※このお話はたぶんフィクションです。実在の人物や団体とはあんまり関係ありません。
序
planetter.comをバージョンアップすることにした。数年前にリリースしてからずっと放置していたけど、そろそろ手を付けないとやばいと思った。
しかしウェブの世界はドッグイヤーだ。3年も経てば何もかもが変わっている。しばらく開発から遠ざかっていた僕には、最近の技術トレンドなんてさっぱりわからない。
まずは自分自身をアップデートするところから始めよう。
Atom
最初はIDEだ。以前はEclipseを使っていたけど、いまはもうウェブ系言語の進化速度に追いつけていないようだった。ウェブ開発用のIDEならいまはWebStormが人気のようだ。有料だけど、最新の技術に対応しているし、使い勝手もいい。
でも最終的にはAtomを選んだ。IDE(統合開発環境)ではなくエディタなので、これ自体は単機能だけど、不足分はパッケージを追加することで補えるし、そのエコシステムが盛況で、新しい技術が出てきても即座に対応している。これを使っておけば流行に置いていかれる心配はないだろう。当分は。
導入した当初はいろんなパッケージを入れまくってたけど、当然ながら動作が重くなるので、必要最低限のものだけにしたら、最終的に以下のようになった。
$ apm list --installed --bare
angularjs@0.3.4
atom-beautify@0.29.7
autocomplete-modules@1.4.1
autocomplete-paths@1.0.2
autocomplete-sass@0.1.0
color-picker@2.1.1
docblockr@0.7.3
file-icons@1.7.10
git-time-machine@1.5.2
highlight-selected@0.11.2
javascript-snippets@1.2.1
linter@1.11.4
linter-eslint@7.2.2
linter-htmlhint@1.1.4
linter-sass-lint@1.4.3
local-history@3.2.3
pigments@0.26.2
todo-show@1.6.0
Git
次はバージョン管理だ。IDEの選定中、久しぶりにEclipseを起動させてみていちばん驚いたのは、標準で付属するバージョン管理プラグインがSVNからGitに変わっていたことだ。数年前はSVNからGitへの移行はshouldくらいの感じだったけど、もはやmustなのだといわれている気がした。世代交代は完全に終わった感ある。
仕方ないのでおとなしくGitを習得することにした。あるていど事前知識はあったのでさほど苦労はしなかった。しかしやはりブランチの概念が最初から組み込まれているのはすばらしい。SVNでこれをやろうとすると地獄を見るし。
今回は個人開発なのでmasterにpushするだけにしようかと思ったけど、せっかくなので少しGitらしいフローも取り入れることにした。
普段はmasterで開発。実験的かつ大きな変更をするときはそれ専用のトピックブランチを切ってそこにpush。「よし、いける」となったら自分でプルリクエストを作成、自分でコードレビュー、masterにマージ、トピックブランチは閉じて、またmasterに戻って開発を続ける。「やっぱこれねーわwww」となったらトピックブランチは破棄して、分岐元のmasterに戻る。これができるだけでもGitに移行してよかったと思えるわ。
リモートリポジトリは無料でプライベートリポジトリを作れるBitbucketを使うことにした。Githubに比べると地味だけど、個人開発用途なら必要十分な機能が揃っている。
Vagrant
次はローカル開発環境の構築だ。どうも最近はVagrantを使うのが主流のようである。
LinuxのISOイメージをダウンロードして、VirtualBox上にインストールして、ネットワークデバイスを有効にして、sshdの設定して、共有ディレクトリの設定して……みたいなめんどくさい作業がほぼ自動でできるようだ。
vagrant box addでOSのイメージファイルを追加して、vagrant initでVagrantファイルを作って、vagrant upするだけでOSが起動する。そしてvagrant sshでSSH接続までできる。なにそれすごい。
Vagrantファイルをリポジトリで管理できるし、チーム開発のときはあらかじめ環境構築しておいたboxファイルをメンバーに配布して、vagrant upしてね、だけで済むのか。PuppetやChefなんかのプロビジョニングツールを組み合わせればさらにいろいろできるし。
Infrastructure as Code
そういえばプロビジョニングツールの流行はどうなってるんだろ、と思って調べてみる。やはりまだChefが主流のようだけど、その簡易版といえるItamaeや、YAML形式でシンプルに書けるAnsibleなんかも人気のようだ。Chefは数年前に挑戦して、あまりに高機能すぎてやめたけど、やはりみんな同じことを感じていたのか。
さらにServerspecというテストツールも出てきているようだ。そうか、こういうのがあれば、まずテストを書いて、エラーを出して、そのテストに通るように本番コードを書く(プロビジョニングする)、というTDDの手法がインフラの世界にも持ち込めるのか。すごい、なんか知らない間にめちゃくちゃ進化してる。
Docker
そしてこのあたりを調べているときに何度も目にしたのがDockerという単語だ。これは仮想化技術ではなく、コンテナ化技術のようである。エミュレートしないので高速に動作するし、Vagrantファイルと同じようにDockerfileをリポジトリで管理できるし、さらに作成したイメージはGitよろしくdockerhubにpush/pullできる。なにそれこわい。インフラ界隈、進化しすぎだろ。
しかしざっとチュートリアルをやった限りでは簡単に導入できそうに思えたけど、本番環境での本格的な運用まで見据えて考えると、かなり敷居は高く感じた。スキルの高いインフラエンジニアが勘所を見定めて、ここぞというところでのみ使うべき技術のような印象だ。僕レベルのエンジニアが手を出してもおそらく火傷するだけだと思って、今回の導入は見送った。身の程を知ることは重要だ。
現在進行形で変化の激しい技術だし、数年後にもう一度手を出してみようかな。
CentOS7
現行のplantter.comはCentOS6で運用しているけど、CentOS7が出ているようだったので試してみた。Linux系OSなんてそうそう大きく変わらんだろ、とか油断してたら、よく使うコマンドが変わりまくってて死んだ。
特にsystemctlがやばい。以前のservice httpd startがsystemctl start httpdに、chkconfig httpd onがsystemctl enable httpdというように変わっているけど、引数の順番が逆になっているので、何度も引数が不正だと怒られた。そしてsystemctlに慣れてから6系を使うと、今度はこっちの引数を逆にしてしまったりしてまた死ぬ。
他にも、nmtuiを使ってウィザード方式でネットワーク設定ができたり、ファイアーフォールも設定ファイル直書きではなくfirewall-cmdというコマンドで設定するようになっていたり、全体的に抽象化が進んでいる印象だ。
Apache2.4
Apacheも2.2から2.4へのアップデートがかなりBreakingなものだったらしく、2.2の設定ファイルはそのままではまず引き継げないと考えていいようだ。とはいえ、今回の開発ではnginxを採用したのであんまり関係なかった。
MySQL/MariaDB
CentOSのRDBMSは7からMariaDBになっている。少し使ってみたけど、systemctlで起動するときのサービス名以外、MySQLとの違いがまったくわからなかった。phpMyAdminとかも特に設定変更せず使えるし。
GoogleやWikipediaがMySQLからMariaDBに移行してたりするし、今後はこっちがデファクトスタンダードになっていくのかな?
MongoDB
2010年前後からNoSQLという単語をよく聞くようになったけど、MongoDBもその系譜だ。スキーマレスのドキュメント指向データベースで、JSON形式のデータをそのまま保存できる。専用クライアントはJavaScriptの構文をそのまま使えたり、JavaScriptとの親和性が高い。なのでNode.jsと組み合わせて使われることが多いようだ。
RDBとはまったく別軸のものなのでMySQLの代替にはならないけど、トランザクションが必要ないような場面……1つのドキュメントがそれ単体で意味をなすデータになっていて、アトミックな操作が可能な場面では有効に使えそうだ。
そういったKVS的な使い方が基本のようだけど、スキーマレスというわりには一般的なSQLの集計関数もばっちり用意されているので、かなり高度な使い方もできるようだ。KVSとRDBMSの中間的な立ち位置なのかなと思う。ちょっとおもしろい存在だ。
Redis
そしてKVSの急先鋒がRedisである。インメモリなKVSならmemcachedという感じだったけど、いまはこちらが人気のようだ。
インメモリデータベースはサーバを落としたらデータが揮発する、それは高速動作との等価交換だから仕方ない……と思ってたけど、Redisは最初から永続化の方法が用意されていて、通常はインメモリで動作しつつ、一定のタイミングでストレージデバイスに書き込むようになっている。だからサーバを再起動してもデータが失われない。
実際に少し使ってみたけど、特段に難しいところもなく、軽快に動作して好印象だった。既存案件のmemcachedをわざわざ置き換えるほどじゃないけど、新規案件ならRedisを選ばない理由はない、くらいの感じかな?
PHP7
インフラ関係はこのくらいにして、そろそろ言語にいこう。
PHPは去年の暮れに7が出たばかりのようで、いまはちょっと微妙な時期だなと思った。5.6のサポート期限が延長されていて、7.0より長いのだ。
As it is the final PHP 5 release, support for PHP 5.6 has been extended: active support will run for an additional four months, and the security fix period has been doubled from one to two years. Other releases are unaffected.
このあたりのこともあるし、7以上が開発の現場で普通に使われるようになるのは、まだまだ先のことになりそうかな?
Githubでざっと最近のPHPコードをながめてみたら、名前空間や[]やクロージャが普通に使われてるものが多くて、時代の流れを感じた。
PHPフレームワーク
PHPのMVCフレームワークはまだまだCakePHPが人気のようだ。v2からv3になって、かなり様変わりしている。既存案件のアップグレードは難しそう。
しかしどうもこのCakePHP人気、日本だけのローカル現象のようで、海外ではLaravelがメインストリームになりつつあるようだ。あまり把握できてないけど、めちゃくちゃ高機能っぽい。ただそのせいか動きが若干もっさりしている感じがした。このあたりは機能とのトレードオフなので仕方ないか。
他にもいろいろフレームワークは出てきているみたいだけど、個人的にはPhalconが好きな感じだった。普通のマッチョなMVCフレームワークとして使うこともできるし、Sinatra的なスリムな使い方もできる。何よりC言語で書かれているので爆速だ。しかし当然ながらコンパイルが必要になるので、導入にひと手間かかるというのが難点か。最近のComposerを使う流れからは外れることになるし。
Composer
ここ数年のPHP界隈でいちばん大きな変化といえば、このComposerの登場だと思う。やっとPHPもRubyのgemのようなモジュール管理ができるようになったのだ。
プロジェクトディレクトリ直下にcomposer.jsonというファイルを置き、そこに依存関係を記述して、composer installすれば、vendorディレクトリ以下に各モジュールがインストールされるので、スクリプト中でrequire __DIR__ . '/vendor/autoload.php';とかしてやれば、クラスを呼び出すタイミングでオートローディングしてくれる。そしてvendor以下はリポジトリへのコミットが不要で、composer.jsonさえあればいつでもどこでも元の状態を再現できるし、モジュールごとのバージョン管理も可能だ。公式サイトからzipファイルをダウンロードして、解凍して、リポジトリへコミット、なんてもうしなくていいのだ。
HTML5
いつのまにか<!DOCTYPE以降に長々と書く昔ながらのドキュメント宣言をほとんど見かけなくなった。ウェブ全体がバージョンアップされた感ある。
history.pushState()をフォールバックとか考えず躊躇なく使えるようになったのが地味に嬉しい。
CSS3
CSS3もいつのまにか各ブラウザが対応しまくっていて少しびびる。もう角丸ボタンを作るのにPIE.htcを使ったり、ベンダプレフィックスつけまくったりしなくていいのだ。transformとかtransition、rgba()あたりが普通に使えるようになったことも嬉しい。
どうも最近は各ブラウザの対応状況はCan I useというサイトで確認するのが一般的らしいので、ここで近況をざっと見てまわったけど、やっぱり今年初めにMicrosoftが古いIEのサポートを終了したのが大きいよなと思う。これを切り捨てられるだけで使える技術が一気に増えるし。
OOCSS/BEM/SMACSS
ここ数年のCSS界隈での大きな変化は2つあるようだ。1つが設計手法の確立。もう1つがプリプロセッサの普及。まずは前者から見ていこう。
OOCSSはオブジェクト指向CSSの略で、ページを構成する要素を「レゴの集まりのように」バラバラのオブジェクトとして捉える考え方。BEMはページを構成する要素を、Block、Element、Modifierとして捉える考え方と、それらを明確に表すための命名規則。SMACSSはBase、Layout、Module、State、Themeとして捉える考え方と、命名規則。
僕はSMACSSが好きな感じだったので、今回の開発ではこの考え方をベースにした。いままでオレオレで似たようなことはやってきたけど、こうして系統立ったものが一般化されると安心して開発に取り組めるのでありがたい。
余談だけど、最近のCSS開発ではIDを使うのが忌避されている、という事実に少し驚いた。ページ内のユニークな要素をあらわすっていう意味合いがあるんだから、あったほうがよくない? と思ったけど、実際にクラスのみで開発をしてみると、たしかにこちらのほうがレゴっぽくていい感じだった。IDが入ると、そのレゴの中にいきなり超合金ロボが出てくる感じになる。詳細度が上がらない(複雑さが上がらない)というのは意外と大きい。
LESS/Sass(SCSS)
そしてプリプロセッサ。最近のCSS開発では、CSSファイルを直接書くのではなく、LESSやSass(SCSS)等のメタ言語で書いてから、コンパイルをかけて、その出力結果のCSSファイルを利用する、という開発手法が主流になってきているようだ。
SassはRuby/Python使いが好きそうな簡略化された言語。LESSはCSSの拡張言語で、CSSの構文がそのまま使えて、さらに変数とかの便利機能がある感じ。SCSSはそのLESSの機能増強版といった感じ。このあたりに関しては「これがデファクトスタンダード!」みたいなのはないようだ。なら自分の好きなものを使おう。僕はSCSSが好きな感じだったのでSCSSにした。
ただ、数年後にはPostCSSがデファクトになっているかもしれない。そういうポテンシャルを感じる。でもこれも現在進行形で変化の激しい技術っぽいので、いまはやめておいた。
サーバーサイドJavaScript(Node.js)
そしてこのCSSのコンパイルも含め、プロジェクトのビルドに必須となってくるのがNode.jsである。
Node.jsに関しては出たばかりのころにさわったきりだったので、本格的なアプリケーションを簡単に作れるようになっているこの現状にまずびびった。Socket.IOを使ってリアルタイム双方向通信サーバを作ることもできれば、Expressを使って本格的なHTTPサーバを作ることもできるようだ。
もともとC10K問題に対する解のひとつとして、シングルスレッド・イベントループのNode.jsが注目されていったのだと思うけど、いまはそういった「大量のアクセスをさばく」目的だけでなく、多種多様な目的で使われているようである。
npm
そして昨今のNode.js人気は、npm(と、そこで展開されるエコシステム)に裏打ちされているのは間違いない。数年間ウェブ開発の世界から離れていた僕がnpmの現状、その盛況ぶりを見たときの衝撃たるや、筆舌に尽くしがたいものがあった。
たいていの機能はnpmで探せば簡単に見つけられるし、それをnpm installして、スクリプト中からrequire()するだけでいい。そしてそのほとんどが単機能のものばかりなので、APIリファレンスは簡素なものが多く(たいていはREADME.mdだけで済ませている)、習得に時間がかからない。サンプルコードをコピペして、手元のマシンで動かして、ちょっと改変して、「なるへそ」と思ったら自分のプロジェクトに組み込むだけだ。本当に笑ってしまうくらい簡単に、複雑で高度な機能を自分のプロジェクトに組み込むことができるのだ。これは人気が出るわけだわ。
でもその弊害もある。「このモジュールをちょっと改変したやつが欲しいんだけど、機能を組み込んでもらえるか微妙だし……よし、フォークしたろ」的にリリースされた感じの、似たようなモジュールが大量にあったり、フォークされたものでなくても、やっぱり似たような問題を解決するために別方向のアプローチをしたモジュールがたくさんあったりして、どれを使っていいのか、どれがデファクトなのかわからなくて混乱するのである。
そういうときは、Githubのスター数(npm自体にもスターはあるけどあまり利用されてない)、リリース頻度の順に見るようにしている。それでもわからないときは、Stackoverflowの投稿数や、日本国内に限定していいならQiitaの投稿数を見る。Googleトレンドは参考程度に。
Gulp/Webpack
そしてそのモジュール群の中でも特に人気があるのが、プロジェクトのビルドツールだ。前述したCSSのコンパイルを行ったり、画像の最適化をしたり、altJSで書いたJavaScriptをトランスパイルしたり、といったことを自動化するツールである。
以前はGruntが人気があったようだけど、その地位は現在はGulpに奪われ、そして次はWebpackだ、みたいな感じになっているらしい。ああ諸行無常。
みんなこのビルドツールの流行り廃りに疲れてきていて、もうpackage.jsonのscriptに直接コマンド書こうぜ、みたいなオルタナティブな流れもあるようだ。これについては後述する。
僕も最初は「うはwwwGulp超便利www」とか思って、gulpfile.jsにあらゆるタスクを書きまくってたけど、gulp-xxxは結局、元となるモジュールのラッパーでしかなく、そしてそのラッパーが元モジュールのアップデートに追いつけていなかったり、という状況もあって、最終的にgulpfile.jsはCSSのビルドタスクのみになった。
'use strict';
var gulp = require('gulp');
var plumber = require('gulp-plumber');
var notify = require('gulp-notify');
var sass = require('gulp-sass');
var autoprefixer = require('gulp-autoprefixer');
var cleanCSS = require('gulp-clean-css');
var sourcemaps = require('gulp-sourcemaps');
gulp.task('default', ['build:css:watch']);
gulp.task('build:css:watch', ['build:css:dev'], function() {
gulp.watch('./app/assets/stylesheets/**/*.scss', ['build:css:dev']);
});
gulp.task('build:css:dev', function() {
gulp.src('./app/assets/stylesheets/app.scss')
.pipe(plumber({ errorHandler: notify.onError('<%= error.message %>') }))
.pipe(sourcemaps.init())
.pipe(sass())
.pipe(autoprefixer({ browsers: ['last 2 versions'] }))
.pipe(sourcemaps.write({ sourceRoot: './app/assets/stylesheets/' }))
.pipe(gulp.dest('./public/'));
});
gulp.task('build:css', function() {
gulp.src('./app/assets/stylesheets/app.scss')
.pipe(plumber({ errorHandler: notify.onError('<%= error.message %>') }))
.pipe(sass())
.pipe(autoprefixer({ browsers: ['last 2 versions'] }))
.pipe(cleanCSS())
.pipe(gulp.dest('./public/'));
});
これもPostCSSを使えばコマンド化できるのだけど、時期尚早だと判断したし、そこまでして脱Gulpしなくてもいいと思った。便利なものは便利なように使えばいいのだ。
Browserify/Watchify
クライアントサイドJavaScriptのビルドにはBrowserify/Watchifyを使った。クライアントサイドでrequire()を使えるようにしてくれるニクイやつである。
今回の開発ではサーバにNode.jsを採用したので、サーバサイドもJavaScriptで書いたのだけど、そのときに自作したモジュールやJSONデータも、クライアントサイドでrequire()するだけで使えるわけである。サーバ/クライアントの開発言語を統一するとこんな嬉しい特典があるのかと思った。この感動は実際に体験してみないとわからないかもしれない。
ちなみに、バンドルしてしまったらブラウザ上でのデバッグがやりにくくなるんじゃ……という不安があったのだけど、exorcistをかましてソースマップファイルを作れば、あとはChromeのDeveloper Toolsが勝手に解釈してくれるので、バンドルされていることを意識する必要さえなく、元のファイル名、元の行数でデバッグ可能だった。最近の開発ってマジ近未来SF。
クライアントサイドJavaScriptフレームワーク
クライアントサイドJavaScriptフレームワークに関してはここ数年、戦国時代と言って差し支えない、混沌とした状況だったようだ。そのせいなのかこのあたりを調査していると、「コレが最強」「アレはクソ」「まだそんなことやってるの?」みたいな言説が多くてつらい。
「自分の使っている技術がいちばん優れている」は、エンジニアが陥る誤謬の最たるもので、それはどれほど賢明で分別のある人間でも迷い込んでしまう魔境なんだと思う。他山の石としたいけど、やはり自分も例外ではないことは肝に銘じておきたい。
話がそれた。
クライアントサイドのJavaScriptフレームワークをいま導入するならFlux/VirtualDOMのReact(+Redux)かなあと思ったけど、これも現在進行形で変化の激しい技術のようだったので今回は見送った。今回の開発では現段階であるていど枯れているであろう、AngularJSを採用した。v2ではなくv1。現在ベータ版のv2もちらっと見たけど、「どうしてこれにAngularの名を冠したし」とつっこみたくなるほど完全に別物だった。WebComponentsはウェブ開発のあり方を根本から見直さないといけないので、本当に一般層に受け入れられるかどうかは未知数である。いまはまだ様子見したほうが無難だと判断した。
しかし最近jQueryがレガシー扱いされてて不憫で仕方ない。めちゃくちゃ便利なのに。
package.json
npmは依存関係をプロジェクトディレクトリ直下のpackage.jsonというファイルにJSON形式で記述するのだけど、ここにnpm runで実行可能なコマンドを登録できる。今回の開発ではここに各種タスクを登録した。
ビルドツールを使うのではなく、ここにタスクを登録するメリットはいくつかある。
- ビルドツールは廃れる可能性が高いが、npm自体が廃れる可能性(とpackage.jsonの仕様が変わる可能性)は前者よりは低い
- ほとんどのビルド系ツール、Lint系ツールは、コマンドラインから使用することを想定しており、こちらが正攻法である(各ツールの概要ページで
npm installコマンドのあとに解説されるのは、たいていコマンドラインからの使用方法だ) - 通常、コマンドラインから(短いコマンドで)使うためにはグローバルインストールする必要があるが、
package.jsonのscript内から使う場合には、./node_modules/.bin/にPATHが通っている状態なので、ローカルインストールでいい - 上記により、環境構築時に個別コマンドをグローバルインストールする必要がなく、
npm installだけで開発の準備が完了する -
package.jsonを見れば開発に必要なコマンドすべてがわかる状態になる(README.mdに別途記載とかしなくていい) - ぶっちゃけコマンドラインから実行できるものならなんでもいいので、npmの埒外にあるものでも使える
とか、つらつらと考えて、僕はもうnpm runのみでいくことにした。gulpコマンドすらグローバルインストールしないのだ。ああすっきり。
{
"name": "planetter",
"description": "Travel the planet",
"version": "1.1.0",
"private": true,
"scripts": {
"start": "node ./bin/www",
"start:watch": "nodemon ./bin/www -L -e js,json,dot --watch ./app/server/",
"start:debug": "node-debug ./bin/www",
"start:sync": "browser-sync start -s --directory --no-notify -f='./test/assets/**/*.html' -f='./public/app.css'",
"test": "npm run test:server && npm run test:client",
"test:server": "NODE_ENV=test istanbul cover _mocha -- ./test/server/",
"test:server:watch": "NODE_ENV=test mocha -w ./test/server/",
"test:client": "karma start",
"test:client:watch": "karma start --no-single-run --reporters=mocha",
"test:client:linux": "karma start --browsers PhantomJS,Chrome,Firefox",
"test:client:windows": "karma start --browsers PhantomJS,Chrome,Firefox,IE",
"build": "npm run build:js && npm run build:css",
"build:js": "rm ./public/app.js.map -f && browserify ./app/client/app.js | uglifyjs -m -o ./public/app.js",
"build:js:watch": "watchify ./app/client/app.js -d -v -o 'exorcist ./public/app.js.map > ./public/app.js'",
"build:css": "gulp build:css",
"build:css:watch": "gulp build:css:watch",
"lint": "npm run lint:js && npm run lint:css && npm run lint:html",
"lint:js": "eslint ./app/ ./test/",
"lint:css": "sass-lint './app/assets/stylesheets/**/*.scss' -v -q",
"lint:html": "htmlhint ./app/server/views/*.dot"
},
"dependencies": {
"body-parser": "^1.15.1",
"config": "^1.19.0",
"connect-redis": "^3.0.2",
"debug": "^2.2.0",
"dot": "^1.0.3",
"express": "^4.13.4",
"express-session": "^1.13.0",
"http-status": "^0.2.1",
"log4js": "^0.6.36",
"mongoose": "^4.4.15",
"passport": "^0.3.2",
"passport-facebook": "^2.1.0",
"passport-google-oauth2": "^0.1.6",
"passport-twitter": "^1.0.4",
"redis": "^2.6.0-2"
},
"devDependencies": {
"angular": "^1.5.3",
"angular-mocks": "^1.5.3",
"angular-touch": "^1.5.3",
"async": "^1.5.2",
"browser-sync": "^2.12.5",
"browserify": "^13.0.1",
"browserify-istanbul": "^2.0.0",
"chai": "^3.5.0",
"comma-separated-values": "^3.6.4",
"eslint": "^2.9.0",
"exorcist": "^0.4.0",
"gulp": "^3.9.1",
"gulp-autoprefixer": "^3.1.0",
"gulp-clean-css": "^2.0.7",
"gulp-notify": "^2.2.0",
"gulp-plumber": "^1.1.0",
"gulp-sass": "^2.2.0",
"gulp-sourcemaps": "^2.0.0-alpha",
"htmlhint": "^0.9.13",
"istanbul": "^0.4.3",
"jquery": "^2.2.3",
"js-yaml": "^3.6.0",
"karma": "^0.13.22",
"karma-browserify": "^5.0.5",
"karma-chrome-launcher": "^0.2.3",
"karma-coverage": "^0.5.5",
"karma-firefox-launcher": "^0.1.7",
"karma-ie-launcher": "^0.2.0",
"karma-mocha": "^0.2.2",
"karma-mocha-reporter": "^2.0.3",
"karma-phantomjs-launcher": "^1.0.0",
"mocha": "^2.4.5",
"node-inspector": "^0.12.8",
"nodemon": "^1.9.2",
"phantomjs-prebuilt": "^2.1.7",
"request": "^2.72.0",
"sass-lint": "^1.7.0",
"supertest": "^1.2.0",
"svgo": "^0.6.6",
"uglify-js": "^2.6.2",
"watchify": "^3.7.0"
}
}
サーバサイドを開発中、実際にサーバを起動させて確認しつつコードを書きたい場合はnpm run start:watch、テスト駆動で書くときはnpm run test:server:watch、CSS開発中はnpm run start:syncとnpm run build:css:watchでライブリロードかけながらブラウザで確認しつつCSSをリアルタイムビルド、最終的なビルドはnpm run build、みたいに使う。
もちろん大きなプロジェクトだと状況は変わってくる。複数のエントリポイントがあるようならWebpackやGulpを使ったほうが楽なはずだ。ただ、今回の開発では、クライアントサイドJavaScript/CSSの最終的な生成ファイルは1つずつしかなく、その状況でいちばんシンプルな構成を考えたらこうなった。これがベストプラクティスというつもりは毛頭ないけど、小規模な開発ならそこそこ使える構成だと思う。
ES2015/altJS
未来のJavaScript、ES2015(ES6)についても少しふれておこう。
ES2015はES4という果たせなかった夢の実現であり、何がなんでもJavaScriptを使える言語にしてやるんだという強い意志のあらわれであり、すぐそこにある未来、手の届く範囲にあるものだ。でもそこに手を伸ばそうと思ったら、現状ではBabel、TypeScriptといったトランスパイラが必須なようだったので、今回の導入は見送った。
もちろんこういったPolyfillを使って先行実装した人たちのフィードバックが実際の仕様に反映され、ベンダがそれを実装し……というサイクルによってウェブが進化してきたことは理解しているけど、浦島太郎状態のいまの僕には少し荷が重いと判断した。各ベンダが対応しきってPolyfill不要になってから手を出しても遅くはない。
しかし最近はもうメタ言語というのは普通になってきているんだな、というのがまず最初に思ったことである。LESS/Sass(SCSS)しかり、Babel/TypeScriptしかり。
JavaScriptのメタ言語、いわゆるaltJSは、2010年前後から出現し始めて、そのときはもっと種類があったような気がするけど、最近は前述の2つが主流のようだ。あとはRuby使いのためのCoffeeScriptか。TypeScriptは型が使えるらしく、大規模開発なら導入する価値が大いにありそう。
とはいえ、今回の開発は全コード行数1万行を超えないレベルだし、素のJavaScriptでいけると判断した。Good Partsが何かを理解していれば、この「安物のおもちゃ」でも十分に本格的なコードを書けるというのは、いままでの経験からわかっている。
JavaScript史観
しかし変化の激しいウェブ界隈の中でも、特にJavaScriptの変化はすさまじい。
思えば90年代のJavaScriptはただのガラクタだった。当時のJavaScriptはおもにブラクラを作ったり、マウスカーソルに変なものを追尾させるのに使われていた。あやしいわーるどや2ちゃんねるを徘徊していると2日に1回くらいはブラクラに遭遇したため、ブラウザ設定でJavaScriptをオフにするのが一般的であった(あやしいわーるどや2ちゃんねるを見る行為が一般的だったかどうかはわからない)。エキサイトチャットのようなプログラムがブラウザ上で動いているように見えても、それはJavaアプレットというブラウザの外側にあるものの能力であり、ブラウザ自身の能力ではなかった。HTMLはあくまで文書構造を表現するためのものであり、ブラウザはあくまでそれをレンダリングするためのものであった。ブラウザは静的な文書を参照するための、ただの閲覧ソフト、ドキュメントビューアでしかなかった。90年代のJavaScriptは、世界にとって何の意味もない、誰の役にも立たない、ガラクタでしかなかった。
そしてゼロ年代に入ってもその状況は続く。このころはIEコンポーネントを利用した個人開発のブラウザが流行した時期である(e.g. MoonBrowser)。これらのブラウザではいちいち設定画面を開かなくてもJavaScriptのオン/オフを切り替えられたので、普段はオフにしておいて、どうしても必要になったときだけオンにする、というような使い方をしていた。そしてFirefoxが登場し、そちらに乗り換えてからは、NoScriptというアドオンを使い、どうしても必要なサイトだけホワイトリスト方式で許可する、というような使い方をしていた。
転機はゼロ年代中盤に訪れる。GmailとGoogleMapsの登場である。いまではもうインフラ化してしまったので当時の感覚を正確に思い出すことは難しいけど、これがJavaScriptで動いているという事実にとんでもない衝撃を受けたことは覚えている。たとえば、初めて蒸気機関車を見た人はあんなに大きな鉄の塊が蒸気で動いているという事実にどれほど衝撃を受けただろうか。インフラ化してしまった技術は、すぐさまあたりまえのことになって意識されなくなってしまうものだけど、その転換期、パラダイムシフトの瞬間は、とんでもない衝撃があるのだ。いやまあそこまでの衝撃ではなかったかもしれないけど、とにかく、GmailとGoogleMapsの登場は、それくらいのインパクトがあったのである。
その後、当時激しかったブラウザ間の差異を吸収するprototype.js等のライブラリが登場し、少しずつ状況が変わっていく。少しずつJavaScriptを多用したインタラクティブなサイトが増えていき、NoScriptのホワイトリストに追加するのが億劫になっていく。少しずつJavaScriptをオンにするのが「あたりまえ」になっていく。「あたりまえ」が反転する。
そしてjQueryの流行、Ajax技術の発展、ベンダ間の競争によるJavaScriptエンジンの最適化と高速化、等々を経て、かつてただのドキュメントビューアであったブラウザは、アプリケーションプラットフォームとしての地位を確立していく。このころから、Ajax技術を用いたページ遷移のない1ページだけで完結するウェブアプリケーションが増えていく。ちなみに最近はこれをSPA(Single Page Application)と呼ぶらしい。MicrosoftがGoogleDocsに対抗してウェブ版のOfficeを出したときはマジでびびった。こういうことは絶対にしなさそうなイメージがあったから。そういえばMicrosoftのオープン化はこのあたりから始まった気がする。
2010年代に入るとタブレット端末が普及し始め、またウェブは変革を求められ……となっていくけど、きりがないのでこのへんにしておこう。
人間の観測範囲には限界があるので、あくまでこれは僕の見てきた歴史でしかないけど、かつてJavaScriptはまったくの無価値だった時代があり、現在はそうではない、というのはまぎれもない事実である。そして、その転換点がどこにあったかと問われれば、GmailとGoogleMapsの登場だと僕は答える。
こうして、世界にとって何の意味もない、誰の役にも立たないガラクタだったJavaScriptは、現在ではウェブを動かす主力エンジンのひとつとなった。あくまで「安物のおもちゃ」でしかなく、そしてそのおもちゃっぽさはまったく抜けていないというのに、その「安物のおもちゃ」が、世界を動かす。世界をここまで変える。そのことを考えると、なぜかドキドキする。
マイクロサービス
さて、ここまでJavaScriptを中心に最近の技術トレンドを見てきたけど、そろそろ実際の開発、設計に移ろう。
どうも最近はマイクロサービスというアーキテクチャが流行っているようだ。「ひとつのことをうまくやれ」というUnixの哲学をウェブサービスにあてはめたようなものかな、と解釈した。外部に公開しないものであってもRESTfulなWebAPIとして個々の機能を開発し、それらを連携させて全体を動かす。個々の機能や入出力の方法を極端に制限することで、単体としての自由度は下がっても、耐えられる複雑さの規模が上がり、結果的に全体としての自由度は上がる、みたいな。どれかひとつの機能がダウンしてもサービス全体はダウンせず、被害を最小限に抑えられる、みたいな利点もあるようだ。疎結合って大事よね。POSTでデータを投げて、あとはオレオレ仕様で好きなようにやるというのは、いかにも自由度が高く、開発がしやすそうに思えるけど、システムの規模が大きくなるにつれ、それは不自由に変わるのである。
planetter.comは単機能のサービスなのでこのアーキテクチャを採用するまでもないのだけど、RESTへの回帰というのは非常に納得できる潮流だったので、このビッグウェーブに乗ることにした。
REST
そうするとまずはあらためて「RESTとは何か」を知らなければならない。RESTってエンジニアの中で「知ってるようで実は知らないランキング」上位に位置すると思うんだけど、どうだろうか。少なくともこのときの僕は「RESTについて解説せよ」といわれても、あやふやな説明しかできない状態だった。
まずは本屋へ向かう。やはり体系的に学びたいときはネットではなく書籍がいい。何冊か手にとってみて、いちばんしっくりきたのを1冊購入する。オライリーではない本だった。昔は技術書っていうとオライリーが他の出版社より一段上にあるイメージだったけど、いまはそうでもない気がする。これはたぶんオライリーのレベルが下がったわけではなく、他の出版社のレベルが上がったからなんだろうなと思う。ありがたい話である。
帰宅して最初はふんふんと読んでいたのだけど、以下の部分で目から鱗が10枚くらい落ちた。
検索のような機能は、検索行為をモデル化するのではなく、「検索結果」をリソースとして表現します。
HTTPメソッドでは実現できない機能があると感じたら、それが独立した別リソースで代替できないかを考える。検索機能を実現するSEARCHメソッドをHTTPに追加するのではなく、「検索結果リソース」をGETする、と考えることが重要である。
山本陽平 「Webを支える技術 -HTTP、URI、HTML、そしてREST」 技術評論社 p.299 p.295
/search?query=wordみたいなURIってよくあるし、それを見かけるたびに「やっぱりリソース指定に動詞使ってるよなあ」と思ってたけど、そうか、そういうことか。サーバ側で検索という「行為」を行っているかどうか、そんなことはクライアント側からすればどうでもいいのだ。もしかしたら検索という行為自体はすでに終わっていて、その結果をリソースとして返しているかもしれない(キャッシュを使っているなら実際そうだと言える)。そこはクライアント側からしてみれば十分に抽象化されていて気にする必要がない。だからその「行為」はもうすっとばして結果だけください、というのがGET /search?query=wordという文章になるのだ。
やばい、この本めちゃくちゃおもしろい。特に以下の部分がすごく印象に残った。
REST対SOAPの議論は熱を増し、最終的には意地の張り合いになりました。筆者が聞いたREST否定派の一番ひどい言説は「RESTはおもちゃ」です。この言葉の陰にはWebAPIを作っているWebベンチャーなどの技術者に対する、旧来のエンジニアからの侮蔑の意味が込められていたのではないでしょうか。「HTTPやURIだけで基幹システムが作れるのか?」「そんなものおもちゃでしかないじゃないか」と。しかし最終的にはRESTに軍配が上がります。
p.23
リソース設計
RESTについて理解を深めたら次はリソース設計だ。よく考えたらplanetter.comはRESTと相性がいい。リソースが単純な階層構造になっているからである。
現行バージョンのMySQLのテーブルとその主キーは以下のようなものである。
[plans]
user_id plan_id
[pcountries]
user_id plan_id pcountry_id
[pplaces]
user_id plan_id pcountry_id pplace_id
plansが最上位の階層、子がpcountries、孫がpplacesだ。pcountryとpplaceの頭文字pはplanned(計画上の)の意。プログラム中でCountry/Placeクラスがまた別に存在するので違いを明確化するためにこうした。
これをURIで表現するなら/:user_id/:plan_id/:pcountry_id/:pplace_idか。いや待て、「誰が」というのはいらなくないか? つまり、/:plan_id/:pcountry_id/:pplace_idでいいんじゃないか? いまはそれぞれのIDが4文字のランダム英数字なので、IDが被らないようにuser_idも主キーに含めているけど、plan_idの桁数を十分に増やせば、user_idはなくていいんじゃないか?
たとえばYoutubeである。Youtubeは動画を投稿したらhttps://www.youtube.com/watch?v=_T-tRJKuVFgというようなURIを取得できる。そしてこのURIをSNSで共有したり、ブログに貼り付けたりするわけである。このURIに作成者の情報は含まれない。含まれるのは動画のID情報だけだ。Youtubeは動画投稿サイトであり、動画が第一義であり、それを誰が作ったかというのは、さして重要ではないからだ。「誰が」という切り口は、チャンネルという別のリソースで表現している。それはとてもシンプルで、とてもわかりやすいリソース設計のように思える。
planetter.comはどうか。これは旅行プランを作るサービスである。名前通り、planが第一義であり、やはり「誰が」という部分は、あまり重要ではない。それはYoutubeのように別リソースで表現してもいいし、その必要性すらないように思える。あくまでこれはプランを作るサービスであり、データを作るサービスであり、作ったらそのURIが手に入るだけ、こちらではそれ以上のことは何もしない、というスタンスでいいのではないか。うん、なんかそれでいい気がしてきた。
/:plan_idでアクセスしたときは最上位にフォーカスした状態でページが開き、/:plan_id/:pcountry_idでアクセスしたときは国にフォーカスした状態でページが開き、/:plan_id/:pcountry_id/:pplace_idでアクセスしたときは地点にフォーカスした状態でページが開く。そしてそれぞれのリソースにPOST(作成)/PUT(更新)/DELETE(削除)ができる。
よし、これでいこう。だんだん全体像が見えてきたぜ。
MEANスタック
しかしこの時点ではまだどんな技術を使うか決めかねていた。言語はPHPか、データベースはMySQLのままでいいのか。あまり特別なこと、劇的なことはしたくない。あるていど枯れている技術がいい。浮足立ちたくない。地に足つけて生きていきたい。そう思いながらネットを調べていると、MEANスタックというものがあることを知った。
これはMongoDB、Express、AngularJS、Node.jsの頭文字を取ったもので、LAMPに変わるスタックとして最近注目されているようだ。あるていど導入実績、知見の積み重ねもある。お、これええやん。これにしたろ。
基本的な組み合わせが決まれば、あとはもう自動的に決まる。
Expressでも静的ファイルの配信やgzip圧縮はできるので、基本的にこれ単体でいけるけど、やはりそのあたりはnginxに任せてしまって、Expressはアプリケーションサーバとして専念させる。いまはサーバ1台だからいいけど、もし分散するとなったらそのときに泣きそうだし。
セッションストアはMongoDBでもいいかと思ったけど、やはりここはRedisを使っておこう。絶対に永続化しなければならないデータと、永続化したいけど、まあぶっちゃけセッション情報くらい消えてもいいよね、みたいなのは分けておく。
OSはCentOS7。ホスティング先はいままで通りさくらのVPSでいいか。コストパフォーマンスと信頼性から、ここ以外考えられない。
まとめると以下のようになる。
| key | value |
|---|---|
| ホスティングベンダ | さくらのVPS |
| OS | CentOS7 |
| データベース | MongoDB |
| セッションストア | Redis |
| リバースプロキシサーバ | nginx |
| アプリケーションサーバ | Node.js |
| サーバサイドJavaScriptフレームワーク | Express |
| クライアントサイドJavaScriptフレームワーク | AngularJS v1 |
| クライアントサイドJavaScriptプリプロセッサ | Browserify |
| CSSプリプロセッサ | Sass(SCSS) |
| ビルドツール | npm (一部Gulp) |
| ローカル開発環境 | Vagrant |
| バージョン管理 | Git |
| エディタ | Atom |
ディレクトリ構成
次はプロジェクトのディレクトリ構成だ。
まずはexpress-generatorで生成されるディレクトリ構成を見てみる。クライアントサイドJavaScriptがpublic/javascripts/にあるあたり、あまりSPA向けではない。
.
├── app.js
├── bin
├── routes
├── views
└── public
├── images
├── javascripts
└── stylesheets
次にgenerator-meanjsを見てみる。うーん、これもなんか違う気がする。
.
├── server.js
├── config
├── modules
│ ├── core
│ │ ├── client
│ │ ├── server
│ │ └── tests
│ └── users
│ ├── client
│ ├── server
│ └── tests
└── public
└── lib
├── angular
└── ...
ディレクトリ構成は重要なのでかなり時間をかけて調査したけど、どうも「MEANでのSPAならこれがベストプラクティス!」みたいなのはないようだ。ただ、最近のウェブ系フレームワークでRailsの影響を受けていないものは皆無なのだということはわかった。express-generatorで生成されるプロジェクトもあきらかにRailsの影響を受けてるし。
というわけでRailsを下敷きにしてSPA用のディレクトリ構成を独自に考えた結果、以下のような感じになった。
.
├── .gitignore
├── .eslintrc.yml
├── .sass-lint.yml
├── gulpfile.js
├── karma.conf.js
├── package.json
├── README.md
├── Vagrantfile
├── bin
│ ├── www
│ └── ...
├── config
│ ├── default.json
│ ├── development.json
│ ├── production.json
│ ├── staging.json
│ └── test.json
├── public
│ ├── app.css
│ ├── app.js
│ ├── favicon.ico
│ └── robots.txt
├── app
│ ├── assets
│ │ ├── images
│ │ │ └── ...
│ │ └── stylesheets
│ │ ├── _config.scss
│ │ ├── app.scss
│ │ ├── basics
│ │ │ ├── reset.scss
│ │ │ └── ...
│ │ ├── layouts
│ │ │ ├── navi.scss
│ │ │ └── ...
│ │ └── modules
│ │ ├── navi.scss
│ │ └── ...
│ ├── client
│ │ ├── app.js
│ │ ├── controllers
│ │ │ ├── app_controller.js
│ │ │ └── ...
│ │ ├── directives
│ │ │ └── ...
│ │ └── services
│ │ └── ...
│ └── server
│ ├── app.js
│ ├── models
│ │ └── ...
│ ├── routes
│ │ └── ...
│ ├── services
│ │ ├── logger.js
│ │ └── ...
│ └── views
│ └── ...
└── test
├── mocha.opts
├── assets
│ └── stylesheets
│ ├── navi.html
│ └── ...
├── client
│ ├── services
│ │ └── ...
│ ├── fixtures
│ │ └── ...
│ └── helpers
│ └── ...
└── server
├── models
│ └── ...
├── routes
│ └── ...
├── fixtures
│ └── ...
└── helpers
└── ...
今回の開発ではGoogleMapsをAngularJSから完全に切り離したので実際はもう少し複雑だけど、基本形はこれ。Railsを下敷きにMEANのSPA用構成を考えたら、たぶん誰でも似たような結果になると思う。
構文チェッカーの設定ファイル、.eslintrc.ymlと.sass-lint.ymlはAtomのLinterとnpm runタスク共用。.htmlhintrcは特別な設定が必要なかったので置いてない。
bin/以下はcronで実行するシェルスクリプトなんかも置いている。bin/wwwはexpress-generatorのものを参考に、冗長だった部分をそぎ落として簡素な形に書きなおした。
# !/usr/bin/env node
'use strict';
var http = require('http');
var config = require('config');
var logger = require('../app/server/services/logger');
var app = require('../app/server/app');
var server = http.createServer(app);
server.on('error', function(err) {
logger.error.fatal(err);
process.exit(1);
});
server.on('listening', function() {
logger.system.info('App running %s mode', app.get('env'));
});
server.listen(config.get('app.port'));
config/以下はconfigモジュール用。これは環境変数によって設定を切り替えられるモジュールだ。たとえばこの構成なら、NODE_ENV=staging node ./bin/wwwと起動すれば、default.jsonにstaging.jsonの値が上書きされた状態になる。プログラム中からconfig.get('app.port')のようにアクセスしたとき、staging.jsonのほうに設定値があればそちらを、なければdefault.jsonのほうが使われる、という具合である。NODE_ENVの他にもホスト名で切り分けられたり、かなり高度な使い方ができるので、このモジュールは大規模なシステム運用にも耐えられるんじゃないかと思う。
public/はnginxのドキュメントルート。app.*はビルドするので.gitignoreに登録して、リポジトリには含めない。
app/assets/stylesheets/はSCSSファイル群。その下のディレクトリはSMACSSにしたがって、basicsがベースルール、layoutsがレイアウト、modulesがモジュールとなっている。それらをエントリポイントであるapp.scssで以下のようにすべて読み込み、public/app.cssにビルドする。
@charset "UTF-8";
@import "./basics/reset";
// ...
@import "./layouts/navi";
// ...
@import "./modules/navi";
// ...
app/client/はクライアントサイドJavaScript。前述したようにGoogleMapsと完全に切り分けたこともあって実際のものとは少し違うけど、エントリポイントのapp.jsは以下のようになる。
'use strict';
require('angular')
.module('planetter', [require('angular-touch')])
.controller('AppController', require('./controllers/app_controller'))
// ...
.service('googleMaps', require('./services/google_maps'));
require()先のコントローラーやサービスは以下のように定義する。こうすることでkarma-browserifyを用いたユニットテストがしやすくなる。
'use strict';
module.exports = ['$scope', function($scope) {
// ...
}];
app/server/以下はサーバサイドJavaScript。これはexpress-generatorの仕組みほぼそのままなので説明は省略。
test/client/はクライアントサイドのユニットテスト、test/server/はサーバサイドのユニットテスト。test/assets/stylesheets/は、CSS確認用のHTMLファイルを置いている。最初はapp/assets/stylesheets/html/以下にこのHTMLファイルを置いてたけど、よく考えたらこれってCSSのユニットテストだよなと思って、test/以下に移動した。Browsersyncを使えば、PCの画面もタブレットの画面も、とにかくページを開いているブラウザはすべて、ファイルが更新されたタイミングで自動的にリロードされるので、コーディング→チェックのフローが劇的にスピードアップする。
UIデザイン
プロジェクトの基礎的な骨組みはだいぶできてきた。次はUIデザインに移ろう。
まずは現行バージョンのUIを見てみる。
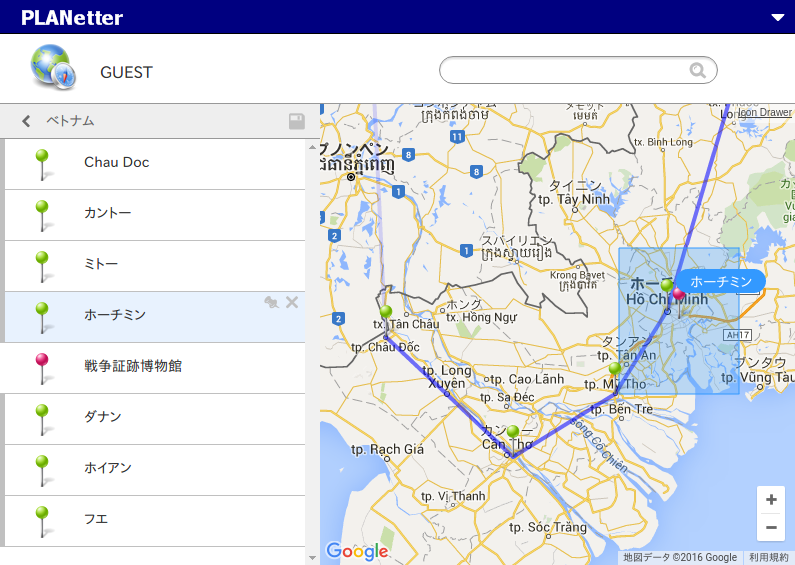
ダサい。超ダサい。死にたい。スマホ/タブレットにも対応してない。これを自分で今風のイケてるデザインにするとか、完全なるミッションインポッシブルに思える。死にたい。
しかし今回は個人開発である。デザイナさんという魔法使いはいないのだ。ドラクエIなのだ。すべてひとりでやらなければならないのだ。おとなしく覚悟を決めてこのクエストに立ち向かおう。
そうだ、しばらく開発の世界から遠ざかっていたとはいえ、デジタルな世界から遠ざかっていたわけではない。PCを使う頻度は下がったものの、その分タブレットを使っていたのである。友達がいないのでLINEとかのコミュニケーションツールは一切使っていないけど、それ以外のツールはよく使っている。だから最近のUI/UXの「文脈」は、多少なりとも理解しているつもりだ。そのあたりから攻めていこう。
まずはWindows10である。Windows8.1 with Bing、いわゆる0ドルWindowsが出たあたりからWindowsタブレットが安くなっていたので10インチの2in1スレートPCを買ってしばらく使っていたのだけど、去年Windows10が出てアップグレードしたときに、「お、このデザインすごい」と思ったのだった。IE11等の旧来からのアプリケーションはともかく、Edgeをはじめとする新しいアプリケーション群は、どう見てもタブレット用にデザインされている。そして僕が使っていたのは2in1マシンなのでマウス(タッチパッド)&キーボードで操作するときもあるのだけど、そのときでもさほど違和感を覚えない。これがユニバーサルデザインというやつかと思った。Microsoftはこういう方向にいくのかと思った。そしてこれは正解だと思った。2in1マシンを使っていると、「マウスか、タッチか」なんてのはそのときの気分でしかない。ユーザーがマウスを手にしているか、画面を直接タップしているかなんてことは、もはや開発者は考えるべきではないのだ。clickというイベント名が意味をなさなくなってきているような状況なのだから。
これをウェブにあてはめるとどうか。数年前はUser-Agent文字列で判定してPC用/スマホ用のスタイルを切り替えるとかやっていたけど、それはもう通じなくなってきている。その境界はもはやなきに等しいのだ。PCでもタブレットでもスマホでも同じ感覚で、しかしその表示領域は最大限活用できるような、そういったデザインが求められているのである。
というようなことをいろいろと考えた結果、以下のような感じになった。
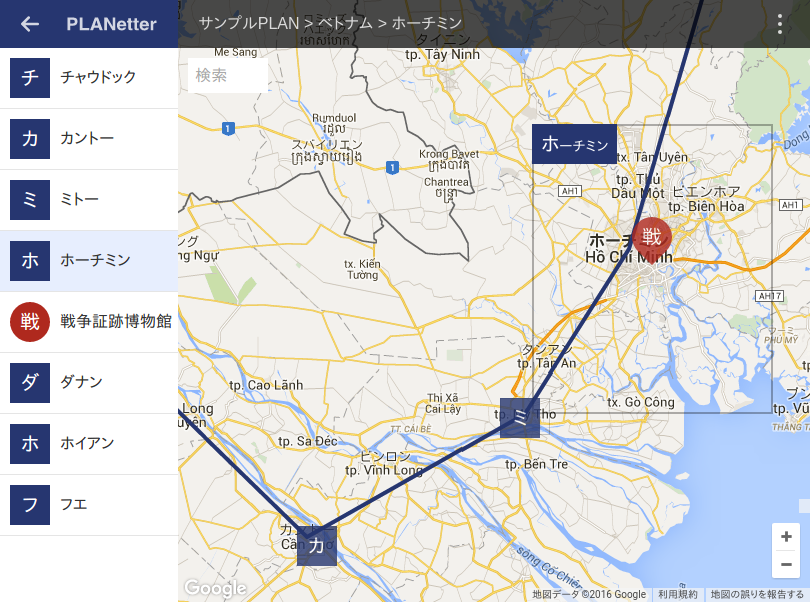
スマホで見るとこんな感じ。
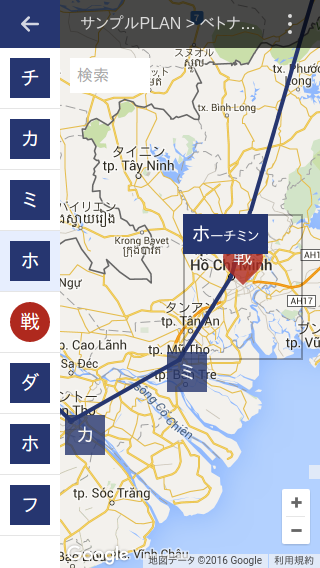
だいぶ今風になった気がする。
非同期プログラミング
デザインもあるていど固まったところで、そろそろコードを書いていこう。まずはサーバサイドからだ。JavaScriptは昔かなりやりこんだからNode.jsも余裕だろうと思っていたけど、それはとんでもない思い上がりだった。
まず、例外が使い物にならない。前提として――よく知られたことではあるけど復習しておこう――以下のコードは期待通りの動作をしない。
try {
setTimeout(function() {
throw new Error('async error');
}, 0);
} catch (e) {
console.log(e); // ここに来そうに見えるけど来ない
}
なぜならsetTimeout()が非同期実行されるからである。そしてNode.jsはシングルスレッド・イベントループの利点を維持するため「すべてのライブラリはスレッドをブロックしてはならない」という制約があるので、万事がこの調子である。こういった事情により、Node.js界隈では非同期メソッドの実行時に何か問題が発生しても例外を投げず、コールバックの第一引数にErrorオブジェクトを取るのが慣例となっている。しかしそうするとただでさえやばいコールバック地獄が、その階層ごとにエラーハンドリングまで課されて、さながら無間地獄の様相を呈する。
この問題への解答のひとつとして、domainモジュールというものがあるのだけど、現在の安定版v4の時点ですでにDeprecatedとなっている。そして代替策はいまのところ用意されていない。
This module is pending deprecation. Once a replacement API has been finalized, this module will be fully deprecated. Most end users should not have cause to use this module. Users who absolutely must have the functionality that domains provide may rely on it for the time being but should expect to have to migrate to a different solution in the future.
この問題への解答は他にもいろいろとあるようだったけど、どれも決め手に欠けるというか、公式の方法でない以上、別の地獄に片足を突っ込んでる感があって躊躇してしまう。
これは考え方を根本的に変えた。そもそも、エラーハンドリングとは、大変なものなのだ。例外に頼っていたいままでが楽をしすぎていたのだ。
それに、Node.jsの慣例にしたがっていれば、さほど混乱はしない。コールバックの第一引数にErrorオブジェクトがあるかないか、コールバック実行時の第一引数にErrorオブジェクトを渡すかnullを渡すか。実際のところ、これだけで十分だった。Expressに関してはミドルウェアでバケツリレーをしていくだけなので、それほどネストが深くなることもないし。
しかしそれでも非同期であるということそれ自体の難しさが薄れるわけではなかった。いやマジでやばい。なんだこの難しさは。本当に最近のプログラマはみんなこんなことやってるのか。マジかよ。信じられない。頭を抱えつつ、これはなんだか覚えのある感じだと思った。これはあれだ、プログラミングを始めたばかりのころ、再帰関数というものがまったく組めなくて懊悩したときの、あの感じに似ている。いまではなんで組めなかったのか謎なくらいだけど、非同期プログラミングもそうなるのだろうか。再帰関数はマトリョーシカ的に深層に潜っていくだけでしかないけど、こちらはそんな単純な話ではない。あっちこっちに飛び火してもう大変。処理の流れがまったくつかめない。プログラムを脳内に展開できない。どうしてこうなった。
しかしそうやってまた懊悩しながらもコードを書き続けていると、少しずつ非同期の世界にも慣れてきた。あらゆることが非同期に進行するこの混沌とした世界が、ある種の整然さを持つようになってきた。どんなことでも繰り返し脳みそに電流を流し続けていれば、それなりに新しい回路ができてくるものだと思った。
Node.jsの性格もわかってきた。何が好きで何が嫌いか、何が得意で何が苦手か、どう話しかければどう答えるのか。だんだんとNode.jsのおもしろさがわかってきた。
そうしてコードを書き続けるうち、ふいに昔のことを思い出した。
初めて会話した日の記憶
もう10年以上前のことになる。当時、僕は3ヵ月更新の派遣で半導体工場のライン作業員をしていた。前工程から流れてきたチップを加工・検査して後工程に流すだけの、特に難しいところもない単純作業だった。朝起きて、職場に行き、単純作業をして、仕事が終わればスーパーで半額惣菜を買い、誰もいない空っぽの部屋に帰り、モソモソと食って、寝る。その繰り返し。繰り返し。夢も希望もない生活だったけど、そもそも僕は夢も希望も必要としていなかった。特にやりたいことがあるわけでもなく、特に何の望みもなかった。世界に色彩はなく、すべてはモノトーンだった。
そんな僕の唯一の人間らしい行動がプログラミングだった。当時はPHPが流行り始めたくらいのころで、ウェブプログラミングといえばまだPerlでCGIを組むのが主流だった。標準入力から読み込んだPOSTデータを自力でパースしていたような牧歌的な時代である。
そのときの僕はソケットプログラミングに挑戦していた。理由はうまく思い出せない。とにかくローカルで完結するようなプログラムには興味がなかった。ネットワークプログラミングしかしなかった。
まず手始めにHTTPサーバと通信してみることにした。しかし軽い気持ちで始めたそれは、非常に難しいことなのだとすぐに思い知らされた。いままでCPANのモジュールを使ってHTTP通信をしていたけど、それを低レベルからすべて自分でやるとなるとこんなに大変なのかと思った。何度もエラーを出しながら、それでもなんとかTCP接続できるようになった。
よし、次だ。次はサーバにHTTPリクエストを投げる。まずはリクエストラインGET / HTTP/1.1、続けてHostヘッダ、そして空行、これで実行。エンターキーを押してから数百ミリ秒の間をおいて、ターミナルにHTTP/1.1 200 OKと表示される――その瞬間、モノクロの世界に色彩が戻った、ステータスラインのあとはヘッダが続く、ああそうか世界はこんな色をしてたんだっけと唐突に思い出した、空行をはさんでボディが表示される、それは僕が初めてHTTPサーバと「会話」した瞬間だった。そして次の瞬間、視界が一気に拡散する。いまこの瞬間もHTTPリクエスト/レスポンスが何千何万何億何兆とネットの海を飛び交っているのが見える。気が遠くなる。深夜ラジオの人生相談、誰にも届かないCQ、掲示板のくだらない書き込み、ダイヤルアップの接続音。いろんな音・イメージが頭の中を駆け巡る。不思議な感覚。見知らぬ誰かと机の下でヒソヒソ話をしているような、そんな感覚。その相手が誰だったのか、HTTPサーバを開発した人だったのかもしれないし、RFC2616を策定した人だったのかもしれない。それはわからない。だけど、なぜかその「会話」は、冗談もごまかしもない、本物のコミュニケーションなのだと思えた。
Node.jsのコードを書いているとき、そんな遠い日の記憶、あの妙なドキドキ感を思い出した。そしてそうするうちに、すっかりNode.jsが手に馴染むようになっていた。
BDD
よし、ウォーミングアップはこのくらいにして、そろそろ本格的な開発に入ろう。
まずはテストだ。時代はテストファーストである。しかし最近はテスト駆動開発、TDD(Test Driven Development)ではなく、振る舞い駆動開発、BDD(Behavior Driven Development)というのが主流になっているようだ。なんぞwwwどう違うんぞwww
とりあえずテストフレームワークmochaを導入する。アサーションライブラリは無難にchaiを使う。最近はpower-assertというのも流行っているようだ。"No API is the best API"のキャッチコピーには惹かれるものがあるけど、やはり僕は多少冗長でも自然言語に近い感じでアサートを書きたい。このあたりは流行りがどうこうより自分の肌感覚に合ったものを選んだほうがいいように思う。
BDDでは以下のようにテストケース、もとい、スペック(要求仕様)を書くようである。
describe('Planモデル', function() {
it('ラベルが空文字なら更新できない', function() {
//...
});
});
なるほど、わからん。テストケースとどう違うのよ……と、本当にまったく違いがわからず、不安になってGithubでいろんな人のBDDの書き方を見てまわった。そしてわかった。これは日本語で書いているからダメなのだと。だから上記のスペックは以下のように書き換えた。
describe('Plan model', function() {
it('should not update with empty label', function() {
//...
});
});
こうすると自然文として意味が取れるようになった。
- describe A 「これからA(主語)について述べます」
- it 「それ(主語)は」
- should ... 「〜となるはずです」
そしてこのスペックが通らなかった場合には、"Plan model should not update with empty label"のように、ちゃんとした文章になってレポートされる。こういう仕様になってるはずだけど要求を満たしてないよ、なんとかしてよ、というふうに。
もちろんスペックの粒度、対象、誰を主体とするか(プログラマか顧客か)によってもいろいろと変わってはくるけど、「最終的に要求仕様として意味の通る文章にする」というところに気をつけていればいいようだ。
istanbul
「どこがテストできてて、どこができてないか」はやはり把握しておきたいのでいちおうカバレッジも取っておく。ツールはistanbulを使った。名前がなんかいい。
サーバサイドは単純なWebAPIだからテストしやすいし、ほぼ完全網羅、90%以上を目標にする。curlコマンドをずらずらと保存しておくとか嫌すぎるし、コードできっちり書き残す。クライアントサイドはテストがしにくいので、正直なくてもいいかなくらいの感じに考えておく。モデルまわりだけきっちりやって、コントローラーは……別にいいや、うん。HTTP通信関連以外のモックが必要になってきたらやめる。モックを使うってなると急激に難易度、というかめんどくささが上がるし、ボーダーラインの設定としてはこれくらいがちょうどいい気がする。
E2E(End to End)テストも今回はなしにした。やはりGUIに近づくにつれてテストの難易度、めんどくささは上がるし、そのコストに対するベネフィットがあるかどうかを考えなければならない。そして今回はめんどくささが勝った。
karma
クライアントサイドのテストは普通にkarmaを使う。CDN上にあるスクリプトも読み込めるので超助かった。これができなければGoogleMaps関連のテストが一切できないところだった。もしくは膨大なモック……あ、考えただけで死にたい……。
'use strict';
module.exports = function(config) {
config.set({
singleRun: true,
browsers: ['PhantomJS'],
frameworks: ['mocha', 'browserify'],
reporters: ['mocha', 'coverage'],
files: [
'http://maps.googleapis.com/maps/api/js?libraries=geometry,places',
'./test/client/**/*.js'
],
preprocessors: {
'./test/client/**/*.js': ['browserify']
},
browserify: {
debug: true,
transform: [require('browserify-istanbul')]
},
client: {
mocha: {
timeout : 5000
}
}
});
};
mongoose
MongoDBとのやりとりはmongooseを使った。バリデーション機能があるのでMongoDBのスキーマレスという部分を補完できたり、いろいろと高機能ではあるのだけど、そのせいなのか重い。プログラムを実行してて感じるレベルではないけど、ベンチマークを取ってみるとあきらかに重い。どうもmongooseオブジェクトを作成すること自体が重いようなので、save()メソッドとかが必要ないときは、leanオプションを付けてfindById()することにした。こうすることでmongooseオブジェクトではなく、素のObjectオブジェクトとしてドキュメントを取得できる。
というか実際に開発を進めてみて感じたけど、MongoDBはわりと重い。小さいデータならかなり速度は出るけど、あるていどのサイズになるとガクンと速度が落ちる。今回はほぼ何も考えずにMEANスタックの一部だからという理由でMongoDBを採用したけど、次回バージョンアップ時には少し再考したい。Cassandraとかがいいのかな。でもオーバースペックな気もするし。うーん。
doT
テンプレートエンジンはdoTを使った。これはあまり一般的ではないので以下は参考ていどに。
これを採用したのには経緯があって、まず素のhttpモジュールを使ったサーバに比べて、Expressで作ったサーバがやたら重かった、というところに端を発する。いろいろと試してみて、Expressのレスポンスメソッド、send()やjson()は重くない、render()が重いのだ、ということがわかった。そのとき使っていたEJSが重いのかと思ったけど、Expressのテンプレートエンジンとしてではなく素のEJSとして使って、その結果文字列をsend()で出力してみると、あら不思議、重くない。つまりテンプレートエンジンではなく、render()メソッド自体が重いのである。えー、じゃあこの方法でいくか、でも待てよ、それならもうEJSじゃなくていいじゃん、今回の開発ではAngularJSのほうでほとんどの処理をするんだし、テンプレートエンジンにイテレータとかいらない、条件分岐と変数展開さえできればいい。そういうシンプルで高速なテンプレートエンジンないかなー、と思って探して発見したのがdoTなのであった。JavaScriptテンプレートエンジン最速を謳っているけど、誇張ではないと思う。
doTをExpressのテンプレートエンジンとしてではなく素で使う場合は以下のようにする。
'use strict';
var path = require('path');
var dot = require('dot');
dot.templateSettings = {
interpolate: /\{%=([\s\S]+?)%\}/g,
encode: /\{%!([\s\S]+?)%\}/g,
conditional: /\{%\?(\?)?\s*([\s\S]*?)\s*%\}/g,
varname: 'it',
strip: (process.env.NODE_ENV === 'production')
};
module.exports = dot.process({
path: path.join(__dirname, '../views')
});
デフォルトでは{{ }}がデリミタになるけど、AngularJSのそれとかぶるので{% %}に変更している。イテレータ等が必要ない場合はここで設定しなければ処理がスキップされるようである。すばらしい。stripはいわゆるuglify。productionモードのときだけ有効にしている。
テンプレートファイルは*.dotで保存する。
<!DOCTYPE html>
<title>Hello</title>
<p>{%! it.message %}
こうするとプログラム起動時にテンプレートファイル名のメソッドが自動的に作成される。つまり上記のテンプレートファイルがあればhello()メソッドが使えるようになる。
たとえばこれを/helloでアクセスした時に出力したい場合は以下のようにする(実際のコードではRouterを使ったほうがいい)。
'use strict';
var app = require('express')();
var template = require('./services/template');
app.get('/hello', function(req, res) {
res.send(template.hello({ message: 'Hello world!' }));
});
app.listen(3000);
passport
OAuth認証にはpassportを使った。これはプラグイン方式になっていて、passport-facebookやpassport-twitterといった認証ストラテジを追加すれば、さまざまなサービスのOAuth認証を簡単に実装できる。
該当サービスのAPIリファレンスを見て自力で実装してたあのころの苦労はいったい……。
AngularJS
AngularJSに関してはもはや語り尽くされていると思うのでざっくりはしょる。
本気出す
本気出した。
systemd
開発もいよいよ大詰めだ。最後にアプリケーションサーバの永続化について検討する。
開発中はコマンドラインからnode ./bin/wwwとするような起動でよかったけど、それで本番運用するわけにはいかない。万が一プログラムが不正終了した場合、落ちっぱなしになってしまうからである。それを回避するため、デーモンを管理するデーモンが必要になってくる。
nodemonは開発用という感じだし、foreverは更新が止まってしまっているし、PM2は高機能すぎてちょっと僕の手には余る。いろいろ考えて、結局npmのモジュールではなくCentOS7標準のsystemdを使うことにした。
まずは実行用ユーザを作成する。ログイン不可、ホームディレクトリなし。
$ sudo useradd -s /bin/nologin -M planetter
/etc/systemd/system/以下にUnit定義ファイルを作る。
[Unit]
Description=planetter backend
After=network.target remote-fs.target nss-lookup.target
[Service]
ExecStart=/usr/bin/npm start
WorkingDirectory=/var/www/planetter
Restart=always
User=planetter
Group=planetter
Environment=NODE_ENV=production
[Install]
WantedBy=multi-user.target
そしてsystemctlコマンドで起動させる。
$ sudo systemctl start planetter
systemctlはstartしても何の反応も返してくれないので起動したのかどうかわかりにくい。statusで確認する。
$ systemctl status planetter
● planetter.service - planetter backend
Loaded: loaded (/etc/systemd/system/planetter.service; disabled; vendor preset: disabled)
Active: active (running) since ...
ちゃんと起動しているようだ。次は自動起動の設定をしてみる。
$ sudo systemctl enable planetter
Created symlink from /etc/systemd/system/multi-user.target.wants/planetter.service to /etc/systemd/system/planetter.service.
$ systemctl status planetter
● planetter.service - planetter backend
Loaded: loaded (/etc/systemd/system/planetter.service; enabled; vendor preset: disabled)
Active: active (running) since ...
有効化されたようである。とりあえずすべて元に戻す。
$ sudo systemctl stop planetter
$ sudo systemctl disable planetter
Removed symlink /etc/systemd/system/multi-user.target.wants/planetter.service.
$ systemctl status planetter
● planetter.service - planetter backend
Loaded: loaded (/etc/systemd/system/planetter.service; disabled; vendor preset: disabled)
Active: inactive (dead)
app/server/app.jsに以下のようなコードを仕込み、もう一度systemctl startする。
app.get('/exit', function(req, res) {
process.exit(1);
});
そしてブラウザで/exitにアクセス。反応はない。強制終了したようだ。そしてしばらくしてからトップページにアクセス。ちゃんと反応が返ってくる。不正終了時にもちゃんと自動で復帰することを確認できた。
リリース
永続化の問題も解決したのでリリース準備に入る。
まずはさくらのVPSの新規サーバ申し込みだ。SSDプランが新しく追加されていたのでこちらを選ぶ。デフォルトOSはまだCentOS6だったのでカスタムインストールでCentOS7を入れる。そして起動。
ちなみにさくらのVPSのウェブコンソールはなかなか優秀で、クリップボードからの貼付けや、いったんテキストエリアに入力してからの送信ができる。つまりシェルスクリプトをブラウザ上から流し込める。ぶっちゃけこれができればSSHで接続する必要性は感じないので、もう80番ポート以外はすべて閉じた。
新サーバ上でのテスト実行……問題なし。前バージョンからのデータコンバート……問題なし。しばらくステージングモードで動作させて様子見……問題なし。DNSを旧サーバから新サーバへ書き換え……問題なし。リリース作業完了。
そしてまた、あの日のメッセージ
ウェブの世界はドッグイヤーだ。3年も経てば何もかもが変わっている。ここまで駆け足で最近の技術トレンドを追ってきたけど、情報量の多さに何度も溺れそうになった。それはもうすべてを押し流していく濁流のようなもので、誰も留めることができない。誰にも制御できない。
その原動力は、何なのだろうか?
ふいにそんなことを考えながら、僕は最終的な確認のため、公開したばかりのサーバにGETリクエストを投げた。
エンターキーを押してから数百ミリ秒の間をおいて、ターミナルにレスポンスが表示される。
その1行目は、やはりあの日と同じメッセージだ。
HTTP/1.1 200 OK