始めに
業務でApache Kafkaを使用することになりましたが、最初は名前すら聞いたことがなく、どのような技術なのか全く分かりませんでした。
そこで、基本的な仕組みを勉強したので、学んだことを自分なりにまとめてみました。
この記事の対象者
- Apache Kafkaとはそもそも何か知りたい方
- Apache Kafkaの勉強を始めた方
この記事で伝えること
- Apache Kafkaとは何か
- Apache Kafkaの仕組み
- Apache Kafkaの特徴
Apache Kafkaとは?
Apache Kafkaとは、
「複数台のサーバーで大量のストリームデータを処理する分散メッセージングシステム」
のことです。
メッセージングシステムとは?
現在の世の中では、リアルタイムで大量のデータが生成され続けています。
これらは「ストリームデータ」と呼ばれており、様々な場所でリアルタイムに収集され、活用されています。
例えば、交通状況もストリームデータの一つであり、渋滞状況の把握などに使われています。
作られたデータは利用場所に送信する必要がありますが、
直接繋げようとすると、下記の図のようにかなり複雑な構成になり、開発・運用・管理が難しくなります。
また、リアルタイムに生成されるデータをそのままリアルタイムに送受信するということなので、その過程で不具合があるとデータロストなどを引き起こしてしまいます。
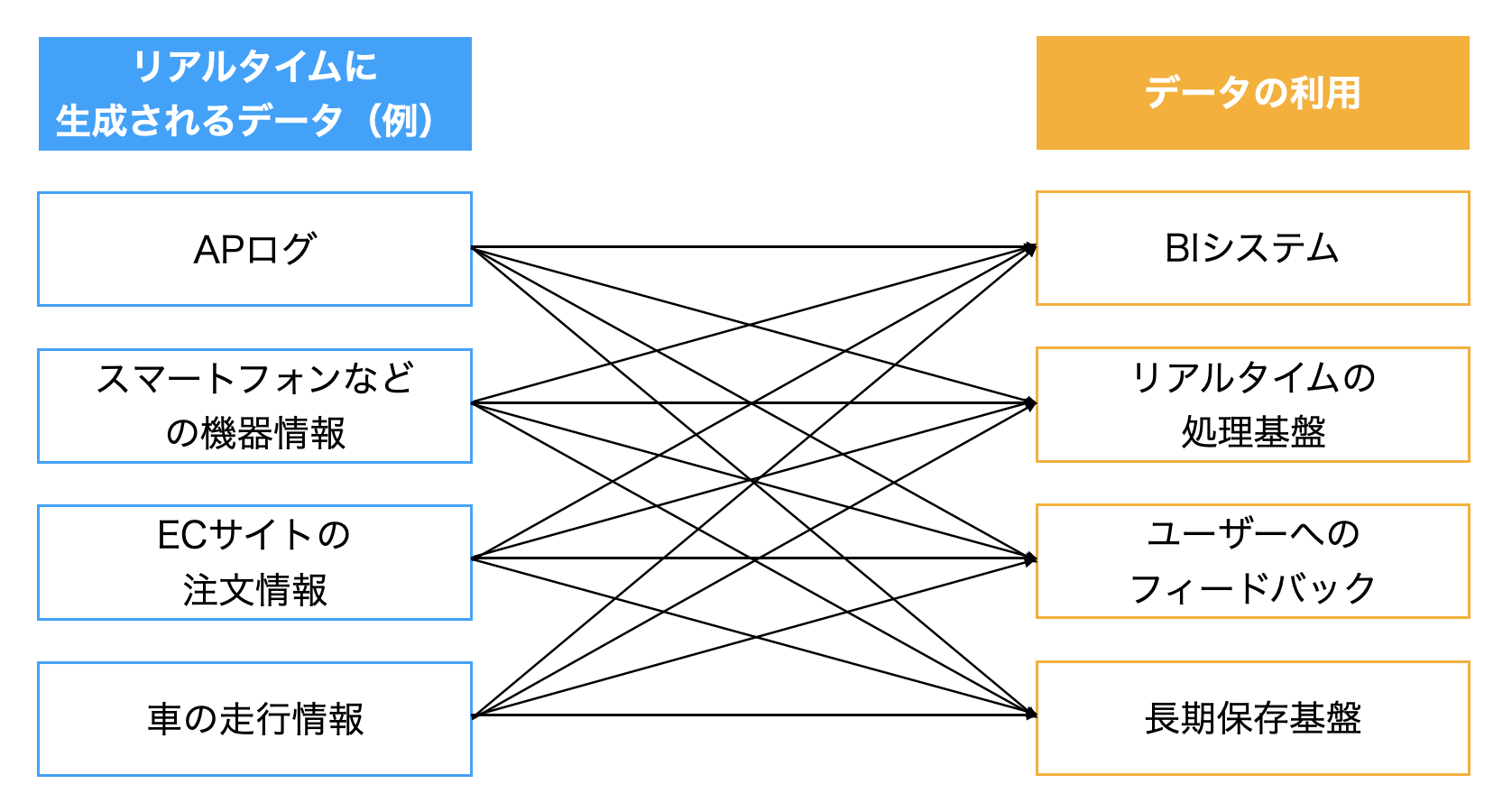
そこで、データ生成場所とデータ利用場所に 中継役 となるメッセージングシステムを配置します。
Apache Kafkaはこの中継役(メッセージングシステム)に当たるもの です。

メッセージングシステムを介することで、下記のようなメリットがあります。
-
構造がシンプルになる
データ生成場所・データ利用場所ともに接続先を一つにできるため、とてもシンプルな構成を実現することができる。 -
確実な送受信の機能を提供
メッセージングシステムの様々な機能により、データロストを引き起こさないシステムを構築することが可能になる。
Apache Kafkaの構成
以下がKafkaを構成する主要な要素になります。
-
Broker
データを送受信する中継役。 -
Message
Kafkaが送受信するデータの単位。 -
Producer
データの送信元。Brokerに対してMessageを送信する。 -
Consumer
データの送信先。BrokerからMessageを取得する。 -
Topic
Messageを種類ごとに保存する。Broker上で管理される。
ProducerとConsumerは 特定のTopicを指定してMessageの送信・受信 を行います。

Apache Kafkaの特徴
Kafkaには大きく分けて3つの特徴があります。
- 分散システム
- データの永続化
- メッセージの送達保証
分散システム
一つのサーバーでデータの受け取り・送信を処理すると、データ量が増えるにつれて負荷が上がります。
また、そのサーバーに障害が発生すると、受け取ったデータが失われたり、送信できなくなったりするリスクがあります。
これを防ぐために、Kafkaでは複数のサーバーに処理を分散し、安定したデータのやり取りを実現しています。
先ほどBroker上ではメッセージを種類ごとにTopicで管理していると説明しましたが、Topicはさらに以下の要素で構成されています。
-
Partition
Topic内でデータを分割する単位。 -
Replica
Partitionの複製。つまりデータの複製のこと。
また、Replicaには二つの種類があります。
-
Leader Replica
メッセージの送受信を担当する主要なレプリカ。
Producerからメッセージを受け取り、Consumerに配信する役割を持つ。
各Partitionに必ず1つ存在する。 -
Follower Replica
Leader Replicaのデータをコピーし、同期を維持するレプリカ。
Leader Replicaに障害が発生した際、代わりに昇格し処理を継続する。
以下の図ように同じPartitionのLeader Replica・Follower Replicaを異なるBroker上に配置することで、 一つのメッセージの複製が複数のサーバーで管理される ようになります。
また、実際にデータのやり取りを行うPartitionは複数のサーバーに分散されるため、 サーバーそれぞれの役割も分散される ことになります。
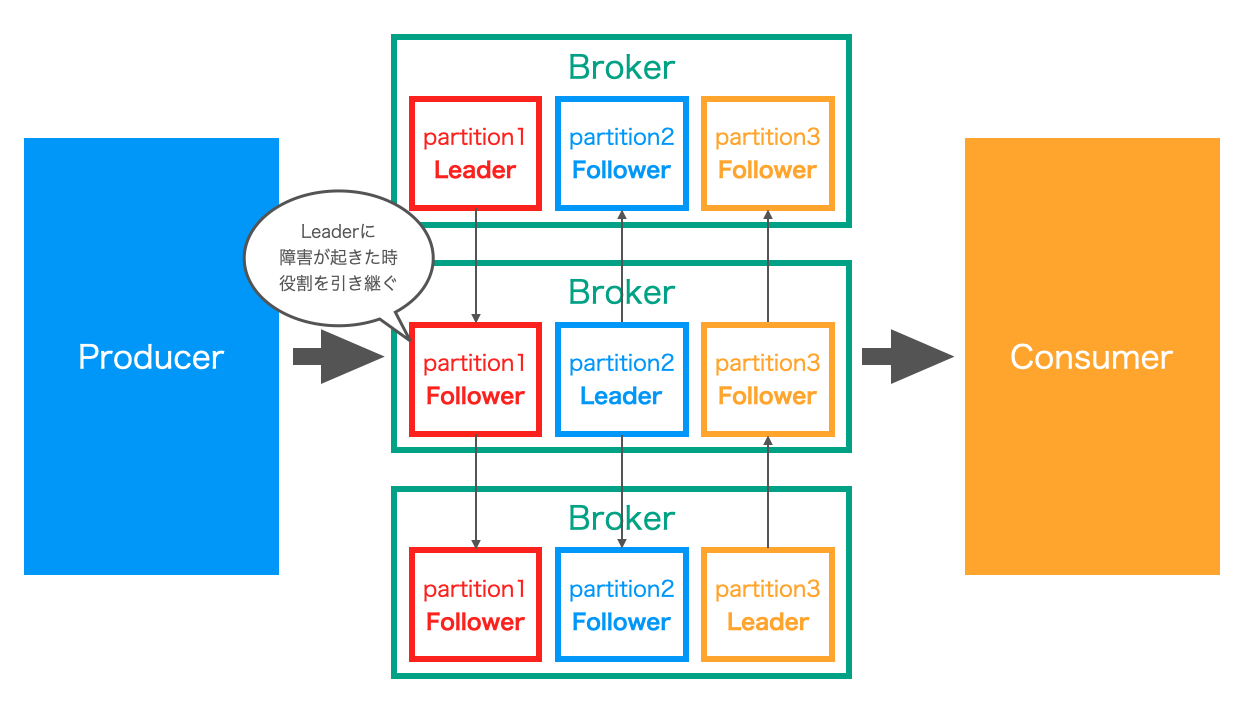
このような分散システムの実現によって、以下のようなメリットがあります。
-
スケールアウトが可能
サーバー(Broker)を増やしPartitionを再配置することで、Partitionの役割も均等になり、各Partitionの役割が少なくなります。サーバーの役割が分散されるため、性能も上がります。 -
障害発生時のデータロストを防ぐ
別のBrokerにデータの複製があるため、あるBrokerに障害が発生してもデータは失われません。
また、Leaderが配置されているBrokerで障害が発生しても、 別のBrokerに配置されているFollowerがすぐにLeaderとしての役割を引き継ぐ ため、データの受信・送信を問題なく続けることができます。
データの永続化
Kafkaでは、BrokerがProducerからメッセージを受け取るとディスク上に保存を行います。
これにより、 Consumerは任意のタイミングでメッセージを取り出すことができる ようになります。
Brokerが能動的に送るのではなく、Consumerからのリクエストに応答して受動的にデータを送る仕組みにより、以下のメリットがあります。
-
バッチ処理を実現できる
Consumerが任意のタイミングでデータを受信するという仕組みを活用し、Broker上に複数のメッセージを溜めておき、一括で受信することで、バッチ処理を実現することも可能です。
データを順次処理するストリーム処理とデータをまとめて処理するバッチ処理両方を実装できるため、柔軟にデータを利用することができます。 -
Consumerが故障した際のBrokerへの影響が少ない
Consumerからのリクエストが無ければBrokerはデータを送信しません。そのため、Consumerが故障してもBrokerのデータ送信を停止するといった対応が不要になります。
メッセージの送達保証
Kafkaには、Messageが正しく送受信されたことを確認する機能や、失敗した時のリトライ機能が備わっています。
送達保証には一般的に以下3つのレベルがあります。
| 送達保証方式 | 説明 | 再送 有無 |
重複の可能性 有無 |
備考 |
|---|---|---|---|---|
| At Most Once | 1 回は送信を試みる | 無 | 有 | メッセージは重複しないがロストする可能性がある |
| At Least Once | 少なくとも 1 回は送達する | 無 | 有 | ロストはしないが重複する可能性はある |
| Exactly Once | 1 回だけ送達する | 無 | 無 | ロストもしないし、確実に1回メッセージを送達できる |
Kafkaでは送達保証方式をこの3つから選択し設定することが可能ですが、当初Kafkaは
At Least Once を実現する製品としてリリースされました。
At Least Onceを実現するための概念として、AckとOffset Commitがあります。
-
Ack
Brokerがメッセージを受け取った際に、Producerに対して受け取ったことを返答すること。ProducerがAckを受け取らなかった場合、再送するべきだと判断することができる。 -
Offset Commit
ConsumerがBrokerからどこまでメッセージを受け取り、Consumer側の処理が完了したかを知らせること。

オフセットという言葉にもあるように、BrokerとConsumerのやり取りでは、「どこまで送信したか」「どこまでの処理が完了したか」 という位置情報を管理しています。
まとめ
Kafkaとは?
複数台のサーバーで大量のストリームデータを処理する分散メッセージングシステムのこと
メッセージングシステムとは?
データ生成場所からデータを受け取り、データ利用場所へデータを送信する役割を担う中継役のこと。
Kafkaの特徴は?
- 分散システム
- データの永続化
- メッセージの送達保証
最後に
Apache Kafkaについて、概要を簡単にまとめてみました。
まだまだ理解できていない部分や学習できていない部分があるので、引き続き勉強していきたいと思います!