BigQueryとは?
BigQueryとはGoogle Cloud Platform(GCP)で提供されるビッグデータプロダクトの一つです。もともとは Google社内で利用されていましたが外部ユーザー向けに利用できるようにしたサービスがBigQueryです。BigQueryの特徴は高速な処理で、120憶行の正規表現マッチ付き集計を数十秒で完了します。
今回はKB(キロバイト)程度の小さなデータではありますが、公開されているオープンデータをBigQueryに入れて集計をしていきます。
使用するオープンデータ
今回はkaggleのWorld Happiness Report(世界幸福度調査レポート)を使用します。 World Happiness Reportは、世界の幸福の状態に関する調査です。155カ国と地域を幸福度でランク付けしたものです。項目は幸福度に関わると考えられる以下の8つです。この項目は毎回見直され、更新されています。 そのため2019年と同じ項目なのは2018年のものだけです。今回は初回のため、その中で2019年だけを使用していきます。
| 項目(原語) | 項目(日本語) |
|---|---|
| Country or region | 国・領域 |
| Score | 幸福度 |
| GDP per capita | 一人当たりのGDP |
| Social support | ソーシャルサポート |
| Healthy life expectancy | 健康寿命 |
| Freedom to make life choices | 人生の選択をする自由 |
| Generosity | 寛大さ |
| Perceptions of corruption | 腐敗の認識 |

ダウンロードしたデータ
こちらがダウンロードしたデータになります。通常は前処理が必要となりますが今回はそのままBigQueryに入れても文字化けやエラーにはならないため、このまま入れます。 ダウンロードしてきたCSVデータの文字コードはShift-jisのため、 そのまま読み込むと文字化けが起きます。必ず文字コードはUTF-8に変換してからアップロードしましょう。 (BigQueryはUTF-8しか対応してないらしいです。) BigQueryにデータを入れる
これからダウンロードしたCSVデータを、BigQueryに入れていきます。自身が初心者のため、分かりやすいよう細かい手順を説明していきます。前提としてBigQueryにすでにアカウントを持っている状態から始めます。
1.Projectの作成
2.Datasetの作成
3.Tableの作成
という手順で進めていきます。
1.Projectの作成
「プロジェクトの選択」から右上の「新しいプロジェクト」を選択します。
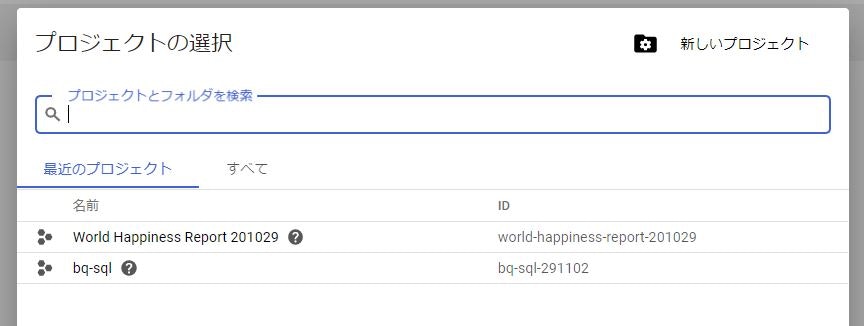
プロジェクト名を決め、「作成」ボタンを押してプロジェクト作成を行います。
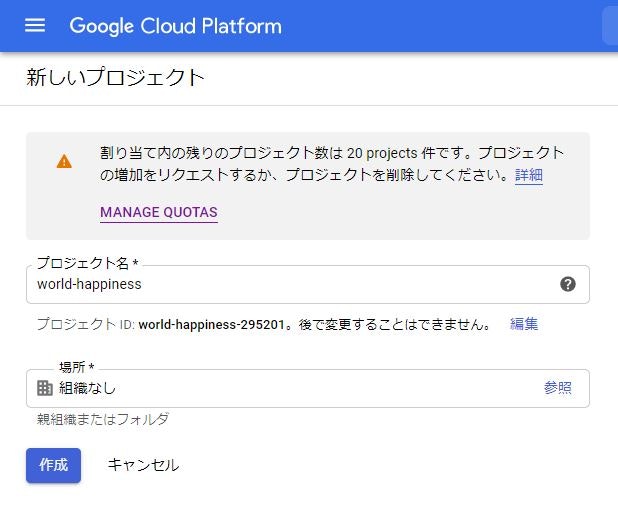
2.Datasetの作成
プロジェクトが作成出来たら、今度はデータセットを作成します。右下の「データセット作成」をクリックし、データセットを作成していきます。 データセットIDを記入し「データセットの作成」を行います。
データセットIDはSQLを打つときによく使用するのであまり複雑なものではないものをおすすめします。
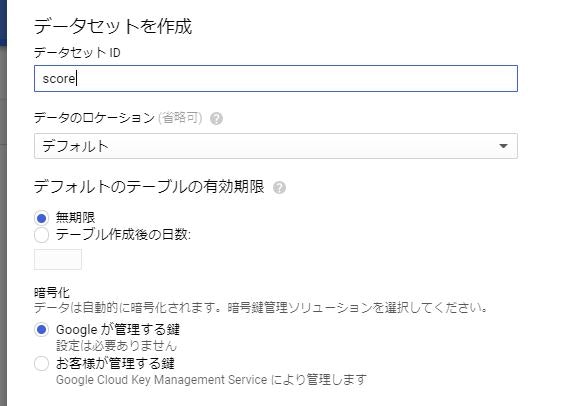
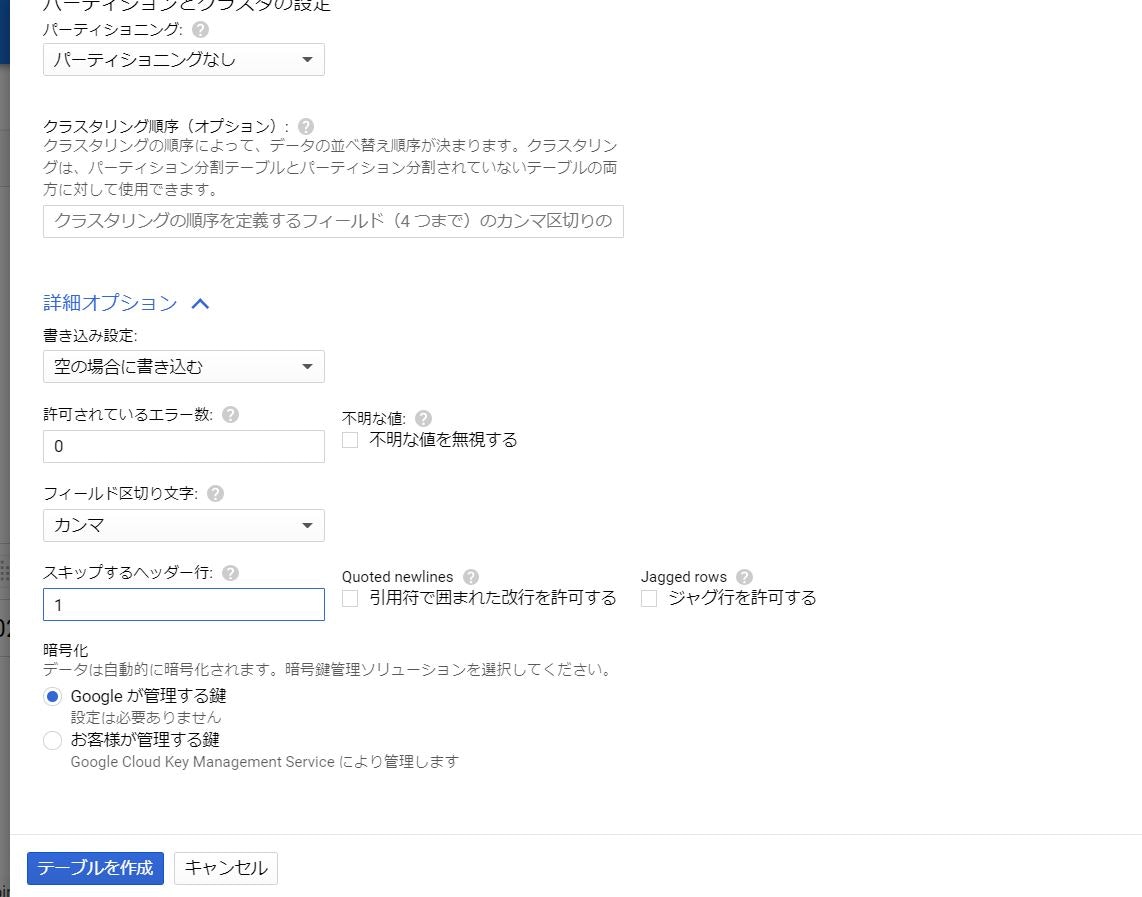
3.Tableの作成
1.ソース→アップロード→ファイル 先ほどデータセットからダウンロードしたファイルを選択します 2.テーブル名を記入 データセットIDと同じく自分でテーブル名を決定します。 3.「自動検出」にクリック 今回は自動検出でしたが、列名・データ型・モードを設定する必要がある場合はここで設定をします。設定が間違っている場合はのちのSQLでデータを呼び出す際にエラーが起こる場合があるので気を付けてください。4.詳細オプションで「スキップするヘッダー行」に「1」を記入
これは最初の一行目をデータとしてカウントしないという意味です。「Score」「GDP per capita」などは項目名のためその読み込みをしないという意味になります。
データにクエリを実行する
BiQueryにまで読み込みができたので、試しにクエリを実行してみます。 以下は、国(地域)別に幸福度数と一人当たりのGDPを抽出するクエリです。GDPが高い地域に絞って比較してみたかったので、GDPが1以上の国に絞っています(特に意図があるわけではありません)。select Country_or_region,Score,GDP_per_capita
from score.2019
where GDP_per_capita >1
order by Score desc;
結果はこんな感じです。
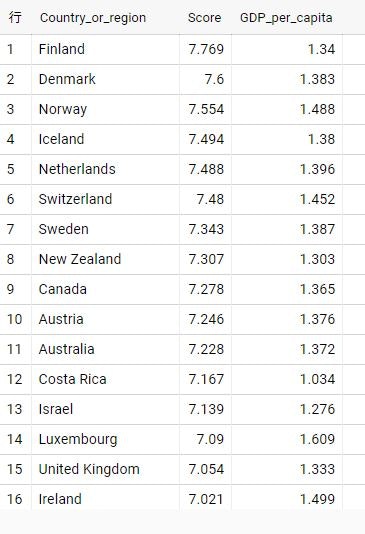
これだけだと相関関係までは何もわかりませんが、一人あたりのGDPが高い国のほうが幸福度も高いのではないかという仮説が出てきますね。
※他データなど見てるわけではないのでただの感想です。
BigQueryへのデータのインポートまとめ
今回はデータのBigQueryへのインポートと