この記事は?
ここではOSSの分散メッセージングシステムであるApache Kafkaについて調べまとめます。具体的には以下のようなことについてまとめます。
- Apache Kafkaの概要
- Kafkaのアーキテクチャ
Apache Kafka の概要
Apache Kafka(以降、Kafka)はLinkedInによって開発された分散メッセージングシステムです。もともとは高スループットでリアルタイムにデータを扱うことを目的とし開発されました。

Kafkaではこれまでのメッセージキュー、ログコレクター、ETLツールなどでは対応しきれない要件に対応するために生まれました。Kafkaには以下のような特徴があります。
- 分散システム
- リアルタイムなデータ処理
- 任意なタイミングでのデータ取り出しも可能
- At Least Oneの到達保証
分散システム
Kafkaは分散システムです。求められるビジネス要件に対してシステムを事前にスケールアウトさせておくことが可能です。
またデータのレプリケーションを行うことで耐障害性も担保しています。
リアルタイムなデータ処理
Kafkaではデータの収集から数百ミリ秒から数秒の間でデータが処理されることが想定されます。分散システムであることにより高スループットを実現しています。また、KafkaはExactly Onceの到達保証を行わない選択をしスループットを優先した開発が行われています。
任意なタイミングでのデータ取り出し
Kafkaはバッチ処理などに対応できるようにデータをディスクにします。それにより比較的大量のデータを保持することが可能です。
ちなみにKafkaではデータの古いものから削除されますデータ保存マニフェストはデータの保存期間(デフォルト一週間)とデータ容量(デフォルト無制限)の2つが設定できます。
そのほかにも、同一のキーで最新のデータのみを保持したいなどの要件に対して、といったようなコンパクションもサポートしています。
At Least Onceの到達保証
KafkaではAt Least One(最低、一回、複数回到達する可能性あり)の到達保証をサポートします。詳細は後程記述しますがシステムがメッセージの到達管理を行います。
Kafkaの要件と他ツールとの比較
Kafkaは以下のようなことを解決することを目指して作成されています。
- リアルタイムでのメッセージのやり取り
- スケールアウト可能な構成
- 永続化可能
- 最低一回の送信保証
こういった要件をすべて満たすツールがそれまで利用されていたツールにはなくそのためにKafkaは開発されました。
| Kafkaの対応する要件 | メッセージキュー | ログコレクター | ETLツール |
|---|---|---|---|
| リアルタイム | 〇 | 〇 | × |
| スケールアウト可能 | × | 〇 | 〇 |
| 永続化 | △(長期保存ができない) | × | × |
| 送信保証 | 〇(ツールによっては強力すぎる) | △(トランザクション機能がない) | 〇 |
Kafkaのアーキテクチャ
Producer、Broker、Consumer
Kafkaでは大きく以下のようなシステム構成をとります。

ProducerとBroker、Consumerはそれぞれが分散してシステムを組むことが可能となっています。
また、BrokerのノードディスカバリにはApache ZooKeeperがつかわれるようです。
Producer、Broker、Consumerのそれぞれの説明を以降にまとめます。
Producer
データの送信元Messageをブローカーへ送信するアプリケーションです。
Producerはライブラリとして提供されたProducer APIをKafkaを利用する開発者側で利用して作成します。
そのほかにもProducerの機能をプラグインとして提供するOSSも存在します。
ProducerはPush型です。
Blocker
データを受信配信する役割を持つサービスです。1つのデーモンプロセスとして動作し受信と配信のリクエストを受け付けます。取得したデータはすべてディスクへの永続化を行います。
Consumer
BrokerからMessageを取得するアプリケーションです。Producerと同じくライブラリとして提供されるConsumer APIを利用し、
ConsumerはPull型として動作し、Consumer側のタイミングでMessageを取得することができます。
データの単位、メッセージの送受信
Kafkaではデータの最小単位をMessageと呼びます。メッセージはKeyとValueを持っています。
Messageの種別ごとにTopicと呼ばれるストレージがBlocker内で用意されており、ProducerやConsumerはTopicを指定してメッセージの送受信を行います。

パーティショニング
1つのTopicに対する大量の入出力に対応するためにBlockerはデータをパーティションと呼ばれる単位で分割してデータを扱います。パーティションはBlockerクラスタ内で分散して配置されます。ProducerからMessageを受け取る際にはKeyのハッシュを用いたパーティショニングとラウンドロビンによるパーティショニングが存在します。
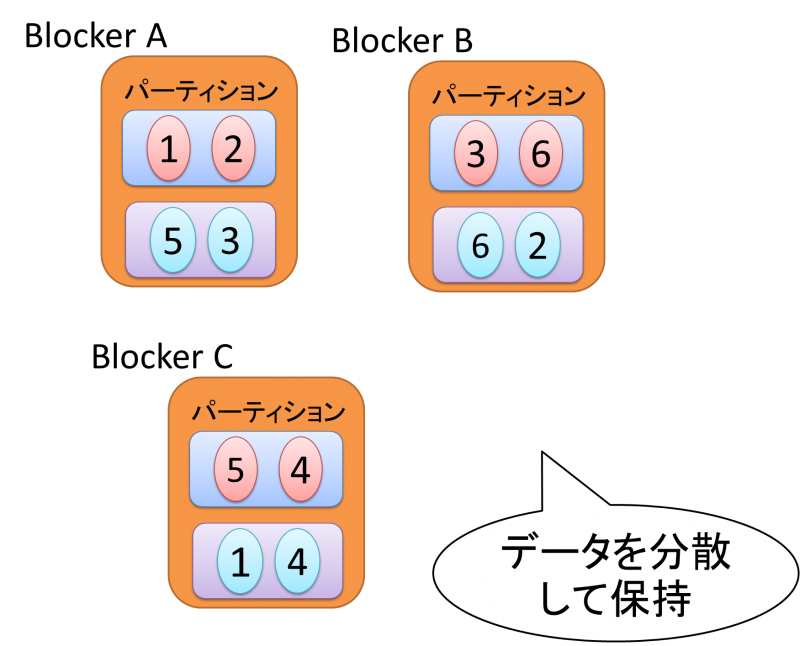
Keyのハッシュを用いる場合は同一Keyを同一のConsumerから取得することが可能といった制御ができるがパーティションで保持するデータの偏りに注意する必要があります。
レプリケーション
Kafkaはサーバの故障などに備えデータをレプリケーションしています。

レプリケーションはパーティションごとに行われ、それぞれ別のBlockerで管理されます。レプリカのうち1つはLeaderと呼び、他のレプリカをFollowerと呼びます。データの読み書きはLeaderから行われます。
Producerのメッセージの送信について
Producerが送信対象のTopicにMessageを送る際にデフォルトでは1メッセージにつき一回の送信ですが、細かい単位でメッセージを送りすぎるとネットワークリソースの枯渇につながるのため、調整が必要です。
以下の二つをトリガーとすることも可能です。
- 指定したサイズまでメッセージが蓄積したらメッセージを送信する。
- 一定時間ごとにメッセージを送信する。
また、上記の通りメッセージ送信する際にはどパーティションに送信するかのパーティショニング機能が備わっています。
At Least Onceの実現のためにBlockerは正しく受信できたことを示すためAck(肯定応答)を行います。Ackを受け取れなかった場合ProducerはMessageの再送処理を行います。

Consumerのメッセージ受信について
Consumerのメッセージ受信ではConsumerがまずトランザクション開始リクエストを送ります。
その後Consumerは取得対象のTopicに対してCurrent Offsetと呼ばれるどこまで送信したか表す位置からMessage のBrokerの持つ最新のMessageまでまとめて配信リクエストを送ります。
ConsumerはからOffset Commit メッセージを送ります。
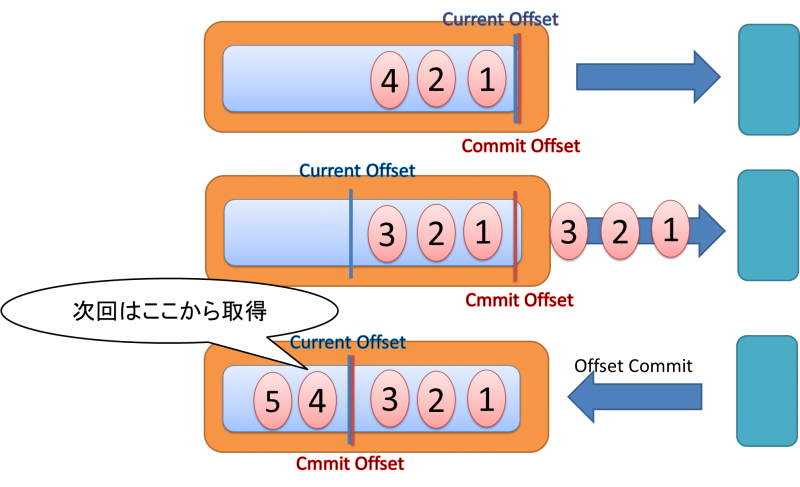
Blockerからメッセージ配信後、Consumer側で障害が発生した際にはCurrent Offsetは前回の位置まで戻ります。

Topicがレプリケーションされている場合は、最新のメッセージまではなくHighWatermarkと呼ばれるレプリケーションが完了Offsetを示す位置までConsumerはメッセージを取得可能です。
このようにすることよってAt Least Oneの到達保証を可能としています。
まとめ
Kafkaの概要とアーキテクチャについてまとめました。Kafkaは分散システムがあるゆえに少し複雑なアーキテクチャになっています。また多くのシステムにおいてはオーバースペック気味になることもあります。しかし、リアルタイムなデータハブを構築したいなどの要件に対して強いソフトウェアとなっています。