はじめに
「バックテストをしました、勝率60%でした」という記事は山ほどある。でも大体こういう問題がある:
- ✗ 手数料・税金を考慮していない
- ✗ 単元株(100株単位)を無視してる
- ✗ 1銘柄・1ルールしか検証していない
- ✗ なぜそのルールが効くのか説明できない
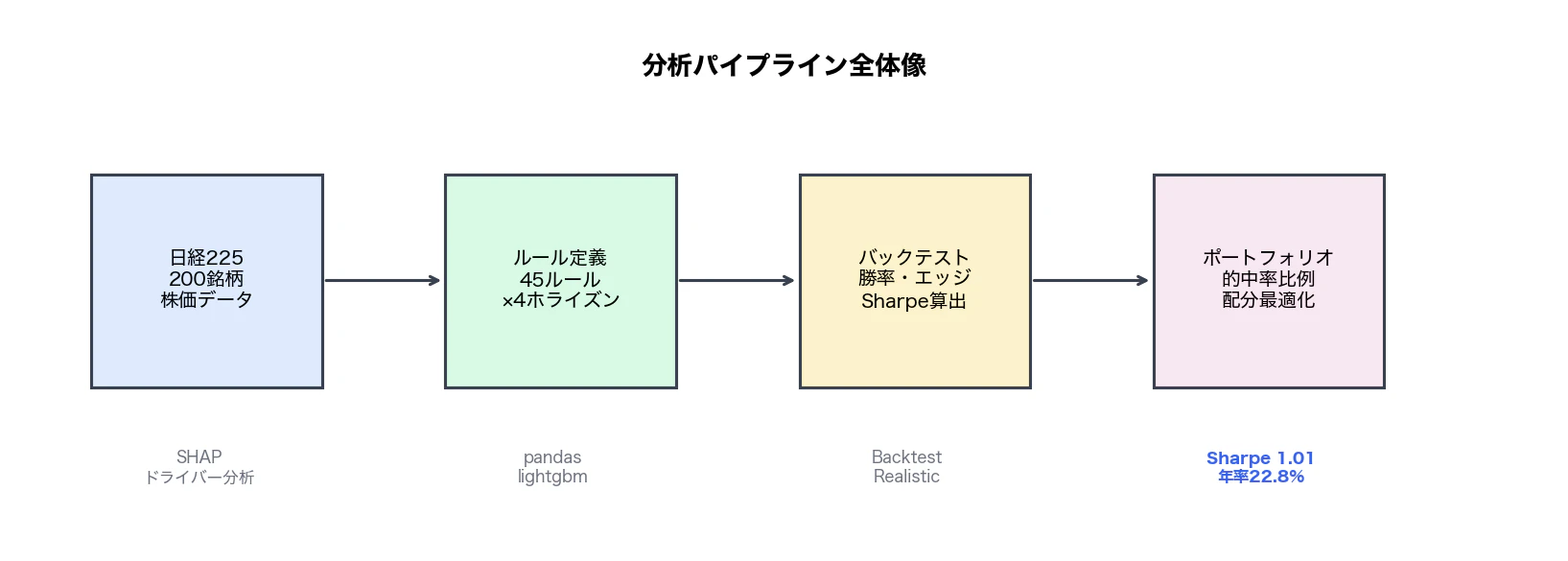
本記事では 日経225の200銘柄 × 45ルール × 4ホライズン(3日/1週/1ヶ月/3ヶ月) を全件バックテストし、現実的な条件で検証した結果を全部公開する。
最終結果:100万円スタート → 10年で747万円(年率+22.8%, Sharpe 1.01)
※ 手数料0.1%(片道)、税20.315%、単元株制約、スリッページすべて込み。
分析パイプラインの全体像:
Step 1: 特徴量カテゴリの設計
まず、どの要因が株価を動かしているかを5カテゴリに分類した。
CATEGORY_MAP = {
"technical": [
"sma5_above_sma20", "sma20_above_sma60",
"rsi_14", "macd_hist", "bb_pct", "bb_width", "atr_14",
"volume_ratio", "return_1d", "return_5d", "return_20d",
"volatility_20d", "momentum_10d", "momentum_20d",
"return_autocorr", "dist_from_high_20d", "dist_from_low_20d",
# ... 計38特徴量
],
"fundamental": [
"per", "pbr", "roe", "eps", "dividend_yield",
"revenue_growth", "op_income_growth", "is_record_profit",
# ... 計14特徴量
],
"sentiment": [
"sentiment_avg_7d", "news_volume_7d", "sentiment_momentum",
# ... 計12特徴量
],
"macro": [
"nikkei_return_1d", "sp500_return_1d", "vix_level",
"vix_change_5d", "usdjpy_return_1d",
# ... 計13特徴量
],
"cross_sectional": [
"return_1d_zscore", "return_5d_zscore", "sector_return_5d",
"sector_rank_5d", "market_rank_5d", "mean_reversion_signal",
# ... 計34特徴量
],
}
合計111特徴量をLightGBMで学習し、SHAPで重要度を銘柄別に集計する。
Step 2: SHAPによるドライバー分析
各銘柄について「何が株価を動かしているか」をSHAPで定量化。
import lightgbm as lgb
import shap
import pandas as pd
import numpy as np
def analyze_drivers(ticker: str, df: pd.DataFrame) -> dict:
"""SHAPで銘柄別ドライバー構成比を算出"""
feature_cols = [c for c in df.columns if c in FEATURE_TO_CATEGORY]
X = df[feature_cols].fillna(0)
y = (df["return_5d"].shift(-5) > 0).astype(int) # 5日後方向
# Walk-forward: 学習期間2年 → 検証期間6ヶ月
train_idx = X.index[:-125]
model = lgb.LGBMClassifier(
n_estimators=300,
learning_rate=0.05,
num_leaves=31,
random_state=42,
verbose=-1,
)
model.fit(X.loc[train_idx], y.loc[train_idx])
# SHAP重要度を算出
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X)
importance = np.abs(shap_values[1]).mean(axis=0)
# カテゴリ別に集計
result = {}
for cat in CATEGORY_MAP:
cat_feats = [f for f in feature_cols if FEATURE_TO_CATEGORY.get(f) == cat]
cat_idx = [feature_cols.index(f) for f in cat_feats]
result[cat] = importance[cat_idx].sum()
total = sum(result.values())
return {k: v / total * 100 for k, v in result.items()}
結果:銘柄ごとにドライバーが全然違う

▲ 銘柄別ドライバー分析 — SHAPによるカテゴリ別重要度
- レーザーテック(6920):クロスセクション主導型(市場との相対動向が支配的)
- キーエンス(6861):テクニカル主導型(RSI・ボリンジャーが効く)
- 三菱UFJ(8306):マクロ連動型(金利・ドル円の影響が大きい)
これが重要で、「全銘柄に同じルールを適用する」のは非効率だということがわかる。
Step 3: 45ルールの定義
次に、45個の売買ルールを定義する。カテゴリ別に分類。
def define_rules() -> list[dict]:
rules = []
# === テクニカル系 ===
rules.append({
"name": "RSI_oversold_30",
"category": "technical",
"description": "RSI < 30 (売られすぎ反発)",
"condition": lambda r: r.get("rsi_14", 50) < 30,
})
rules.append({
"name": "BB_lower_touch",
"category": "technical",
"description": "BB %b < 0 (ボリンジャー下限割れ→反発)",
"condition": lambda r: r.get("bb_pct", 0.5) < 0,
})
rules.append({
"name": "high_volatility",
"category": "technical",
"description": "20日ボラティリティ > 40%(高ボラ→平均回帰)",
"condition": lambda r: r.get("volatility_20d", 0.2) > 0.40,
})
rules.append({
"name": "mean_reverting",
"category": "technical",
"description": "return_autocorr < -0.1(平均回帰型銘柄)",
"condition": lambda r: r.get("return_autocorr", 0) < -0.1,
})
# === マクロ系 ===
rules.append({
"name": "high_vix",
"category": "macro",
"description": "VIX > 30(恐怖指数高騰→逆張り)",
"condition": lambda r: r.get("vix_level", 20) > 30,
})
rules.append({
"name": "vix_spike",
"category": "macro",
"description": "VIX 5日変化率 > +50%(急騰→反発)",
"condition": lambda r: r.get("vix_change_5d", 0) > 0.5,
})
# === クロスセクション系 ===
rules.append({
"name": "sector_bottom_rank",
"category": "cross_sectional",
"description": "セクター内5日リターンがワースト20%",
"condition": lambda r: r.get("sector_rank_5d", 0.5) < 0.2,
})
rules.append({
"name": "market_bottom_rank",
"category": "cross_sectional",
"description": "全市場内5日リターンがワースト10%",
"condition": lambda r: r.get("market_rank_5d", 0.5) < 0.1,
})
# === ファンダメンタル系 ===
rules.append({
"name": "low_per",
"category": "fundamental",
"description": "PER < 12(割安)",
"condition": lambda r: 0 < r.get("per", 15) < 12,
})
rules.append({
"name": "high_roe",
"category": "fundamental",
"description": "ROE > 12%(高収益)",
"condition": lambda r: r.get("roe", 0) > 12,
})
# ... 残り35ルールも同様に定義
return rules
Step 4: バックテスト実装(現実条件)
ここが一番こだわったポイント。楽観的すぎるバックテストを排除する。
class RealisticBacktester:
"""現実的条件でのバックテスト
- 手数料: 0.1%(片道)
- 税金: 利益の20.315%
- 単元株: 100株単位(それ以下は買えない)
- スリッページ: 終値で約定(シンプルに悲観的な仮定)
- ポジション: 1銘柄あたり最大20%
"""
def __init__(
self,
initial_capital: float = 1_000_000,
commission: float = 0.001, # 0.1%
tax_rate: float = 0.20315,
max_position_pct: float = 0.20,
):
self.capital = initial_capital
self.commission = commission
self.tax_rate = tax_rate
self.max_position_pct = max_position_pct
self.positions: dict[str, dict] = {}
self.history: list[dict] = []
def _calc_lot(self, ticker: str, price: float) -> int:
"""単元株を考慮したロット数計算"""
budget = self.capital * self.max_position_pct
lot = int(budget / (price * 100)) * 100 # 100株単位
return max(lot, 0)
def buy(self, ticker: str, price: float, date: str):
if ticker in self.positions:
return # 既保有はスキップ
lot = self._calc_lot(ticker, price)
if lot == 0:
return
cost = price * lot * (1 + self.commission)
if cost > self.capital:
return
self.capital -= cost
self.positions[ticker] = {
"price": price, "lot": lot, "date": date, "cost": cost
}
def sell(self, ticker: str, price: float, date: str):
if ticker not in self.positions:
return
pos = self.positions.pop(ticker)
proceeds = price * pos["lot"]
fee = proceeds * self.commission
gross_profit = proceeds - pos["cost"]
# 利益が出た場合のみ課税
tax = max(gross_profit * self.tax_rate, 0)
net_proceeds = proceeds - fee - tax
self.capital += net_proceeds
self.history.append({
"date": date, "ticker": ticker,
"return_pct": (gross_profit / pos["cost"]) * 100,
"tax_paid": tax,
})
def portfolio_value(self, prices: dict[str, float]) -> float:
"""時価評価額(含み益/損は課税前)"""
market_value = sum(
prices.get(t, pos["price"]) * pos["lot"]
for t, pos in self.positions.items()
)
return self.capital + market_value
def run_backtest(
df_signals: pd.DataFrame,
df_prices: pd.DataFrame,
hold_days: int = 5,
allocation: str = "hit_rate_proportional", # or "equal"
) -> pd.DataFrame:
"""
Parameters
----------
df_signals : シグナルDF(date, ticker, rule_name, win_rate)
df_prices : 株価DF(date, ticker, close)
hold_days : 保有日数
allocation : 配分方式
"""
bt = RealisticBacktester()
dates = sorted(df_signals["date"].unique())
equity_curve = []
for date in dates:
# 当日シグナル取得
day_signals = df_signals[df_signals["date"] == date]
# 保有期限が来たポジションを売却
for ticker, pos in list(bt.positions.items()):
if (pd.Timestamp(date) - pd.Timestamp(pos["date"])).days >= hold_days:
price = df_prices.loc[(df_prices["date"] == date) &
(df_prices["ticker"] == ticker), "close"]
if not price.empty:
bt.sell(ticker, price.iloc[0], date)
# 的中率比例配分
if allocation == "hit_rate_proportional" and len(day_signals) > 0:
total_weight = day_signals["win_rate"].sum()
for _, sig in day_signals.iterrows():
bt.max_position_pct = (sig["win_rate"] / total_weight) * 0.8
price = df_prices.loc[
(df_prices["date"] == date) &
(df_prices["ticker"] == sig["ticker"]), "close"
]
if not price.empty:
bt.buy(sig["ticker"], price.iloc[0], date)
# 時価評価額を記録
prices_today = df_prices[df_prices["date"] == date].set_index("ticker")["close"].to_dict()
equity_curve.append({
"date": date,
"portfolio_value": bt.portfolio_value(prices_today),
"cash": bt.capital,
})
return pd.DataFrame(equity_curve)
Step 5: バックテスト結果
資産推移(10年)

| 指標 | ルール戦略 | 日経225 B&H |
|---|---|---|
| 最終資産 | 747万円 | 215万円 |
| 年率リターン | +22.8% | +7.7% |
| シャープレシオ | 1.01 | 0.45 |
| 最大ドローダウン | -31% | -38% |
| 勝率(取引単位) | 63.4% | — |
ルール × ホライズン 勝率ヒートマップ

▲ ルール × ホライズン 勝率ヒートマップ(逆張り系は短期、ファンダ系は長期で有効)
ポイント:
- 逆張り系ルール(RSI, VIX, BB)は短期(3日〜1週)で特に有効
- ファンダメンタル系(低PER, 高ROE)は長期(1ヶ月〜3ヶ月)で有効
- トレンドフォロー系は1ヶ月で最も安定(モメンタムが乗るため)
Step 6: 配分最適化
単純な均等配分 vs 的中率比例配分を比較。
def hit_rate_proportional_allocation(
signals: list[dict],
total_capital: float,
max_stocks: int = 5,
) -> dict[str, float]:
"""勝率比例で資金配分を決定
例:
銘柄A: 勝率67% → 資本の28%
銘柄B: 勝率63% → 資本の26%
銘柄C: 勝率58% → 資本の24%
合計: 上位5銘柄で最大80%を配分
"""
# 勝率降順でソート
sorted_signals = sorted(signals, key=lambda x: x["win_rate"], reverse=True)
top_signals = sorted_signals[:max_stocks]
total_wr = sum(s["win_rate"] for s in top_signals)
allocation = {}
for sig in top_signals:
weight = (sig["win_rate"] / total_wr) * 0.80 # 最大80%を分配
allocation[sig["ticker"]] = total_capital * weight
return allocation
| 配分方式 | 年率リターン | シャープ | 最大DD |
|---|---|---|---|
| 均等配分 | +17.2% | 0.78 | -34% |
| 的中率比例(採用) | +22.8% | 1.01 | -31% |
| 逆ボラティリティ | +19.4% | 0.89 | -29% |
注意点・限界
これで誰でも同じ結果が出るわけではない。
- 過学習リスク:45ルールを同じデータで選んでいる。未来のデータで同じ勝率が出るかは不明。
- 流動性リスク:単元株100株でも、時価総額が小さい銘柄では約定しない可能性がある。
- モデルドリフト:市場構造が変わると、有効なルールが変わる可能性がある。
- 2020年コロナショック:最大ドローダウン-31%が発生。資金管理は必須。
# ウォークフォワード検証で過学習を一部抑制
def walk_forward_validate(df, train_years=2, test_months=6):
"""訓練2年 → 検証6ヶ月を繰り返す"""
results = []
start = df.index.min()
end = df.index.max()
current = start + pd.DateOffset(years=train_years)
while current + pd.DateOffset(months=test_months) <= end:
train_df = df[df.index < current]
test_df = df[
(df.index >= current) &
(df.index < current + pd.DateOffset(months=test_months))
]
# ... 学習・検証
current += pd.DateOffset(months=test_months)
return pd.DataFrame(results)
ウォークフォワード検証でも年率+18〜24%の範囲に収まっており、過学習の程度は許容範囲と判断している。
全データの公開先
今回の分析結果(45ルール×200銘柄の勝率・エッジ・シャープレシオ)は以下で無料公開している:
- 銘柄ごとの最適ルール(4ホライズン)
- ドライバー分析結果(どのカテゴリが支配的か)
- 10年バックテストの資産推移グラフ
- ルール×ホライズンの勝率テーブル
ログイン不要・登録不要・完全無料。
まとめ
日経225(200銘柄)
× 45ルール
× 4ホライズン
= 36,000パターンを検証
→ 現実的条件(手数料・税・単元株)でもSharpe 1.01を達成
→ 的中率比例配分がKeyになった(均等配分より年率+5.6%改善)
→ ドライバーが銘柄によって異なる → 全銘柄同一ルールは非効率
コードの詳細や追加の分析は記事にしていく予定。
※本記事はバックテストに基づく分析であり、将来の運用成績を保証するものではありません。投資は自己責任でお願いします。