はじめに
下記は、Googleのサッカーの試合詳細ページに出てくる勝敗予想です

バルサ強いよねってのは置いといて、試合の勝敗予想をAutoML (ML.NET)による多項分類で実現してみます
教師データを用意する
今回は、得失点期待率(~Average)と試合結果(Result)をCSVファイルで用意しました。
※期待値直近10試合(ホーム・アウェーを加味)の平均
※レコード数は約4000件
HomeGoalsForAverage,HomeGoalsAgainstAverage,AwayGoalsForAverage,AwayGoalsAgainstAverage,Result
0,0,0,0,D
2,0,0,2,W
0,2,2,0,L
0,1,1,0,L
1,1,1,1,D
1,1,1,1,D
4,2,2,4,W
1.5,1,1,2,W
1,0,1,0.5,W
<略>
トレーニングする
ML.NETツールをインストールします。
dotnet tool install --global mlnet-win-x64
分類(classification)のトレーニングを実行します。
mlnet classification --dataset result.csv --label-col Result --name MatchClassification --train-time 200
トレーニングが開始されるので、いっぷくいれます
Start Training
start multiclass classification
Evaluate Metric: MacroAccuracy
Available Trainers: LGBM,FASTFOREST,FASTTREE,LBFGS,SDCA
Training time in second: 200
Use train validate split with ratio: 0.1
| Trainer MacroAccuracy Duration |
|--------------------------------------------------------------------|
|0 FastTreeOva 0.5377 0.5700 |
|1 FastTreeOva 0.5361 0.1750 |
|2 FastTreeOva 0.5217 0.1790 |
|3 SdcaLogisticRegressionOva 0.3537 0.4790 |
<略>
|880 LbfgsLogisticRegressionOva 0.5341 0.0940 |
|881 SdcaLogisticRegressionOva 0.5146 0.1140 |
|882 SdcaLogisticRegressionOva 0.5007 0.1650 |
|883 LbfgsLogisticRegressionOva 0.5341 0.0440 |
[Source=AutoMLExperiment, Kind=Info] cancel training because cancellation token is invoked...
|--------------------------------------------------------------------|
| Experiment Results |
|--------------------------------------------------------------------|
| Summary |
|--------------------------------------------------------------------|
|ML Task: multiclass classification |
|Dataset: result.csv |
|Label : Result |
|Total experiment time : 199.0000 Secs |
|Total number of models explored: 885 |
|--------------------------------------------------------------------|
| Top 5 models explored |
|--------------------------------------------------------------------|
| Trainer MacroAccuracy Duration |
|--------------------------------------------------------------------|
|527 LightGbmMulti 0.5593 0.3120 |
|27 FastForestOva 0.5570 0.5190 |
|339 FastForestOva 0.5570 1.0630 |
|340 FastForestOva 0.5570 0.9780 |
|365 FastForestOva 0.5570 0.9440 |
|--------------------------------------------------------------------|
[Source=AutoMLExperiment, Kind=Info] cancel training because cancellation token is invoked...
save MatchClassification.mbconfig to C:\Users\kashin777\source\repos\ML\MatchClassification
場所に最適なパイプラインのためのコンソール プロジェクトを生成しています : C:\Users\kashin777\source\repos\ML\MatchClassification
トレーニングが完了しました
出力の内容から、今回一番良い結果を得られたのは
527回目に試行された「LightGbmMulti」で0.5593(約56%)の精度
となりました。
トレーニング結果のファイルを確認します。
*.mbconfig 学習の設計図(設定ファイル)
*mlnet 学習結果(完成品)
コンソールアプリのサンプルも出力されているので、実装時の参考にどうぞ
PS > dir
Directory: C:\Users\kashin777\source\repos\ML\MatchClassification
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 2026/03/29 20:18 5877 MatchClassification.consumption.cs
-a--- 2026/03/29 20:18 524 MatchClassification.csproj
-a--- 2026/03/29 20:18 2748 MatchClassification.evaluate.cs
-a--- 2026/03/29 20:18 10717 MatchClassification.mbconfig
-a--- 2026/03/29 20:18 69562 MatchClassification.mlnet
-a--- 2026/03/29 20:18 5964 MatchClassification.training.cs
-a--- 2026/03/29 20:18 1608 Program.cs
結果を利用して推論する
ML.NETの結果を利用するので、必要パッケージをインストールします
パッケージ追加
<PackageReference Include="Microsoft.Extensions.ML" Version="5.0.0" />
<PackageReference Include="Microsoft.ML" Version="5.0.0" />
<PackageReference Include="Microsoft.ML.FastTree" Version="5.0.0" />
<PackageReference Include="Microsoft.ML.LightGbm" Version="5.0.0" />
選ばれたトレーナーに応じて、FastTree / LightGbm 等が必要です
実装
サービスを実装
using MyApp.Model;
using Microsoft.Extensions.ML;
using Microsoft.ML;
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Linq;
namespace MyApp.ML.MatchPrediction;
public class MatchPredictionService(PredictionEnginePool<MatchPredictionInput, MatchPredictionOutput> pool)
{
private static IEnumerable<string>? labels = null;
// 勝敗予想を取得
public Model.MatchPrediction Predict(TeamResultBase HomeResult, TeamResultBase AwayResult)
{
labels ??= GetLabels(pool.GetPredictionEngine());
var raw = pool!.Predict(new MatchPredictionInput
{
HomeGoalsForAverage = (float)HomeResult.GoalsForAverage,
HomeGoalsAgainstAverage = (float)HomeResult.GoalsAgainstAverage,
AwayGoalsForAverage = (float)AwayResult.GoalsForAverage,
AwayGoalsAgainstAverage = (float)AwayResult.GoalsAgainstAverage
});
var result = GetScoreWithLabel(raw);
return new Model.MatchPrediction
{
Win = result["W"],
Draw = result["D"],
Lose = result["L"],
};
}
private Dictionary<string, float> GetScoreWithLabel(MatchPredictionOutput result)
{
var unlabeledScores = result.Score;
Dictionary<string, float> labledScores = [];
for (int i = 0; i < labels!.Count(); i++)
{
var labelName = labels!.ElementAt(i);
labledScores.Add(labelName.ToString(), unlabeledScores[i]);
}
return labledScores;
}
private static IEnumerable<string> GetLabels(PredictionEngine<MatchPredictionInput, MatchPredictionOutput> predictionEngine)
{
var schema = predictionEngine.OutputSchema;
var labelColumn = schema.GetColumnOrNull("Result");
if (labelColumn == null)
{
throw new Exception("Result column not found. Make sure the name searched for matches the name in the schema.");
}
var keyNames = new VBuffer<ReadOnlyMemory<char>>();
labelColumn.Value.GetKeyValues(ref keyNames);
return keyNames.DenseValues().Select(x => x.ToString());
}
}
public class MatchPredictionInput
{
[LoadColumn(0)]
[ColumnName(@"HomeGoalsForAverage")]
public float HomeGoalsForAverage { get; set; } = 0f;
[LoadColumn(1)]
[ColumnName(@"HomeGoalsAgainstAverage")]
public float HomeGoalsAgainstAverage { get; set; } = 0f;
[LoadColumn(2)]
[ColumnName(@"AwayGoalsForAverage")]
public float AwayGoalsForAverage { get; set; } = 0f;
[LoadColumn(3)]
[ColumnName(@"AwayGoalsAgainstAverage")]
public float AwayGoalsAgainstAverage { get; set; } = 0f;
[LoadColumn(4)]
[ColumnName(@"Result")]
public string? Result { get; set; }
}
public class MatchPredictionOutput
{
[ColumnName(@"PredictedLabel")]
public string PredictedLabel { get; set; } = string.Empty;
[ColumnName(@"Score")]
public float[] Score { get; set; } = [];
}
DIコンテナへ登録
学習済みモデルをDIコンテナに登録します。
var modelFile = new FileInfo(Path.Combine(AppContext.BaseDirectory, "ML/MatchPrediction/MatchPrediction.mlnet"));
services.AddPredictionEnginePool<MatchPredictionInput, MatchPredictionOutput>().FromFile(modelFile.FullName);
services.AddTransient<MatchPredictionService>();
利用する
var predicator = App.AppHost.Services.GetRequiredService<MatchPredictionService>();
var matchPrediction = predicator.Predict(r.HomeResult, r.AwayResult);
結果
推論に使用する入力データとして、以下の3パターンを試してみました
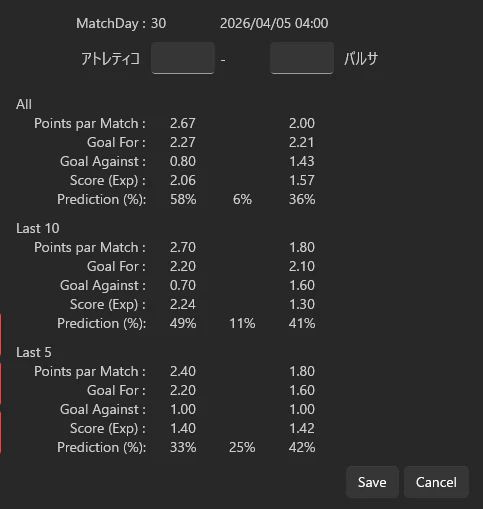
All(シーズン全体)
Last 10(直近10試合)
Last 5(直近5試合)
Last 5の結果が、Google先生に近い結果となりました
アトレティコ vs バルサ
マジョルカ vs レアル
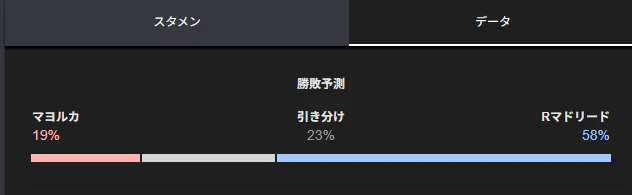

頑張れマジョルカ!
おわりに
精度56%の原因分析
ChatGPT先生によるアドバイス
みたい人だけどうぞ
今回のモデルは、MacroAccuracyが約56%という結果でした。
一見すると低く感じますが、この値にはいくつかの明確な理由があります。
① 特徴量がシンプルすぎる
今回使用した特徴量は以下の4つのみです。
- HomeGoalsForAverage
- HomeGoalsAgainstAverage
- AwayGoalsForAverage
- AwayGoalsAgainstAverage
これらはチームの平均的な強さを表す指標ではありますが、試合単位の結果を決定するには情報が不足しています。
サッカーの勝敗は以下のような要素にも大きく影響されます:
- 直近の調子(フォーム)
- ホーム/アウェイ差
- 対戦相性
- 怪我・出場停止
- 日程(疲労)
👉 「長期平均だけで短期の結果を当てようとしている」状態です。
② 引き分け(D)の予測が難しい
3クラス分類(W / D / L)において、最も難しいのが「引き分け」です。
理由:
- 発生確率が中間的(約20〜30%)
- ノイズに近く、偶然性が高い
- 特徴量との相関が弱い
その結果:
- W / L はそこそこ当たる
- D が外れやすい
→ 全体精度が低下する
👉 多クラス分類における典型的な難所です
③ クラス不均衡の影響
データの分布が例えば以下のような場合:
- W:45%
- D:25%
- L:30%
モデルは「当てやすいクラス(W)」に偏りやすくなります。
その結果:
- Wの予測が多くなる
- Dの再現率が低くなる
👉 MacroAccuracyを使用していても、完全には影響を避けられません
④ データ数がやや少ない
約4,000件は一見十分に見えますが、
- サッカーはばらつきが大きい
- 条件の組み合わせが多い(ホーム×相手×時期)
といった特性があります。
👉 実質的には「パターン不足」の状態です
特に以下のようなケースが不足しがちです:
- 強豪 vs 弱小
- 中位同士
- ダービーマッチ
⑤ 時系列を無視している
今回の学習はAutoMLによるランダム分割です。
しかし、実際の予測は
- 過去 → 未来
の流れで行われます。
ランダム分割では:
- 未来の情報が学習に混ざる可能性がある
- 実運用より高いスコアが出やすい(データリーク気味)
👉 それでも56%ということは、実運用ではさらに下がる可能性があります
⑥ 特徴量の「粒度」が粗い
例:
- シーズン平均(All)
- 直近5試合(Last5)
サッカーは「流れのスポーツ」であり、
- 直近の好不調
- 監督交代
- 戦術変更
などの影響を強く受けます。
👉 平均値だけでは、この変化を捉えることができません
💡 まとめ
今回の56%という精度は、
シンプルな特徴量で、ノイズの多い問題に挑んだ結果としては妥当
と言えます。
🚀 改善の優先順位
精度を上げるために、特に効果の高い改善案は以下の通りです。
-
直近データ(Last5 / Last10)を追加する
→ 最も効果が高い(+5〜10%も期待できる) -
ホーム/アウェイ成績を分離する
→ より実態に近づく -
順位・勝ち点差を特徴量に追加する
→ チーム力の相対比較が可能になる -
引き分け対策(2値分類の検討)
→ 勝ち / 非勝ち など -
データ数を増やす(複数リーグ・複数シーズン)
👍 一言でまとめると
👉 強いチームかどうかは分かる
👉 しかし「その試合で勝つか」は分からない