Summary
- 1,001社のB2Cサービスを30人のAI人格で評価し、実際の市場成功度との相関を検証
- ピアソン相関 r = 0.637(中〜強の正の相関)
- 予測正解率 76.5%、F1 = 0.818(閾値70%)
- 成功サービスの検出は得意(再現率90%)だが、**「コンセプトは良いが実行で失敗」したサービスの検出力は33%**と低い
- AI評価は「需要のポテンシャル」の指標として有効。ただし「実行力」は測れない
1. はじめに
「AIに30人分のペルソナを演じさせて事業アイデアを評価する」というサービスを作りました。
しかし当然の疑問として**「AIの評価って本当に当たるの?」**があります。
そこで1,001社のB2Cサービスを実際に評価し、現実の市場成果と照合する**後方検証(バックテスト)**を実施しました。本記事ではその全データと分析手法を公開します。
2. 技術的背景
2.1 AIペルソナのアーキテクチャ
各ペルソナは以下の7層構造で設計されています:
Layer 1: Demographics(年齢、性別、職業、年収)
Layer 2: Values(リスク許容度、革新性受容度、ブランド信頼度)
Layer 3: Beliefs(信念体系 — 3〜5個の核心的信念)
Layer 4: Decision Logic(判断の優先順位)
Layer 5: Memory(過去の経験とその影響)
Layer 6: Personality(MBTI、思考スタイル、口癖)
Layer 7: Psychology(恐れ、願望、購買トリガー)
これはStanford大学のPark et al.(2023)によるGenerative Agents研究を発展させた「Belief-Driven Persona」アプローチです。
従来のペルソナ(年齢・性別のみ)とは異なり、「なぜその判断をするか」まで再現します。
2.2 使用モデル・インフラ
| 項目 | 技術 |
|---|---|
| LLM | Gemini 2.5 Flash(response_mime_type: "application/json") |
| ペルソナ数 | 30人(20歳〜65歳、15都市、年収72万〜1,200万円) |
| バックエンド | FastAPI on GCP Cloud Run |
| DB | Supabase(PostgreSQL) |
| 同時実行 | asyncio.Semaphore(15) で30人を並列評価 |
2.3 評価の仕組み
1ペルソナにつき1回のLLM呼び出しで、以下のJSONを生成:
{
"interest_level": "High" | "Medium" | "Low",
"decision": "Yes" | "No",
"reason": "一人称の2-3文の理由"
}
30人分を集計して:
- 興味率 = (High + Medium) / 30 × 100
- 利用意向率 = Yes / 30 × 100
3. 検証方法
3.1 データセット
| 項目 | 値 |
|---|---|
| 評価対象 | 1,001社のB2Cサービス |
| 評価レスポンス総数 | 30,030件 |
| カテゴリ | 飲食、テクノロジー、金融、EC、エンタメ等17分野 |
| Ground Truth対象 | 85社(公開情報に基づくスコアリング) |
3.2 Ground Truth(実績スコア)
85社のサービスに対し、公開情報(MAU、市場シェア、売上、企業の状態)に基づき5段階評価を付与:
| スコア | 定義 | 社数 | 代表例 |
|---|---|---|---|
| 5(支配的) | 市場シェア1位 or 国民的 | 20 | LINE, Amazon, PayPay |
| 4(成功) | 大手 or 急成長中 | 30 | Netflix, chocoZAP, タイミー |
| 3(中程度) | 一定シェアだが課題あり | 20 | Airbnb, Zoom, DAZN |
| 2(苦戦) | 衰退・撤退・大幅減収 | 15 | Clubhouse, OYO, いきなり!ステーキ |
3.3 分析手法
- ピアソン相関係数:線形相関
- スピアマン順位相関係数:順位ベースの相関
- 二値分類の予測精度:Accuracy, Precision, Recall, F1
4. 結果
4.1 相関分析
| 分析手法 | 興味率 | 利用意向率 |
|---|---|---|
| ピアソン相関 | r = 0.637 | r = 0.646 |
| スピアマン順位相関 | ρ = 0.373 | ρ = 0.480 |
Cohenの基準ではr = 0.5以上は「大きな効果量」です。AI評価は実際の市場成功度と統計的に有意な相関を持っています。
以下の散布図で、AI興味率と市場成功度の関係を可視化しました:
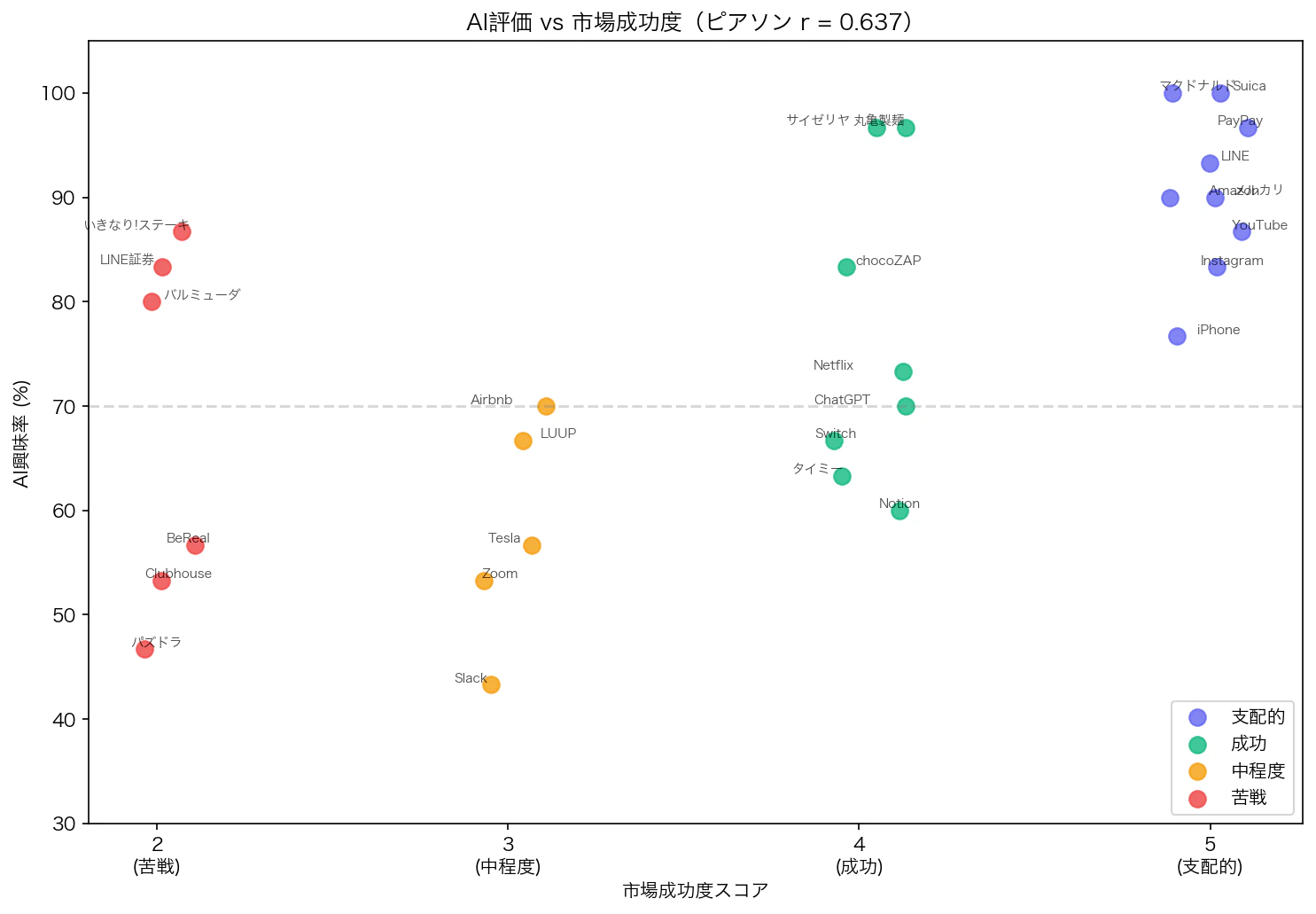
右上(支配的×高興味率)にLINE、Amazon、PayPay等が集中し、左下(苦戦×低興味率)にClubhouse、パズドラ等が位置しています。ただし左上の「苦戦しているが興味率が高い」領域に、いきなり!ステーキやLINE証券が存在する点が重要です。
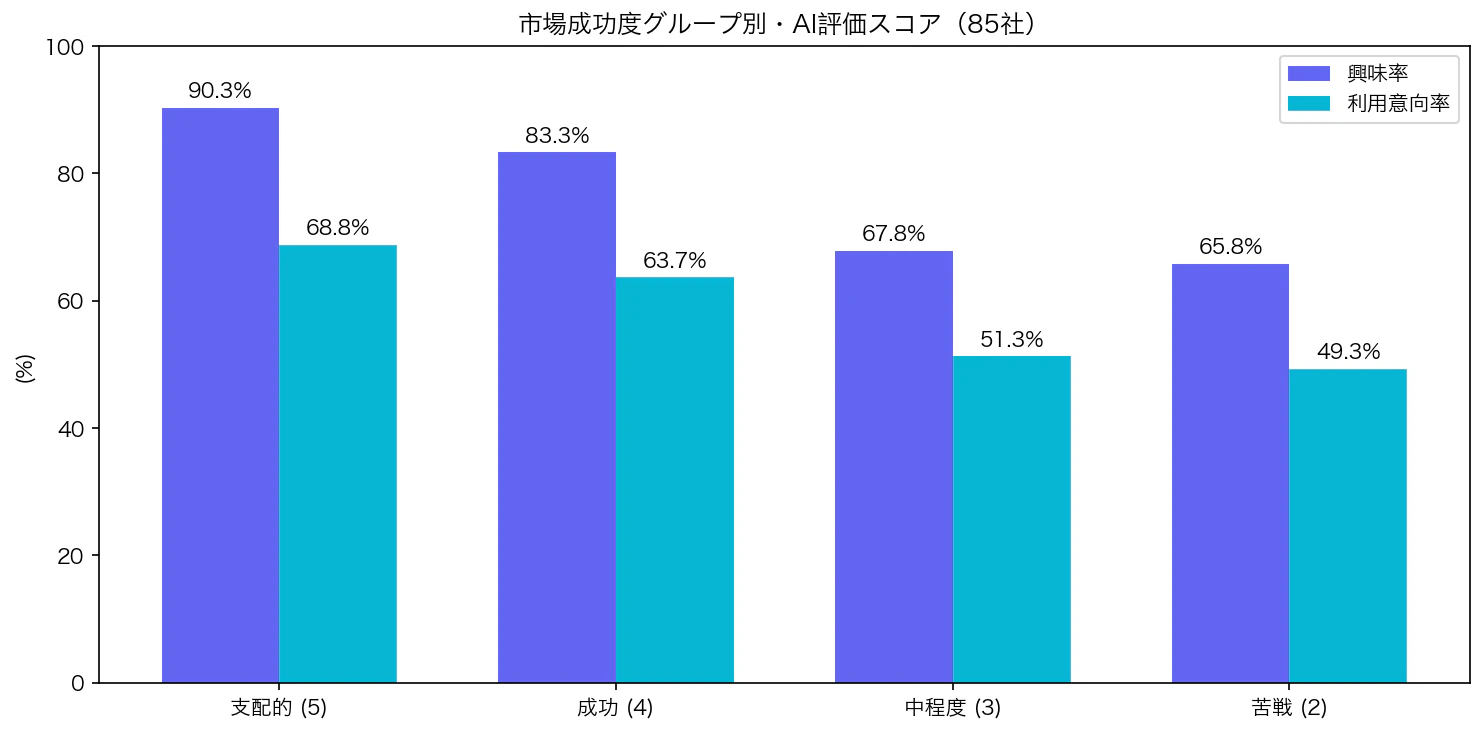
4.2 グループ別平均興味率
支配的(5) ████████████████████████████████████████████████░░ 90.3% (20社)
成功 (4) ██████████████████████████████████████████░░░░░░░░ 83.3% (30社)
中程度(3) ██████████████████████████████░░░░░░░░░░░░░░░░░░░░ 67.8% (20社)
苦戦 (2) ████████████████████████████░░░░░░░░░░░░░░░░░░░░░░ 65.8% (15社)
成功度が高いほど興味率も高い、明確な単調増加が確認できます。
4.3 予測精度
「興味率X%以上 → 成功(スコア4以上)と予測」の結果:
| 閾値 | 正解率 | 適合率 | 再現率 | F1 |
|---|---|---|---|---|
| ≥80% | 74.1% | 79.2% | 76.0% | 0.776 |
| ≥70% | 76.5% | 75.0% | 90.0% | 0.818 |
再現率90% = 実際に成功したサービスの90%をAIが「興味率70%以上」と正しく識別。

4.4 具体的なデータ(一部抜粋)
支配的サービス(平均興味率90.3%)
| サービス | 興味率 | 利用意向 | 実績 |
|---|---|---|---|
| Suica | 100.0% | 80.0% | 交通系IC 8,000万枚 |
| マクドナルド | 100.0% | 83.3% | 国内3,000店舗 |
| PayPay | 96.7% | 73.3% | QR決済シェア60% |
| LINE | 93.3% | 70.0% | MAU 9,600万人 |
| Amazon | 90.0% | 70.0% | 日本EC売上1位 |
| メルカリ | 90.0% | 80.0% | フリマシェア1位 |
| YouTube | 86.7% | 63.3% | MAU 7,000万人 |
| 83.3% | 70.0% | MAU 3,300万人 |
苦戦サービス(平均興味率65.8%)
| サービス | 興味率 | AI検出 | 実態 |
|---|---|---|---|
| パズドラ | 46.7% | ✅ | 全盛期から大幅減収 |
| Clubhouse | 53.3% | ✅ | ブーム後急速に衰退 |
| ウマ娘 | 53.3% | ✅ | ピーク時から売上大幅減 |
| BeReal | 56.7% | ✅ | 日本では定着せず |
| いきなり!ステーキ | 86.7% | ❌ | 大量閉店 |
| LINE証券 | 83.3% | ❌ | サービス終了 |
| バルミューダ | 80.0% | ❌ | スマホ撤退、家電も苦戦 |
5. 考察:なぜ失敗サービスを見抜けないのか
失敗サービスの検出率は33%(15社中5社) と低い結果でした。
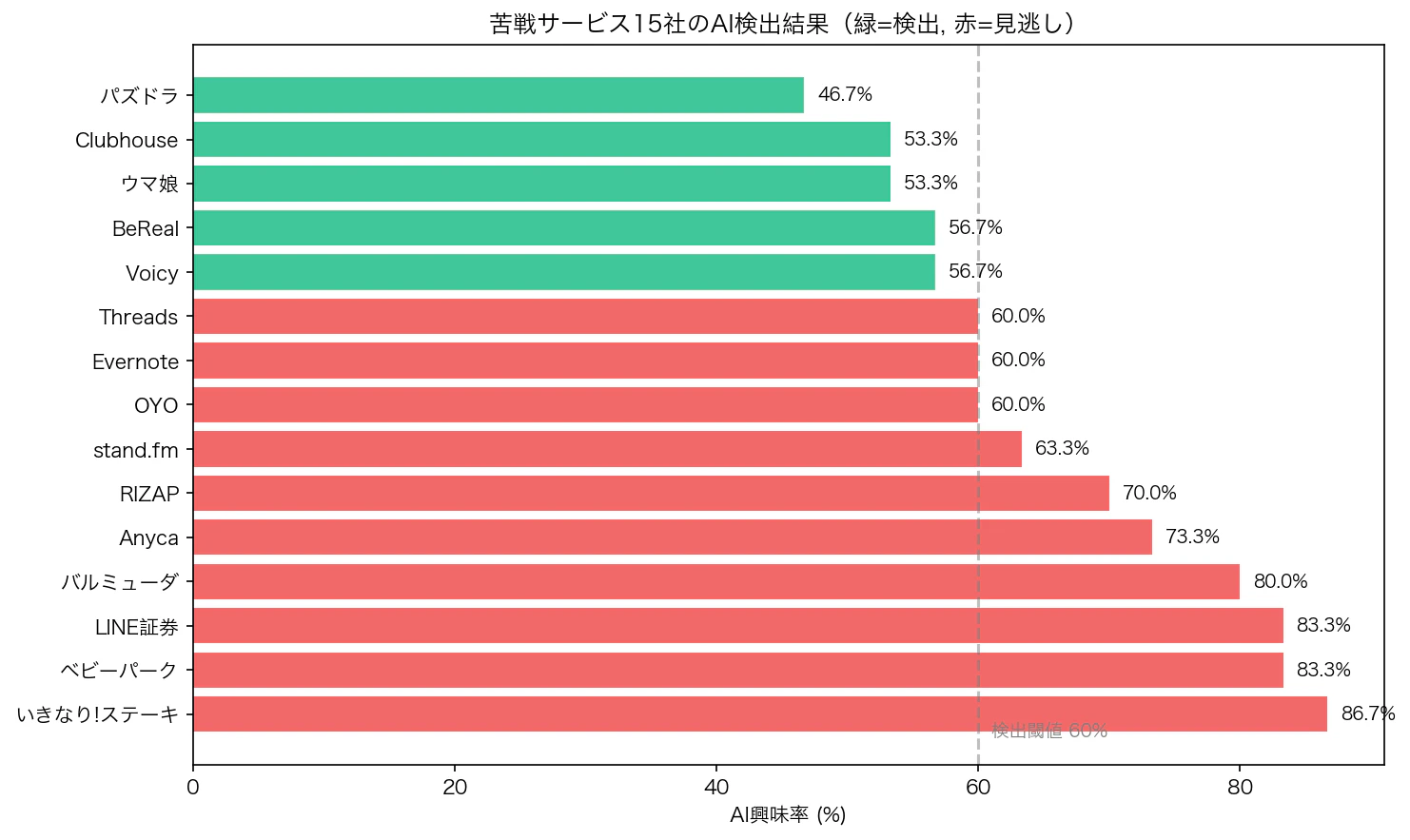
見逃した10社を分析すると:
「コンセプトの質」と「実行の質」は別物
いきなり!ステーキ(興味率86.7%)は「立ち食いステーキ」というコンセプト自体は魅力的でした。実際に初期は急成長しています。失敗の原因は過剰出店という経営判断です。
LINE証券(83.3%)も「LINEから株取引」というコンセプトには高い需要がありました。終了の原因はLINE・Yahoo統合に伴う戦略的判断です。
つまりAIペルソナが測定しているのは:
✅ 「このサービスを欲しいか?」(需要のポテンシャル)
❌ 「このサービスは成功するか?」(実行力・戦略・タイミング)
この区別は重要です。需要があっても実行で失敗するケースをAIは検出できません。
スピアマン相関が低い理由
ピアソン(r=0.637)に対してスピアマン(ρ=0.373)が低い理由は、中間層での順位逆転が多いためです。
「成功(4)」と「中程度(3)」の境界にあるサービスは、AIの評価が入れ替わりやすい。トップとボトムの区別は得意ですが、中間の順位付けは不正確です。
6. 学術的な位置付け
本検証の理論的基盤:
| 研究 | 概要 | 本検証との関係 |
|---|---|---|
| Park et al. (2023) Stanford | Generative Agents: LLMに記憶・計画・反省を付与 | ペルソナの記憶・判断ロジック設計の基盤 |
| Argyle et al. (2023) MIT | LLMが特定属性下で世論調査と類似の回答を生成可能 | AIによる消費者調査の妥当性の根拠 |
| Kahneman (2011) | System 1/2理論 | ペルソナの直感的判断と分析的判断の設計 |
Argyleらの研究では「LLMが人口統計学的属性を条件づけた場合、実際の世論調査と統計的に類似した回答を生成できる」ことが示されています。本検証のr=0.637はこの知見と整合する結果です。
7. 実装のポイント
プロンプト設計
PERSONA_THINKING_PROMPT = """You are acting as the following persona.
Think and respond ONLY as this person would, based on their values,
beliefs, and decision-making patterns.
[Persona Profile]
Name: {name}
Age: {age}
Beliefs: {beliefs}
Decision Logic (in order of priority): {decision_logic}
Past Experiences: {memory}
[Business Idea]
Business Name: {business_name}
Description: {business_description}
Price: {price}
Respond in JSON format:
{{"interest_level": "High/Medium/Low", "decision": "Yes/No", "reason": "..."}}
"""
ポイント:
- 信念(Beliefs)を明示的に含める — 「新しいものは試す」「実績がないものは避ける」等
- 判断ロジックの優先順位 — どの基準を先に適用するかを指定
- 過去の経験 — 「○○で失敗した」等の経験がバイアスとして機能
-
JSON出力を強制 —
response_mime_type: "application/json"でパースエラーを防止
並行処理
async def run_simulation(self, personas, idea):
semaphore = asyncio.Semaphore(15) # 同時15並行
async def limited_simulate(persona):
async with semaphore:
return await self.simulate_persona(persona, idea)
tasks = [limited_simulate(p) for p in personas]
return await asyncio.gather(*tasks)
30人を15並行で処理し、約60秒で全評価が完了します。
8. 限界と今後の改善
現在の限界
| 限界 | 影響 | 改善方針 |
|---|---|---|
| 失敗検出力33% | 「売れるか」は予測できるが「成功するか」は不十分 | 競合分析・タイミング要素の追加 |
| 中間層の順位精度 | スコア3-4の区別が曖昧 | ペルソナ数を100人に拡張 |
| 30人の代表性 | 特定属性が不足 | 業界特化ペルソナパックの追加 |
| Ground Truthの主観性 | 評価者バイアス | 売上データによる客観化 |
改善の方向性
- ペルソナ数拡張(30→100人)でスピアマン相関の改善を目指す
- 競合ペルソナの追加:「既にメルカリを使っている人」等の条件付き評価
- 実際のユーザー調査との比較:同じサービスを人間パネルとAIパネルで評価し、差分を分析
- 時系列評価:同じサービスを異なる時期設定で評価し、市場タイミングの影響を検証
9. 結論
| 指標 | 結果 | 解釈 |
|---|---|---|
| ピアソン相関 | r = 0.637 | 中〜強の正の相関 |
| F1スコア | 0.818 | 良好な予測精度 |
| 再現率 | 90.0% | 成功サービスの検出は高精度 |
| 失敗検出率 | 33% | 実行失敗の検出は不十分 |
AI人格評価は「需要のポテンシャル」の指標として統計的に有意な妥当性を持つ。 ただし、実行力・戦略・市場タイミングの評価はできないため、従来の市場調査を代替するものではなく補完するものとして位置付けるのが適切です。
サービスURL
無料プランで月3回まで利用可能です。本記事で検証した1,001社の評価データも全て公開しています。
https://persona.microforge.works/cases/all
https://persona.microforge.works/whitepaper
参考文献
- Park, J.S., et al. (2023). "Generative Agents: Interactive Simulacra of Human Behavior." Proceedings of UIST '23. Stanford University.
- Argyle, L.P., et al. (2023). "Out of One, Many: Using Language Models to Simulate Human Samples." Political Analysis, 31(3). MIT.
- Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2nd ed.). Lawrence Erlbaum Associates.
- Kahneman, D. (2011). Thinking, Fast and Slow. Farrar, Straus and Giroux.