データベースの使い方をいつも忘れてしまうので備忘した。
1.ローカルでデータベース
(1)やりたいこと
・index.htmlにアクセスする度に、Text型の変数nameと、Integer型の変数count、Date型のtimestamp変数をデータベースに保存していく
・countはindex.htmlにアクセスする度に1ずつ加算していく
・timestampは保存した日時
(2)補足説明
①__init__.pyのファイルは中に何も書かずに作成
②index.htmlの中身は取り急ぎ”Hello world!”のみを表示するシンプルなもの
③pipでpostgresqlをインストール,sqliteのバージョンも確認
sqlite3 --version
pip install sqlalchemy
(3)作成したファイルを全て作成後、実行にあたり
①データベースの初期設定をする必要がある
ターミナルで以下のコマンドでpythonモードにする
python3
その後以下をターミナルに入力
>>>from assets.database import init_db
>>>init_db()
上記実行でassetsフォルダ内にdata.dbが作成される
②データベースに初期値を入れる
pythonモードのまま
>>>from assets.database import init_shoki
>>>init_shoki()
上記実行で、初期値が入った。これをやらないとmain.pyでデータ読み込み時に
値が入っていないデータベースを読み込むためエラーが出る
③main.pyを実行
/にアクセスする度に、データベースのテーブル"data"の、nameとcountが保存される(countは1ずつ加算)
(4)データベースを確認する
以下のコマンドでslite3モードにする
sqlite3 assets/data.db
①テーブルの情報
sqlite3モードで以下をターミナルに入力
>>>.table
data
②テーブルからレコードを取り出す
sqlite3モードのまま
>>>SELECT name FROM data;
初期設定としてデータベースの1個目の文字列だよ
1個目の文字列だよ
2個目の文字列だよ
3個目の文字列だよ
4個目の文字列だよ
5個目の文字列だよ
>>>sqlite> SELECT count FROM data;
0
1
2
3
4
5
(5)作成ファイル
test_sql
├main.py
├assets
│ ├__init__.py
│ ├data.db
│ ├database.py
│ └models.py
│
└templates
├index.html
# coding: utf-8
from flask import Flask,request,render_template
import datetime
# データベースを使うにあたり追加
from assets.database import db_session
from assets.models import Data
app = Flask(__name__)
@app.route('/')
def bbs():
#データベースを読み込む
data = db_session.query(Data.name,Data.count).all()
#データベースに書き込む、nameは文字列で、countはアクセスするたびに1ずつ加算する処理をする
#lenでdataの要素数を取得する
count_read = data[len(data)-1][1]
count_add = count_read + 1
row = Data(name="{}個目の文字列だよ".format(count_add),count=count_add,timestamp=datetime.datetime.today())
db_session.add(row)
db_session.commit()
#再度データベースを読み込む
data = db_session.query(Data.name,Data.count,Data.timestamp).all()
print("/にアクセスする度にデータベースdataに追加されていきます、dataの要素の全ては、",data,"です。")
print("dataの要素数は、",len(data),"です。")
print("dataの最後の要素は、",data[len(data)-1],"です。")
print("dataの最後の要素のcountの値は",data[len(data)-1][1],"です。")
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=False)
# coding: utf-8
# database.py/sqliteなど、どのデータベースを使うのか初期設定を扱うファイル
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session,sessionmaker
from sqlalchemy.ext.declarative import declarative_base
import datetime
import os
# data_dbという名前で、database.pyのある場所に(os.path.dirname(__file__))、絶対パスで(os.path.abspath)、data_dbを保存する
database_file = os.path.join(os.path.abspath(os.path.dirname(__file__)),'data.db')
# データベースsqliteを使って(engin)、database_fileに保存されているdata_dbを使う、またechoで実行の際にsqliteを出す(echo=True)
engine = create_engine('sqlite:///' + database_file,convert_unicode=True,echo=True)
db_session = scoped_session(
sessionmaker(
autocommit = False,
autoflush = False,
bind = engine
)
)
# declarative_baseのインスタンス生成する
Base = declarative_base()
Base.query = db_session.query_property()
# データベースの初期化をする関数
def init_db():
#assetsフォルダのmodelsをインポート
import assets.models
Base.metadata.create_all(bind=engine)
# データベースに初期値を入れる関数(name=初期設定として最初の文字列書くよ、count=0)
def init_shoki():
from assets.models import Data
# import assets.models
row = Data(name="初期設定としてデータベースの1個目の文字列だよ",count=0,timestamp=datetime.datetime.today())
db_session.add(row)
db_session.commit()
# coding: utf-8
from sqlalchemy import Column,Integer,String,Boolean,DateTime,Date,Text
from assets.database import Base
from datetime import datetime as dt
# データベースのテーブル情報
class Data(Base):
__tablename__ = "data"
id = Column(Integer,primary_key=True)
name = Column(Text,unique=False)
count = Column(Integer,unique=False)
timestamp = Column(DateTime,unique=False)
#初期化する
def __init__(self,name=None,count=0,timestamp=None):
self.name = name
self.count = count
self.timestamp = timestamp
<!doctype html>
<html lang="jp">
<head>
<!-- Required meta tags -->
<meta charset="utf-8">
<meta name="viewport" content="width=device-width,
initial-scale=1, shrink-to-fit=no">
<!-- Bootstrap CSS -->
<link rel="stylesheet" href="https://stackpath.bootstrapcdn.
com/bootstrap/4.5.2/css/bootstrap.min.css" integrity="sha38
4-JcKb8q3iqJ61gNV9KGb8thSsNjpSL0n8PARn9HuZOnIxN0hoP+VmmDGMN
5t9UJ0Z" crossorigin="anonymous">
<title>Hello, world!</title>
</head>
<body>
<h1>Hello, world!</h1>
</body>
2.Herokuでデータベース
(1)ローカルで作成したことをHeroku上でやる
pip install gunicorn
postgresqlをbrewを使ってインストールする。
brew install postgresql
次に postgresqlを使うためのpython用のドライバーとして、 psycopg2-binaryをインストールする。psycopg2をそのままインストールすると、なぜかエラーが出るため、psycopg2-binaryをインストール(原因不明)。
pip install psycopg2-binary
次にdatabase.pyを修正するが、environというHeroku上の環境変数を見に行ってDATABASE_URLというデータベースを取得する処理を記述する。environには接続先のURLがセットされる。また、orをつけることで、ローカル環境上はsqliteをデータベースとして参照することとした。herokuに接続されている場合はpostgresqlのurlを参照して、接続されていない場合はsqlを参照に行くという格好。具体的には以下の通り。
engine = create_engine(os.environ.get('DATABASE_URL') or 'sqlite:///' + database_file,convert
database.pyを修正する
# coding: utf-8
# database.py/sqliteなど、どのデータベースを使うのか初期設定を扱うファイル
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session,sessionmaker
from sqlalchemy.ext.declarative import declarative_base
import datetime
import os
# data_dbという名前で、database.pyのある場所に(os.path.dirname(__file__))、絶対パスで(os.path.abspath)、data_dbを保存する
database_file = os.path.join(os.path.abspath(os.path.dirname(__file__)),'data.db')
# データベースsqliteを使って(engin)、database_fileに保存されているdata_dbを使う、またechoで実行の際にsqliteを出す(echo=True)
# engine = create_engine('sqlite:///' + database_file,convert_unicode=True,echo=True)
engine = create_engine(os.environ.get('DATABASE_URL') or 'sqlite:///' + database_file,convert_unicode=True,echo=True)
db_session = scoped_session(
sessionmaker(
autocommit = False,
autoflush = False,
bind = engine
)
)
# declarative_baseのインスタンス生成する
Base = declarative_base()
Base.query = db_session.query_property()
# データベースの初期化をする関数
def init_db():
#assetsフォルダのmodelsをインポート
import assets.models
Base.metadata.create_all(bind=engine)
# データベースに初期値を入れる関数(name=初期設定として最初の文字列書くよ、count=0)
def init_shoki():
from assets.models import Data
# import assets.models
row = Data(name="初期設定としてデータベースの1個目の文字列だよ",count=0,timestamp=datetime.datetime.today())
db_session.add(row)
db_session.commit()
(2)Herokuへデプロイ
Heroku login
heroku create test-sql2
Herokuとローカル環境を紐つけて、
heroku git:remote -a test-sql2
requirements.txt作成
pip freeze > requirements.txt
Procfileを作成
ディレクトリapp内にProcfileを作成し、以下を入力。
この時、gの前はブランク一つ必要、また、:appの前のmainは、main.pyのappという意味なので注意が必要(form.pyなら、form:app)
web: gunicorn main:app --log-file -
addして
git add .
git commit -m'the-first'
Herokuにpushする
git push heroku master
Heroku側でpostgresqlの設定をする
Herokuのサイトのaddonで、Heroku Postgresを選択する

データベースの初期化する
Herokuで以下のコマンドでpythonモードにする
heroku run python
その後以下をターミナルに入力
>>>from assets.database import init_db
>>>init_db()
データベースに初期値を入れる
Herokuのpythonモードのまま
>>>from assets.database import init_shoki
>>>init_shoki()
(3)Herokuの時間を日本時間に設定する
Herokuのbashモードにする
heroku run bash
現在の時間を確認するとUS時間となっている
$date
一度、bashモードを終了して
heroku config:add TZ=Asia/Tokyo
これで日本時間になる
Herokuをリスタートしてオープン
heroku restart
heroku open
(4)Heroku内のPostgresqlを触る
Postgresql をインストールすると、heroku pg コマンドで Heroku Postgres を操作できるようになる。
例えば以下を入力すると、インストールした Heroku Postgresの状況は以下のように確認できる。
heroku pg:info
以下を入力すると、Heroku Postgresqlに接続できる。
heroku pg:psql
テーブル名を確認するコマンドは以下のとおり
\d
すると、typeがtableで、data名でテーブルが登録されている点を確認
テーブル内のデータを一覧するコマンド
SELECT * FROM data(dataは、テーブル名);
(5)HerokuのPostgresqlをcsvに落とす
\copyコマンドでCSVに出力する
ファイルはカレントのディレクトリに書き出される(Heroku側ではなく、ちゃんとローカルのディレクトリに書き出しになる)
heroku pg:psql -c "\copy (SELECT * FROM data) TO dump.csv WITH CSV HEADER"
cat dump.csv
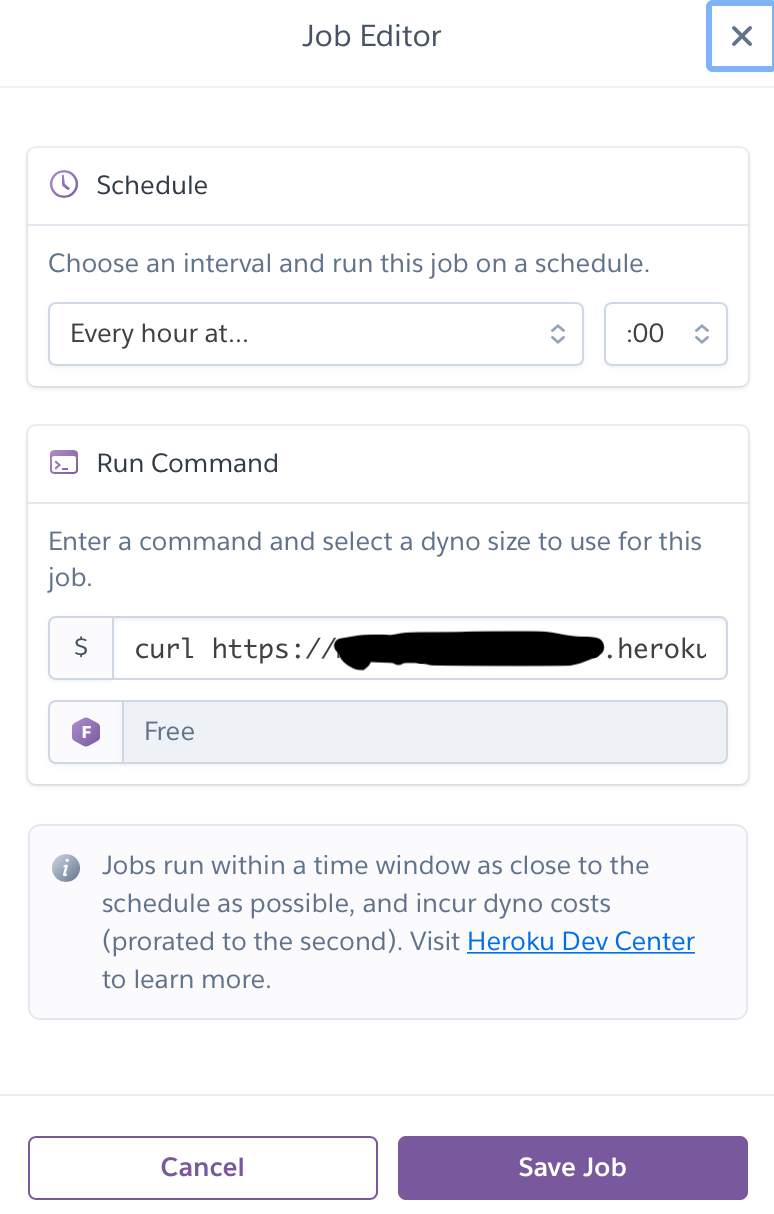
(6)Heroku定期実行
Herokuのaddから、Heroku Schedulerを選択し、以下のように入力
curl https://●●●●●.herokuapp.com