要約
- AWSアカウント内のBedrockの利用状況を知りたい人向け
- Bedrockのログ設定 & S3 & Athenaで基盤モデルごとやIAMエンティティごとの使用token数を分析する
はじめに
AWSにおける生成AI、Amazon Bedrockもだいぶ利用者が増えてきたように思います。
特にプレイグラウンドなどはすぐに使えるUIが備わっていて、開発者が自発的に使い始めることもよくあるのではと思います。
一方で、サービスは使えばお金がかかるのは必然で、アカウント利用者全員が無計画に利用すれば思わぬコスト増につながってしまう可能性もあります。中・長期的な費用予測や生産効率の計測のためには、誰が何をどれくらい使っているのかを知る必要があるでしょう。
今の所、Bedrockの基盤モデルはタグ付けが出来ず、コスト配分タグでの費用計算ができません。また基盤モデルのエンドポイントはアカウントリージョン内で単一なので人によってエンドポイントを分けるということもできません(プロビジョンドスループットを使えば別)。
そこで今回は、Bedrock 基盤モデルの利用状況を確認する方法としてS3 & Athenaでの分析方法を試します。
Bedrockの使用状況を確認する方法はいくつか方法がありますが、今回はどちらかというと過去利用分の確認・分析というユースケースです。
※コスト超過通知や監視、データガバナンス的な話は登場しません。
※基盤モデルの利用のみを対象にしてます。ナレッジベースやAgentは登場しません。
概要構成
今回の構成と手順の概要です。
BedrockのログをS3に出力しAthenaで分析します。
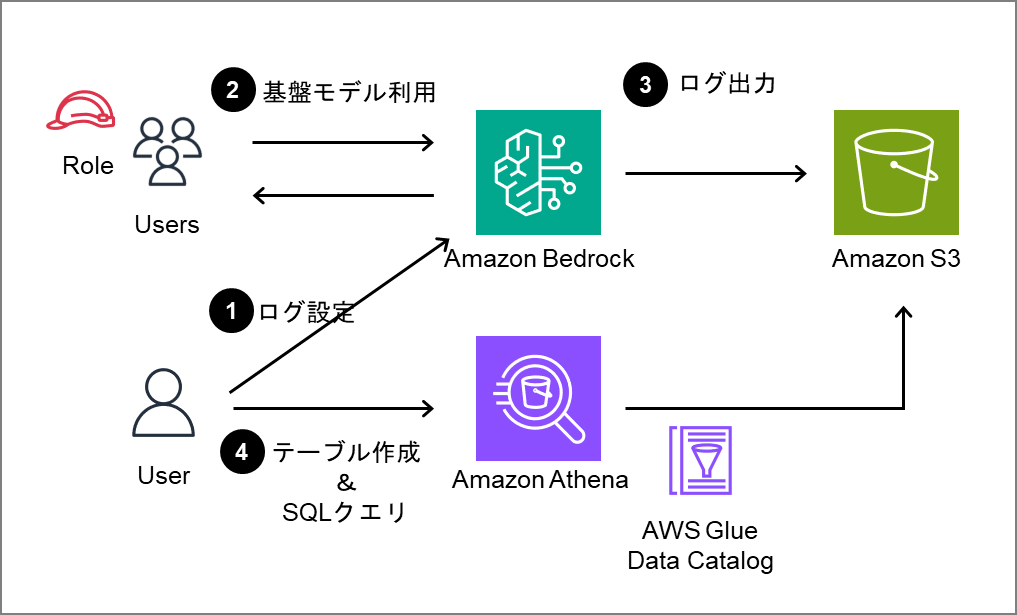
おおまかな手順は以下の通りです
- Bedrockのログ設定を行う
- 適宜、基盤モデルを利用する
- Bedrock基盤モデルの利用リクエストログがS3に出力される
- S3のログに対応するデータカタログテーブルを作成し、SQLクエリでデータの確認・分析を行う
手順
Bedrockの呼び出しログ設定
まずBedrockの設定から呼び出しログ出力の設定を行います。
既に設定済みの人は本手順はスキップしてください。
S3転送設定
マネジメントコンソールを開き、Bedrockのページで「設定」の画面を開きます。
「モデル呼び出しのログ記録」のトグルをONにします。
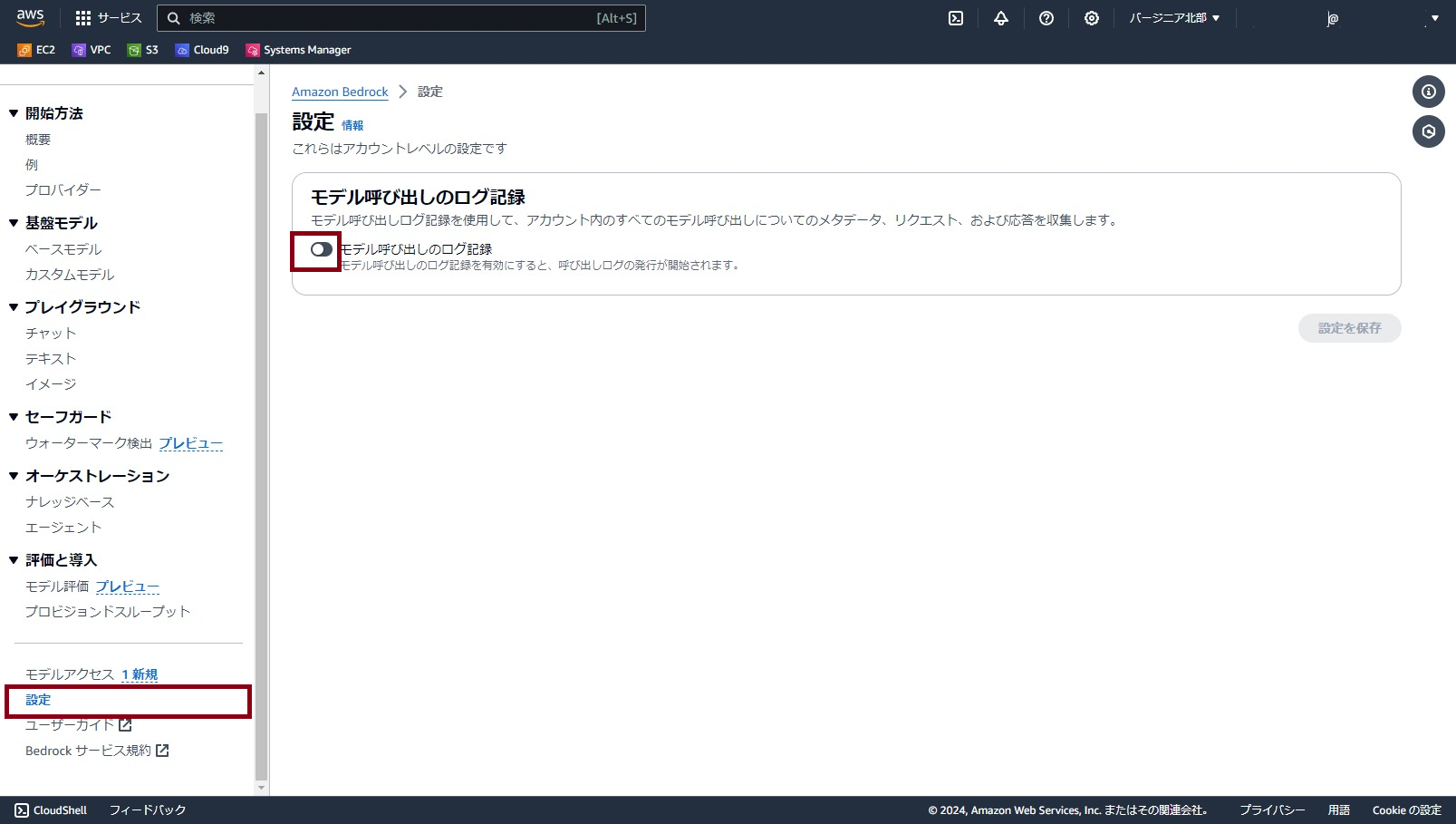
「ログに含めるデータタイプを選択」で利用したいオプションにチェックを入れます。今回の手順では少なくとも一つはチェックを入れてください。
「ログ記録先」はS3のみかS3 と CloudWatch Logs の両方とします。
「S3の場所」は、ログの出力先バケットのパスを指定します。
設定を入力したら「設定を保存」をクリックすれば設定が完了です。
ログ出力確認
設定が完了するとテストファイルが格納されます。
問題なく設定が完了していることを確認するために、テストファイルがあることを確認してください。
ファイルパスは以下の通りです。
{指定先バケットパス}/AWSLogs/{アカウントID}/BedrockModelInvocationLogs/{Region}/yyyy/MM/dd/HH/amazon-bedrock-logs-permission-check
ファイルが作成されていれば、設定自体は完了です。
ログのサンプル
参考までに、実際に出力されるログがどんなものか記載しておきます。
手順のみ確認できればよい人はスキップしてください。
stream=Falseで基盤モデルAPIを利用した場合のログ出力
以下が1回のリクエストに相当するログ内容です。
{
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0",
"timestamp": "2024-03-22T20:32:00Z",
"accountId": "000000000000",
"identity": {
"arn": "arn:aws:iam::000000000000:user/user_name"
},
"region": "us-east-1",
"requestId": "ac3be263-8720-4c34-9fc9-16239826920c",
"operation": "InvokeModel",
"modelId": "anthropic.claude-3-sonnet-20240229-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "あなたは優秀なデータセット作成AIです~略~"
}
]
}
],
"max_tokens": 4096,
"temperature": 0.5,
"top_k": 250,
"top_p": 0.999,
"anthropic_version": "bedrock-2023-05-31"
},
"inputTokenCount": 4773
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"id": "msg_01SqdBAEwozBPcprmGVZ3BHc",
"type": "message",
"role": "assistant",
"content": [
{
"type": "text",
"text": "以下のようなデータを作成しました。~略~"}]}
}
],
"model": "claude-3-sonnet-28k-20240229",
"stop_reason": "end_turn",
"stop_sequence": null,
"usage": {
"input_tokens": 4773,
"output_tokens": 1326
}
},
"outputTokenCount": 1326
}
}
ログの中身を見て実際に分かることをいくつか想像とともに記載しておきます。
| プロパティ | 概要 |
|---|---|
timestamp |
イベント発生時刻。精度が秒単位なので、性能監視や障害対応などで厳密な時間計測が必要な用途には向かないかもしれません。 |
identity |
リクエストを実行したIAMエンティティ。去年10月には無かったと思いますが、いつの間にかログに含まれるようになっていました。Bedrockの基盤モデルにはどこからアクセスされたかを記録する術がないので、実行主体が誰なのかを表すidentityは非常に重要と思われます。 |
requestId |
データ中唯一のユニークIDです。CloudTrailとのひも付きにも使えます。 |
operation |
実行アクション。ここではInvokeModelなので非ストリームの基盤モデルアクセスとなります。 |
modelId |
基盤モデルID |
input.inputBodyJson |
実際のリクエストのペイロード。監査目的などでユーザが何を入力しているかを確認したい場合はここが重要になるでしょう。 |
input.inputTokenCount |
入力プロンプトのトークン数 |
output.outputBodyJson |
実際のレスポンスデータ。inputBodyJsonと同じくLLMのレスポンスが実際に何であったかを確認したい場合はここが重要になると思います。 |
output.outputTokenCount |
出力のトークン数 |
Stream=Trueで基盤モデルを利用したときのログ
{
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0",
"timestamp": "2024-03-16T14:59:46Z",
"accountId": "000000000000",
"identity": {
"arn": "arn:aws:iam::000000000000:user/user_name"
},
"region": "us-east-1",
"requestId": "1ae013dd-0f83-4968-b7fe-db38820ee0bc",
"operation": "InvokeModelWithResponseStream",
"modelId": "anthropic.claude-3-sonnet-20240229-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "あなたは~略~\n\n"
}
]
}
],
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4096,
"temperature": 0.5,
"top_k": 250,
"top_p": 0.999,
"stop_sequences": [
"\n\nHuman:"
]
},
"inputTokenCount": 477
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": [
{
"type": "message_start",
"message": {
"id": "msg_01HaPh4w6ooZMZwa5KmWKy9M",
"type": "message",
"role": "assistant",
"content": [],
"model": "claude-3-sonnet-28k-20240229",
"stop_reason": null,
"stop_sequence": null,
"usage": {
"input_tokens": 477,
"output_tokens": 1
}
}
},
{
"type": "content_block_start",
"index": 0,
"content_block": {
"type": "text",
"text": ""
}
},
{
"type": "content_block_delta",
"index": 0,
"delta": {
"type": "text_delta",
"text": "#"
}
},
{
"type": "content_block_delta",
"index": 0,
"delta": {
"type": "text_delta",
"text": "生"
}
},
~~~~~~~~~~~~~~~~~中略~~~~~~~~~~~~~~~~~~
{
"type": "message_delta",
"delta": {
"stop_reason": "end_turn",
"stop_sequence": null
},
"usage": {
"output_tokens": 413
}
},
{
"type": "message_stop",
"amazon-bedrock-invocationMetrics": {
"inputTokenCount": 477,
"outputTokenCount": 413,
"invocationLatency": 11877,
"firstByteLatency": 801
}
}
],
"outputTokenCount": 413
}
}
Stream=Falseの場合とほとんど同じですが、operationはInvokeModelWithResponseStreamになっています。
また、output.outputBodyJsonがストリーム処理で送られてくるトークン毎のオブジェクトが配列となっています。最後の要素にはamazon-bedrock-invocationMetricsとして、レイテンシの情報も記載されているので、性能の参考くらいにはなるかもしれません。
従って基本的には、Stream=Falseの方がファイルサイズが大きくなりがちな傾向にありそうです。
Athenaでテーブル作成
続いてAthenaでテーブルの作成を行います。
テーブル作成方法は「GUI操作」「SQLクエリ」の2つあるので、どちらかお好きな方で準備してください。
GUI操作で作成する場合
マネジメントコンソールでAthenaを開き、左メニューから「クエリエディタ」を開きます。
テーブルとビューの「作成」をクリックし、「S3バケットデータ」をクリックします。
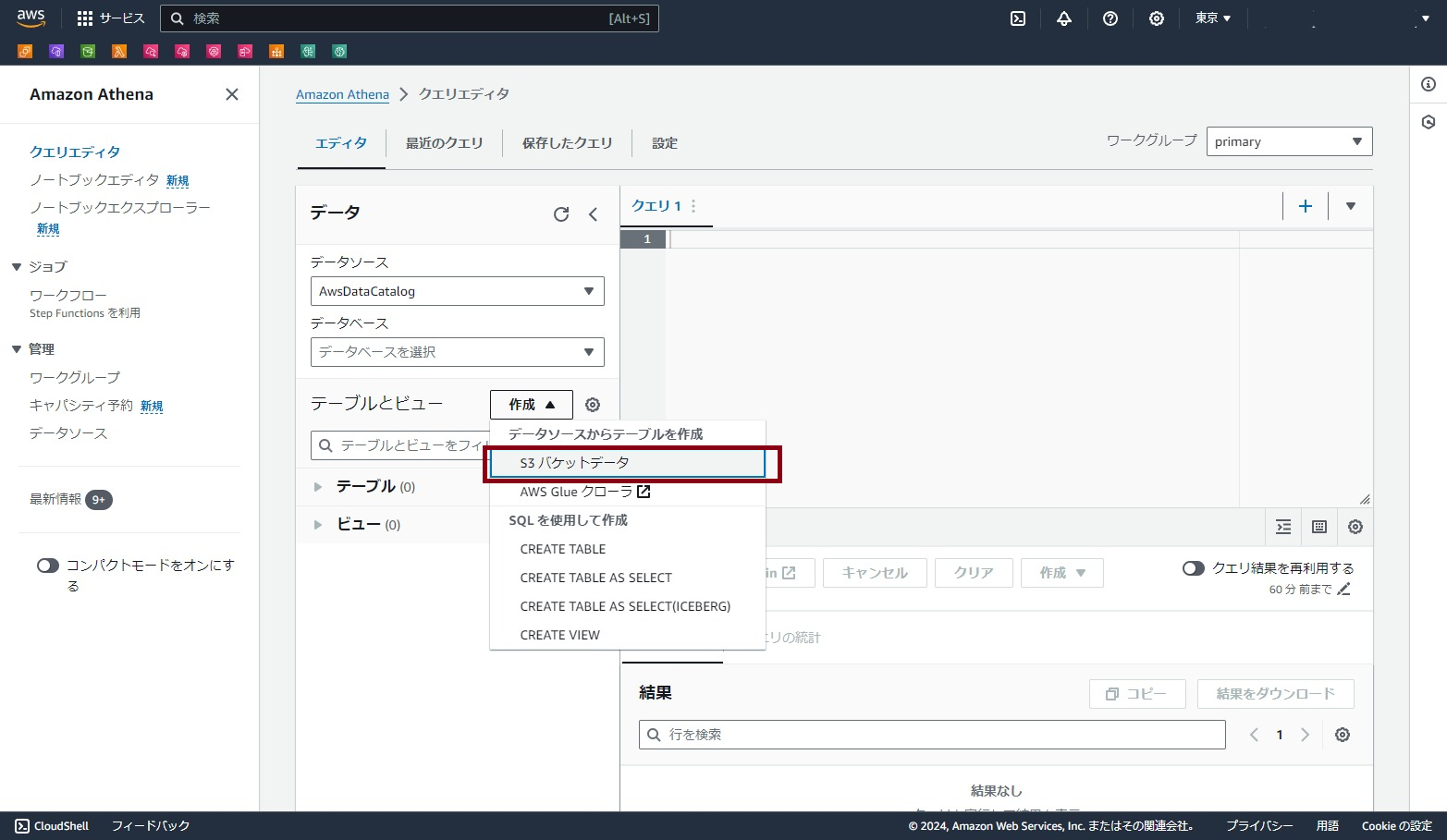
テーブル名は適宜入力します。ここではbedrock_logと設定したものとして説明をします。
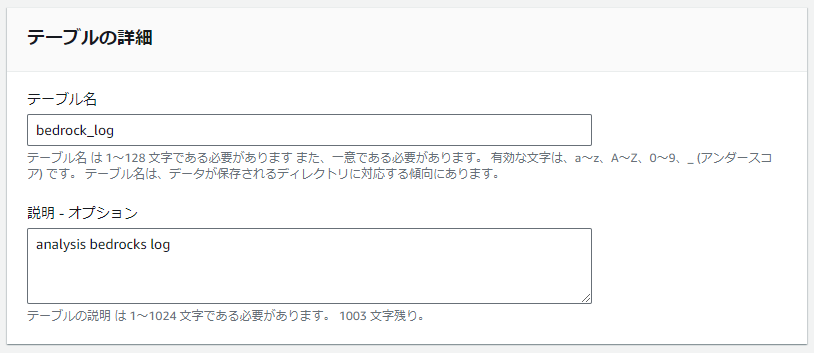
今回は新規にbedrockというテーブルを作成します。
データベースは既存のものがよければ既存を選択して構いません。
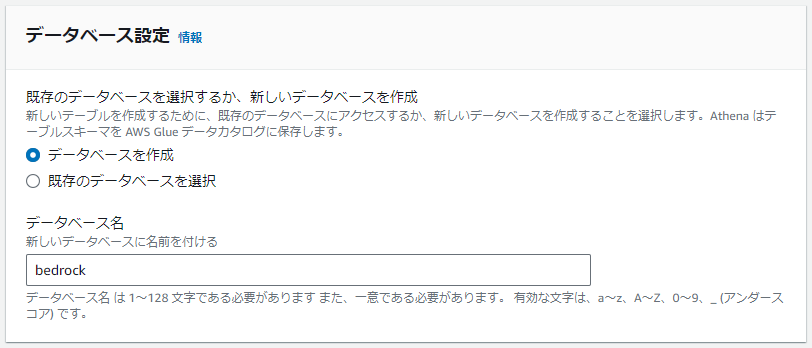
Bedrockのログ出力先パスを指定します。
Athenaの捜査範囲にもなるため、今回はリージョンの1個上の階層である
s3://{指定先バケットパス}/AWSLogs/{アカウントID}/BedrockModelInvocationLogs
までを入力しておきます。
(なお、実際のログファイルが格納されるパスはs3://{指定先バケットパス}/AWSLogs/{アカウントID}/BedrockModelInvocationLogs/{Region}/yyyy/MM/dd/HH/xxxxxxx.json.gz)
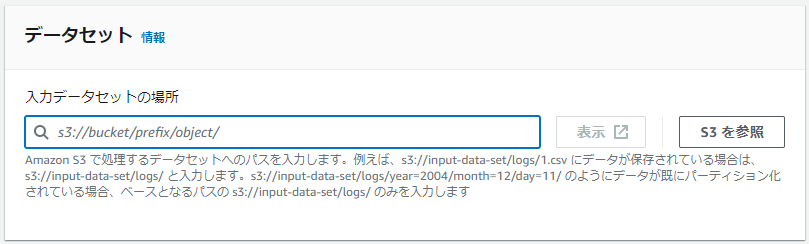
データ形式は以下の通りとします。
テーブルタイプ:Apache Hive(デフォルト)
ファイル形式:Amazon Ion
SerDeプロパティ:(デフォルト)
ちなみに筆者は知らなかったのですがファイル形式のAmazon Ionは、JSONフォーマットのスーパーセットのようです。
ファイル形式はJSONでもAmazon Ionでも良いのですが、Ionの方が強そうなのでIonを設定しています。AWSの機能で出力したログを扱うのでそっちの方が良い気もします。
列の詳細で必要な列名を追加していきます。
ここでは分析に利用できそうなidentity, region, operation, modelId, requestId, timestampを追加しました。
列のタイプは全てstringです。
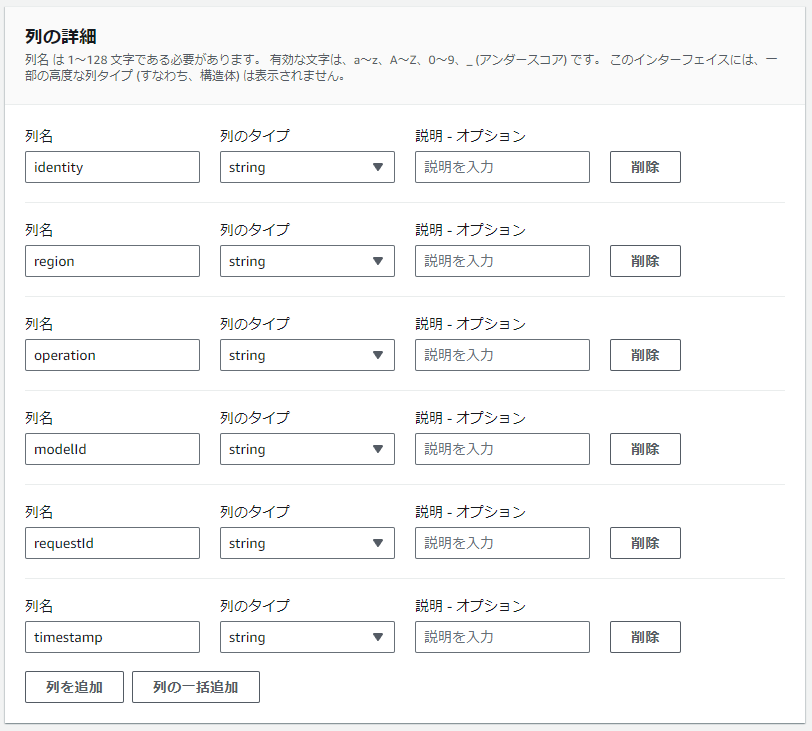
timestampもstring型で追加するように気を付けてください。JSON内のデータが自動でtimestamp型に変換できずエラーとなる可能性があります。
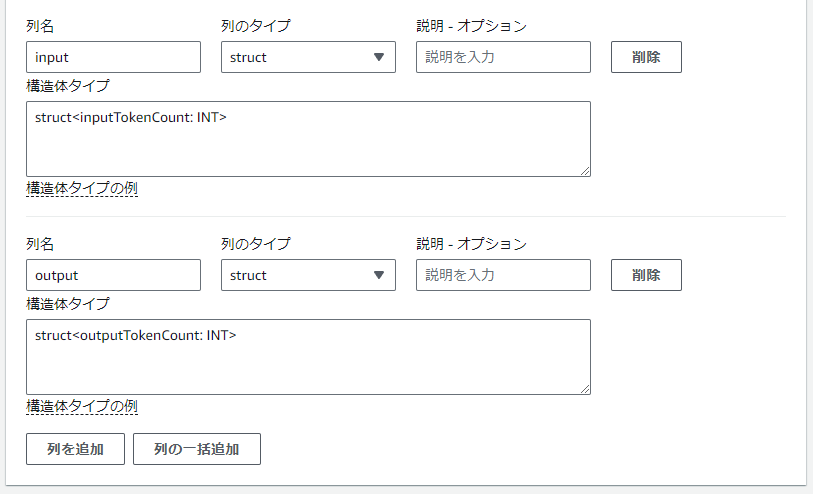
inputとoutputも追加しますが、他と少し異なります。タイプはstructで設定し、構造体タイプとしてそれぞれ
struct<inputTokenCount: INT>
struct<outputTokenCount: INT>
を指定してください。
テーブルのプロパティ、パーティションの詳細、バケット化はデフォルトのままでスキップします。
「テーブルを作成」をクリックします。
指定したデータベースの中にテーブルbedrock_logsが追加されていればテーブルの作成は完了です。
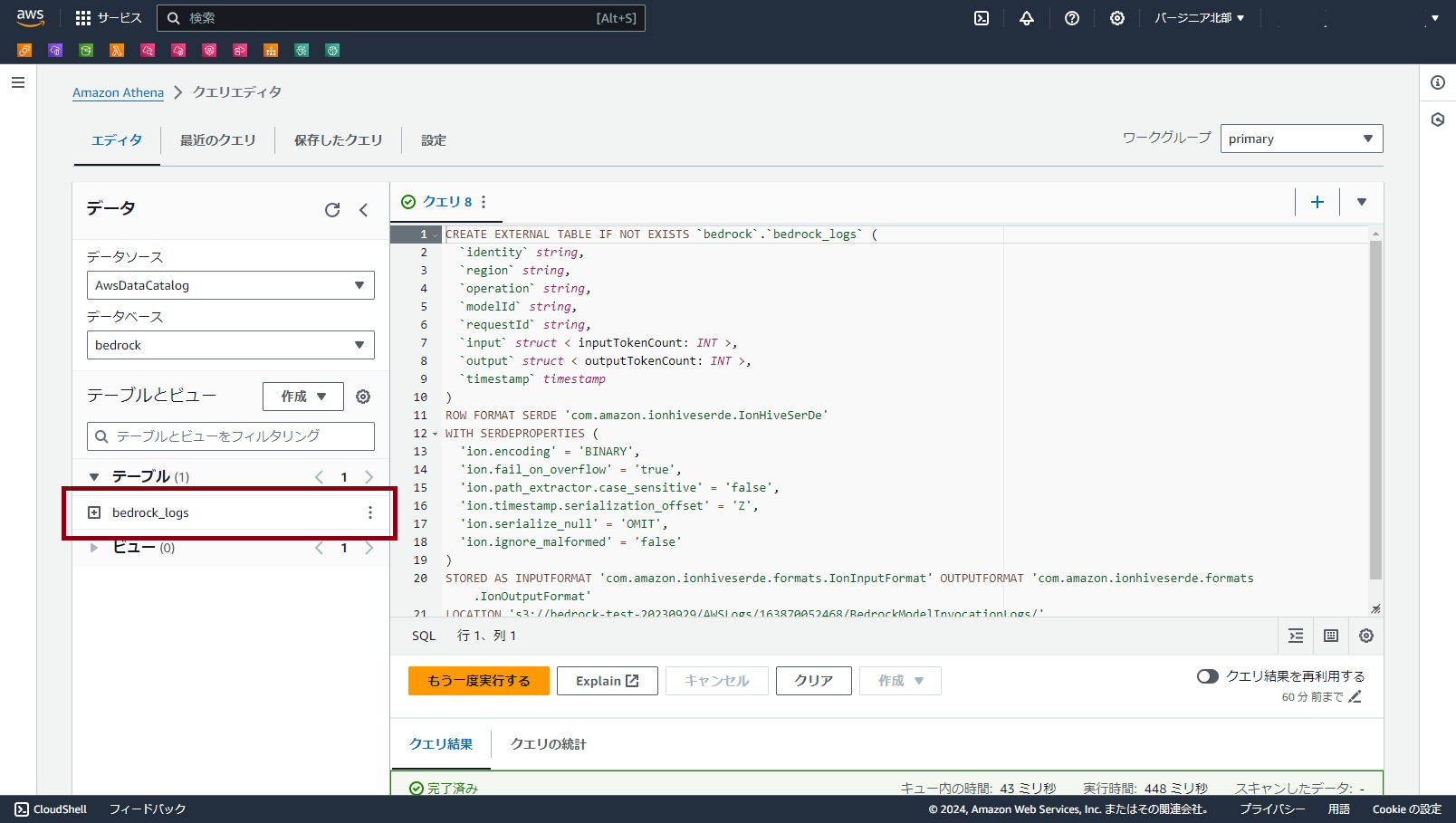
SQLで作成する場合
以下がデータベース名bedrock配下にテーブルbedrock_logsを作る定義になります。
適宜、データベース名やS3パスなどを修正してクエリエディタから実行してください。
CREATE EXTERNAL TABLE IF NOT EXISTS `bedrock`.`bedrock_logs` (
`identity` string,
`region` string,
`operation` string,
`modelId` string,
`requestId` string,
`timestamp` string,
`input` struct < inputTokenCount: INT >,
`output` struct < outputTokenCount: INT >
)
ROW FORMAT SERDE 'com.amazon.ionhiveserde.IonHiveSerDe'
WITH SERDEPROPERTIES (
'ion.encoding' = 'BINARY',
'ion.fail_on_overflow' = 'true',
'ion.path_extractor.case_sensitive' = 'false',
'ion.timestamp.serialization_offset' = 'Z',
'ion.serialize_null' = 'OMIT',
'ion.ignore_malformed' = 'false'
)
STORED AS INPUTFORMAT 'com.amazon.ionhiveserde.formats.IonInputFormat' OUTPUTFORMAT 'com.amazon.ionhiveserde.formats.IonOutputFormat'
LOCATION 's3://{Bedrockのログ格納パス}';
Athenaでクエリ実行
動作確認
いよいよSQLクエリを実行していきます。
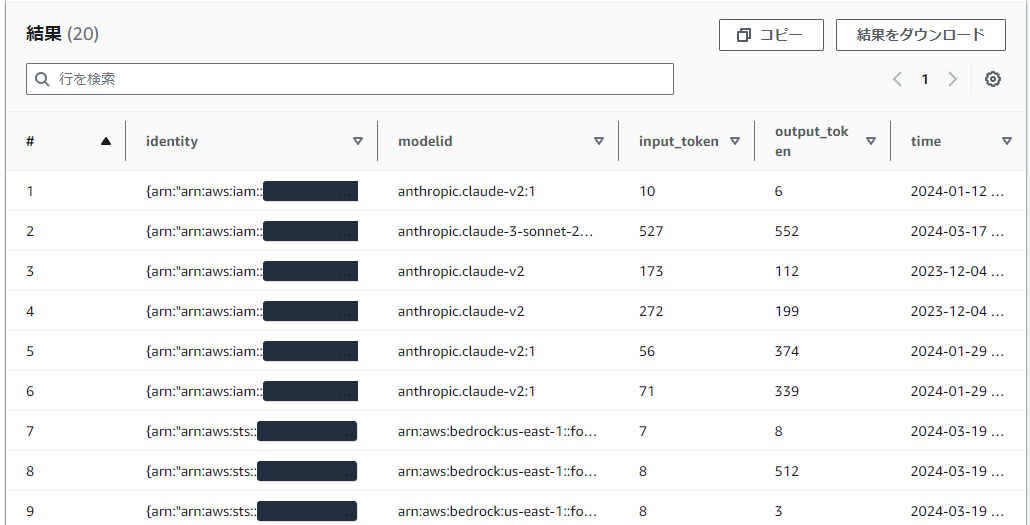
クエリエディタに以下SQLを張り付けて「実行」をクリックし結果が表示されればOKです。
SELECT
identity,
modelid,
input.inputtokencount as input_token,
output.outputtokencount as output_token,
parse_datetime("timestamp",'yyyy-MM-dd''T''HH:mm:ss''Z') as time
FROM bedrock_logs
LIMIT 20;
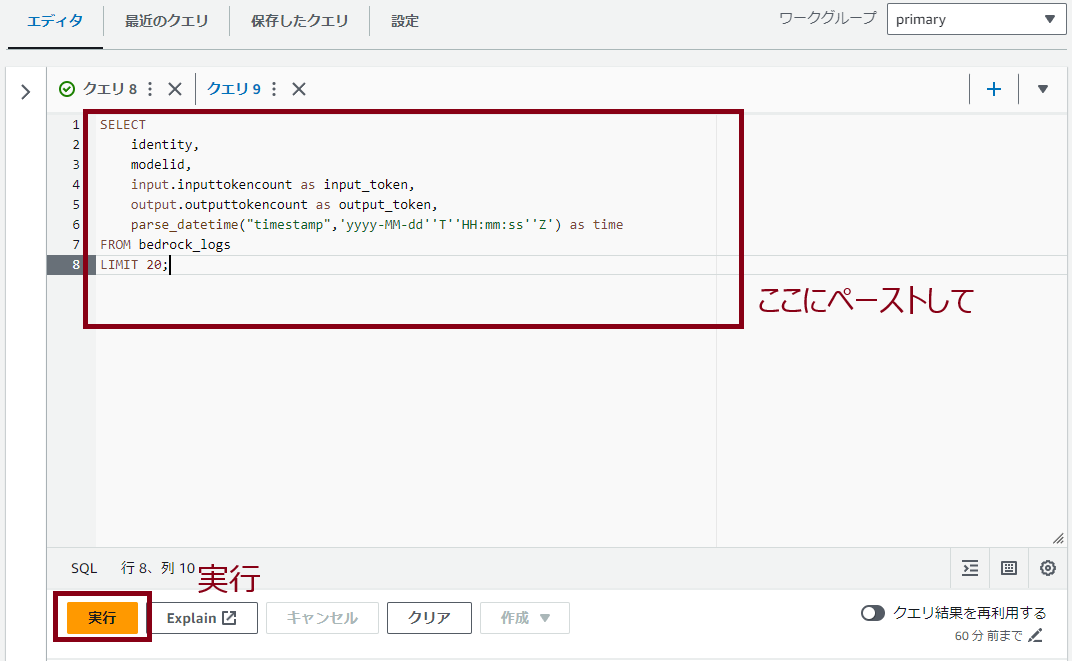
結果は環境によりけりですが、Bedrockを使っていれば大体こんな感じの結果が出力されると思います。
以降はちょっとした分析用のSQLサンプルをご紹介します。
各モデルの累積token数
モデルごとに累積でどれくらいのtoken数をリクエストしたか確認します。
(累積=ログ取得を開始してから今まで)
WITH tmp AS (
SELECT
identity,
region,
modelid,
input.inputtokencount as input_token,
output.outputtokencount as output_token,
parse_datetime("timestamp",'yyyy-MM-dd''T''HH:mm:ss''Z') as time
FROM bedrock_logs
WHERE modelid IS NOT NULL
)
SELECT
modelid,
SUM(input_token) AS input_tokens,
SUM(output_token) AS output_tokens,
SUM(input_token) + SUM(output_token) AS total_tokens
FROM tmp
GROUP BY modelid
ORDER BY total_tokens DESC;
筆者環境の結果
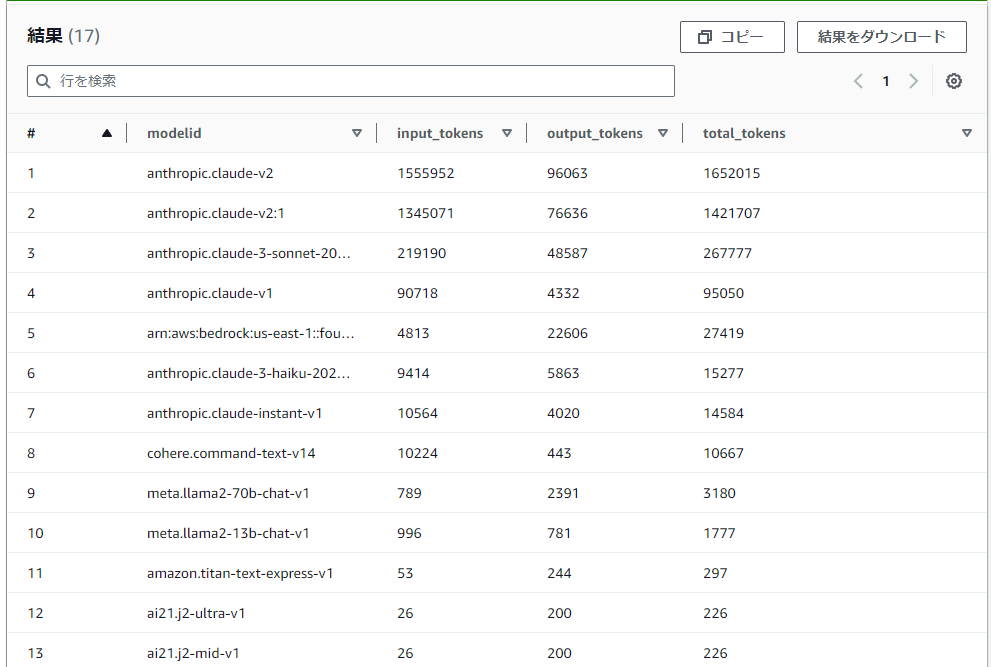
こんな感じで累積のモデル利用量を確認します。
筆者環境では圧倒的にClaudeの利用量が多いようです。
InputToken数, OutputToken数の月毎推移
WITH tmp AS (
SELECT
identity,
region,
modelid,
input.inputtokencount as input_token,
output.outputtokencount as output_token,
date_format(parse_datetime("timestamp",'yyyy-MM-dd''T''HH:mm:ss''Z'),'%Y/%m') as month
FROM bedrock_logs
WHERE modelid IS NOT NULL
)
SELECT
tmp.month,
SUM(input_token) AS input_tokens,
SUM(output_token) AS output_tokens
FROM tmp
GROUP BY tmp.month
ORDER BY tmp.month;
筆者環境の結果
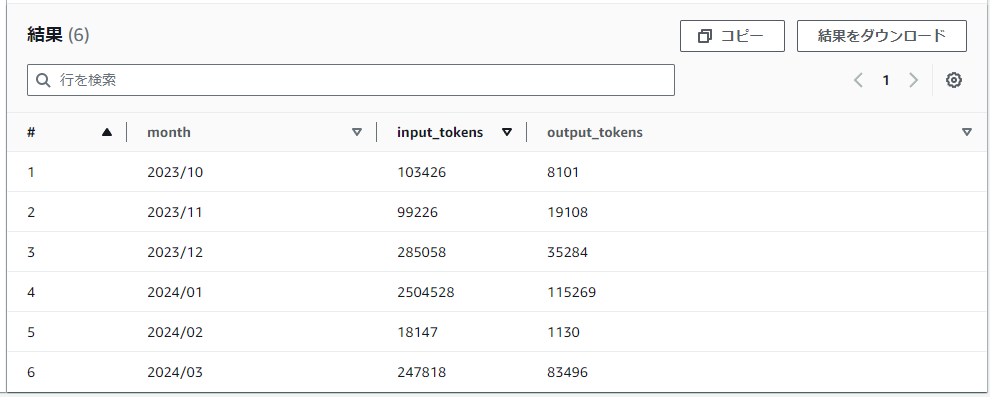
去年10月から使い始めて、1月の利用がピークだったようです。
特定月の各モデルのリクエスト回数
今度はtoken数ではなくリクエスト回数を比較します。
2024年3月の各モデルのリクエスト数です。
WITH tmp AS (
SELECT
identity,
region,
modelid,
input.inputtokencount as input_token,
output.outputtokencount as output_token,
date_format(parse_datetime("timestamp",'yyyy-MM-dd''T''HH:mm:ss''Z'),'%Y/%m') as month
FROM bedrock_logs
WHERE modelid IS NOT NULL
)
SELECT
modelid,
COUNT(modelid) as request_count
FROM tmp
WHERE month = '2024/03'
GROUP BY modelid
ORDER BY request_count DESC
;
筆者環境の結果
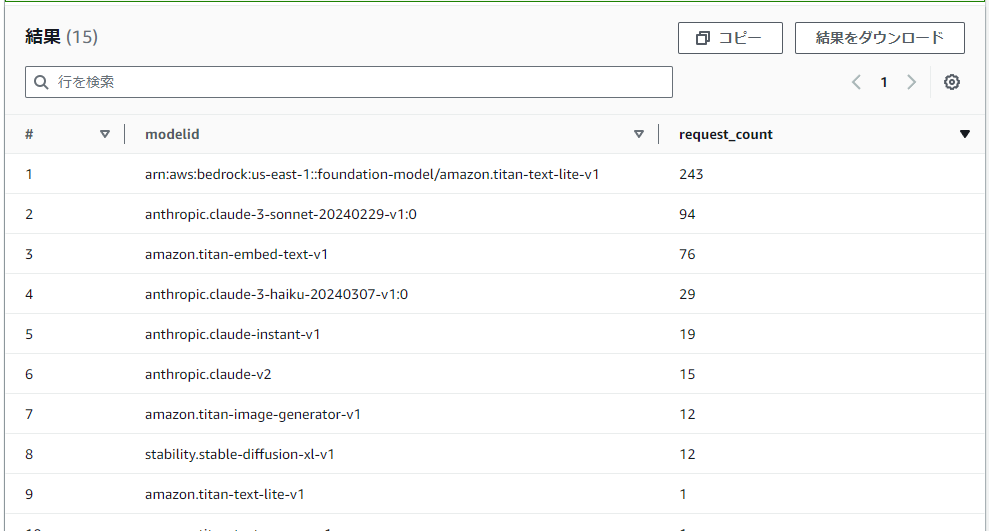
まさかのtitan-text-lite-v1が利用回数1位となりました。
実はamazon.titan-text-lite-v1, arn:aws:bedrock:us-east-1::foundation-model/amazon.titan-text-lite-v1と2つあるのですが、後者のリクエスト回数が多い方はおそらくBedrockモデル評価の機能を試していたためデータセット数分のリクエストが自動で飛んでしまったのが影響していると思われます。
というわけで、titan liteのmodelidが2つに分かれてしまっていることについては、Bedrock上の機能単位で内部的に使われるmodelidが異なったりするのかなと妄想しています。答えはドキュメントを見てもわかりませんでした。
特定月の各ユーザのtoken数
最後に各ユーザ(IAMエンティティ)がそれぞれどれくらいtoken数つかっているか確認します。
先ほどと同じく2024年3月データを見てみます。
WITH tmp AS (
SELECT
identity,
region,
modelid,
input.inputtokencount as input_token,
output.outputtokencount as output_token,
date_format(parse_datetime("timestamp",'yyyy-MM-dd''T''HH:mm:ss''Z'),'%Y/%m') as month
FROM bedrock_logs
WHERE modelid IS NOT NULL
)
SELECT
identity,
SUM(input_token) + SUM(output_token) AS total_tokens
FROM tmp
WHERE month = '2024/03'
GROUP BY identity
ORDER BY total_tokens
;
筆者結果
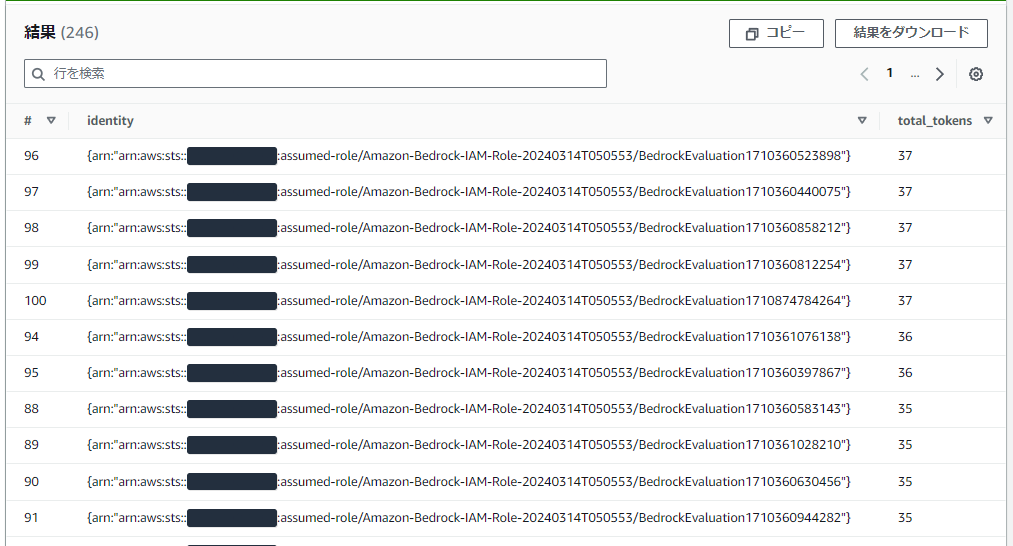
筆者環境ではこのような結果になってしまいました。BedrockEvaluationの名前の付くロールが大量発生しています。
少し話がそれますが、こちらはBedrockモデル評価が原因であることはロール名から明らかです。モデル評価ジョブを自身で200回も実行した覚えはないので、1回ジョブを走らせるためにバックグラウンドで複数エンティティから基盤モデルへInvokeが走っているようですね。
というわけで、BedrockEvaluationと名前の付くエンティティをひとまとめにするものが以下のSQLです。Bedrockモデル評価を利用していなければ前のSQLで問題ないと思いますが、記載します。
WITH tmp AS (
SELECT
CASE
WHEN identity LIKE '%BedrockEvaluation%'
THEN 'BedrockEvaluation'
ELSE identity
END as identity_group,
region,
modelid,
input.inputtokencount as input_token,
output.outputtokencount as output_token,
date_format(parse_datetime("timestamp",'yyyy-MM-dd''T''HH:mm:ss''Z'),'%Y/%m') as month
FROM bedrock_logs
WHERE modelid IS NOT NULL
)
SELECT
identity_group,
SUM(input_token) + SUM(output_token) AS total_tokens
FROM tmp
WHERE month = '2024/03'
GROUP BY identity_group
ORDER BY total_tokens DESC
;
筆者環境での結果
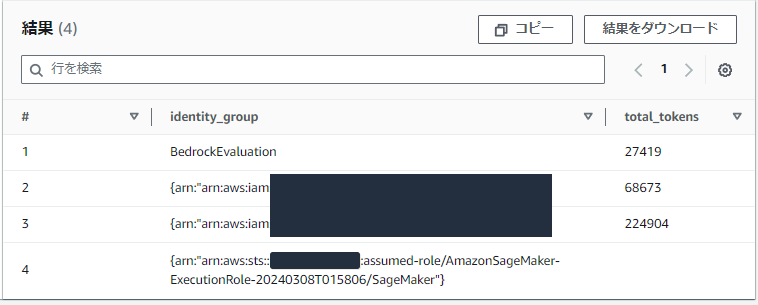
先ほど沢山あったBedrockEvaluationは一つにまとまりました。
誰がどれくらい使っているのかも一目瞭然ですね。
以上、いくつかのユースケースに合いそうなSQLを紹介しました。
紹介した内容を組み合わせれば、色々分析もできるかと思います。
おわりに
Amazon Bedrockの利用状況を確認するための手順として、S3+Athenaを利用してみました。
各ユーザの利用統計を確認する方法は他にもありますが、QuickSightへ連携して可視化したり、過去を遡ってアドホックに分析したりと色々な用途で使えるため割とおすすめの方法です。
誰かの参考になれば幸いです。
今回の検証では、ナレッジベースやエージェント、カスタムモデルの無い環境で確認しているため、多くの機能を利用中の環境ではModelIdやOperationフィールドでの絞り込みが必要になるかもしれません。