※このお話はたぶんフィクションです。実在の人物や団体とはあんまり関係ありません。
序章
はじめに
近年、ウェブ開発をとりまく環境の変化は激しさを増しており、全体像を把握することが非常に困難な状況である。フルスタックエンジニアというものが幻想になり、もはやすべての分野を網羅的に横断できる能力を持った人間はひとりもいないと言っても過言ではない。
しかしアーキテクチャ設計には全体を俯瞰する力が必要であり、技術選定には現在を時代の潮流の一地点として捉える時代感覚が必要であり、コーディングには歴史的文脈に対する素養が不可欠である。
中級以上のエンジニアならそういった感覚は大なり小なり持ちあわせているかと思うが、それを言語化・外部化することは、これまた非常に困難であり、それが現状の混乱をさらに加速させているものと考える。
本エントリはそういった感覚の共有ライブラリ化への挑戦である。ウェブプログラミングの変遷をメインテーマに、各時代のインターネットの空気感、ウェブの持つダイナミズム等もサブテーマとして扱う。
筆者のおもな言語来歴はPerl→PHP→JavaScriptであり、本エントリもこれを主軸にして進む。RubyサイドやJavaサイドから見た歴史観はまた違ったものになるかと思われるが、筆者にそれを語る力がないことは最初に明記しておく。
対象
本エントリは昨今のウェブ開発の混乱に呑まれている(と感じている)エンジニアを対象としている。あるていどの基礎知識は必要となるが、以下の条件を満たしているエンジニアなら問題なく読めるはずである。
- Unixコマンドを打ったことがある
- HTMLを書いたことがある
- なんらかのプログラミング言語をさわったことがある
あくまでウェブ開発の全体像を把握することが目的なので、わからない箇所があれば躊躇なく読み飛ばしてかまわない。
手元に開発環境があったほうが読み進めやすいので、Vagrantで環境構築しておくことをおすすめする。dotinstallの講座がわかりやすいので導入の参考にされたい。
Vagrantに限らず、何かわからない技術が出てきたら、このサイトで探してみよう。どんな技術も最初の一歩がいちばん重いハードルとなるが、そのハードルをひょいと飛び越えさせてくれるのでおすすめである。
動機
筆者に興味がなければこの節は読み飛ばしてかまわない。
このエントリを書いた動機はふたつある。
先日、「HTTP/1.1 200 OK」というエントリを寄稿した。これは自分の学習メモをもとに書き起こした自分用のまとめであり、他人向けに書いた文章ではなかったが、意外にも好評をいただいた。そして多くの人が自分と同じようにウェブ開発の現状に混乱しているのだということを理解した。それから、こういった「感覚を共有ライブラリ化する能力」というのは希少な能力であり、どうも自分はそれを持っているのかもしれない、ということに思い至った。これがひとつ。
そしてもうひとつ、こちらがメインの動機なのだが、論文を書く練習のため、である。
筆者は高校を中退していて、現在30代半ばながら大学を目指している「周回遅れの大学受験生」なのだが、志望しているのは理系ではなく文系、経済学部である(このあたりの経緯は去年増田に書いた)。そういった学部では論文を書く能力が求められるかと思うので、今回はその練習として論文調の構成を意識して書いた(内容的には論文というより新書の類だが)。これは自分の書く技術的・学術的文書がどのくらい世の中に通用するか、という試金石なのである。
それではさっそくその公開試験を始めよう。
第1章 ウェブの夜明け
1-1 からっぽの洞窟
'90年代のインターネットはそれ自体がアンダーグラウンドなものだった。スマホもタブレットもない時代、インターネットへアクセスするにはPCが必須だったが、当時のPCは高価だった上、必要とされる知識も高度だったため、個人が所有するようなものではなかった。だから当時のインターネットは、研究者と、一部のマニアだけのものだった。
縦横高さどの次元でもない、その新しく拡張された領域、インターネットという仮想空間は、まだ現実世界と隔絶しており、まともな法整備もなく、一般層からは、得体のしれないもの、薄気味悪いものとして忌避されていた。
しかし実際には、いたって普通の人間が集まる、いたって普通の場であった。たしかに無法者・愚連隊を自称する集団はちらほらいたものの、そういった集団がやっていることといえば掲示板荒らしくらいのもので、当時のインターネットは、現在と比べれば非常に牧歌的なものであった。
1-2 個人サイト
'90年代、人々はインターネットでどのようにコミュニケーションを取っていたのだろうか。IRC、ICQ、ニュースグループ、いろいろあるが、やはり個人サイトの存在が大きかったように思われる。
SNSもブログもない時代、個人が情報を発信するためには「無料ホームページスペース」やレンタルサーバを借り、FTPでHTMLをアップロードして、CGIを設置して……と、自力でサイトを構築する必要があったが、それはスキルの高いエンジニアにのみ許された行為ではなく、とても一般的な行為だった。
このころの空気を体感するために、以下のサイトを見てみよう。
ネタサイトなので多少誇張されているきらいはあるが、当時の個人サイトはおおむねこのような雰囲気だったと考えて問題ない。ここで注目して欲しいのは「リンク集」と「掲示板」である。
1-3 検索エンジン
まずはリンク集――の話をする前に、当時の検索エンジンについて少し解説しておかなければならない。
現在はGoogleやBingで検索して、その検索結果からリンクをたどるのが「あたりまえ」であるが、'90年代はこれは「あたりまえ」ではなかった。このころはYahooをはじめとしてディレクトリ型検索エンジンが主流であった。これは登録されたサイトのみが検索対象となる種類の検索エンジンだ。運営者による選別を経ているので良質なコンテンツのみを検索可能という利点はあったが、ウェブ全体を網羅的に検索するものではなかった。そもそも当時の貧弱なCPU、少ないストレージで、ウェブ上のすべてのリソースをインデックス化するなんてことは、あまりにもバカげた発想だった。
Googleが導入したロボット型検索エンジンのもっとも優れていたところは、ただ闇雲にウェブ全体をクロールするだけでなく、被リンク数をもとにページランクという指標を設け、それを検索結果順位に反映させたことである。論文の被引用回数のようなものだと考えればその重要性は理解できるが、これはいまだから言えることであって、当時としてはとても画期的なものであった。
1-4 ハイパーリンク
少し脱線してしまったので話をまとめよう。'90年代にはSNSもブログもなく、個人が情報を発信するには自分のサイトを作成するのが一般的であった。しかし当時はディレクトリ型検索エンジンが主流で、ただサイトを作って公開しただけではどこからも参照されない、存在しないも同然のサイトになってしまう。
では、どうするか? 個人サイト同士で相互にリンクをはりあうのである。
このころの個人サイトは上で見たようなサイト構成が様式美のようになっていて、ほぼ確実にリンク集が置かれていた。誰かの個人サイトに行ったら次はそのリンク集をたどって別の人のサイトへ、そしてまたそのリンク集をたどって……と延々「ネットサーフィン」できるわけである。思えばこの言葉が死語になってしまったのも、Googleの登場によってこういった行動様式がなくなってしまったことが関係しているのかもしれない(ただダサかっただけかもしれないが)。
リンクからリンクへ。さらにそのリンク先へ。それは地図にない路地裏をあてどもなく歩くようなもので、どこにたどりつくのかわからない、ある種のワクワク感があった。現在はGoogleによってすっかり「ならされ」、交通整理されてしまった感があるし、Googleの他にもTwitterやその他キュレーションサービス等、要所要所に「中心」が存在するが、'90年代のウェブに「中心」は存在しなかった。ただ小さなミームがリンクによってつながりあい、webの字義通り、蜘蛛の巣のように糸が張り巡らされていたのだ。
Google登場前のウェブは、ハイパーリンクによって縦横無尽につながっていたのである。
1-5 HTTP
ではその蜘蛛の糸は、どのような仕組みなのだろうか。実はウェブ上のページ同士が直接的につながっているわけではない。これにはHTTPという仕組みが深く関わっている。
少し低レイヤの話になるが、ウェブの根幹をなす技術であるし、マイクロサービスというアーキテクチャの流行によって現在でも、というかむしろ現在だからこそ重要な知識となってきているので、ここで軽くふれておこう。
手元にUnix環境がある人はターミナルで以下のように打ってみて欲しい。
$ curl -v http://example.com/index.html
curlは非常に優秀なHTTPクライアントプログラムであるが、-vオプションを付けることで、取得結果の表示だけでなく、さらに詳細な報告もしてくれる。上記のコマンドは以下のような結果になるはずである。
* Hostname was NOT found in DNS cache
* Trying 93.184.216.34...
* Connected to example.com (93.184.216.34) port 80 (#0)
> GET /index.html HTTP/1.1
> Host: example.com
> ...
>
< HTTP/1.1 200 OK
< Content-Type: text/html
< ...
<
<!doctype html>
<html>
...
</html>
* Connection #0 to host example.com left intact
ブラウザのアドレスバーにhttp://から始まるURIを入力したとき、つまりHTTPクライアントにURIを渡したとき、どのような処理が行われるか、これを見るとわかりやすのではないかと思う。
順番に見ていこう。
最初の*から始まる行は事前準備である。URI中にあるホスト名example.comという文字列を、実際のインターネット上の番地にあたるIPアドレスに変換する。このあたりはインフラエンジニア志望でなければ「そういうものなのだ」くらいの認識でかまわないかと思う。ウェブに関する知識はあまりに膨大かつ多岐に渡るため、こうしてあるていどのところで立ち止まるのもまた必要なスキルである。人間ひとりのリソースは矮小なのだから。
IPアドレスが判明したら当該サーバに接続を試みる。いわば電話をかけている状態である。相手方が電話に出てくれたら(接続を許可してくれたら)、ここからHTTPという言語を用いた「会話」が始まる。
>から始まる行はこちらから相手方へのメッセージである。GETはメソッド、命令にあたる。つまりこの場合、「あなたのところにある/index.htmlを取得せよ」と命じているわけである。サーバはこの命令に従って行動する。だからserver(給仕人)と呼ぶのだ。ちなみに命じる方はclient(依頼人)である。
<から始まる行はサーバからの返答である。1行目はサーバがクライアントからのメッセージを正しく解釈したことを示している。ちゃんとHTTPという言語で話さないと、ここで「おまえは何を言っているんだ」と返される。こわい。
そしてさらに「いまからこういうようなことを話しますよ」といったようなメッセージが続き、空行をはさんで、クライアントが指定したリソース、この場合は/index.htmlの内容がサーバによって語られるわけである。
最後の*は会話が終了したので電話を切った、つまり接続が切断されたことを示している。
これがHTTPという言語を用いた「会話」のあらましである。ブラウザのアドレスバーにURIを入力したとき、こうした処理がバックグラウンドで行われ、サーバから取得したHTML等のリソースの内容をブラウザが解釈し、画像等が必要であればそれも追加でサーバから取得し、ウェブページをレンダリングする。こうして晴れて、遠いどこかのサーバ内にあった情報が、ブラウザを使っているユーザの視神経に到達する。ウェブページ内にリンクがあり、ユーザがそれをマウスでクリックすれば、そのURIをもとにまたバックグラウンドでサーバに接続し、そのリソースを取得し……という具合である。実はウェブの世界は、こんなシンプルな仕組みによって成り立っているのだ。
もうひとつの頻出メソッドPOST、そしてRESTについては次章で少しふれるが、もしこの節の内容をおもしろいと感じたのなら、「Webを支える技術」を読むことをおすすめする。これは非常な名著で、本エントリなど比較にならないくらいおもしろく読めるはずである。読んでいてワクワクする技術書というのは、そうそうあるものではない。
さて、ここまでは「リンク集」の解説だった。静的なコンテンツがどのようにつながっているか、という話であった。次は「掲示板」の話に移ろう。動的なコンテンツは、どのような仕組みで動いているのだろうか。前置きが長くなってしまったが、次章からウェブプログラミング(サーバサイド)の変遷について見ていく。
第2章 サーバサイドの変遷
2-1 Perl/CGI
'90年代は個人サイトが一般的だったことはすでに述べた。そのサイトの中に掲示板やチャットを設置することも一種の様式美だったが、これは静的なコンテンツを設置するのに比べて高度な知識が要求された。そのため広告入りのレンタル掲示板で済ませる人も多かったが、KENT WEBのようなサイトで配布されているCGIプログラムを自力で設置することも、さほどめずらしいことではなかった。
では、CGIとはいったいなんだろうか。これは過去の技術ではなく現在も普通に使われている技術なので知っておいて損はない。
手元にUnix環境がある人は以下のようなテキストファイルを作成してみて欲しい。
print "Hello world!\n";
そしてこのテキストファイル(スクリプト)を以下のようにコマンドラインから実行すると、Hello world!と表示されるはずである。
$ perl hello.pl
ここまではPerlインタプリタにスクリプトを渡して実行する、というあたりまえのことを確認したにすぎない。このスクリプトを以下のように書き換えてみよう。
# !/usr/bin/perl
print "Hello world!\n";
さらにこのファイルに実行権限を与える。
$ chmod +x hello.pl
そしてそれをコマンドラインから直接叩いてみると、さっきと同じようにHello world!と表示されるはずである。
$ ./hello.pl
※起動に失敗する場合はwhich perlコマンドでPerlインタプリタの位置を確認しよう
Unixではスクリプトの1行目でインタプリタを指定し、そのファイルに実行権限を与えると、それ単体で実行できるようになる。これも立派なUnixプログラムなのだ。
そしてこのプログラムをApache等のHTTPサーバから呼び出すのが、CGIと呼ばれる仕組みなのである。このプログラムは実のところ何でもよくて、シェルスクリプトでもいいし、C言語で書いてコンパイルしたバイナリファイルでもかまわない。標準入出力が使えれば何でもいいのである。
参考までに簡単なCGIプログラムを紹介しよう。環境構築できる人は実際に動かしてみて欲しいが、あまり現代的な書き方ではないので、コードを読んで当時の雰囲気だけ感じてもらえれば十分である(HTML5なのはご愛嬌)。
# !/usr/bin/perl
read(STDIN, $buffer, $ENV{CONTENT_LENGTH});
foreach (split(/&/, $buffer)) {
my ($key, $value) = split(/=/);
$value =~ tr/+/ /;
$value =~ s/%([0-9A-Fa-f][0-9A-Fa-f])/pack("H2", $1)/eg;
$post{$key} = $value;
}
print "Content-type: text/html\n";
print "\n";
print "<!DOCTYPE html>\n";
print "<title>Echo</title>\n";
print "<form method=\"POST\">\n";
print "<input name=\"name\">\n";
print "<input name=\"message\">\n";
print "<input type=\"submit\">\n";
print "</form>\n";
print "<p>buffer: $buffer\n";
print "<p>name: $post{name}\n";
print "<p>message: $post{message}\n";
これはブラウザから送信した文字列をCGI側で受け取って表示するだけの単純なエコープログラムである。初回アクセス時には以下のようなHTMLになる。
<!DOCTYPE html>
<title>Echo</title>
<form method="POST">
<input name="name">
<input name="message">
<input type="submit">
</form>
<p>buffer:
<p>name:
<p>message:
テキストボックスに適当に文字列を入力する。
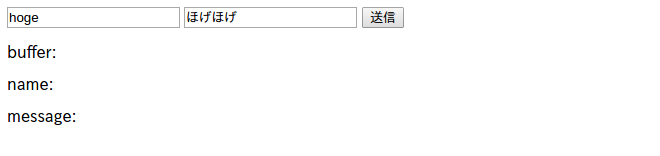
この状態で送信ボタンを押したとき、ブラウザのバックグラウンドでどのような処理が行われるのだろうか。前章ではGETメソッドしか扱わなかったが、今度はPOSTメソッドについて見ていこう。
<form>タグのmethod属性にPOSTが指定されている場合、サーバへの命令はGETではなくPOSTメソッドが使われる。この状態で送信ボタンを押すと、クライアントからサーバに以下のようなメッセージが送信される。
POST /echo.cgi HTTP/1.1
Content-Length: 54
...
name=hoge&message=%E3%81%BB%E3%81%92%E3%81%BB%E3%81%92
1行目はメソッド、2行目はボディの長さである。そしてその他のヘッダ、空行をはさんで、ボディ(フォームから送信されたデータ)が続く。こういったメッセージがクライアントからサーバに送られたとき、CGI側では標準入力からボディデータを読み込めるようになっている。
クライアントからの申告Content-Length: 54は環境変数$ENV{CONTENT_LENGTH}に格納されているので、この申告を信用して、標準入力STDINからその分だけボディデータを読み込み、変数$bufferに格納する。
read(STDIN, $buffer, $ENV{CONTENT_LENGTH});
フォームから送信されたデータは<input>要素ごとに&で区切られているのでまずはそれをsplit()で分解し、ループ処理する。
foreach (split(/&/, $buffer)) {
さらにそれらは=でフィールド名と値のペアになっているので、またsplit()で分解する。
my ($key, $value) = split(/=/);
値はエンコードされているのでデコードし、連想配列に格納する。
$value =~ tr/+/ /;
$value =~ s/%([0-9A-Fa-f][0-9A-Fa-f])/pack("H2", $1)/eg;
$post{$key} = $value;
その結果が以下のようにブラウザにレンダリングされる。
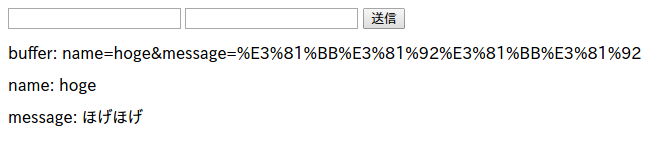
このプログラムではただ受け取ったデータを表示しているだけだが、テキストファイルやデータベースに保存し、それを表示するようにすれば、立派な掲示板プログラムの出来上がりだ。
最近はフレームワークを使って開発するのが主流になっているので、こういった低レイヤの知識が必要とされる場面はあまりないかもしれないが、ここを理解していれば、設計やコーディングのレベルがぐんと上がるはずである。
そして次は言語レベルでこのあたりを吸収してしまったPHPについて見ていこう。
2-2 PHP
PerlからPHPに移行したとき、当時のウェブプログラマはどのように感じたか。これは解説するよりも実際のコードを見比べるのがいちばん早いかと思う。
前節のCGIプログラムをPHPで書くと以下のようになる。
<!DOCTYPE html>
<title>Echo</title>
<form method="POST">
<input name="name">
<input name="message">
<input type="submit">
</form>
<p>name: <?php echo $_POST['name'] ?>
<p>message: <?php echo $_POST['message'] ?>
実際のプロダクトはもっとプログラム的な要素が多いのでこれは少し誇張されているきらいはあるが、かなりすっきりしたように感じられないだろうか。この「すっきり感」にはいくつか理由がある。
まずPHPにはスーパーグローバルという定義済みのグローバル変数があり、ここにパース済みのPOSTデータが格納される。これはモジュール等ではなく言語レベルでの実装なので、何もしなくても$_POST['xxx']とするだけでユーザがフォームから送信したデータを参照できるのである。
そしてHTMLを出力するのにprint文が不要というところも画期的であった。プログラムの中にHTMLを書くのではなく、HTMLの中にプログラムを書く、という発想の転換である。なんらかのテンプレートエンジンを使うのが主流の現在ではすっかり忘れ去られてしまった感があるが、PHPのいちばんの特色はここにあった。PHP自体がひとつのテンプレートエンジンだったのだ。
他にも、file_get_contents()という組み込み関数1行でファイルの読み込みができたり、かゆいところに手が届く設計であった。このファイル読み込み系の関数もデータベースが主流になってしまった現在ではあまり使う機会はなくなってしまったが。
さて、PHPもv3やv4のころはまだ上記のような牧歌的なコードが多かった。しかしv5になると本格的なオブジェクト指向プログラミングが可能になり、一気にモダンな雰囲気になっていく。Smartyの流行でプログラム機能とテンプレート機能が分離され、さらにその流れはMVCフレームワークへとつながっていく。
2-3 MVCフレームワーク
MVCフレームワークの解説の前に、ひとつ根本的なところを問おう。そもそもプログラミングとは、何だろうか。人によって、視点によって、答えはさまざまだと思うが、筆者の解答はこうだ。プログラミングとは、機械の言葉を人間の言葉に翻訳する作業である。
どのようなプログラミング言語も最終的には0と1からなる機械語に翻訳される。なぜなら現行のCPUがそれしか解さないからだ。最初期のプログラミングは、その機械語を使って直接CPUに語りかける作業であった。しかしこれはあまりにも人間離れした行為である。「01010101、00110011」などと喋るのはつらい。だから当然の流れとして、これを人間の言葉に近づけようという動きが起こる。アセンブリ言語等の低級言語がそれにあたるが、これは「0001」は「あ」といったように機械語と自然言語の変換表を作ったにすぎず、やはり文法は機械語のままであった。文法も自然なものにしようとして生まれたのが、C言語をはじめとする高級言語である。こういった高級言語で書かれた文章を翻訳した機械語は、自然言語同士の機械翻訳と同様、どこかたどたどしいものになってしまうため、それを解釈するCPUの動作効率は落ちてしまうが、そういったデメリットよりも、自然言語に近くなったことによって、より複雑なプログラムを組めるようになったメリットのほうが遥かに大きかった。たとえば極端な例だが、Excelを機械語・アセンブリ言語で書くことは、理論上は可能であっても、事実上不可能である。それは低級言語で書くには複雑すぎるからだ。そしてExcelの有用さ、社会に与える影響の大きさは、誰もが知る通りである。プログラミング言語の進化の歴史は、機械の言葉を抽象化し、自然な言葉に近付けることによって、より複雑、より大規模なシステム開発に耐えられるようにしようと試みる、抽象化の歴史なのである。MVCフレームワークも、この流れの一端にすぎない。
前置きが長くなってしまったが、ここからは実際のコードを使って解説していこう。以下はシンプルなMVCフレームワークの上に作った掲示板プログラムである。
<?php
class Post extends Model {
}
class PostsController extends Controller {
protected $viewEngine = 'Print';
public function add($name = 'anonymous', $message = '') {
$post = new Post();
$post->name = $name;
$post->message = $message;
$post->save();
$this->view->set('success', true);
$this->view->set('name', $post->name);
$this->view->set('message', $post->message);
}
public function show() {
$this->view->set('title', 'Message Board');
$this->view->set('posts', Post::findAll());
}
}
// 以下、フレームワーク
abstract class Model {
protected $fields = [];
public function __set($name, $value) {
$this->fields[$name] = $value;
}
public function __get($name) {
return $this->fields[$name];
}
public function save() {
$json = json_encode($this->fields);
file_put_contents(get_class($this).'.txt', $json."\n", FILE_APPEND);
}
public static function findAll() {
$all = [];
foreach (file(get_called_class().'.txt') as $json) {
$all[] = json_decode($json, true);
}
return $all;
}
}
abstract class View {
protected $vars = [];
abstract public function render();
public function set($key, $value) {
$this->vars[$key] = $value;
}
}
class PrintView extends View {
public function render() {
print_r($this->vars);
}
}
class JsonView extends View {
public function render() {
echo json_encode($this->vars)."\n";
}
}
abstract class Controller {
protected $view;
protected $viewEngine;
public function __construct() {
$viewClass = $this->viewEngine.'View';
$this->view = new $viewClass();
}
public function invoke($action, $args) {
call_user_func_array([$this, $action], $args);
$this->view->render();
}
}
$controllerClass = $argv[1].'Controller';
$controller = new $controllerClass();
$controller->invoke($argv[2], array_slice($argv, 3));
わかりやすくするため、HTTPサーバからではなくコマンドラインから使うようにした。まず、以下のようにコマンドラインから新しいメッセージを投稿する。
$ php bbs.php Posts add hoge hogehoge
Array
(
[success] => 1
[name] => hoge
[message] => hogehoge
)
第1引数はコントローラ、第2引数がアクション、それ以降はアクションに渡す引数となる。投稿したメッセージを見るときは以下のようにshowアクションを使う。
$ php bbs.php Posts show
Array
(
[title] => Message Board
[posts] => Array
(
[0] => Array
(
[name] => hoge
[message] => hogehoge
)
)
)
これはデータベースさえ使っていない非常にシンプルなMVCフレームワークだが、その基本的な考え方を理解するには十分な要素が詰まっている。
まず、フレームワークを使うプログラマ側が定義しているのはPostクラスとPostsControllerクラスだけである。これだけのコードであとはフレームワークがよしなに計らってくれる。たとえばPostsControllerの$viewEngineをJsonに書き換えて実行してみよう。print_r()ではなく、JSON形式で結果表示されるはずである。このように、プログラマ側はフレームワーク側が必要とする情報を与えるだけでいいのだ。単機能のライブラリとフレームワークの違いはここにある。前者の場合は「ここはこうして、そこはああして」とプログラマ側が逐次命令を与える形だが、後者の場合は、「ここはどうするの? そこはどうなるの?」というフレームワーク側からの問いかけに逐次答える形になる。前者は「使う」ものであり、後者は「使われる」ものなのだ。これを制御の反転という。そしてMVCというアーキテクチャを実現するためにこの手法を用いるのが、MVCフレームワークなのである。
MVCはModel/View/Controllerの略である。モデルがデータやビジネスロジック、ビューが表示、コントローラが操作を担当するが、このあたりはきっちりとした境界があるわけではなく、モデルが担当するはずのビジネスロジックがコントローラに食い込んだりといったことはよくある。状況によりけりなので、このあたりは他人のコードを読んだり、自分で試行錯誤して、最適解を最速で見つけられる知見を自分の中に蓄積するしかない。そしてそのためには基礎部分への理解が不可欠である。
完成形のMVCフレームワークは大規模すぎてその全容を把握することは困難だが、上のようなシンプルなMVCフレームワークなら、モデルの保存方法を変更したり、ビューの種類を増やしたりといった改造は容易である。そうして基礎部分、根本的な部分への理解を深めておけば、CakePHPのような完成形のMVCフレームワークを使う祭にも、その知見は必ず活かされる。MVCフレームワークを使っているけどその仕組みがよくわからないという人は、上のプログラムを自分でいろいろ改造してみよう。
2-4 REST
前節のプログラムではコマンドラインからコントローラ・アクション・引数を指定しているが、これを/posts/showといったようなURIで表現するのが一般的なウェブ系フレームワークの手法である。しかし最近はコントローラのアクションをURIで指定するのではなく、代わりにHTTPメソッドを使おうという潮流がある。
どうしてそんな潮流が生まれたのだろうか? /posts/showは投稿データを表示せよといった意味で非常にわかりやすい。/posts/delete/1234は投稿データを削除せよといった意味だ。これでいいではないか。しかしこれは送信されるHTTPリクエストを見てみると、その文意が明らかにおかしいのがわかる。
<a href="/posts/delete/1234">削除</a>
このリンクをクリックしたとき、クライアントからサーバに送信されるHTTPリクエストは以下のようになる。
GET /posts/delete/1234 HTTP/1.1
これを文章として読むと、「投稿データID1234を削除するためのリソースを取得せよ」、つまり、削除フォームのページを表示するような意味になる。削除という「行為」それ自体はサーバに命令されていないのだ。
GET等の命令のあとに続くのはリソース指定であって、そこにさらに命令が置かれるのは動詞に動詞を重ねることになってしまっておかしい。だからここに動詞があったとしても、それはリソース指定の補語としての意味しか持たない。たとえば、/search?query=wordのときのsearchは動詞ではなく、search_resultの意である。このときは検索結果というリソースを指定しているのであって、サーバに検索という「行為」を命令しているわけではない。/posts/createのときのcreateはcreate_formの意である。新規作成のためのフォームというリソースを指定しているのであって、サーバにデータの作成そのものを命令しているわけではない。HTTPリクエストは「このリソースに対してこうせよ」という、動詞・目的語の2つで完結する、単純な命令文にしなければならない。
以上の説明からGET /posts/delete/1234というHTTPリクエストが削除という「行為」を求めるものではないことがわかるかと思う。ではサーバに「行為」を求めるにはどうすればいいか。ここで「HTTPメソッドを使おう」という話になってくるのである。
上の例だとこうなる。
DELETE /posts/1234 HTTP/1.1
GETのときは文脈を読み手側で推測する必要があったが、今回は非常に簡潔で、誰が読んでも明瞭な文章だ。「/posts/1234というリソースを削除せよ」以外の意味に取りようがない。そしてこの簡潔さ・明瞭さというのは、開発の世界における絶対正義である。
ならなぜいままでこの手法が取られてこなかったのか? それはブラウザの<form>タグがGETとPOSTにしか対応していないからである。かつてのブラウザ主体のウェブサービスは、この2つのメソッドを駆使するしかなかったのだ。しかしJavaScriptで通信する場合、この制限はない。Ajax技術が一般的になったこと、日ごと大規模化していくウェブサービスに対してシンプルなアーキテクチャが求められたこと、さまざまな要因がからみあった結果として、RESTへの回帰という潮流が生まれたのである。
SQLの主要なメソッドがINSERT、SELECT、UPDATE、DELETEであることからもわかるように、データに対して行う操作は作成、読み取り、更新、削除の4つがあれば十分である。これをHTTPメソッドにあてはめると、POST、GET、PUT、DELETEとなる。このメソッド群を使って指定したリソースに対して操作を行えるサービスを、RESTfulであると表現する。
RESTに関しては簡単なようで実はかなり奥が深い概念なのでここでは解説しない。前章で紹介した「Webを支える技術」を読むことをおすすめする。ウェブサービスのアーキテクチャ設計・リソース設計をする人は必読の書である。
ちなみに最近のウェブ系フレームワークでは<input type="hidden" name="_method" value="DELETE">といったような隠し要素で、擬似的なHTTPメソッドを実現可能なものが多い。ただ、これは結局POSTメソッドを使っていて、クライアントから送信されたデータの中に_methodというフィールドがあればそのメソッドに置換する、というフレームワーク側の吸収にすぎない。非SPAなブラウザ版とスマホアプリのWebAPIを共通化したい場合等には有効かと思われるが、やはり複雑さは上がってしまうので、使いどころには注意されたい。
2-5 Node.js
日ごと大規模化していくウェブサービスで問題になるのは複雑さだけではない。処理能力も大きな問題である。
'00年代も後半になるとインターネットの総人口は爆発的に増え、ウェブサービスに求められるスケールが10年前とは比較にならないほど大規模になっていった。それは時代の流れとして止められなかった。クラウドによってスケールアウトは容易になったが、それでも根本的な問題、「1台のサーバが同時に処理可能なクライアント数には限界がある」という問題、C10K問題は解消されなかった。ハードウェア的な解決だけではなくソフトウェア的にも根本的な解決が求められた。
そんな中でシングルスレッド・イベントループという非同期の仕組みが注目され始めた。ひとつのスレッドで複数の接続をイベントループで処理すればコンテキストスイッチが発生しないので高速に動作するし、メモリの消費量も抑えられる、という解決法である。nginxが有名だが、これはあくまでHTTPサーバであり、ここから(FastCGI)プログラムを呼び出せば、やはりC10K問題に引っかかってしまう。そういった問題がある中、サーバサイドでプログラムを実行する環境としてNode.jsが注目されていった。
Node.jsはJavaScriptで記述可能なサーバサイドアプリケーションプラットフォームである。最初は勘違いする人が多いが、これはPerl/CGIやApacheのPHPモジュールとは違い、HTTPサーバから呼び出すものではなく、Node.jsのプログラム自体がサーバになるのである。
これは実際のコードを見るのが早いかと思う。
console.log('Hello world!');
このスクリプトをコマンドラインから実行すると"Hello world!"と表示して即時終了する。これは普通のプログラムである。
$ node hello.js
Hello world!
今度はhttpモジュールを使ってサーバ化してみよう。これを実行すると、即時終了せずにクライアントからの接続を待ち受ける。
var http = require('http');
var server = http.createServer();
server.on('request', function(req, res) {
res.write('Hello world!\n');
res.end();
});
server.listen(3000);
別のターミナルを開いて、このサーバプログラムにcurlコマンドでアクセスしてみる。
$ curl -v http://localhost:3000/
* Hostname was NOT found in DNS cache
...
> GET / HTTP/1.1
> ...
>
< HTTP/1.1 200 OK
< ...
<
Hello world!
* Connection #0 to host localhost left intact
Hello world!とレスポンスが返ってきているのが確認できる。
今度は以下のようなファイル配信サーバプログラムを作成して実行してみよう。
var path = require('path');
var fs = require('fs');
var http = require('http');
var server = http.createServer();
server.on('request', function(req, res) {
console.log('request: ' + req.url);
fs.readFile(path.join('.', req.url), 'utf8', function(err, data) {
res.write(data);
res.end();
});
});
server.listen(3000);
そしてまた別のターミナルからcurlコマンドでアクセスしてみる。今度はURIで/hello.jsをリソース指定してみよう。
$ curl -v http://localhost:3000/hello.js
* Hostname was NOT found in DNS cache
...
> GET /hello.js HTTP/1.1
> ...
>
< HTTP/1.1 200 OK
< ...
<
var http = require('http');
...
* Connection #0 to host localhost left intact
リソース指定した/hello.jsの内容が返ってきているのがわかる。別のリソースを指定してもファイルが存在するならうまくいくはずである。これで立派なファイル配信サーバの出来上がりだ。Node.jsのプログラムはHTTPサーバから呼び出すものではなく、それ自体がサーバになるのだ、ということが実感できたかと思う。起動して、処理をして、終わり、ではなく、起動したら、接続を待ち受けて、クライアントからのアクセスがあるたびに、requestイベントに登録されたコールバックを実行するのだ。
上のプログラムはただ指定されたファイルを返しているだけだが、クライアントからの要求をもとにデータベースに接続して、さまざまな処理をして……というようなプログラムを組めば、いままでPerl/CGIやPHPでやっていたことがNode.jsでも実現できる。そのサーバプログラムは、クライアントから直接アクセスさせてもいいし、nginxをリバースプロキシサーバにして、Node.jsをバックグラウンドで動かしてもいい。覚えておきたいのは、後者の場合でも、nginxとのやりとりはHTTP通信である、ということだ。もう一度言うが、Node.jsのプログラムは、それ自体がサーバなのである(もちろんそうでないプログラムも組めるが)。
そしてnpmのモジュールを使えば、いろんな種類のサーバプログラムが組める。Expressで本格的なHTTPサーバも組めるし、Socket.IOでWebSocketを使ったリアルタイム双方向通信サーバも組める。Node.jsの真価は、シングルスレッド・イベントループで大量のアクセスをさばけることではなく、このnpmによるエコシステムにあると言っても過言ではない。
現状ではNode.jsを採用する場面はあまりないかもしれないが、向いているのは以下のようなサービスである。
- WebSocketを使った常時接続のリアルタイム双方向通信サーバ。たとえばチャットや、Googleドキュメントの共同編集のような機能を実装するとき。
- SPA/スマホアプリ用のRESTful WebAPI。アクセス量が多く軽い処理ばかりの場合に特に向いている。逆に重く複雑な処理になる場合は普通にPHPのMVCフレームワークを使ったほうがいい。
Node.jsを採用するメリットは、クライアントサイドと言語を統一できること等いろいろあるが、デメリットもそれなりに多い。
まず最初に、非同期プログラミングが非常に難しい、ということが挙げられる。現在クライアントサイドのJavaScriptがそれなりに書ける人でも、Node.jsでまともなコードを書けるようになるまでに、半月〜1か月はかかると見ておいたほうがいい。それくらいクライアントサイドとはまったくの別物である。どうやってクライアントサイドとコードを共通化するのか、どのあたりが共通化できるのか、ということを見極められるようになるのは、Node.jsを「モノにした」あとだ。
もうひとつのデメリットは、実行環境が非常にピーキーだということである。Node.jsは基本的には高速に動作するが、ふとしたきっかけでガクンと速度を落としてしまうことが頻繁にある。シングルスレッド・イベントループの利点を保つにはシビアな調整が必要であり、それには開発中、常にベンチマークを取り続ける以外にない。
しかしそういったデメリットをすべて吹き飛ばしてしまうほどの不思議な魅力がNode.jsにはあるのだ。コードを書いていて楽しい、というのは、やはりプログラマにとって重要なファクターである。
さて、ここまでサーバサイドの変遷を振り返ってきたが、これは別に後発のものほどいいという話でもない。Perl/CGIはいまでも普通に使われている技術だし、PHPはまだまだメインストリームだし、Node.jsが最先端というわけでもない。ただこういう流れがあったというだけだ。しかしこういう流れがあったことを知見として持っておくことによって、説得力と納得感のある設計・コーディングが可能になるのである。
ウェブ開発の世界は変化が激しく、情報量の多さに心が折れそうになるかと思うが、本当に大切なことは、さして多くない。そして本当に大切なことは、とても基本的で、とてもありふれたことばかりなのだ。ここまでフレームワークやライブラリを一切使わずに解説を続けてきたのは、そのことを知ってもらいたかったからである。
第3章 モダン化するウェブ
3-1 掌編小説「スポラディックE層を待ちながら」
その少年は中学校で無線部に所属していた。入学した当初は運動部に入っていたが、めんどくさくなって3日でバックレた。しかしその学校には生徒は全員なんらかの部活に所属しなければならないという謎ルールがあったため、気が進まないながらもなんとなく入部したのが、部員数ゼロの「幽霊部活」、無線部だった。部室は校内の片隅にあり、顧問もめったに来ない隔離施設のような場所だったが、家庭環境が悲惨だった彼は、できるかぎりの時間をその狭く埃っぽい場所ですごした。
彼は学校の授業をまともに受けたことはほとんどなかったが、本を読むことや何かを学ぶこと自体はとても好きだった。だから部室に置いてあった教本を勝手に読み、アマチュア無線4級の試験を勝手に受け、合格した。
長らく使われていなかったのか埃をかぶってはいたものの、部室にはちゃんとした設備があった。開局もしていたのでコールサインもあった。それを使って初めてCQを出した日、誰からも返事はなかった。次の日、またCQを出した。返事があった。ドキドキした。
それからいろんな人と交信した。QSLカードもたくさん交換した。しかしどれだけがんばっても部室にある設備では県内の人との交信が精一杯だった。
ある日のこと、突然、数百キロ離れたところにいる人との交信に成功した。しかもすぐ近くにいるかのようなクリアさで。相手は別段驚いた様子もなく、「ああ、いまEスポが出てるね」と言った。ごくまれに出現するスポラディックE層というこの特殊な電離層は、通常では不可能な長距離通信を可能にするのである。少年は思った。数百キロ離れたところにも世界は広がっている。そこにも人がいて、その人にも人生があって、いまこうして自分と話をしている。それはなんだか、とてもワクワクすることだと。
3-2 陽のあたる場所へ
上に見たように、インターネット普及以前、遠距離の見知らぬ人間と交流する方法は極めて限られていた。アマチュア無線や雑誌の投稿欄等が擬似的にそのプラットフォームとしての役割を果たしたが、参入の難しさや、リソースの関係上、さほど大きなプラットフォームにはならなかった。
'90年代前半はポケベルの時代だった。最初は数字しか送れなかったが、カタカナ表現ができるようになってから、中高生を中心に爆発的な人気を得た。このときのカタカナ表現、「11」が「あ」、「25」が「こ」といった入力方法は、後の携帯電話の日本語入力に影響を与えた。
'90年代後半はPHSが流行したが、まだ電話を携帯するということ自体は、あまり一般的なものではなかった。
'00年代前半になると携帯電話が普及し始める。ひとり1台持つのがあたりまえになっていくが、履歴書等の連絡先の欄に携帯電話番号を書くと、変な顔をされる時代であった。まだ固定電話を持っているのがあたりまえであり、携帯電話はその補助的位置付けにすぎなかった。
インターネットと現実世界にはまだ断絶があったが、人々は知らず知らずのうちにインターネットを使用していた。おもにi-mode、メールといった形で。「なんでメールにすぐ返信くれないの!」という悲劇はこのころによく発生した。「いやメールはそもそも非同期で……」と説明しても、理解してくれる人は少なかった。
'00年代後半になるとインターネットと現実世界は急速に融合を果たしていく。これはどこかに突出したブレークスルーがあったわけではなく漸次的なものだったが、あえてひとつの節目をあげるとすれば「電車男」がそれにあたる。このあたりからインターネットのアンダーグラウンドなイメージが書き換えられていく。かつて得体のしれないもの、薄気味悪いものとして忌避されていたインターネットは、ライトでポップなものとして一般層に受け入れられていく。サブカルチャーからメインカルチャーへと急速に引き上げられていく。
'10年代に入るとスマホ/タブレットが普及し始める。電車内では本や新聞を読んでいる人より、スマホをいじっている人のほうが多くなっていく。物理ボタンがないことへの抵抗感から忌避する人も多かったが、その便利さの前には勝てず、翻意していった。
そしてSNSの急速な拡大、モバイル環境の整備、等々を経て、インターネットはもはやインフラという次元を超えて、人々の日常に溶け込んだ存在になっていく。Youtubeの初出は2005年であるが、このときはまだブロードバンドがあまり普及しておらず、筆者は「動画サイトなど流行るわけがない」と思っていた。しかし実際はどうか。いまやテレビでYoutube映像を流す時代である。真面目なニュース番組でTwitterの投稿がリアルタイムで流れる時代である。10年前に誰がこんな状況を予想しただろうか。世界はもはや誰も想像しえなかったフェーズに突入している。
インターネット上のWebAPIは、「ひとつのことをうまくやれ」というUnixの哲学に従うかのように互いに連携しあい、HTTPが標準入出力/パイプの役割を果たし、まるで惑星全体がひとつの大きなコンピュータであるかのように振る舞う。
海底を這う光ファイバーケーブルは神経索のように伸び、国家間をつなぎ、この惑星をおおっていく。背骨に沿って伸びた神経索の末端が肥大化して「脳」と呼ばれるまでになったように、それは近い将来、何か別種のものに変化を果たすのかもしれない。
仮想空間のみならず現実でもつながりすぎてしまった世界は、国家単位ではなく惑星単位での富の再分配について考えなければならない段階に突入した。パナマ文書がその契機となるか、今後の動向に注目したい。
第4章 インターネットのイデオロギー
4-1 標準化≠デファクトスタンダード
インターネットに中心は存在しない。首都、国会、内閣、最高裁判所、そういった明確な中心がないのである。あえていえばW3C等の標準化団体がそれに該当するが、これらは決して立法府でも行政府でもない。標準化団体は文字通り標準化を推進するが、そこになんらかの強制力が存在するわけではない。インターネットのイデオロギーは民主主義ではないのである。
民主主義であれば、法を策定する政治家が舞台から降ろされることはあっても、策定された法それ自体が無視されることはない。それがどのような悪法であっても、である。その悪法をなかったことにするためには、また民主的なプロセスが必要になる。そうでなければ民主主義は成り立たない。
しかしインターネットの世界はそのようなプロセスを必要としない。策定されたルールが筋の悪いものであれば、ただ民衆から無視され、なかったことになるだけである。標準化されたものがデファクトスタンダードになるのではなく、デファクトスタンダードになったものが結果として標準化されるのだ。そして標準化されたときにそれがもはやデファクトスタンダードではなかったとしたら、そのルールはやはり無視され、なかったことになるだけである。変化の激しいインターネットの世界では、こういった事態はさして珍しいものでもない。
4-2 見えざる手に導かれて
それではインターネットのイデオロギーは自由主義なのだろうか? 個々が自らの利益を最大化しようと動いた結果として、見えざる手に導かれるように、最適な均衡状態に至るのだろうか?
ここでOSSの世界にフォーカスしてみよう。OSSの主要コミッターには有名なIT企業の従業員が名を連ねていることが多い。しかも勤務時間のすべてをそのOSSの開発に費やしていることもままある。なぜ企業はこんな投資をするのだろうか? これはCSR活動なのだろうか? もちろんそういった側面もあるだろうが、実のところ、これはとてもありふれた営利活動である。
OSSのプロダクトを自社で使用する際に、そのプロダクトをフォークして自分たちに必要な機能だけを差分開発するとしよう。しばらくはそれでうまくまわるが、もしもそのプロダクトが大きなバージョンアップをしたとき、どうなるか。これまで独自開発してきたその差分の適用に多大な労力を要することになる。つまり多大なコストがかかる。ならば最初からそのOSSのプロダクトに直接コミットしてしまったほうがいい、という最適化がなされる。これは、フォークして差分開発するコスト > OSSに直接コミットするコスト + ライバル企業に技術を提供してしまうデメリット、という単純な不等式の解であり、とてもありふれた営利活動なのだ。その結果、ライバル企業の従業員同士がOSSで肩を並べて共同開発するという均衡状態が生まれるのである。
このような例を見れば、なるほどインターネットは自由主義である、完全な自由市場が全体にとって最適な結果をもたらしているのだ、と言える。
しかし本当にそうだろうか。現実の歴史を振り返ってみれば、「レッセフェール」は決して万能の呪文ではなかった。それは1929年にも、2008年にも、これまで何度も何度も証明されてきたことだ。市場には政府による規制が必要なのだ。さもなければ破綻するのが宿命だ。
しかしインターネットには規制らしい規制はほとんど見受けられない。それで破綻することもなく成り立っている。なぜか?
ここで今度は現実世界のおもしろい事例を紹介しよう。「腐る貨幣」の話である。
4-3 腐る貨幣
当然のことだが紙幣は腐らない。コインも腐らない。しかしこれまた当然のことだが食べ物は腐る。その他の耐久消費財も時間の経過とともに確実に減価する。会計に明るくなくても減価償却という言葉くらいは聞いたことがある人も多いだろう。
古代、金や銀や塩が価値の代替表現として使われていたのは、それらが腐らないからであった。そして持ち運びしやすいように、金や銀はコインという形態になり、さらに持ち運びしやすいようにコインとの引換券という形態になり、紙幣が生まれた。貨幣が貨幣たりうる最も重要なファクターは、腐らないこと、いつでも交換可能なことなのである。
だから貨幣はいつでも交換できる。いまこの瞬間に消費しなくてもかまわない。ひるがえって、消費財の交換には時間制限がある。早く消費しなければどんどん減価してしまう。この違いによって、貨幣を持つ側と消費財を持つ側との間に権力構造が生じ、資本は資本を元手に肥大化し、富の一極集中が起こり、経済が停滞し、恐慌や戦争に至るのだ、これはおかしいではないか、と考えた経済学者がいた。
そして「腐る貨幣」を発明した。具体的に言うと、一定期間ごとに額面に応じたスタンプを購入して貼らないと使えない、スタンプ貨幣である。これはまさに時間とともに腐っていく貨幣だと言える。
こんなものは貨幣として成り立たないと思うだろうか? ところがどっこい、このスタンプ貨幣を地域通貨として導入した街は、経済活動がおおいに活発になった。なぜだろうか?
人間は自身の利益を最大化しようとする生き物である。誰だって得したい。従来通りの貨幣なら腐ることもなく、場合によっては利子さえ付くので、貯めておくほうが得だ。消費や投資にまわすのは、そちらのほうが得な場合だけだ。
しかし貨幣が腐る世界では、貨幣の価値が時間の経過とともに確実に減少していくので、貯めておくより早めに使って同等の価値の財やサービスに形を変えたほうが得になる。そしてそれを受け取った人も、その貨幣を早めに使ってしまったほうが得になるので……というループ構造により、貨幣の流通スピードが加速し、経済活動が活発になるのだ。
世界恐慌のまっただ中、オーストリアにあるヴェルグルという街は、地域通貨としてこのスタンプ貨幣を導入し、前述のような過程を経て、地域経済の再建に成功したのである。
しかしこういった小さな経済圏での成功例があるからと言って、国家の法定通貨もこの仕組みにしようというのは早計にすぎるだろう。よりマクロになればなるほど、この仕組みからの逃げ道も多くなるからだ。よりマクロな状況では、法定通貨の代わりに別のものが貨幣の役割を果たすようになるだけであろう。
しかしそういった逃げ道がない状況というのも、たしかに存在する。中央銀行の当座預金がそうであり、インターネットの世界における技術トレンドがそうである。
4-4 資本主義 feat.インターネット
ここからがこの章の本題である。
前節では話をシンプルにするためにわざと省略したが、貨幣が貨幣たりうる条件は「腐らないこと」だけでは足りない。それでは石ころだって条件に当てはまってしまう。もうひとつの重要な条件は、誰もがその価値を認めているということである。金や銀は誰もがその価値を認めていたからこそ、どこに行っても同等の価値のものと交換が可能で、だから貨幣として使うことができた。その交換券である紙幣も、いつでも金や銀に交換することができたからこそ、ただの紙切れが貨幣となりえた。そして金や銀に交換できなくなっても、誰もがまだそこに価値を認めているからこそ、ただの紙切れが、いま現在も貨幣として使われているのである。福沢諭吉のブロマイドになぜ1万円分の価値があるかと問われたら、「だってみんながそう思ってるから……」という小学生レベルの解答でかまわない。為替も株も、いや世界中のあらゆる市場が、このとてつもなく単純な原理で動いているのである。
インターネットという仮想空間において、誰もが価値を認めるものとは何だろうか? それは技術である。それもデファクトスタンダードの技術だ。だから営利団体は自分たちの利益のために次のデファクトスタンダードを創りだそうとするが、これはたいてい失敗に終わる。本章の初めに述べたように、そんなことをしても筋が悪いものなら無視されるだけだからだ。しかし逆に、それが良質なものであれば、それを創ったのが営利団体であろうと非営利団体であろうと関係なく受け入れられる。だから彼らが自らの利益を最大化するには、自分たちの利益だけを考えるのではなく、公益について考慮しつつ、技術に対して真摯に取り組む必要がある。このあたりは現実の社会でも同じである。
ここからがインターネット特有の現象だ。ご存じのように、ここはドッグイヤーの世界である。現在デファクトスタンダードな技術が、1年後もそうだとは限らない。この世界の技術はすぐさま陳腐化する。この「資本」は時間の経過とともに確実に減価する。それも、とてつもないスピードで。そしてそれは誰にも止められない。これは、「腐る貨幣」なのである。そしてこの資本は別の形に変えることができない。そんなことをしても意味がない。だから逃げ道がない。
OSSの話を覚えているだろうか。あの不等式、フォークして差分開発するコスト > OSSに直接コミットするコスト + ライバル企業に技術を提供してしまうデメリット、という不等式を成り立たせるものはなんだろうか。それは、両辺に隠れている、「技術の変化スピード」という係数である。もしもこの係数がなければ、もしくは、十分に変化スピードが遅ければ、この不等号は逆向きになるはずである。この「技術の変化スピード」という係数こそが、インターネットの自由市場を成立させる鍵なのだ。
技術の変化スピードが十分に速ければ、資本がひとところに滞留しない。資本が資本を元手に肥大化しない。富の一極集中、技術の寡占が起こらない。今日の富者は明日の貧者かもしれない。だから絶対的な権力が発生しない。権力構造はいつも絶妙なバランスの上で均衡状態に至る。誰もが自身の資本の価値を高めようと奔走する。しかしどのような手を尽くしても、未来は誰にもわからない。世界中の人間の集合演算結果を知ることは誰にもできない。だからこの仮想空間を誰も制御できない。誰も占領できない。誰にも支配できない。
たしかにこの世界の技術トレンドは変化が激しすぎる。もはや異常と言ってもいい。しかしもしもこの仮想空間が変化することをやめてしまったとしたら、そのときは、現実世界と同様に、富の一極集中、技術の寡占が起こり、インターネットは早晩崩壊するだろう。これは、どうしようもなく必要なコストなのだ。
そのコストが高すぎる、コストの支払いが困難な状況がインターネットを危機に晒している、それも一理ある。その不経済を解消することこそが、本エントリの真の目的である。資本の流動性を高め、自由闊達なインターネットを存続させることが、筆者にとっての利益となるからである。
第5章 クライアントサイドの変遷
5-1 HTML
さて、ここからはクライアントサイドの変遷について見ていこう。そのためにまた時間軸をインターネット黎明期へ戻す。
第1章で述べたように、'90年代のインターネットは牧歌的で、総人口も少なく、IRCやICQといったオルタナティブなコミュニケーション手段の存在もあり、ウェブ(World Wide Web)に求められる機能はさほど多くなかった。だから当然ながらそのクライアントソフトウェアであるブラウザも、さほど高機能なものではなかった。エキサイトチャットというリアルタイムチャットの人気サービスがあったが、こういった高度なプログラムがブラウザ上で動いているように見えても、それはJavaアプレットというブラウザの外側にあるものの能力であり、ブラウザ自身の能力ではなかった。
しかしいくつかの機能を組み合わせることによって、ブラウザ自身の能力だけでもチャットを実現することはできた。参考としてKENT WEBのYY-CHATのサンプルを見てみよう。注目して欲しいのは「リロード:40秒」という記述である。当時のチャットは<meta http-equiv="refresh" content="40">といったタグをHTMLヘッダに仕込むことによって、一定間隔ごとにクライアント側でページのリロードを行っていたのだ。これと<form>タグによる投稿で、擬似的にリアルタイムチャットを実現していたのである。
どうしてこんなタイムラグの発生する方法を取っていたのだろうか? それはサーバ側からクライアント側へイベントの発生を伝達する手段がなかったからである。チャットの参加者が新しくメッセージを投稿しても、それを本人以外に伝えるためには、サーバから他の参加者のクライアント、つまりブラウザへ伝達しなければならない。現在ならWebSocketによる常時接続・双方向通信が可能だが、当時はそんな技術はなかった。だからクライアントのほうから一定間隔ごとに新しい投稿がなかったか逐一確認してもらうという方法しか取れなかったのである。この手法をポーリングと呼ぶ。ちなみにこのポーリングとWebSocketの間にはCometという技術があったが、ここでは詳しくは解説しない。興味のある人は自分で調べてみて欲しい。
当時のブラウザは、指定されたURIをもとに、サーバに接続して、リソースを取得し、レンダリングする、というただの閲覧ソフト、ドキュメントビューアでしかなく、そこにいくつかの便利機能が付属しているにすぎなかった。その機能をうまく組み合わせてウェブアプリケーションとして成り立たせていただけであり、アプリケーションとしての機能のほとんどはサーバサイドにあった。'90年代のクライアントサイドには、プログラム的な要素はほとんどなかったのである。
'00年代に入ってもそれはあまり変わらなかった。そもそも当時はプログラムと言えばVector等の配布サイトからダウンロードし、PC内部にインストールして使うものであり、ブラウザ上で本格的なプログラムを実行するという発想がほとんどなかった。どうしてもブラウザ上で高度なプログラムを動かす必要があるときは、ブラウザの外側の能力、JavaアプレットやActiveX等の技術を用いて実装するのが常であった。
5-2 JavaScript
'00年代前半、IEコンポーネントを利用した個人開発のブラウザが流行した。以下はそのひとつ、MoonBrowserの実行画面である。
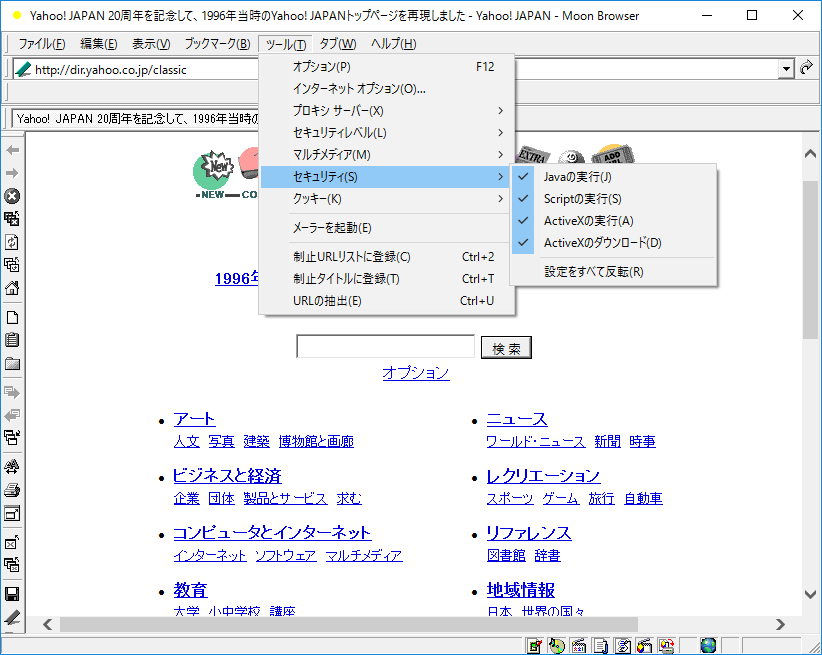
Windows10上で実行しているので当時とまったく同じ画面というわけではないが、'00年代前半の個人開発ブラウザの雰囲気は十分に感じ取れるはずである。注目して欲しいのは、ツールバーからセキュリティ設定のオン/オフが可能だということだ。これはウィンドウ左のショートカットアイコンからもアクセスできる。こういった機能は他の個人開発ブラウザでも当然のように実装されていた。なぜか? それは当時のブラウザのセキュリティレベルが低かったこと、そして、ブラウザクラッシャーの類がウェブ上に蔓延していたことに起因する。無限に開き続けるウィンドウ、閉じても復活するウィンドウ、デスクトップを動き回るウィンドウ、FDDにアクセス「ガガガッ!」。最後のは別として、こういったブラクラの類はJavaScriptで作られたものが多く、あるていどリテラシのあるユーザはJavaScriptをオフにするのが一般的であった。だからこういった個人開発のブラウザでは、セキュリティ設定を簡単にオン/オフできるような機能が実装されていたのである。
JavaScriptはいまでこそウェブを動かす主力エンジンのひとつとなっているが、当時はこのような扱いであった。HTMLのドキュメントツリーへのアクセスがDOMで抽象化されたことによって'90年代に比べれば使い勝手はよくなっていたが、それでもブラウザ間の差異は大きく、使われる用途も、上記のようなブラクラか、さもなければステータスバーに文字を流したり、マウスカーソルに変なものを追尾させたりといった、いまいち効果のよくわからない使い方しかされておらず、あまりいいイメージはなかった。当時のJavaScriptは、世界にとって何の意味もない、誰の役にも立たないガラクタでしかなかった。こんな「安物のおもちゃ」で本格的なアプリケーションが作れるなんて、誰も本気で考えはしなかった。GmailとGoogleMapsが登場するまでは。
このふたつのウェブアプリケーションは、確実にこの言語の未来を決定付けた。いや、ウェブそのものの未来を決定付けた。これ以前もダイナミックHTMLという考え方はあったが、ただページを動的に書き換えられる、それでウェブページが少しだけインタラクティブになる、というだけのものでしかなかった。Googleはさらにこの考えを推し進め、ページの動的書き換えだけでなく、サーバとの通信もJavaScriptに委譲することによって、ページ遷移のないウェブアプリケーション、SPA(Single Page Application)を実現させた。これはもはやJavaScriptという言語の範疇に収まらない、ウェブ全体のパラダイムシフトであった。
5-3 Ajax
ページ遷移がなくなることによって何が改善されたのだろうか? 先ほどのチャットでは40秒ごとに毎回毎回、HTMLの最初から最後まで、すべてのデータを取得して、再レンダリングしていた。なるほど、これはこれで問題ない。しかしGmailとなるとどうか。Gmailは起動時にプログレスバーが出ることからもわかるように、その受信データ量はなかなかに巨大だ。筆者の環境ではすべてのデータを読み込み終えるまで待つと、合計で4.7Mのデータを受信していた。起動直後はメール一覧画面になるが、その一覧からメールを開くたびに、また同じようにデータを受信して、再レンダリングするような仕様だったとしたら、どうだろうか。多少ウェブ開発に関わったことのある人間なら誰でもわかることだが、これは完全に使い物にならない。ページ遷移がなくなるということは、この再受信、再レンダリングがなくなるということなのである。
実際のGmailでは、一覧からメールを開いたとき、対象データだけをJavaScriptによる通信で取得し、その結果をもとにHTMLの一部を書き換えている。以前のウェブアプリケーションでは、すべてを受信して、すべてをレンダリングしていたが、SPAでは、必要な分だけデータを受信し、必要な分だけレンダリングするのだ。こういった技術を総合してAjaxと呼ぶ。
Ajax以前もこういった需要はあった。上で見たチャットも、リロードをかけているのは下フレームのログ部分だけなので、これも広義の意味では部分レンダリングであると言えよう。しかしフレームはHTMLが分散するのでロボット型検索エンジンと相性が悪く、バグの原因となることも多かったため、開発者から敬遠されるようになり、次第に廃れていった。そのフレームによる部分レンダリングを代替するものとしてAjax技術が生まれたのは、歴史の必然だったのである。
5-4 クライアントへの委譲
Ajax以前、ウェブアプリケーションの主体はサーバサイドにあったが、Ajax以後、これがクライアントサイドへと移されていくことになる。なぜこのような潮流が発生したのだろうか? これにはさまざまな理由がある。
まず、黎明期に比べてウェブに求められる機能が多くなっていたことが挙げられる。Web2.0というバズワードが発生したのはこのころだが、ウェブの双方向性がやたらと強調されるようになり、情報の発信者と受信者の境界が曖昧になっていった。SNSが流行し始めたのも、この'00年代後半からである。当時はFacebookではなく、mixiだったが。
さらにインターネット人口の爆発的増加により、サーバの処理能力が不足気味だったことも大きい。SPAなら初回読み込みのあとは必要な時に必要な分だけ処理すればいいので、サーバの負荷が軽減されるのである。クライアントのマシンスペックの向上、ブラウザのJavaScriptエンジンの高速化・最適化により、これまでサーバサイドで負担していた処理をクライアントサイドに負担させることができる下地があったということも付け加えておく。サーバサイドの一点集中による処理ではなく、クライアントサイドも使った負荷分散が可能になっていたのである。
そしてマルチプラットフォームだ。これまでデスクトップアプリケーションとしてインストールして使っていたようなプログラムでも、Ajax技術を駆使すれば同等のものをブラウザ上で実行可能である。そしてそれはスマホだろうとタブレットだろうと、ブラウザさえあれば動作するのだ。インストール不要、プラグイン不要、何も事前準備しなくてもブラウザでアクセスするだけで実行可能、アップデートも自動。特別な知識・操作が一切必要ないというのは、それだけで一般層へのリーチに貢献する。
他にも、モバイル環境を見越しての通信量削減だとか、クリック/タップ時の体感速度の向上だとか、枚挙にいとまがないが、こういったさまざまな要素が絡みあった結果として、サーバサイドからクライアントサイドへ、アプリケーション機能の委譲が行われていったのである。
5-5 SPA
典型的なSPAの実例として、筆者が開発・運営しているplanetter.comの仕組みを見てみよう。
http://planetter.com/bestplanisnoplan
上記のURIにアクセスすると、サンプルの旅行プランが表示されるはずである。
リストアイテム1番目の「日本」をクリックすると、表示が切り替わり、アドレスバーのURIも以下のように書き換わる。
http://planetter.com/bestplanisnoplan/0001
しかしここではページ遷移もAjax通信も行われていない。必要なデータは最初にすべて読み込んでいるからである。
次に「京都市」をクリックすると、またアドレスバーが以下のように書き換わる。
http://planetter.com/bestplanisnoplan/0001/0001
今度はブラウザの「戻る」ボタンで履歴を戻ってみよう。「日本」にフォーカスが戻るはずである。
この状態でブラウザの「更新」ボタンでリロードしてみる。当然ながらデータの再受信・再レンダリングが行われるが、画面はリロード前と同じはずである。
さらに「進む」ボタンや「戻る」ボタンで履歴を移動しても、そのときの状態に戻ることができる。
これは、クライアントサイドもサーバサイドも、同じURIのときは必ず同じ画面になるようにプログラムが組まれているからである。こういったコンテキストを意識しない、状態を持たないサービスのことを、ステートレスであると表現する。これもRESTの重要な要素のひとつだ。
具体的には、クライアントサイドはHTML5のhisotry APIを用いて動的にURIを書き換え、サーバサイドもそのURIに対応したリソースを返す、というところを考慮して開発する。
また、従来型のウェブサービスではリンクをクリックした時点でサーバに問い合わせ、その受信が完了するまで待ち時間が発生していたが、ここではリストアイテムをクリックした直後に画面が切り替わっているので、体感速度が大幅に向上している。通信が必要最低限になるようにプログラムが組まれているからである。
planetter.comでサーバとの通信が発生するのは、以下の場合だけである。
- ログイン/ログアウトしたとき。これは画面遷移をともなう。
- プランデータを切り替えたときはJSONデータをAjax通信でGETする。すでにキャッシュがある場合は通信しない。
- リソースの作成時はPOST、更新時はPUT、削除時はDELETEリクエストをAjax通信でサーバに送る。
- 場所検索のときはplanetter.comではなくGooleのAPIに問い合わせる。
その他の処理はすべてクライアントサイドで完結させている。こういったウェブアプリケーションをSPAと呼ぶのである。
TwitterやFacebookは同じリソース内の処理ならAjaxで済ませるが、まったく違うリソースに移動したときは普通に画面遷移するので、こういったタイプはハイブリッド型だと言えよう。
5-6 抽象化ライブラリ
さて、ここまで概念の解説につとめてきたが、ここからはもう少し実際的な話に移ろう。
'00年代後半になるとAjax技術を用いたインタラクティブなサイトが増えていったが、これにはprototype.jsやjQueryといった抽象化ライブラリの存在が大きく関わっている。
Gmail/GoogleMapsの登場によってAjax技術の有用性は証明されたが、当時はまだブラウザ間の差異が激しく、素のJavaScriptではその差異を埋める条件分岐が必須になり、煩雑なコードになるのは避けられなかった。だからその差異を吸収する抽象化ライブラリが生まれるのは必然だったし、それが流行するのも当然であった。
特にjQueryはウェブのあり方を大きく変えた。登場から10年になる現在でもその存在感は計り知れない。JavaScript抽象化ライブラリの金字塔と呼んで差し支えないだろう。
'00年代前半のAjaxプログラムは以下のようなものであった。
<!DOCTYPE html>
<title>Ajax</title>
<textarea id="result"></textarea>
<script>
function getXHR() {
if (typeof XMLHttpRequest !== 'undefined') {
return new XMLHttpRequest();
}
try {
return new ActiveXObject('Msxml2.XMLHTTP');
} catch (e) {
try {
return new ActiveXObject('Microsoft.XMLHTTP');
} catch (e) {}
}
return null;
}
window.onload = function() {
var xhr = getXHR();
if (!xhr) return;
xhr.open('GET', location.href);
xhr.onreadystatechange = function() {
if (xhr.readyState === 4) {
document.getElementById('result').value = xhr.responseText;
}
};
xhr.send(null);
};
</script>
これは現在開いているページを取得してテキストエリアに表示するだけのシンプルなプログラムだが、コードは非常に煩雑だ。
これがjQueryでは以下のようになる。
<!DOCTYPE html>
<title>Ajax</title>
<textarea id="result"></textarea>
<script src="https://code.jquery.com/jquery-2.2.4.min.js"></script>
<script>
$(function() {
$.get(location.href, function(data) {
$('#result').val(data);
});
});
</script>
これだけでもjQueryの偉大さがわかるかと思う。
5-7 データバインディング
jQueryが登場した当初は誰もがその便利さに虜になったが、しかし一方で、便利な機能を集めただけのライブラリにすぎない、という問題も浮上してきた。軽量なウェブページをAjaxでインタラクティブにするていどならこれ以上ないほどに有用なツールだが、本格的なフレームワークではないので、大規模なSPAに耐えられるだけの強度がないのだ。そしてその主たる原因は、データバインディング能力の欠如にある。
以下の例を見てみよう。
<!DOCTYPE html>
<title>Chat</title>
<style>li { border-bottom: solid silver 1px }</style>
<form id="form">
<input id="name">
<input id="message">
<input type="submit">
</form>
<ul id="log"></ul>
<script src="https://code.jquery.com/jquery-2.2.4.min.js"></script>
<script>
$(function() {
var $name = $('#name');
var $message = $('#message');
var $log = $('#log');
$('#form').on('submit', function() {
$log.prepend('<li>' + $name.val() + ': ' + $message.val() + '</li>');
$message.val('');
return false;
});
});
</script>
これは入力した文字列を画面上に表示していくだけの擬似チャットプログラムである。投稿者が自分だけなのでセキュリティは考慮していない。
このプログラム中のデータはどこにあるだろうか? 投稿データは毎回、jQueryオブジェクトの$logに追加されている。そう、データは<ul id="log">の中、つまりDOM上にあるのだ。そしてDOM上にしかない。だからデータを参照するときは、DOMにアクセスする必要がある。
jQueryが流行し始めた当初はこのようなコードが多かった。モデルがビューの中に食い込んでいた。というかモデルがビューの中に取り込まれていた。簡単なウェブページなら特に問題ないが、大規模なSPAでこれはちょっと厳しい。データを参照したり、書き換えたりする必要があるからだ。
上のコードを少し改良してみよう。
<!DOCTYPE html>
<title>Chat</title>
<style>li { border-bottom: solid silver 1px }</style>
<form id="form">
<input id="name">
<input id="message">
<input type="submit">
</form>
<ul id="log"></ul>
<script src="https://code.jquery.com/jquery-2.2.4.min.js"></script>
<script>
$(function() {
var posts = [];
var $name = $('#name');
var $message = $('#message');
var $log = $('#log');
var render = function() {
var html = '';
for (var i = 0; i < posts.length; ++i) {
var post = posts[i];
html += '<li>' + post.name + ': ' + post.message + '</li>';
}
$log.html(html);
};
$('#form').on('submit', function() {
posts.unshift({
name: $name.val(),
message: $message.val()
});
render();
$message.val('');
return false;
});
});
</script>
今度はDOMではなくJavaScriptのメモリ上にpostsという配列を作り、投稿があればunshift()で追加、その直後にrender()でpostsの中身をすべて描写するようにした。これならデータの参照も変更もDOMではなくpostsに対して行えばいい。
これでモデルをビューから切り離せたが、描写のタイミングはやはりまだプログラマが制御しなければならない。postsの中身が変更されたら自動的に<ul id="log">の中身も変更されるようにできないだろうか。そうすればプログラマは描写制御の煩わしさから解放される。それには<ul id="log">という要素にpostsという配列を紐付ければいいのだ。
しかしどのようにしてデータをDOMに紐付けするか。この問題への解答として、さまざまなフレームワークが生まれた。
たとえばAngularJSだと以下のようになる。
<!DOCTYPE html>
<html ng-app="chat" ng-controller="ChatController as chat">
<title>Chat</title>
<style>li { border-bottom: solid silver 1px }</style>
<form ng-submit="chat.submit(form)">
<input ng-model="form.name">
<input ng-model="form.message">
<input type="submit">
</form>
<ul>
<li ng-repeat="post in chat.posts">
{{post.name}}: {{post.message}}
</li>
</ul>
<script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.5.6/angular.min.js"></script>
<script>
angular.module('chat', [])
.controller('ChatController', function() {
this.posts = [];
this.submit = function(form) {
this.posts.unshift({
name: form.name,
message: form.message
});
form.message = '';
};
});
</script>
</html>
独特の記法が多いのでAngularJSをさわったことがない人は面食らうかもしれないが、注目すべきはHTML中の<li ng-repeat="...">とJavaScript中のthis.submitだけである。後者では投稿データをthis.postsに追加しているだけで、render()に相当するような処理はない。描写に関しては何も命令していないのに、this.postsの中身を変更すると即座に画面に反映される。なぜか? 前者ですでにデータがDOMに紐付けられているからである。フレームワークの働きにより、モデルを更新するだけでビューも勝手に書き換わるのだ。これでプログラマは描写制御から解放され、モデルの操作に専念できる。これをデータバインディングという。
今回はクライアントサイドだけで完結しているが、これがサーバサイドのプログラムもあるチャットサービスだと仮定すると、他の人の投稿データをAjax通信でサーバから取得して、同じようにthis.postsに追加するだけで、それも即座に画面に反映されるのである。どうだろうか? なんとなくSPAが作れそうな気がしてこないだろうか? 少なくとも筆者は画面描写について考えなくていいというだけで非常に気が楽になる。これまで占有されていた脳のリソースが解き放たれる感じがする。そしてそのリソースをより本質的な問題に割り当てられることに気付くのだ。この「プログラマのリソース解放」のために、データバインディング機能を備えたフレームワークが必要なのである。
2016年現在、多種多様なJavaScriptフレームワークが存在し、群雄割拠の様相を呈しているが、それらのほとんどはこのデータバインディングを主眼にしていると言っていいだろう。AngularJSは$digestループという力技でねじ伏せ、ReactはVirtualDOMという一見迂遠だが高速かつスマートな方法で解決した。このようにデータバインディングに対するアプローチの方法がそれぞれ違うのだということを意識しておけば、些事に惑わされることなく現状を俯瞰できるはずである。
ここまでが過去の経緯。ここからは現在進行形。そして少し先の未来の話。いま現在、クライアントサイド開発の潮流がどのような方向に向かっているのかを見ていこう。
5-8 コンポーネント指向
以下は前節のプログラムをRiot.jsで書き直したものである。
<!DOCTYPE html>
<title>Chat</title>
<my-chat></my-chat>
<script type="riot/tag">
<my-chat>
<form onsubmit={ submit }>
<input name="name">
<input name="message">
<input type="submit">
</form>
<ul>
<li each={ posts }>
{ name }: { message }
</li>
</ul>
<style scoped>
li { border-bottom: solid silver 1px }
</style>
this.posts = []
submit(e) {
this.posts.unshift({
name: this.name.value,
message: this.message.value
})
this.message.value = ''
}
</my-chat>
</script>
<script src="https://cdn.jsdelivr.net/riot/2.4/riot+compiler.min.js"></script>
<script>riot.mount('my-chat');</script>
また見慣れない書き方で面食らうかもしれないが、注目すべきは<my-chat>タグのみである。このタグを書くだけでブラウザ上にチャット機能が現出するのだ。
どうしてこんな標準仕様にないタグが使えるのだろうか? それは<script type="riot/tag">の中でカスタムタグとして定義されているからである。これによって<my-chat>というユーザ定義のタグが使用可能になっているのだ。
その内容はどうなっているだろうか。上から順番に見ていくと、HTML、CSS、JavaScriptがいっしょくたになっているのがわかる。<my-chat>というタグがどのようなUIか、どのような動作をするのか、といったことをいっぺんに記述しているのだ。これまではHTMLはHTMLの層で、CSSはCSSの層で、JavaScriptはJavaScriptの層で記述する必要があったが、その3層を統合し、処理とUIをひとまとめにして、それ単体で意味をなすコンポーネントにしているのである。
コンポーネント指向の概念を解説するのに最適だったのでここではRiot.jsを使用したが、何もこれが特別なフレームワークというわけではない。コンポーネント指向のフレームワークと言えばまずReactが挙げられるし、Angular2も完全にそうだ。そして実はAngular1もv1.5からコンポーネント指向に対応している。ウェブ全体の大きな流れとして、コンポーネント化へと向かう潮流があるのだ。
また面倒な潮流が生まれたと思うだろうか? しかし新しい潮流が生まれるのにはいつも必然性がある。なんらかの問題が発生していて、時代の要請として、それを解決するために新しい技術が生まれるのだ。
では、コンポーネント指向は何を解決するのだろうか? 少し長くなるが、ここはもう一度ウェブ黎明期から遡って解説したほうがより納得感が出るだろう。

これはクライアントサイドの概念図である。縦方向がレイヤ、横方向が規模をあらわしている。サイト全体ではなく、あくまで1ページのレイヤ・規模である。便宜上、これをクライアントサイド・バランスシート、略してCSBSと呼ぶことにする。このCSBSを使ってクライアントサイドがどのように変化していったかを見ていこう。
'90年代はHTMLですべてをまかなっていた。文字の色や大きさを変えるのにも<font>タグを使っていた。しかしやはりHTMLは文書構造を表現するためのマークアップ言語だ、見栄えは分離するべきだ、という潮流が生まれ、CSSが一般化する。この分離作業は'00年代前半に行われた。ウェブ全体の移行にはかなりの時間と労力を要したが、大半の開発者たちには好意的に受け止められた。ウェブに求められる機能・規模が少しずつ増加していたからである。

ここでレイヤがひとつ増えたが、すぐにもうひとつのレイヤが追加されることになる。そう、JavaScriptである。'00年代半ば、Gmail/GoogleMapsが登場し、それまで誰の役にも立たないガラクタにすぎなかったJavaScriptの価値が見直され、Ajax技術を多用したインタラクティブなサイトが増えていく。そしてそれにともなって、ウェブに求められる機能・規模も増大していく。

ところで、ここまでレイヤと規模が比例し、CSBSが綺麗な正方形を保っているのには理由がある。市場からの要請で規模が増大する方向へ力が加われば、レイヤもそれにともなって厚くしなければ対応できない。そしてその結果レイヤが厚くなればさらに規模の拡大が可能になって市場からの要請が……というループ構造なのである。
しかしここからこのバランスが崩れ始める。その主たる原因はSPAという新しいウェブアプリケーション形態の出現にあると見てまず間違いないだろう。従来通りのウェブアプリケーションでは大規模化するとしてもサーバサイドが主体だったが、SPAではクライアントサイドが主体となる。さらに、これまでサーバ内に分散していたリソースが集約されるようになり、1ページの規模が大きくなる。時を同じくしてクライアント端末のスペックが急激に向上し、より大規模なアプリケーションを実行可能になっていく。そして実行可能であればさらに市場からの要請が強まっていく。こうして、クライアントサイドに求められる規模の増大速度が、これまでの比ではなくなってしまったのだ。
HTML5、CSS3、ES5といった標準仕様のバージョンアップによって多少なりともレイヤは厚くなったが、規模の増大速度にはとてもではないが追いつかない。標準化を待っているだけではダメだ。

こうして、jQueryを先駆けとして、CoffeeScriptやTypeScriptといったaltJS、LESSやSass(SCSS)といったCSSプリプロセッサが生まれた。しかしもうレイヤを厚くすることも限界だ。いや、これ以上厚くしても無意味なのだ。もっと根本的な解決法が必要だ。
大規模化が問題なら、当然の流れとして、それを小さく分割するという解決法が試みられる。SmartyをはじめとするテンプレートエンジンはHTMLを分割し、クライアントサイドMV*フレームワークはJavaScriptを機能単位で分割し、Browserify/Webpackによるバンドルはグローバル変数を駆逐し、BEMやSMACSSといった設計手法の確立は命名規則によるCSS分割を可能にした。
しかしこれは同じレイヤ内での分割である。HTMLのどことJavaScriptのどこが関連している、といったことは開発者がすべて把握していなければならない。CSBSであらわすと以下のようになる。
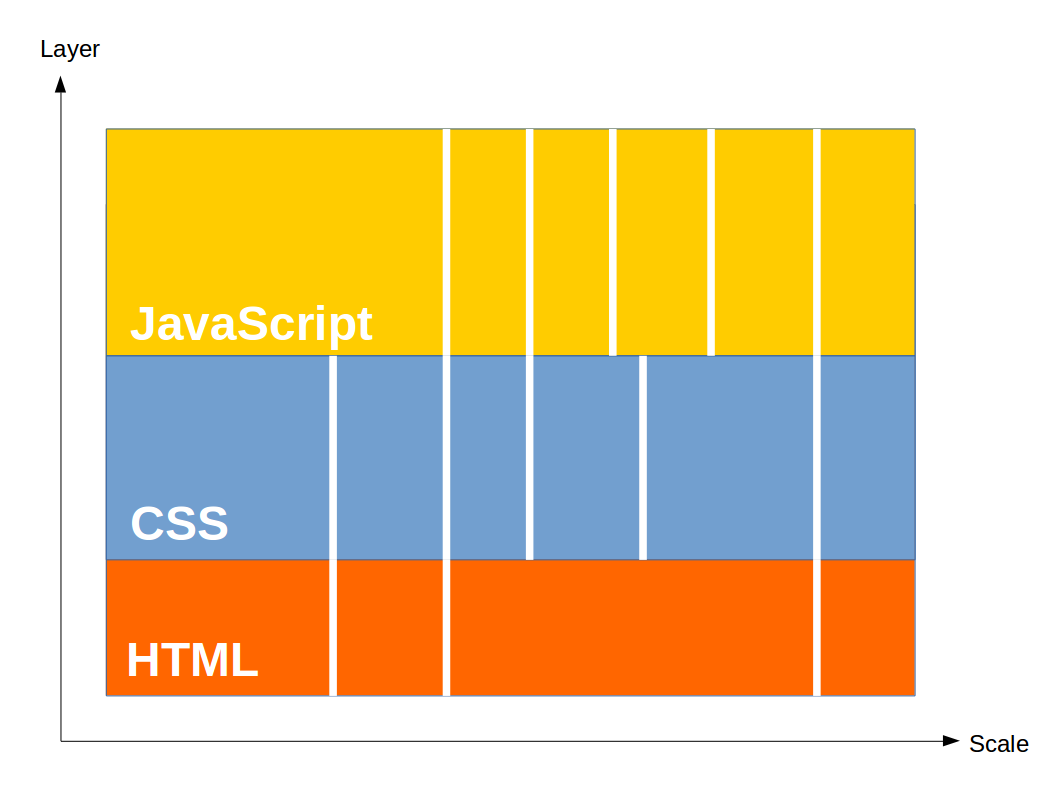
この手法では結局のところ全体を把握する必要があり、大規模なSPAの開発には到底耐えられない。ひとりの開発者が把握できる規模には限界があるからだ。全体を把握する必要さえない分割方法が必要なのだ。しかしこれ以上何をどうすればいいというのだ。もうこれ以上の大規模化は望めないのではないか。
現実の社会でも似たような問題は発生する。たとえば企業組織の大規模化だ。企業が事業拡大を続け、組織が肥大化したとき、あるていどまではレイヤを厚くすることで対応できるが、一定以上の規模を超えると、中間管理職をいくら増やしても効果がなくなる。そんなとき、企業はどうするか? そう、独立性の高い事業部を子会社化し、本体から切り離して、経営のスリム化をはかるのだ。社内カンパニー制とはそれを見越した体制である。それで横のつながりが薄くなり、部分的には非効率になっても、全体にとってはそれが最適なのである。この理屈をクライアントサイド開発の世界に適用すると、CSBSは以下のようになる。
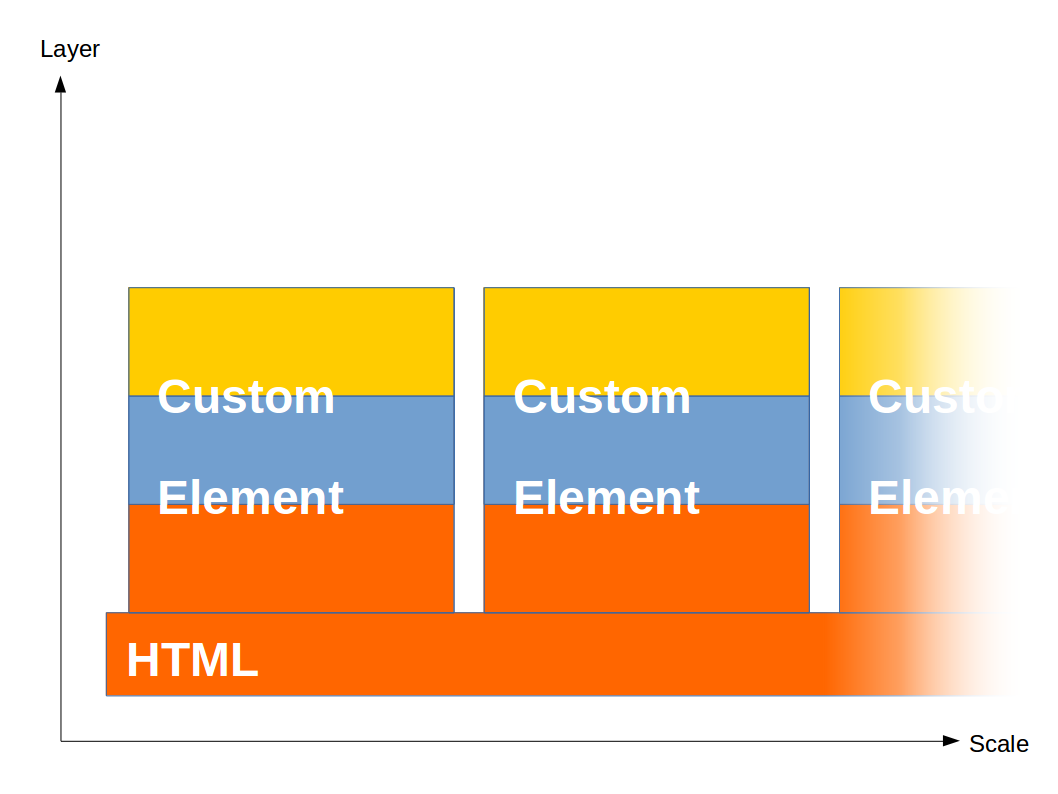
※各部品が正方形に戻っていることに注目
HTML、CSS、JavaScriptという3層を垂直方向にばっさりと分割し、横のつながりを断ち、関連性のあるものをまとめて独立性の高い部品にする。そしてその部品を組み合わせて全体を構築する。これがコンポーネント指向の所以である。
サーバサイドはマイクロサービスというアーキテクチャで大規模化の波に対抗しているが、これも同じ理屈だと言える。「ひとつのことをうまくやれ」というUnixの哲学はやはり偉大だ。疎結合、ステートレスといった考え方は、これからますます重要になっていくだろう。
さて、だいぶ長くなってしまったが、本節初めのRiot.jsで書かれたコードを覚えているだろうか。これまでの開発手法に慣れた人にとっては奇異に見えたかもしれないが、ここまで読み進めてきた人ならわかるはずである。これ以外に大規模化に対抗する手段がないのだ。他にどうしようもないのだ。小規模サイトの構築なら従来通りの方法論で片付くかもしれないが、その方法論ではもう追い付かなくなっている現場も確実に存在しているのだ。そういう現場はどうすればいいというのだ。従来通りの発想ではもう限界なのだ。発想の転換、パラダイムシフトが必要なのだ。
そしてこれは前節で見たデータバインディングから地続きになっているのである。データをDOMに紐付けることはできるようになったが、HTMLもJavaScriptも肥大化した状態では、位置が離れすぎていて、どのデータがどのDOMに紐付いているのか、把握が困難だ。コンポーネント指向であれば、同じコンポーネント内にモデルとビューが共存するので、位置がぐんと近くなり、把握が容易になる。よりよいデータバインディングの方法論を模索した結果として、最終的にコンポーネント指向にたどりついたのだと言ってもいいだろう。
そしてこの潮流はWeb Componentsという形で標準化の策定が進んでいる。React、Angular2といったコンポーネント指向のフレームワークは、ここに至る道を踏みならしているのだと言えよう。しかしそうして舗装された道が一般層に受け入れられ、メインストリームとなるかどうか、それは未知数である。標準化≠デファクトスタンダードなのだから。
個人的にはRiot.jsの「予言」が非常に的を射ているように思われる。
最終的には、業界標準としてのWeb Componentsに辿り着くべきです。それは長い年月を必要としますが、いずれは標準コンポーネントがウェブを満たすことになります。
これらのコンポーネントは複雑であるため、直接に使われない可能性が大きいです。今日多くの人が、直接DOMを操作せずjQueryを使うように、Web Componentsの上にもさらなる層が作られるでしょう。
そしてこのWeb Componentsも、 Extensible Webというさらに大きな潮流の一支流にすぎない。これは、時間のかかる標準化策定・ベンダ実装を待つのではなく自分たちで未来を切り拓いていこう、低レベルなAPIを組み合わせて独自にウェブを拡張していこう、という潮流である。その中にはService Workerのような、ウェブのあり方を根本から変えてしまいそうなポテンシャルを秘めた技術もある。Web Componentsが標準化されたらそれで安泰、もうこれ以上の変化はない、などということは決してないのである。
さて、ここまでクライアントサイドの変遷を振り返ってきたが、結局のところ、いま現在、何を選択すればいいのだろうか?
クライアントサイドの技術がどのように進化してきたかを思い出そう。それは、大規模化への対抗、SPA化への対応であった。その中で新しい技術、新しい考え方が生まれ、その時点で最も適した形(CSBSが正方形)へと変化を遂げてきた。このことを踏まえれば、「新しいものほどいい」というのが誤りであることは明白だ。非SPAの軽量ページにはコンポーネント指向は足枷にしかならないだろうし、逆もまた然りで、jQueryでは大規模なSPAには耐えられない。重要なのはバランスである。その案件が小規模〜大規模、非SPA〜SPAというグラデーションのどこに位置するのかを見極め、それに合わせたアーキテクチャ設計・技術選定をすることが肝要である。
何にせよ、すべての問題を解決する銀の弾丸はない。最も優れた技術など存在せず、最も適した技術が存在するのみである。
終章
おわりに
かつての少年は思う。
ああ、なんて遠いところまで来てしまったんだろう。ひとりきりでスポラディックE層を待っていた、あの狭く埃っぽい部室から、本当に遠いところまで来てしまった。
あれから彼の人生にもいろんなことが起こった。プログラマになったり、ホームレスになったり、海外を放浪したりした(このあたりの経緯は数年前に増田に書いた)。そのあとまたいろいろあって福島で除染作業員をしていたが、思ったより東北の夏が暑かったのでしばらく北海道をブラブラして、いまは札幌に住んでいる。もともと関西の人間なので雪なんてほとんど見たこともなかったが、ここで2回ほど冬を越して、ドカ雪にも最高気温氷点下にもすっかり慣れた。いまは無職ひきこもりなのでこの先どうなるかはわからないが、まあどうにかこうにかやっていくだろう。

札幌の冬の日常的光景 - 2015年1月 近所の交差点にて撮影
その間に、ウェブの世界もすっかり様変わりしてしまった。
Perl、Ruby、Java、PHP、Node.js、LAMP、MEAN、仮想化、クラウド、Infrastructure as Code、IaaS、PaaS、SaaS、リレーショナルデータベース、インメモリデータベース、NoSQL、SVN、Git、TDD、BDD、継続的インテグレーション、ビルドツール、パッケージ管理、スマホ、タブレット、レスポンシブデザイン、フラットデザイン、HTML5、CSS3、ES2015、MV*フレームワーク、オブジェクト指向、コンポーネント指向、マイクロサービス、SPA、REST。
初めてHTTPサーバと会話した、あの瞬間、あの色彩は、遥か後方に過ぎ去り、振り返ってみたところで、そこはもう二度と戻ることのできない場所なのだと思い知らされるだけだ。
ウェブの変化はめまぐるしく、技術はどんどん進歩を続け、世間は騒がしく、周囲の環境もどんどん変化して、目の前の風景がとてつもないスピードで過ぎ去っていく。自分ひとりだけが世界から取り残されていくように思える。
だからせめて、ここに道標を置いていこう。
この道標――感覚の共有ライブラリ――を、すべてのエンジニアにささぐ。
Good-bye, Silver Bullet!
それでも人は、銀の弾丸を求めてしまう。
世界のどこかに特別なものがあるのだと、自分はまだそれを見つけていないだけなのだと、西へ東へ走りまわって、ただただ歳を重ねる。
気付けばいつのまにか人生の黄昏時で、自分はいままで何をやってきたんだろうとうなだれる。
そんな繰り返しは、うんざりじゃないか。
さあ、もう夢を見るのはやめにしよう。未来に希望を抱くのもやめよう。
そんなものはどこにも存在しない。
サクセスストーリーも、ハッピーエンドも、本当はこの世のどこにも存在しないのだ。
僕らの手元にあるものは、いつだって、くだらなくて、ろくでもない、安物のおもちゃばかりだ。
それを使って、いまこの瞬間、ただただコードを書いていこう。
そのガラクタのようなプログラムが、この惑星を動かしていくのだから。