ってはいけないです。画質はそれほど良いとは言えませんが、全方向をワンショットで記録でき、後からその場の色々な方向を眺め回すことができます。その場の雰囲気を丸ごと記録すると言えば良いでしょうか。風景を入れた記念写真をこのカメラで撮影する場合は、人物-カメラ-風景 のようにカメラを挟んで撮影した方がいい感じに撮影できます(ケースバイケースですけれど)。LineやGoogleフォトも360度カメラ画像に対応しているので、撮った写真を人にあげるのも簡単です。問題点はスマホ(Android使用)との接続がなかなか上手く行かない場合があることで、Wi-Fi自体は接続済みになっているのに、THETAアプリの方でカメラと接続できない旨のエラーが良く出ます。これは改善して欲しい。また、スマホでモニターしながら撮影しようとすると、前述の問題に加え、いちいち撮影した画像をスマホに転送してくるので、本体のみで撮影して時間に余裕のある時にスマホに転送するという使い方が宜しいのではないでしょうか。"
[7] "想像以上に楽しいです。空間をそのまま保存できるので手軽に撮影ができます。撮った画像はLINEだと360°対応なので簡単に家族や友達に送って見てもらう事ができます。非常に便利で楽しいです。現段階ではSCが値段と性能のバランスが一番いいと思います。マウナ・ケアで長時間露光撮影機能を使用し天の川を全天球撮影する事もできました。太陽等の強い光源がある場合は側面を光源に向けて撮影すると良いですよ。簡単なコツなので試してみればわかると思います。久々に値段以上の満足感を得られました。レンズが出っ張っているので落下保障は付けたほうが良いと思いますよ。"
[8] "ずーっと気になっていました。普段は一眼レフとパノラマ雲台、広角レンズで高解像度パノラマを作成していますが、機材をセットしてるグルグル写真撮って、それをAutopanoでつなげて、って作業が必要です。人がたくさんいれば撮れないし、機材は重いし。もちろん高解像度なので使い道はありますし、今後も併用していくことになります。ただ、スマホで写真を撮る感覚で360パノラマが撮れるのは感動ものです。"
[9] "今日使い始めたばかりですが、大変感動モノのカメラだと感じました。今までと違う世界ですね。ただし作例のような芸術領域に至るのは時間がかかりそうです。手持ちの撮影はおススメしません。短くても自撮り棒あるいはミニ三脚に乗せてのセルフタイマー撮影がいいですね。ワイヤレスでシャッターを切るときにスマホを使うと撮影者の視線が悪くなるのでセルフタイマーの方がいいでしょう。腕に自信がある人は市販のwifiデバイスをプログラミングしてワイヤレスシャッターが作れるようですが、とりあえず自撮り棒とセルタイマーがいいんじゃないですか。宴会などで卓中央にミニ三脚で立てるとなかなか良い写真が撮れます。初日ですが、かなり深い使い方ができそうなカメラですね。"
[10] "以前より興味がありましたが、今回旅行へ行く機会に恵まれたため、思い切って購入いたしました。普段の写真とは違った趣があり、これはこれとして楽しいツールであると使っていて感じました。ただ一般的な写真と比べて目が粗いなどまだまだ改善のよりがあるため、☆4とさせていただきました。上位機種との差異はわかりませんが、まだ市場も開拓されていないため購入するならエントリークラスで十分楽しめるのではないでしょうか?(ハイクラスを購入してもそれほど違いを感じないと思います"
取れていますね!
10件分のコメントがテキストの形でそれぞれ格納されています。
テキストデータの操作
それでは、早速ですが取得したテキストデータを操作してみましょう!
冒頭でも書いた通りRMeCabというパッケージにテキストマイニングのための
あれやこれやが入っています。
その中でRMeCabCは日本語のテキストを引数に渡すと名詞や動詞といった品詞分類をしてくれます。
では早速、先程取得したレビューコメントデータで試してみましょう。
※[1]をつけて試しに1つ目のコメントのみで動かしています
# パッケージのインストール
install.packages("RMeCab")
# パッケージの読み込み
library("RMeCab")
# 品詞分類をしてみる
RMeCabC(media[1])
↓結果
[[1]]
名詞
"RICOH"
[[2]]
名詞
"THETA"
[[3]]
名詞
"SC"
[[4]]
名詞
"縺"
[[5]]
名詞
"ョ"
[[6]]
名詞
"繝"
文字化けしとるじゃないの!!!!

文字化けの解消
落ち着きましょう。
モチのロンでRでも文字コードを調べたり、変換することができます。
detectEncodingを使えば渡したデータがどの文字コードでエンコードされているかがわかります!
早速調べてみましょう!以下を実行します。
# パッケージのインストール
install.packages("Ruchardet")
# パッケージの読み込み
library("Ruchardet")
# 文字コード確認
detectEncoding(media[1])
↓結果
> detectEncoding(media[1])
[1] "UTF-8"
はい、ということで今回取得した情報は「UTF-8」でエンコーディングされています。
RMeCabをインストールする時に気づかれたかもしれませんが、辞書データのMeCabは
defaultの文字コードがSHIFT-JISになっています。
従って取得した情報を「UTF-8→SHIFT-JIS」変換してあげることで
RMeCab上でも文字化けしないようになりそうです。
文字コード変換
文字コードの変換は簡単でiconvというコマンドで変換します。
それでは情報抽出するときに使った以下のコードにiconvコマンドを追加してみます。
# 旧コード
media <- html_nodes(data,".review-text") %>%
html_text()
# iconvを追加
media <- html_nodes(data,".review-text") %>%
html_text() %>%
iconv(,from = "UTF-8"
,to = "Shift-JIS")
パイプでコマンドをつないでいるためiconvの第一引数は省略されています。
もう一度文字コードを確認します。
# 文字コード再確認
detectEncoding(media[1])
↓結果
> detectEncoding(media[1])
[1] "Shift_JIS"
SHIFT-JISに変換されています!
それではもう一度RMeCabCにトライ!
# 品詞分類をしてみる
RMeCabC(media[1])
↓結果
[[1]]
名詞
"RICOH"
[[2]]
名詞
"THETA"
[[3]]
名詞
"SC"
[[4]]
助詞
"の"
[[5]]
名詞
"レビュー"
[[6]]
助詞
"から"
YEEEEEEEEEEEEEE!!!!
無事日本語で表示されていますね。
これでRMeCab上でもデータが操作できるようになりました!
簡単なテキスト解析
ここからRMeCabのコマンドを使って簡単なテキスト解析をやってみます。
といってもdocMatrixというコマンドに打ち込むだけです!苦笑
ただひとつ、このdocMatrixコマンドを使うために準備が必要です。
それは解析対象のテキストがファイルになっていないといけないということです。
(なんでなんや...)
先程、10件のレビューコメントを取得しましたので10個のファイルに分けて
それぞれのレビューコメントを出力してみます。
データのファイル出力
write.tableコマンドでデータを出力することができます。
今回はRが動いているフォルダの中に「review_info」という
フォルダを新規で作成しました。
以下の繰り返し処理によってmediaに格納された10件の
レビューコメントを1つずつのテキストファイルに出力していきます。
# ファイル出力
for (nu in 1:length(media)) {
write.table(media[nu]
, paste0("./review_info/review",nu,".txt")
, row.names = FALSE
, col.names = FALSE)
}
write.tableの第一引数が出力したいデータ、第二引数が出力名です。
今回は作業フォルダの中にreview_infoフォルダを作ったので
フルパスを書かずに上のように./review_info/と省略して記載できます。
また、今回はコメントデータのみが必要であるため列名、行番号を表示しないよう
row.names = FALSEとcol.names = FALSEのパラメータを渡しています。
↓結果
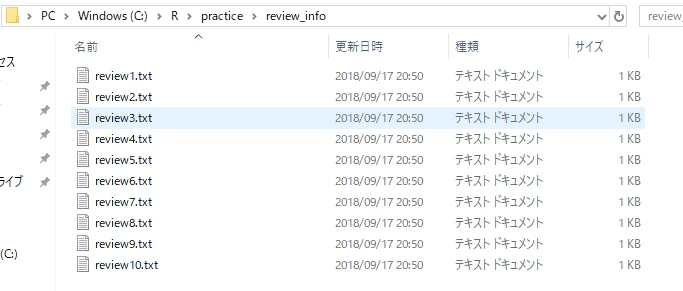
こんな風にmedia変数の中身がファイルに出力されました。
次はコマンドにこのファイルを入れてみましょう!
docMatrixの実行
docMatrixはそのテキストデータを単語ごとに集計してくれるコマンドです。
第一引数に対象のファイル、もしくはフォルダ(フォルダを指定した場合はその中のファイルすべて)
第二引数にカウントしてほしい品詞を指定します。
データが複数あれば複数を横並びに表示してくれます。
早速実行してみましょう!
# 一度結果を変数に入れてからそれを表示することで結果を確認できます。
res <- docMatrix("./review_info",c("名詞","形容詞"))
res
↓結果
terms review1.txt review10.txt review2.txt review3.txt review4.txt review5.txt review6.txt
" 2 2 2 2 2 2 2
[[LESS-THAN-1]] 0 0 0 0 0 0 0
[[TOTAL-TOKENS]] 51 130 137 210 186 140 246
Amazon 1 0 0 0 0 0 0
BOXY 1 0 0 0 0 0 0
RICOH 1 0 0 0 0 0 0
SC 2 0 0 0 0 0 0
theta 1 0 0 0 0 0 0
THETA 2 0 0 0 0 1 1
アルミ 1 0 0 0 0 0 0
ケース 3 0 0 0 0 0 0
バッグ 1 0 0 0 0 0 0
メガネ 1 0 0 0 0 0 0
レビュー 1 0 0 0 0 0 0
中 1 0 0 0 0 0 0
便利 1 0 0 0 0 0 0
無造作 1 0 0 0 0 0 0
用 1 0 0 1 1 0 0
4 0 1 0 1 0 0 0
エントリー 0 1 0 0 0 0 0
クラス 0 1 0 0 0 0 0
これ 0 2 0 0 1 1 2
ため 0 3 1 0 1 0 0
ツール 0 1 0 0 0 0 0
の 0 1 1 1 1 2 2
ハイクラス 0 1 0 0 0 0 0
以前 0 1 0 0 0 0 0
違い 0 1 0 0 0 0 0
一般 0 1 0 0 0 0 0
改善 0 1 0 0 0 0 1
開拓 0 1 0 0 0 0 0
楽しい 0 1 1 1 0 0 0
機会 0 1 0 0 0 0 0
機種 0 1 0 0 0 0 0
興味 0 1 0 0 0 0 0
購入 0 3 0 1 0 0 0
今回 0 1 0 0 0 0 0
差異 0 1 0 0 0 0 0
市場 0 1 0 0 0 0 0
写真 0 2 4 2 1 0 2
趣 0 1 0 0 0 0 0
十 0 1 0 0 0 0 0
上位 0 1 0 0 0 0 0
粗い 0 1 0 0 0 0 0
的 0 1 0 0 0 1 0
普段 0 1 0 0 0 0 0
分 0 1 0 0 0 0 0
目 0 1 0 0 0 0 0
旅行 0 1 0 0 0 0 0
1つ 0 0 1 0 0 0 0
360 0 0 2 0 0 1 1
iPhone 0 0 1 0 0 0 0
LINE 0 0 1 0 0 0 0
アプリ 0 0 2 0 0 0 1
カメラ 0 0 2 4 0 1 5
こと 0 0 1 2 0 0 2
シャッター 0 0 3 0 0 0 0
スマ 0 0 2 1 0 0 2
セルカ 0 0 1 0 0 0 0
ところ 0 0 1 0 0 0 0
プリント 0 0 1 0 0 0 0
ホ 0 0 2 1 0 0 2
ボタン 0 0 1 0 0 0 0
リモコン 0 0 2 0 0 0 0
画面 0 0 1 0 0 0 0
簡単 0 0 1 1 0 0 1
顔 0 0 1 0 0 0 0
興味津々 0 0 1 0 0 0 0
残念 0 0 1 0 0 0 0
使いみち 0 0 1 0 0 0 0
使用 0 0 1 3 0 0 1
純正 0 0 2 0 0 0 0
送信 0 0 1 0 0 0 0
対応 0 0 3 0 0 0 1
知り合い 0 0 1 0 0 0 0
度 0 0 2 0 0 1 1
難しい 0 0 1 0 0 0 0
不安 0 0 1 0 0 0 0
不要 0 0 1 0 0 0 0
平 0 0 1 0 0 0 0
棒 0 0 1 1 1 0 0
優先 0 0 1 0 0 0 0
話題 0 0 1 0 0 0 0
- 0 0 0 1 0 0 1
( 0 0 0 1 0 0 2
) 0 0 0 1 0 0 1
)』 0 0 0 1 0 0 0
. 0 0 0 1 0 0 0
/ 0 0 0 2 0 0 0
:// 0 0 0 1 0 0 0
1 0 0 0 1 0 0 0
2 0 0 0 1 0 0 0
6 0 0 0 1 0 0 0
amzn 0 0 0 1 0 0 0
D 0 0 0 1 0 0 0
Egxczx 0 0 0 1 0 0 0
EOS 0 0 0 1 0 0 0
fi 0 0 0 1 0 0 0
http 0 0 0 1 0 0 0
MHG 0 0 0 1 0 0 0
docs
terms review7.txt review8.txt review9.txt
" 2 2 2
[[LESS-THAN-1]] 0 0 0
[[TOTAL-TOKENS]] 153 101 163
Amazon 0 0 0
BOXY 0 0 0
RICOH 0 0 0
SC 1 0 0
theta 0 0 0
THETA 0 0 0
アルミ 0 0 0
ケース 0 0 0
バッグ 0 0 0
メガネ 0 0 0
レビュー 0 0 0
中 0 0 0
便利 1 0 0
無造作 0 0 0
用 0 0 0
4 0 0 0
エントリー 0 0 0
クラス 0 0 0
これ 0 0 0
ため 0 0 0
ツール 0 0 0
の 0 1 1
ハイクラス 0 0 0
以前 0 0 0
違い 0 0 0
一般 0 0 0
改善 0 0 0
開拓 0 0 0
楽しい 2 0 0
機会 0 0 0
機種 0 0 0
興味 0 0 0
購入 0 0 0
今回 0 0 0
差異 0 0 0
市場 0 0 0
写真 0 2 1
趣 0 0 0
十 0 0 0
上位 0 0 0
粗い 0 0 0
的 0 0 0
普段 0 1 0
分 0 0 0
目 0 0 0
旅行 0 0 0
1つ 0 0 0
360 1 1 0
iPhone 0 0 0
LINE 1 0 0
アプリ 0 0 0
カメラ 0 0 2
こと 0 1 0
シャッター 0 0 2
スマ 0 1 0
セルカ 0 0 0
ところ 0 0 0
プリント 0 0 0
ホ 0 1 0
ボタン 0 0 0
リモコン 0 0 0
画面 0 0 0
簡単 2 0 0
顔 0 0 0
興味津々 0 0 0
残念 0 0 0
使いみち 0 0 0
使用 1 0 0
純正 0 0 0
送信 0 0 0
対応 1 0 0
知り合い 0 0 0
度 0 0 0
難しい 0 0 0
不安 0 0 0
不要 0 0 0
平 0 0 0
棒 0 0 2
優先 0 0 0
話題 0 0 0
- 0 0 0
( 0 0 0
) 0 0 0
)』 0 0 0
. 0 0 0
/ 0 0 0
:// 0 0 0
1 0 0 0
2 0 0 0
6 0 0 0
amzn 0 0 0
D 0 0 0
Egxczx 0 0 0
EOS 0 0 0
fi 0 0 0
http 0 0 0
MHG 0 0 0
[ reached getOption("max.print") -- omitted 247 rows ]
今回は名詞と形容詞を指定したので、コメント中の名詞、形容詞がカウントされています。
なんか凄いですよね。
この結果を軽く眺めると「楽しい」や「簡単」といった単語が複数のコメントで見られます。
ここからこの360度カメラは画質や写真加工といった性能面よりも
手軽に今までにない体験ができるところが評価されている、ということが読み取れます。
最後に
最後のテキスト解析の部分、かなり雑にやってしまってすみません...
実際には例えば「良い評価」と「悪い評価」で使われている言葉を分析したり
ユーザーの属性や、レビュー時期によってデータを分けながら分析していくことが一般的なのかな...
分析業務は私もこれから触っていく予定なので、引き続き勉強していきたいと思います!
じゃあの!